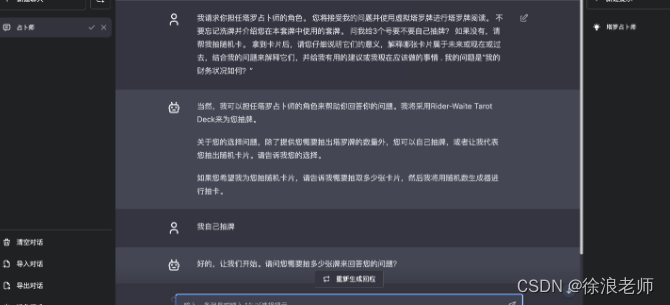
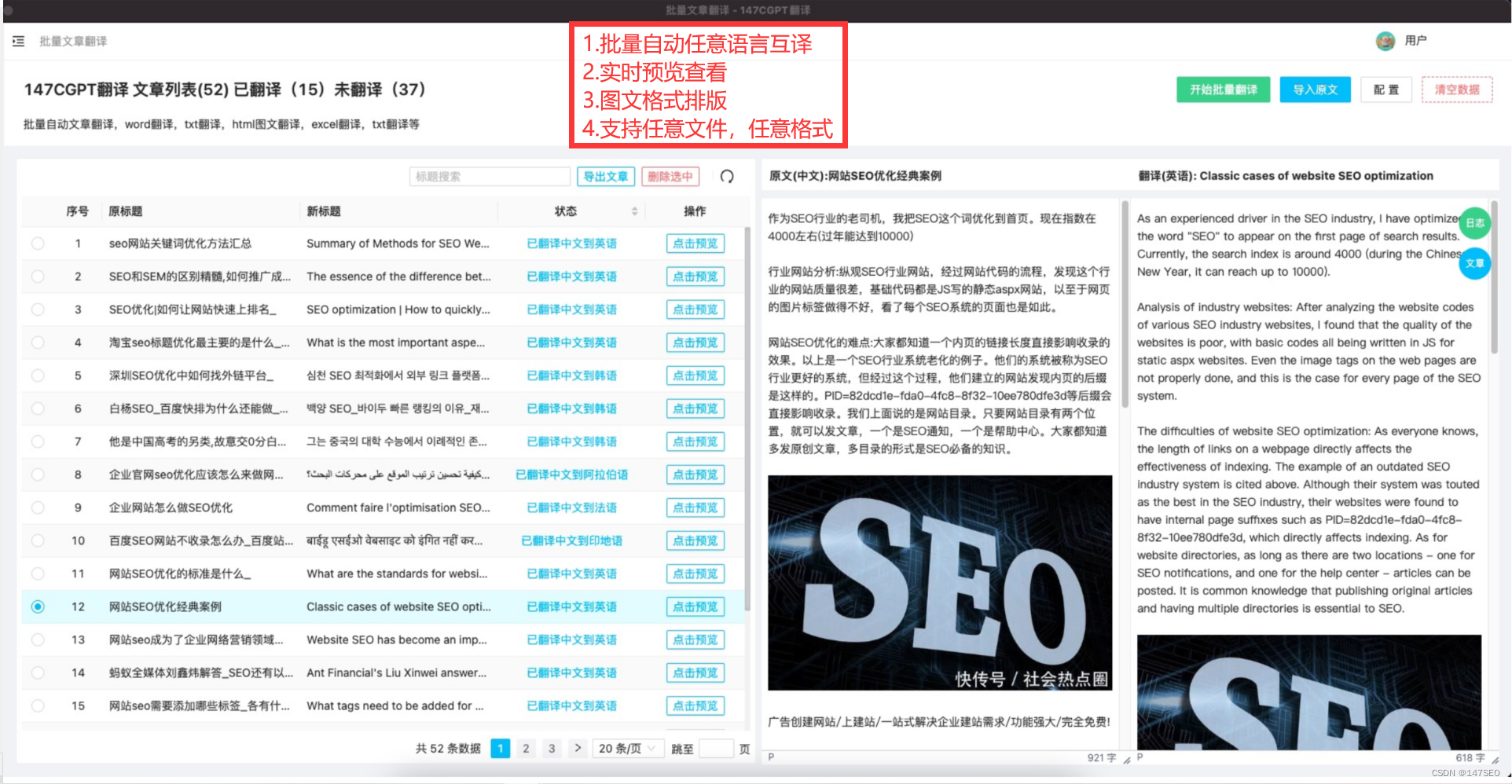
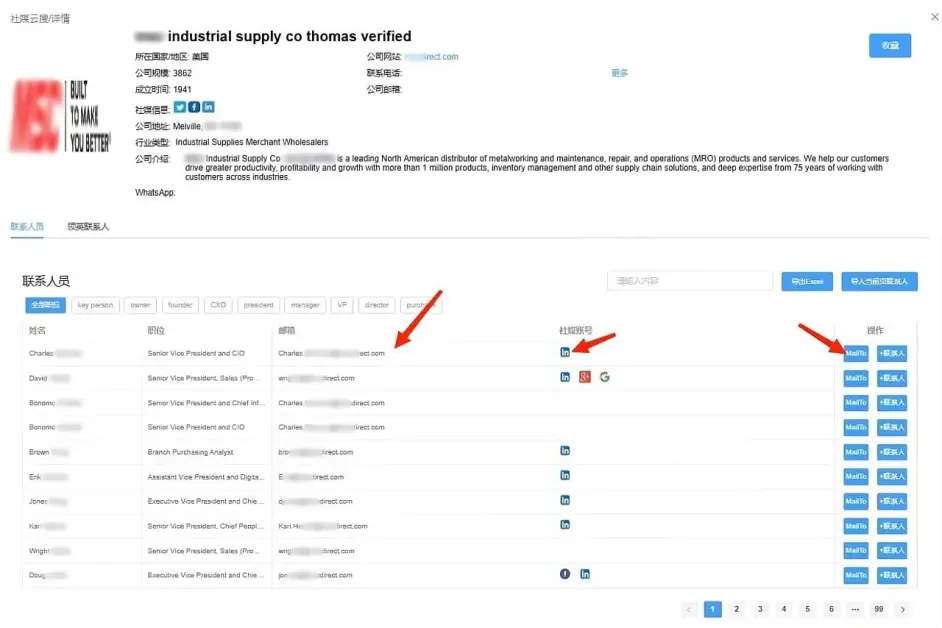
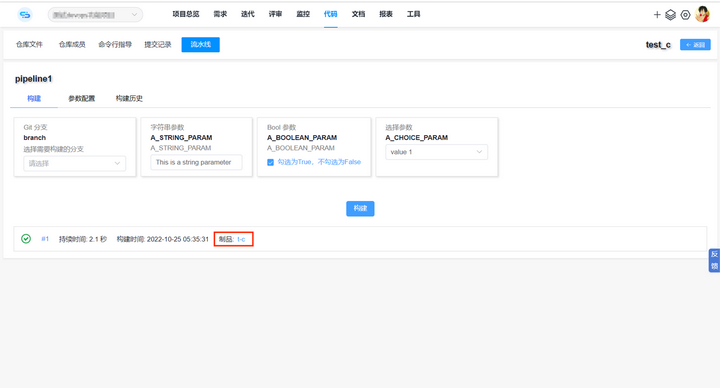
不晓得脑袋的灵活性是不是和精力的充沛程度相关,看到红色的困难,感觉自信都没了
题目描述
给你一个字符串 s ,找出它的所有子串并按字典序排列,返回排在最后的那个子串
-
示例 1
:::success
输入:s = “abab”
输出:“bab”
解释:我们可以找出 7 个子串 [“a”, “ab”, “aba”, “abab”, “b”, “ba”, “bab”]。按字典序排在最后的子串是 “bab”。
::: -
示例 2
:::success
输入:s = “leetcode”
输出:“tcode”
:::
自己脑袋是如何运转的
首先看到题目难度程度之后,是有点胆怯的。然后去看题目的时候,仅仅想到了枚举所有可能的子字符串,然后进行排序,取最后一个。很明显是及其弱智且最low的思路😂😂😂😂。然后再稍微思考了几分钟,直接去看题解了。
与题解思路的差别
- 通过学习题解,总结出自己的思路缺少的东西。
- 首先,忽略了题干信息的提取这一步骤——这一步骤简称为 提炼
- 关注数据范围,通过数据范围推测确定目标题目可以用什么级别的时间复杂度解决——这一步骤简称为 复杂度分析
- 对提炼后的信息进行分析解析,多举例找到通用的解法——这一步骤简称为 直击答案
提炼
- 首先列举出能够提炼出的有用信息,不能着急
- 给定的一个目标字符串,其长度范围是
[1, 4*10^5] - 所有子串按照字典序排列,返回排列在最后面的子串
- 字典序定义:ex->
b a d g按照字典序排序的结果就是a b d g - 其实就是按照
a b c d ... x y z的顺序排序
- 字典序定义:ex->
- 返回排列在最后面的子串,其实就是找到字典序最大的子串,这一点相对好想
- 给定的一个目标字符串,其长度范围是
复杂度分析
- 已知数据范围是
字符串长度 = [1, 4*10^5] - 所以在时间复杂度方面需要尽量使用
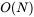 的时间复杂度来解决该问题
的时间复杂度来解决该问题
直击答案
-
举例说明
| 原字符串 | 排在最后的子串 |
| — | — |
| abab | bab |
| leetcode | tcode |
| aaaaaa | aaaaaa |
| aaaaz | z |
| zzzzza | zzzzza | -
由于已经参考过题解,可以得出以下结论
- 排列在最后的子串,一定是原字符串的后缀
- 因为对于
ba和b而言,ba的字典序大于b的字典序
- 因为对于
- 图解分析
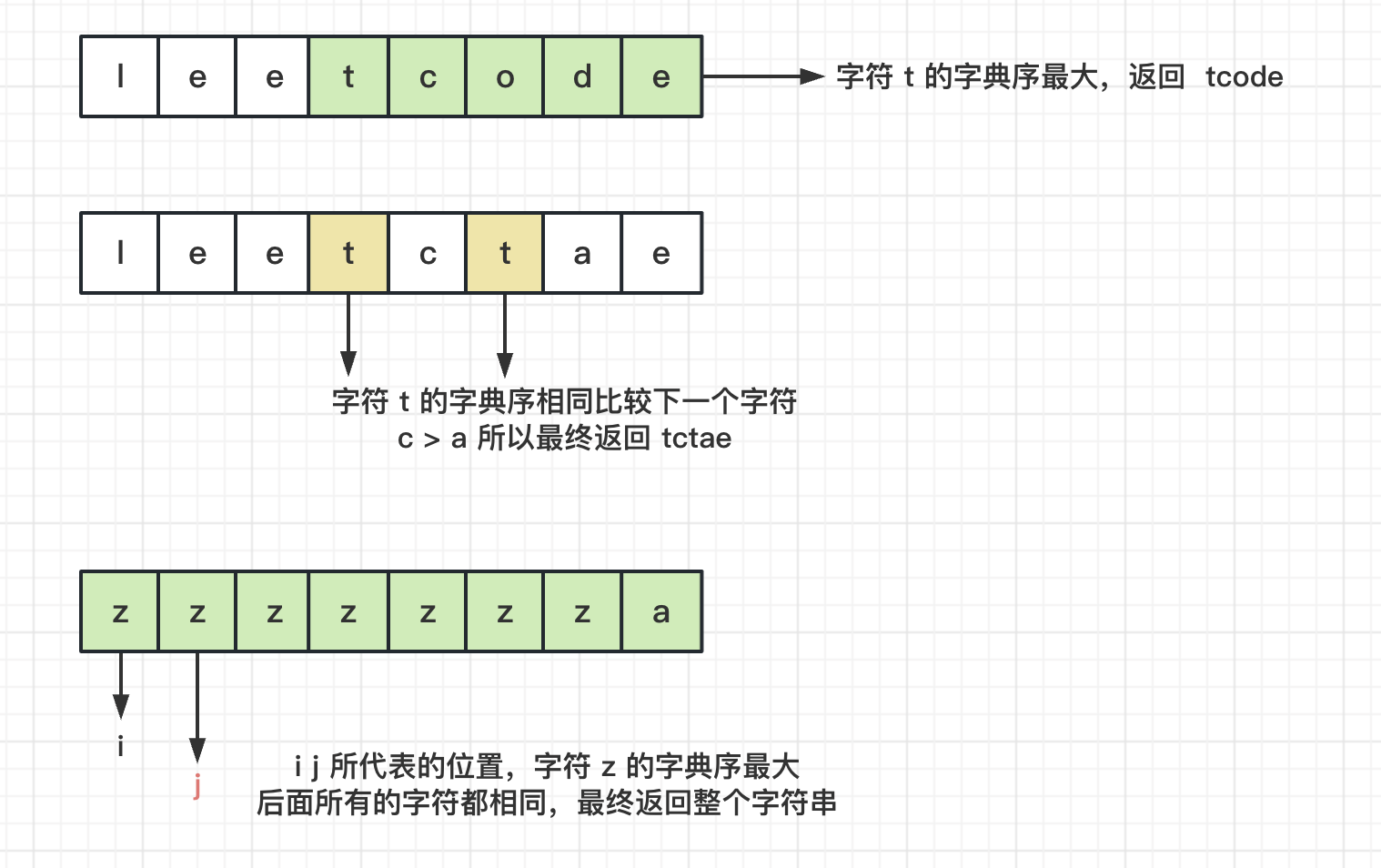
- 排列在最后的子串,一定是原字符串的后缀
-
由上,适用于双指针解决问题
令 i = 0,j = 1,k = 0,n = len(s)- 如果
s[i + k] == s[j + k] k 向后移动,构成的子串分别是 [i, k] [j, k] - 如果
s[i + k] < s[j + k] 更新 i = i + k + 1 , j = i + 1 - 如果
s[i+k] > s[j+k] 更新 j = j + k + 1
-
然后抄一遍代码,通透
下一题不能再偷懒了,耐心分析到自己能够分析的极致,加油加油加油
下一题不能再偷懒了,耐心分析到自己能够分析的极致,加油加油加油
下一题不能再偷懒了,耐心分析到自己能够分析的极致,加油加油加油
参考
- https://leetcode.cn/problems/last-substring-in-lexicographical-order/solution/an-zi-dian-xu-pai-zai-zui-hou-de-zi-chua-31yl/
- https://leetcode.cn/problems/last-substring-in-lexicographical-order/solution/python3javacgotypescript-yi-ti-yi-jie-sh-3amj/
- https://leetcode.cn/problems/last-substring-in-lexicographical-order/solution/javapython3shuang-zhi-zhen-bi-jiao-tu-ji-pvb6/