背景
-
消息队列如Kafka、Pulsar利用事务特性所提供的exactly once语义,只能在特定使用场景 consume-transform-produce 下保证,即一个事务同时包含了生产和消费,利用事务的原子性,事务中的操作包含sink端的生产和source端的offset提交,这两个操作要么同时完成,要么同时不完成。它不用关心事务是否commit成功,因为无论是否成功,端对端的状态前后都是一致的。因此,kafka、pulsar实现的事务,都只支持commit或者abort一次,后面重复提交commit、abort请求是非法的,即不支持Commit操作的幂等性。
-
Flink提交的exactly once语义,是基于Flink自身实现的两阶段提交协议来保证的,当接入一个外部系统时,为了保证exactly once语义,Flink对外部系统是有要求的:1. 提供事务功能 2. 事务commit操作要保证幂等性。详细原理参考上一小节:https://blog.csdn.net/m0_43406494/article/details/130294452
问题分析
因此,当前Kafka、Pulsar接入Flink都是不完全满足条件的。
当Flink打checkpoint完成时,会调用到notifyCheckpointCompelete方法,发送commit请求给外部系统。然而notifyCheckpointCompelete方法只是best effort的,并不保证一定会执行。而且notifyCheckpointCompelete方法执行失败,也不会让已经打好的Checkpoint给删除掉,因此Flink侧要求commit请求必须保证最终成功,否则可能导致丢数。因此,commit请求如果失败,flink会立刻重启任务,执行recoverAndCommit方法,重新执行commit请求,一直到commit请求成功。
那Kafka、Pulsar不支持多次Commit的,岂不是会无限重启?理论上是这样的。
下面举些具体的例子,触发这个问题:
- flink发送commit请求到达broker后,broker把事务commit成功后,刚好滚动重启或者宕机,导致commit成功的响应没给flink客户端,导致flink侧报错重启任务,重新commit,但是kafka、pulsar不支持重复commit因此会一直报错。此时事务在broker侧是committed状态的,这种情况直接忽略报错是状态一致的。
- flink完成了pre commit阶段,进入了commit阶段,发送commit请求,还没来得及发送就宕机了,或者用户关停任务,持续相当长一段时间,重新启动flink任务时会重新commit事务,但是由于时间较长事务在broker侧早就超时自动aborted了,因此,此时事务在broker侧是aborted状态的,这就导致了丢数了。
Pulsar与Kafka的不同点
是否保存最后一个事务的状态
- pulsar的transactionID是由broker分配的,不用用户设置,也没法设置;而kafka这里是用户设置的。
- kafka的ProducerID是由broker分配的,用户没法设置;但是pulsar的ProducerName是可以由用户设置的。
- kafka会复用transactionID,transactionID一个时刻对应一个事务,这个事务完成后可以复用这个transactionID开启下一个事务,broker会使用一个Map维护每个transactionID的元数据。因此只要没开启新的事务,kafka是能查询到最后一个完结的事务的状态,更旧的事务状态会被最后一个事务的状态覆盖掉;但是pulsar不一样,一个transactionID严格对应一个事务,不能复用,pulsar用完一个transactionID就立刻清除数据了。
有一个点这里需要提示的,虽然在broker侧Kafka是能查到最后一个事务的状态,但是Kafka原生的客户端逻辑会使得尽管没开启新事务,第二次Commit仍然会失败,但是Flink Kafka Connector处理了这个问题,从而支持了:只要不开启新的事务,Kafka是支持对最后一个事务进行重复commit的。
下面进行详细地介绍这个事情,如果是简单地重复commit两次,会报错
@Test
public void givenMessage_whenProduceWithTransaction_thenShouldSucceed() {
try {
kafkaProducer.beginTransaction();
String message = "Hello, Kafka";
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, message);
kafkaProducer.send(record);
kafkaProducer.commitTransaction();
kafkaProducer.commitTransaction();
} catch (Exception ex) {
kafkaProducer.abortTransaction();
Assertions.fail("Failed to produce message with transaction, reason: " + ex.getMessage());
}
}
报错如下:
org.apache.kafka.common.KafkaException: TransactionalId kafka_producer_id: Invalid transition attempted from state READY to state COMMITTING_TRANSACTION
这是因为,客户端第一次commit,收到broker的成功响应后会把事务的状态转换为Ready状态,而Commit请求会尝试把事务状态切换为COMMITTING状态,只能从IN_TRANSACTION状态切换为COMMITTING状态,从Ready状态切换为COMMITTING状态是非法的,因此第二次commit报错了。
客户端侧的事务状态机如下:
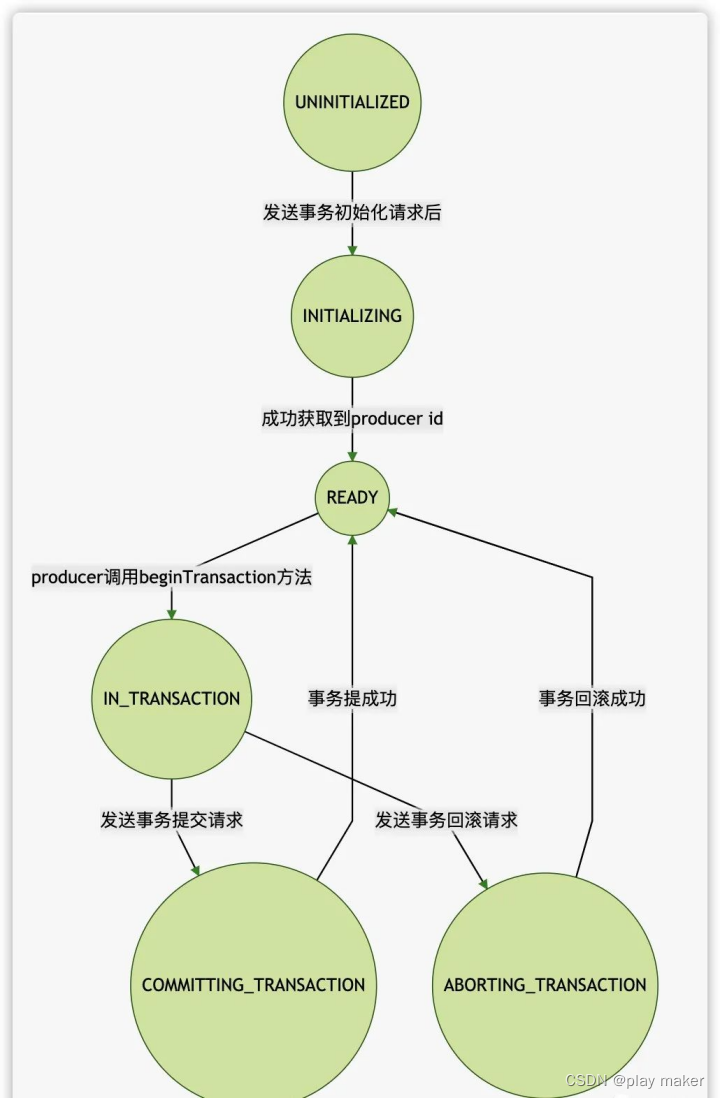
org.apache.kafka.clients.producer.internals.TransactionManager.State#isTransitionValid
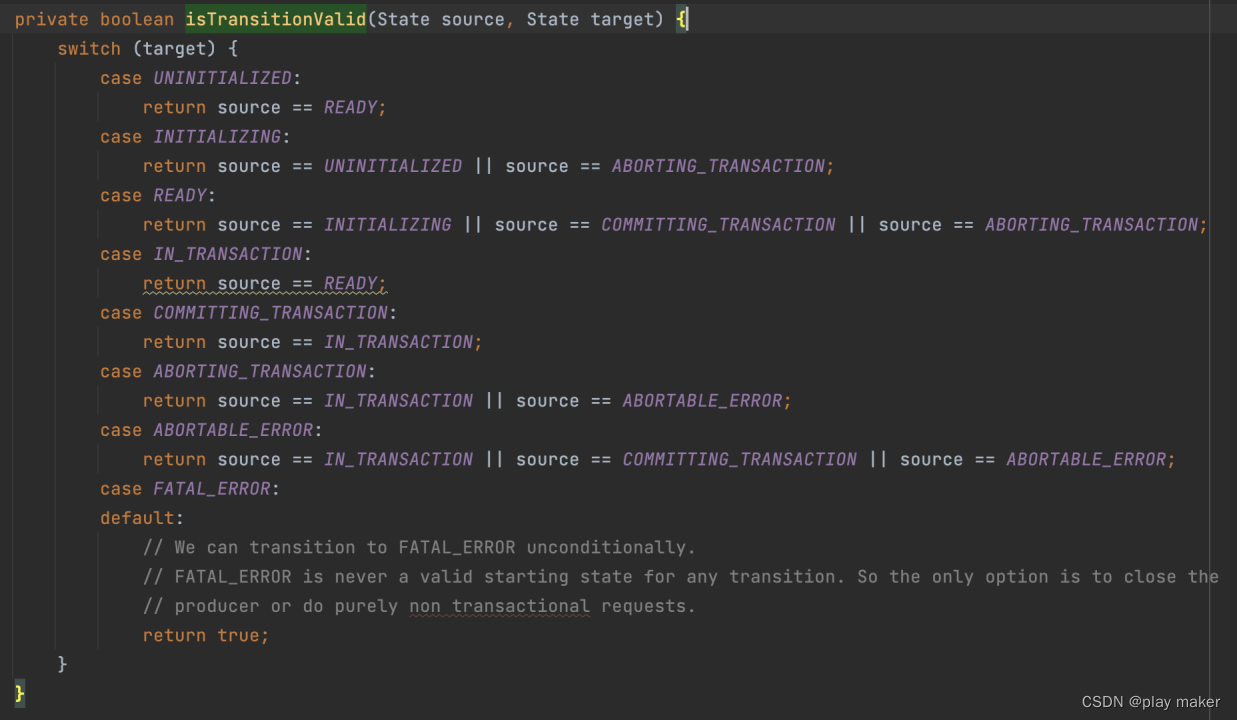
而Flink Kafka Connector对这种情况进行了fix,在恢复事务时,通过反射的手段把事务的状态强行设置为IN_TRANSACTION状态,从而支持重复commit了。
org.apache.flink.streaming.connectors.kafka.internals.FlinkKafkaInternalProducer#resumeTransaction

为了更好地展示这个事情,使用下面的测试代码模拟Flink Kafka Connector的逻辑。
/**
* we can see that, given specified transaction ID, flink kafka connector support for
* committing to the last transaction multiple times.
*/
@Test
public void testCommitMultipleTimes() {
try {
kafkaProducer.beginTransaction();
String message = "Hello, Kafka";
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, message);
kafkaProducer.send(record);
kafkaProducer.commitTransaction();
// try to commit multiple time directly will fail, because current state
// of transaction is Ready.
// kafkaProducer.commitTransaction();
// we need to roll back the transaction state to IN_TRANSACTION to prepare for
// second commit.
Object transactionManager = getField(kafkaProducer, "transactionManager");
assert getField(transactionManager, "currentState").equals(getEnum(
"org.apache.kafka.clients.producer.internals.TransactionManager$State.READY"));
setField(transactionManager, "currentState", getEnum(
"org.apache.kafka.clients.producer.internals.TransactionManager$State.IN_TRANSACTION"));
assert getField(transactionManager, "currentState").equals(getEnum(
"org.apache.kafka.clients.producer.internals.TransactionManager$State.IN_TRANSACTION"));
kafkaProducer.commitTransaction();
} catch (Exception ex) {
kafkaProducer.abortTransaction();
Assertions.fail("Failed to produce message with transaction, reason: " + ex.getMessage());
}
}
还有一个问题,前面也说了,当前支持:只要不开启新的事务,Kafka是支持对最后一个事务进行重复commit的。
那如果开启了新事务,那最后一个事务的状态不就被覆盖了?根据Flink两段式协议的流程,如下图:

在执行snapshotState方法,即pre commit阶段就调用了beginTransaction开启了一个新的事务T2,这不就覆盖了当前checkpoint对应的事务T1的状态了吗?
如果T1跟T2的TransactionID是相同的话,是会覆盖的。因此Flink Kafka Connector里面维护了一个TransactionID池,当notifyCheckpointComplete中事务commit成功时才会把T1对应的TransactionID给放回池子里,供后面的新事务使用。TransactionID池是一个阻塞队列,按添加的顺序进行排序,出队列也是按照顺序来。
每个TransactionID会创建一个对应的Producer,一个checkpoint只用一个事务,对应一个Producer,相邻的checkpoint使用不同的TransactionID、Producer。因此,不用担心新的事务会覆盖最后一个事务的状态。

默认TransactionID池的大小为5,也就是说连续5个checkpoint会分别对应5个不同TransactionID。
最后提示一点,虽然Kafka保证了维护最后一个事务的状态,但也不是永远维护的。为了避免一些TransactionID不再使用了,导致对应无用元数据一直存储在broker内存里,kafka有一个机制:当一个TransactionID的事务状态长时间不更新,则自动把它从内存中删除掉。由transactional.id.expiration.ms来配置这个时间,默认为7天。因此如果停止flink任务长达7天以上,那么重启时也有可能commit失败。

事务超时机制
相同点:
- pulsar跟kafka都是支持由用户为每个事务配置超时时间,在事务初始化时传入到broker。
不同点:
-
kafka在broker侧还有一个配置transaction.max.timeout.ms,用来限制用户设置的超时时间的最大上限,超过了则会事务初始化失败。
逻辑如下,kafka.coordinator.transaction.TransactionCoordinator#handleInitProducerId


-
pulsar对事务超时的控制比kafka更精确,pulsar使用了一个时间轮来安排超时事务的自动abort任务,时间精度为100ms。
-
kafka对事务超时的控制是粗糙的,安排一个周期任务,定期将所有超时的事务abort掉,默认的时间周期是10s,也就是说,会有最大10s的误差。
kafka.coordinator.transaction.TransactionCoordinator#startup

-
pulsar对事务超时的操作是向TB、TP发送abort指令,将事务状态转换为ABORTED,删除元数据就完了。
-
kafka还多了一个epoch机制:
- 每次新Producer创建,初始化事务会把epoch递增1,从而把拥有旧epoch的Producer给fence掉。
- 而事务超时时,不仅会把事务abort掉,还会把该事务ID对应的epoch值递增1,从而把当前Producer给fence掉,认为当前Producer已经无法正常工作了。
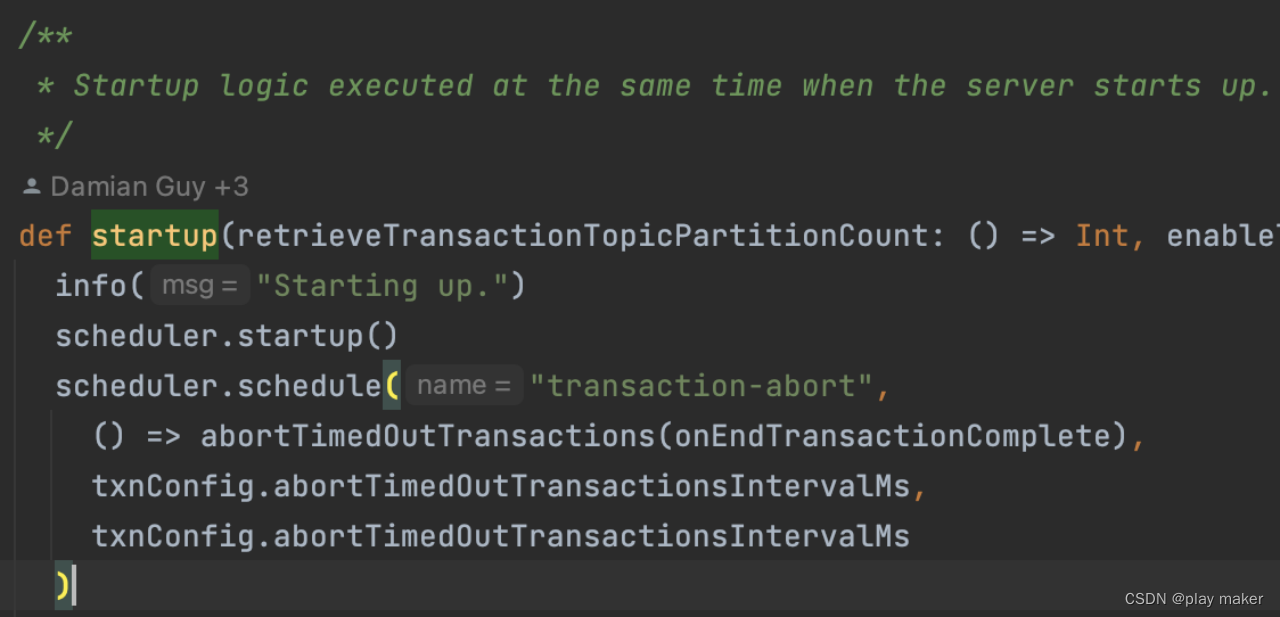
kafka.coordinator.transaction.TransactionCoordinator#abortTimedOutTransactions
kafka.coordinator.transaction.TransactionMetadata#prepareFenceProducerEpoch
看如下测试代码:
/** will throw org.apache.kafka.common.errors.ProducerFencedException:
* There is a newer producer with the same transactionalId which fences the current one.
* Broker will abort the timeout txn and increment epoch to fence current producer, so
* ProducerFencedException will be thrown.
*/
@Test
public void testCommitTimeoutTxn() {
try {
printProducerIdAndEpoch();
kafkaProducer.beginTransaction();
String message = "Hello, Kafka";
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, message);
kafkaProducer.send(record);
// check timeout txn in broker every DefaultAbortTimedOutTransactionsIntervalMs, default 10s.
Thread.sleep(TRANSACTION_TIMEOUT_IN_MS + 25000);
kafkaProducer.commitTransaction();
} catch (Exception ex) {
System.out.println(ex);
Assertions.fail("Failed to produce message with transaction");
}
}
连续执行两次上面的测试代码,commit一个超时的事务,都抛出了ProducerFencedException报错,观察两次执行时打印的epoch值,发现递增了2,而不是1。这是因为事务超时会递增epoch值一次,第二次执行时初始化事务递增epoch值一次,因此是递增2。


- 因此,kafka commit一个超时的事务,会报ProducerFencedException错误。
- pulsar commit一个超时的事务,会报InvalidTxnStatusException错误,Pulsar客户端侧还有一个定时任务,达到事务超时时间时会自动把事务状态转换成TIME_OUT,此时客户端调用abort、commit方法都会直接报InvalidTxnStatusException错误,无法发送请求出去。
checkpoint中保存的事务信息
- kafka中会保存transactionalId、producerId、epoch三个信息。
org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.KafkaTransactionState
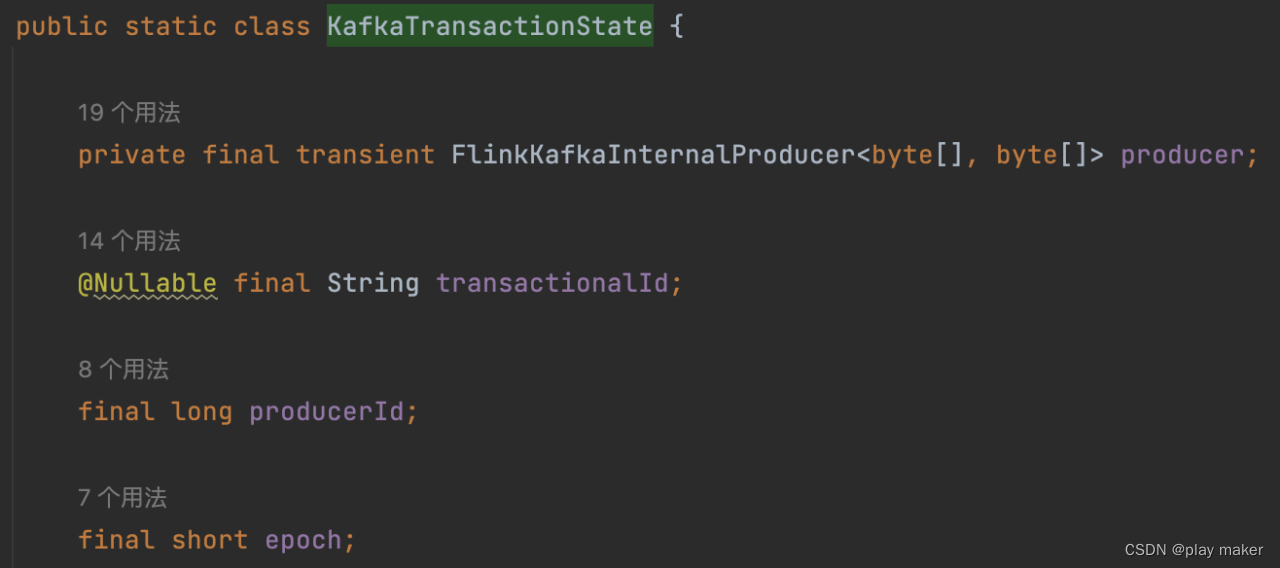
transactionalId与producerId是一对一的,几乎不会变。根据前面内容可知,epoch可能递增。
事实上,因为kafka transactionalId的设计,一旦一个事务的元数据被新的事务覆盖,则不可能再对旧的事务进行commit、abort操作,连请求都发不出来。commit请求中包含了transactionalId、producerId、epoch三个信息,如果新事务覆盖了旧事务,commit请求中的三个信息可能还是相同的(除了epoch可能会变)。比如说,(1,1,1)对应三个信息,事务txn1被新事务txn2覆盖了,但是对txn1、txn2的commit请求中包含的信息都是(1,1,1)。而如果txn1与txn2之间发生了epoch递增,则变成了txn1对应(1,1,1),txn2对应(1,1,2)。此时就能区分出旧事务txn1了,flink也是采用这种方式来记住一个旧事务,因此checkpoint中包含了epoch信息。此时commit请求如果包含(1,1,1),则会报错ProducerFencedException。
因为上面的关系,Flink Kafka Connector在重启任务执行recoverAndCommit方法时,不会调用kafkaProducer.initTransactions()来初始化事务(避免递增epoch),而是读取checkpoint里的transactionalId、producerId、epoch三个信息,然后直接通过反射来设置好,直接发送commit请求。测试代码testCommitOldTxnSuccess模拟了这个过程。
static void printProducerIdAndEpoch() {
Object transactionManager = getField(kafkaProducer, "transactionManager");
System.out.println(getField(transactionManager, "producerIdAndEpoch"));
}
public static void initWithoutInit() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_ADDRESS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, CLIENT_ID);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "kafka_producer_id");
props.put(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, TRANSACTION_TIMEOUT_IN_MS);
kafkaProducer = new KafkaProducer<>(props);
// kafkaProducer.initTransactions();
}
public void commitUnit() {
printProducerIdAndEpoch();
kafkaProducer.beginTransaction();
String message = "Hello, Kafka";
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, message);
kafkaProducer.send(record);
kafkaProducer.commitTransaction();
printProducerIdAndEpoch();
}
/**
* commit old transaction to simulate roll back to older checkpoint.
* As epoch do not increment,commit an older transaction will succeed.
*/
@Test
public void testCommitOldTxnSuccess() {
try {
commitUnit();
// do a checkpoint to save producerId,transactionalId,epoch
Object transactionManager = getField(kafkaProducer, "transactionManager");
Object producerIdAndEpoch = getField(transactionManager, "producerIdAndEpoch");
commitUnit();
commitUnit();
// restart instances.
cleanup();
// do not init transaction to avoid epoch incrementation.
// init();
initWithoutInit();
// configure producerIdAndEpoch from checkpoint with refection instead of
// calling kafkaProducer.initTransactions()
transactionManager = getField(kafkaProducer, "transactionManager");
setField(transactionManager, "producerIdAndEpoch", producerIdAndEpoch);
// set txn state
setField(transactionManager, "currentState", getEnum(
"org.apache.kafka.clients.producer.internals.TransactionManager$State.IN_TRANSACTION"));
setField(transactionManager, "transactionStarted", true);
// commit old transaction.
printProducerIdAndEpoch();
kafkaProducer.commitTransaction();
printProducerIdAndEpoch();
} catch (Exception ex) {
System.out.println(ex);
Assertions.fail("Failed to produce message with transaction");
}
}
org.apache.flink.streaming.connectors.kafka.internals.FlinkKafkaInternalProducer#resumeTransaction
- pulsar中只需包含事务ID即可。
由于pulsar中事务ID无法复用,因此没有那么多复杂的情况。
org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSinkBase.PulsarTransactionState
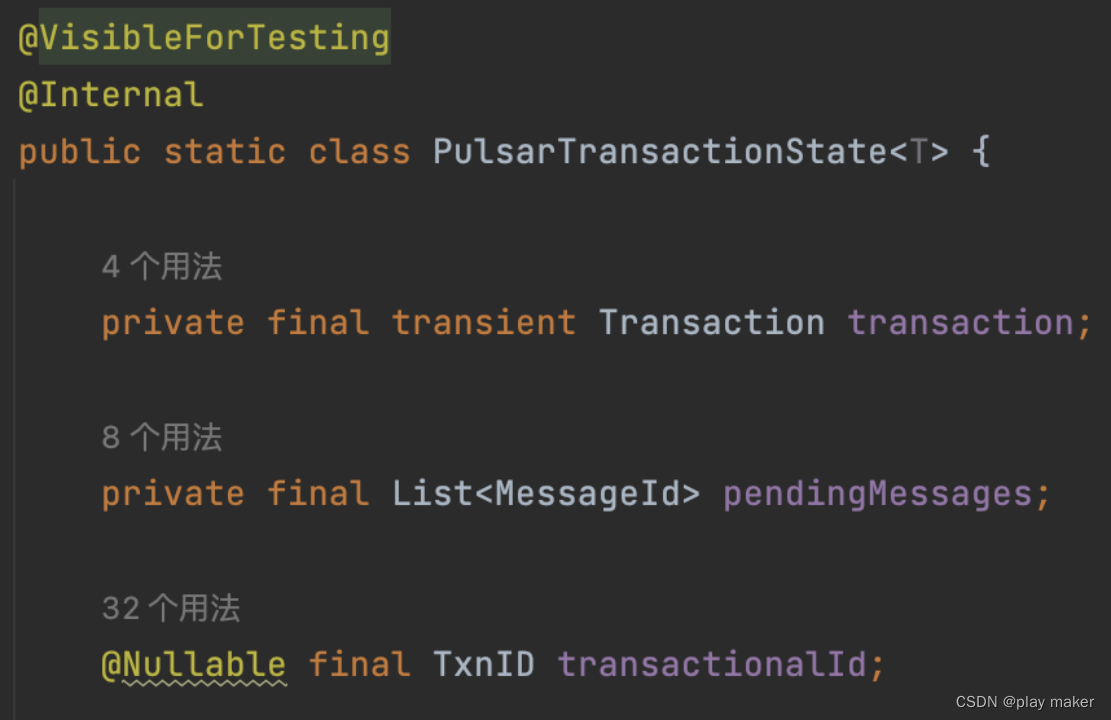
字段pendingMessages其实可以去掉。
方案及分析
Kafka方案:支持不完全的commit操作幂等性+忽略极端情况的报错
根据前面的分析,Flink+Kafka是支持对最后一个事务进行重复commit的,这算是不完全的commit操作幂等性。实际上,Flink在大多数情况下都只需要commit最后一个事务,因此这种方案能hold住大多数情况。
下面分析一些极端情况:
- 长时间宕机
为了避免broker或者flink长时间宕机,导致一个commit请求都没到达过broker,从而导致事务自动超时aborted,最终导致丢数,FlinkKafkaProducer将事务超时时间默认设置为1h,从而能允许宕机一个小时的情况。由前面超时机制的分析,kafka在broker侧的transaction.max.timeout.ms配置会限制客户端配置的事务超时时间大小,默认最大为15min,因此必须要配置kafka broker的transaction.max.timeout.ms配置大于1h,从而允许客户端配置事务超时时间transaction.timeout.ms为1h。

- 回滚到更旧的checkpoint
回滚到更旧的checkpoint M,而不是最后一个checkpoint N。要想触发问题,根据前面分析可知:- 得要M对应的事务ID IDm发生了事务状态覆盖。即:假设事务ID IDm对应了两个事务txn1、txn2,txn1是checkpoint M包含的,txn2是后来复用IDm新创建的事务,导致txn1的事务元数据被覆盖了。
- 还要,事务ID号 IDm 对应的epoch发生了递增,即触发事务超时或者重启flink任务。
这个时候会报ProducerFencedException错误,如果不管的话显然是会发生无限重启任务的问题。
Kafka的fix方案是:当recoverAndCommit方法报错,某些报错类型会直接忽略commit请求的失败,这样就会接着执行Flink任务了,避免无限重启。
FlinkKafkaProducer#recoverAndCommit
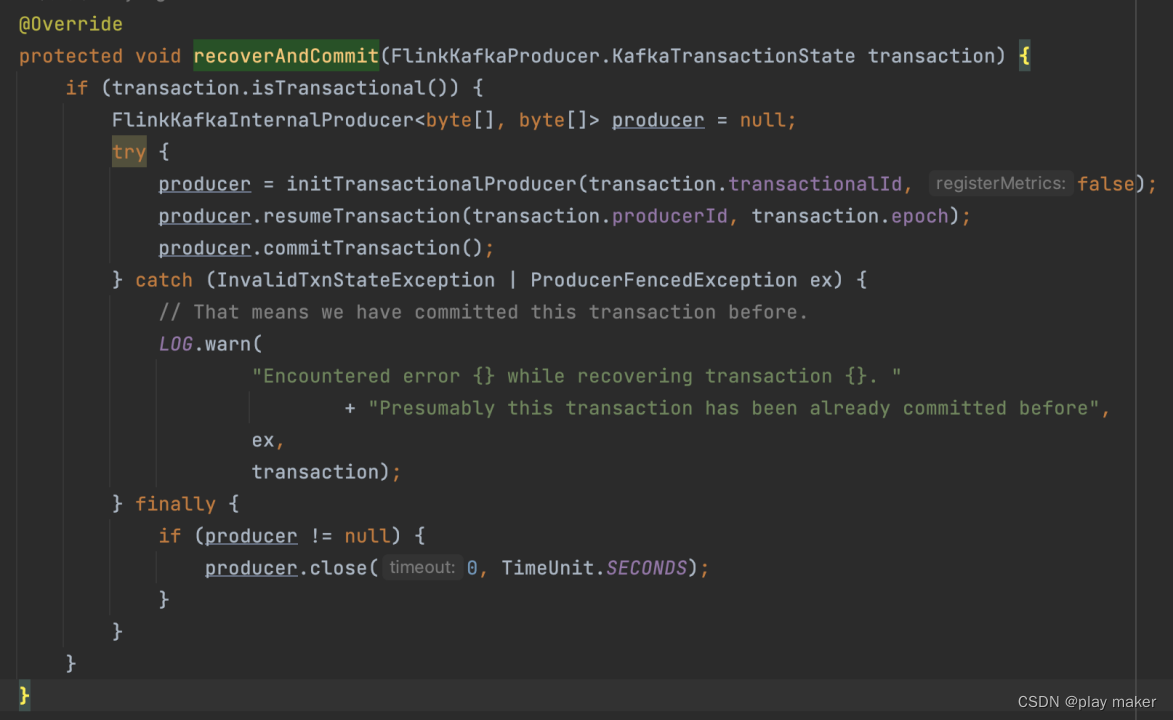
这里忽略了InvalidTxnStateException 、ProducerFencedException两种报错。
- InvalidTxnStateException
由方法logInvalidStateTransitionAndReturnError来生成,这个方法只在kafka.coordinator.transaction.TransactionCoordinator#endTransaction中调用到。 - ProducerFencedException
由前面分析可知,commit一个超时的事务或者回滚到一个旧的checkpoint也有机率会报这个错误。
因此,无限重启的问题肯定不会出现了。
但是忽略报错的方案依赖于:事务在broker侧是成功committed,如果是aborted就丢数了。
下面再分析会不会丢数:
-
如果是事务超时导致的ProducerFencedException,由前面分析知事务超时时间已经设成了1h了,除非宕机时间超过1h才有一点点概率会aborted,否则1h内肯定足够发送commit请求到达broker。就算宕机时间超过1h,要发生丢数问题也是很微弱的,因为得要宕机的时间点刚好在:前面发送消息都没报错,pre commit阶段完成进入commit阶段之后,并且在commit阶段发送commit请求给broker之前。这个时间空隙是很小很小的,因为进入commit阶段就会立马发送commit请求了,没有耗时操作。
-
如果是回滚到一个旧的checkpoint,那么它对应的事务在broker侧肯定是committed的,如果是aborted那么根本不会开启新的事务,而是直接重启flink任务了。这一点根据数学归纳法也可以证明出来。
综上所述:几乎不会发生丢数。
但是,回滚到到一个比较旧的checkpoint,会导致数据重复。比如说当前是checkpoint N,回滚到checkpoint N-5,回滚checkpoint可以把source端的offset给重置回去,但是不能把sink端已经生产的消息给删除掉,因此checkpoint N-5到checkpoint N之间生产的消息会发生重复。
但Flink侧回滚到到一个比较旧的checkpoint是极端极端的情况了,就算真发生了,根据这里的分析可知也影响不大,不至于导致丢数。
Pulsar方案 - 事务commit幂等性
根据前面的分析,Flink Kafka Connector当前提供的保证是相当强的,Pulsar侧提供的保障则相当地弱了。
而看回Flink对外部系统的要求:1. 提供事务功能 2. 事务commit操作要保证幂等性。因此要对Pulsar进行改造,方向也是让Pulsar的commit支持幂等性。
因此,接下来的各个方案之间,区别仅在于如何实现事务commit的幂等性。
方案1 - 保存事务元数据一定的时间
这个方案已经实现完成,并经过测试了,但是有缺陷,见下面分析。
https://github.com/apache/pulsar/pull/19662
当前pulsar是事务一完成(committed或aborted)就立刻删除元数据了,因此无法支持事务commit的幂等性。因此,很自然的想法就是不立马删除元数据,继续在内存里保存一段时间,因为客户端只会在transaction.timeout.ms时间内才能发送请求到broker,因此在内存中保存transaction.timeout.ms这么长时间就足够了。
缺点:
- 事务元数据的持久化是靠TC log来实现的,如果事务完成时不立马删除元数据,那么该事务对应的所有tc log entry都要延迟删除,如果事务超时时间设置为1h,那么TC recovery时就得扫描前1h生产的tc log entry,这会大大拉长TC recovery时间,造成较长不可用时间。
- 如果事务并发量突增,而事务超时时间又没发生变化,那么事务元数据占用的内存大小就可能突增,造成频繁GC,这是不可控的,因为随着集群的使用,事务流量不断增大,事务并发量也不断增大,内存占用问题会越来越突出。
方案2 - 保存指定数目的事务元数据
增加broker配置:
#每个TC为每个客户端维护的N个已结束的事务状态
TransactionMetaPersistCount=10
# 为每个客户端维护已结束的事务状态的最长时间,避免客户端长时间不用导致数据不清理。
TransactionMetaPersistTimeInHour=72
客户端增加配置ClientName,类似于ProducerName,要用户保证唯一性。如果client只使用一个Producer,则可以让ClientName=ProducerName。
方案:
- TC维护一个Map<ClientName,LinkedList>,维护每个客户端最新N个事务的状态,事务结束时,会把事务元数据写入这个List里,同时写入一个Compacted topic(__terminated_txn_state)里持久化,Compacted topic的key循环遍历 ClientName-0,…, ClientName-(N-1),从而能自动删除旧的事务元数据。(或者为了保证逻辑简单清晰,使用一条消息来存储N个事务元数据,Key为ClientName即可,这样可以很简单地应对客户端动态更新N值的情况)
- TC recovery时从Compacted topic里恢复维护的事务状态信息。
分析:
- TC recovery时不会大量增加扫描事务日志的量,避免了读取大量无用的事务日志entry,只需精准读取Compacted topic里的数据,提高tc recovery效率。
- 内存占用大小可控,根据需求及内存情况来配置。一般flink一个checkpoint只使用一个事务,就算考虑到执行checkpoint是异步的,可能会同时有多个checkpoint执行,事务的并发数目也很小。
注记:可以进一步优化,可以只保留aborted的事务状态,committed状态的事务不用保留,那么如果找不到事务元数据时,默认是committed的事务。但是这样的话会隐藏掉可能丢数的风险,因此暂不采用。