一、新建一个Scrapy项目daimg
scrapy startproject daimg二、进入该项目并创建爬虫文件daimgpc
cd daimg
scrapy genspider daimgpc www.xxx.com
三、修改配置文件settings.py
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"四、进入爬虫文件,编写代码
1、指定要爬取的网站
start_urls = ["http://www.XXXXXcom/photo/world/"]2、解析该页面获取,获取详情页网址和图片名称
列表= response.xpath('/html/body/div[5]/ul/li')
for i in 列表:
标题=i.xpath('./a/@title').extract_first()+'.jpg'
详情页=i.xpath('./a/@href').extract_first()3、爬取多页图片标题及详情页
start_urls = ["http://www.XXXX.com/photo/world/"]
多页url模板='http://wwwXXXXXcom/photo/world/list_69_%d.html'
if self.页码<4:
新url=format(self.多页url模板%self.页码)
self.页码+=1
yield scrapy.Request(url=新url,callback=self.parse)4、解析详情页,获取图片链接
yield scrapy.Request(url=详情页,callback=self.详情页解析)
def 详情页解析(self,response):
图片地址=response.xpath('/html/body/div[4]/div[1]/ul[2]/img/@src').extract_first()
print(图片地址)5、将图片地址和图片名称声明到items
图片名称 = scrapy.Field()
图片地址 = scrapy.Field()6、将DaimgTiem函数导入爬虫文件
from ..items import DaimgItem7、将图片地址和图片名字保存到itme对象,并提交给管道处理
itme对象=DaimgItem()
itme对象['图片名称']=标题
yield scrapy.Request(url=详情页,callback=self.详情页解析,meta={'item':itme对象})
meta=response.meta
item=meta['item']
item['图片地址']=图片地址
yield item8、管道文件编写
from scrapy.pipelines.images import ImagesPipeline
class DaimgPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
请求地址=item['图片地址']
yield scrapy.Request(url=请求地址,meta={'名称':item['图片名称']})
def file_path(self, request, response=None, info=None, *, item=None):
保存名称=request.meta['名称']
return 保存名称
def item_completed(self, results, item, info):
return item9、配置文件填写保存的文件夹
IMAGES_STORE='aiyou'10、开启管道
ITEM_PIPELINES = {
"daimg.pipelines.DaimgPipeline": 300,
}五、运行爬虫文件
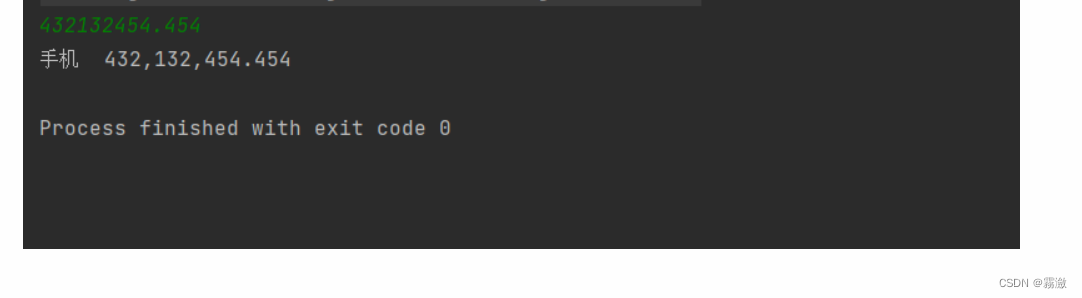
scrapy crawl daimgpc六、运行结果

七、提高效率设置
1、线程数量,默认16
CONCURRENT_REQUESTS = 322、禁止cookies
COOKIES_ENABLED = False3、禁止重试
RETRY_ENABLED = False4、设置超时时间
DOWNLOAD_TIMEOUT = 10