centos7环境下:DolphinScheduler3.1.5简介和伪集群模式安装部署
DolphinScheduler简介
Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
伪集群部署目的是在单台机器部署 DolphinScheduler 服务,该模式下master、worker、api server 都在同一台机器上
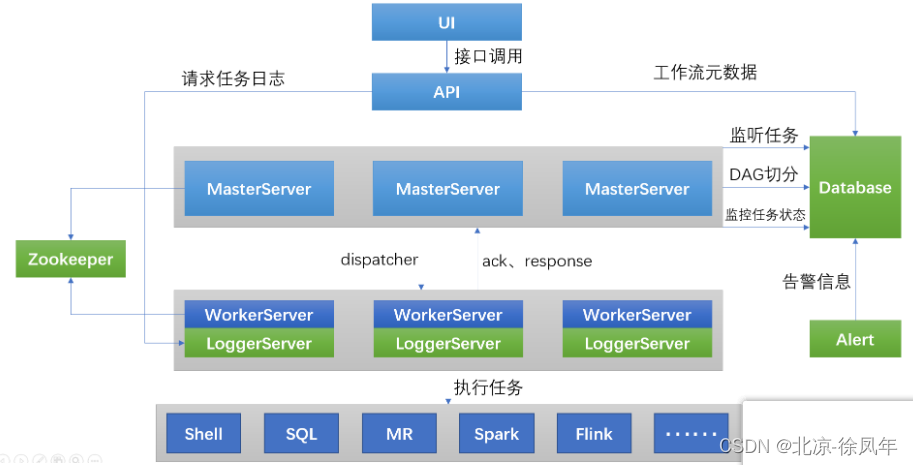
DolphinScheduler核心架构
DolphinScheduler的主要角色如下:
MasterServer 采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交、任务监控,并同时监听其它MasterServer和WorkerServer的健康状态。
WorkerServer 也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。
ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。
Alert服务,提供告警相关服务。
API接口层,主要负责处理前端UI层的请求。
UI,系统的前端页面,提供系统的各种可视化操作界面。
1. 1集群规划
集群模式下,可配置多个Master及多个Worker。通常可配置2~3个Master,若干个Worker。由于集群资源有限,此处配置一个Master,一个Worker,集群规划如下。
hadoop master、worker
1.2 前置准备工作(文档在我博客,资源我都上传了)
(1)节点均需部署JDK(1.8+),并配置相关环境变量。附上我的博客链接:http://t.csdn.cn/TFgeQ
(2)需部署数据库,支持MySQL(5.7+)或者PostgreSQL(8.2.15+)。两者任选其一即可,如 MySQL 则需要 JDBC Driver 8.0.16
附上我的博客链接:http://t.csdn.cn/9BVap
(3)需部署Zookeeper(3.4.6+)。附上我的博客链接:http://t.csdn.cn/1can4
#(4)如果启用 HDFS 文件系统,则需要 Hadoop(2.6+)环境。
(5)节点均需安装进程树分析工具psmisc。
CentOS 7上离线安装psmisc,可以按照以下步骤进行操作:
上传psmisc包。或者直接使用yum命令下载都可以。(所有的ds安装包我已经上传,免费下载)
在目标CentOS 7计算机上,使用以下命令进行安装:
rpm -ivh psmisc-22.20-16.el7.x86_64.rpm
安装完成后,通过以下命令验证psmisc是否安装成功:
rpm -qa | grep psmisc
或者yum安装
sudo yum install -y psmisc
Yum时可能出现下面错误
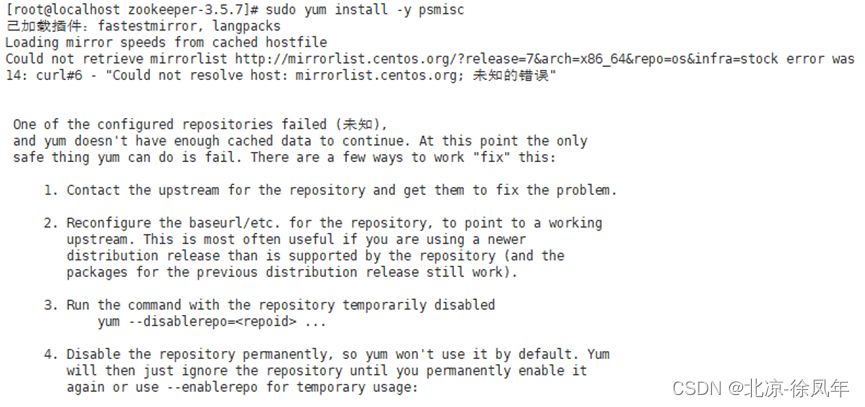
原因:没有配置resolv.conf
解决办法:
到/etc目录下配置resolv.conf加入nameserver IP,如:
nameserver 8.8.8.8
nameserver 8.8.4.4
search localdomain
保存再次运行上面的命令就可以。
2.1准备 DolphinScheduler 启动环境
配置用户免密及权限
创建部署用户,并且一定要配置 sudo 免密。以创建 dolphinscheduler 用户为例
# 创建用户需使用 root 登录
useradd dolphinscheduler
# 添加密码
echo "dolphinscheduler" | passwd --stdin dolphinscheduler
# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-*-bin
• 因为任务执行服务是以 sudo -u {linux-user} 切换不同 linux 用户的方式来实现多租户运行作业,所以部署用户需要有 sudo 权限,而且是免密的。初学习者不理解的话,完全可以暂时忽略这一点
• 如果发现 /etc/sudoers 文件中有 “Defaults requirett” 这行,也请注释掉
2.2免密操作
附上我之前的博客地址:http://t.csdn.cn/IIe29
3.1 解压DolphinScheduler安装包
(1)上传DolphinScheduler安装包到hadoop节点的/opt/software目录
(2)解压安装包到当前目录
3.2 创建元数据库及用户
DolphinScheduler 元数据存储在关系型数据库中,故需创建相应的数据库和用户。
(1)创建数据库
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
(2)创建用户
mysql> CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
注:
若出现以下错误信息,表明新建用户的密码过于简单。
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
可提高密码复杂度或者执行以下命令降低MySQL密码强度级别。
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
(3)赋予用户相应权限
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> flush privileges;
3.3修改相关配置
完成基础环境的准备后,需要根据你的机器环境修改配置文件。配置文件可以在目录 bin/env 中找到,他们分别是 并命名为 install_env.sh 和 dolphinscheduler_env.sh。
修改 install_env.sh 文件
ips="192.168.2.221"
sshPort=“22”
masters="192.168.2.221"
workers="192.168.2.221:default"
alertServer="192.168.2.221"
apiServers="192.168.2.221"
installPath="/opt/module/dolphinscheduler-3.1.5"
deployUser="root"
zkRoot="/dolphinscheduler"
dolphinscheduler_env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
export DATABASE="mysql"
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.2.221:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"
export SPRING_DATASOURCE_USERNAME="root"
export SPRING_DATASOURCE_PASSWORD="root"
export SPRING_CACHE_TYPE="none"
export SPRING_JACKSON_TIME_ZONE="Asia/Shanghai"
export MASTER_FETCH_COMMAND_NUM="10"
export REGISTRY_TYPE="zookeeper"
export REGISTRY_ZOOKEEPER_CONNECT_STRING="192.168.2.221:2181"
将mysql驱动复制到包括 api-server/libs 和 alert-server/libs 和 master-server/libs 和 worker-server/libs和tools/libs(注意一定是五个地方)
[root@localhost software]# cp mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler-3.1.5/api-server/libs/
[root@localhost software]# cp mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler-3.1.5/alert-server/libs/
[root@localhost software]# cp mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler-3.1.5/master-server/libs/
[root@localhost software]# cp mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler-3.1.5/worker-server/libs/
[root@localhost software]# cp mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler-3.1.5/tools/libs/
完成上述步骤后,您已经为 DolphinScheduler 创建一个新数据库,现在你可以通过快速的 Shell 脚本来初始化数据库
bash tools/bin/upgrade-schema.sh
4.1启动 DolphinScheduler
使用上面创建的部署用户运行以下命令完成部署,部署后的运行日志将存放在 logs 文件夹内
bash ./bin/install.sh
注意: 第一次部署的话,可能出现 5 次sh: bin/dolphinscheduler-daemon.sh: No such file or directory相关信息,此为非重要信息直接忽略即可
4.2登录 DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统UI。默认的用户名和密码是 admin/dolphinscheduler123
4.3启停服务
# 一键停止集群所有服务
bash ./bin/stop-all.sh
# 一键开启集群所有服务
bash ./bin/start-all.sh
# 启停 Master
bash ./bin/dolphinscheduler-daemon.sh stop master-server
bash ./bin/dolphinscheduler-daemon.sh start master-server
# 启停 Worker
bash ./bin/dolphinscheduler-daemon.sh start worker-server
bash ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停 Api
bash ./bin/dolphinscheduler-daemon.sh start api-server
bash ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Alert
bash ./bin/dolphinscheduler-daemon.sh start alert-server
bash ./bin/dolphinscheduler-daemon.sh stop alert-server
注意1:: 每个服务在路径 <service>/conf/dolphinscheduler_env.sh 中都有 dolphinscheduler_env.sh 文件,这是可以为微 服务需求提供便利。意味着您可以基于不同的环境变量来启动各个服务,只需要在对应服务中配置 <service>/conf/dolphinscheduler_env.sh 然后通过 <service>/bin/start.sh 命令启动即可。但是如果您使用命令 /bin/dolphinscheduler-daemon.sh start <service> 启动服务器,它将会用文件 bin/env/dolphinscheduler_env.sh 覆盖 <service>/conf/dolphinscheduler_env.sh 然后启动服务,目的是为了减少用户修改配置的成本.
注意2::服务用途请具体参见《系统架构设计》小节。Python gateway service 默认与 api-server 一起启动,如果您不想启动 Python gateway service 请通过更改 api-server 配置文件 api-server/conf/application.yaml 中的 python-gateway.enabled : false 来禁用它。
官方部署手册地址:https://www.bookstack.cn/read/dolphinscheduler-3.1.0-zh/bf5533c107dc1904.md#
部署环境一定一定去看官网,遇到问题回来看个人写的笔记。官方爸爸才是正解。