近期工作遇到了excel数据灌入数据库表的任务,无聊整理一下实现方法:
System.out.println("=======分割线======");
文章目录
- 1、使用数据库管理工具
- 2、使用SQL
- 3、使用脚本
1、使用数据库管理工具
首先是使用工具来完成,常见的比较成熟的数据库管理软件都有这个功能,MySQL Workbench、Navict、DataGrip、DBeaver。这里拿DBeaver举例:
-
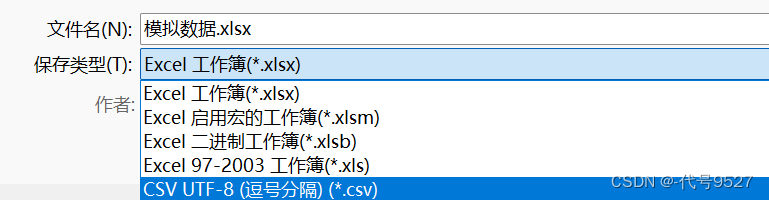
将excel另存为csv格式,选择编码为UTF-8
-
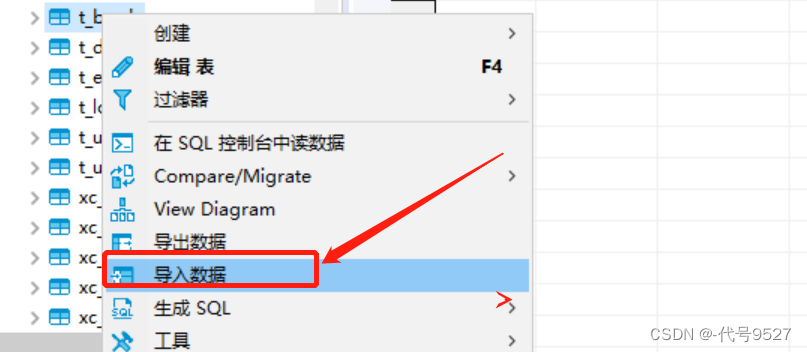
右键要导入的表,选择导入数据
-
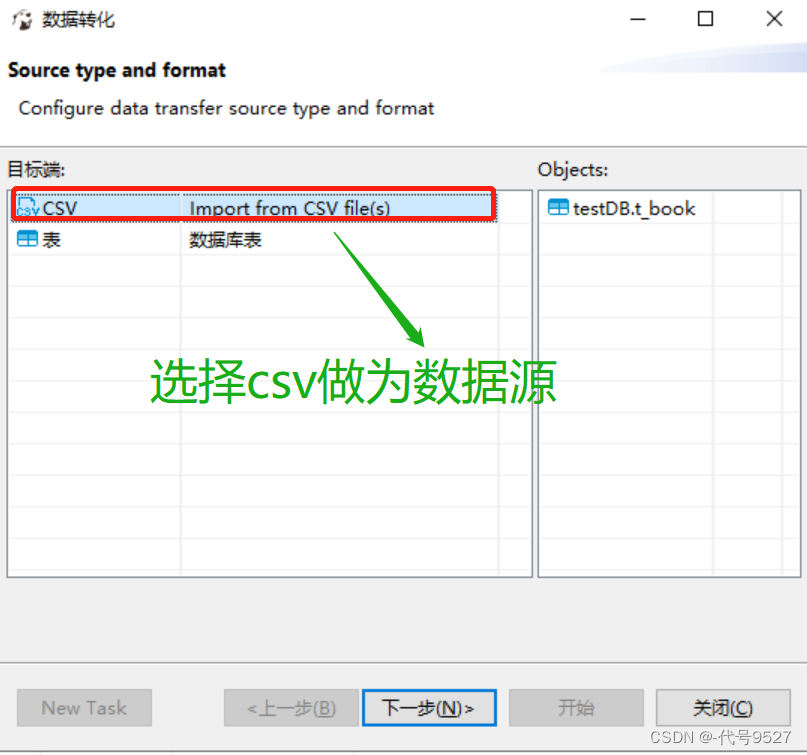
选择csv做为数据源,点击下一步
-
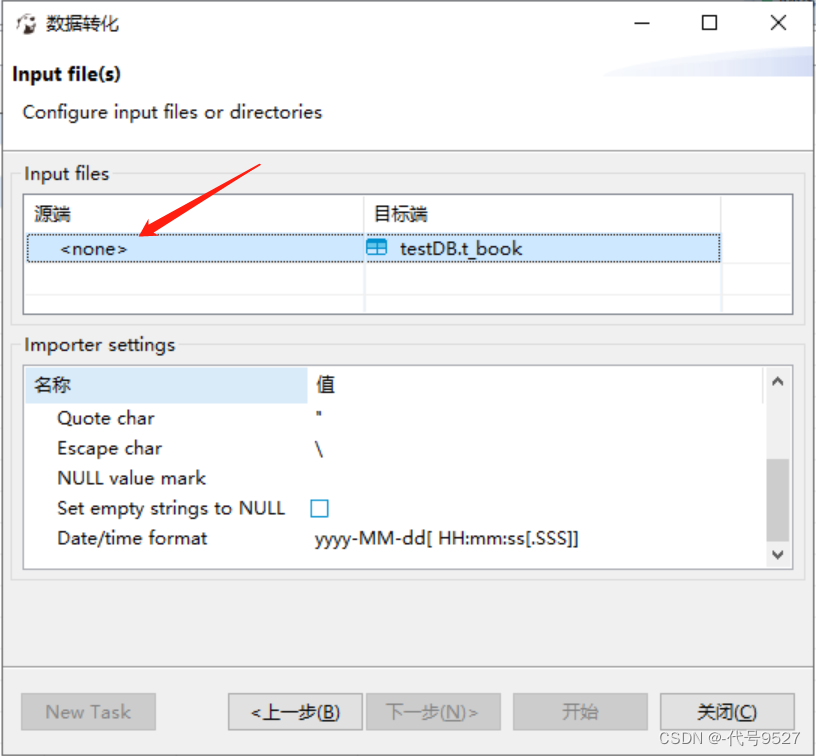
点击选择csv文件
-
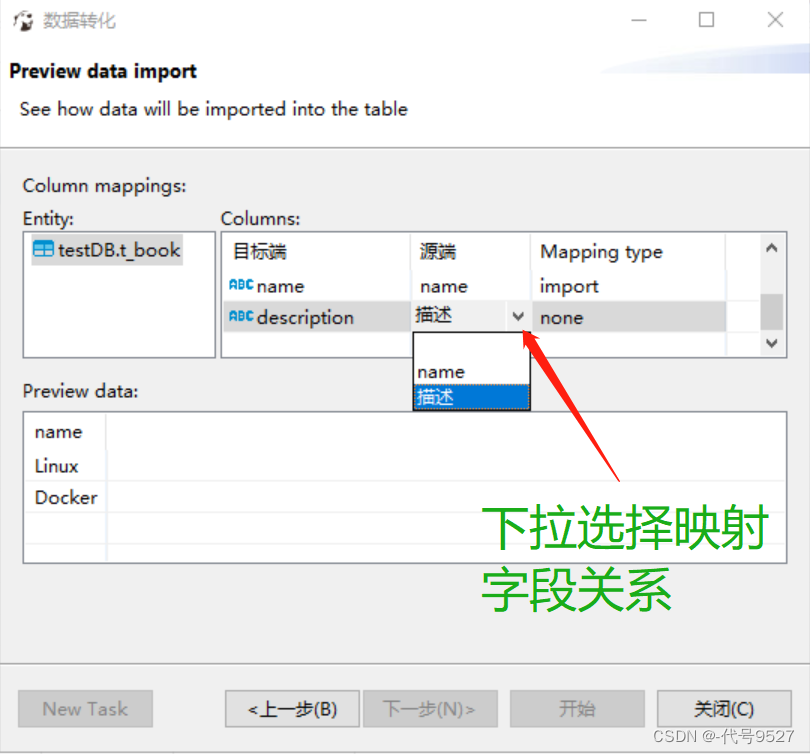
下拉选择excel字段与MySQL字段映射关系
-
点击开始,F5刷新即可看到新数据
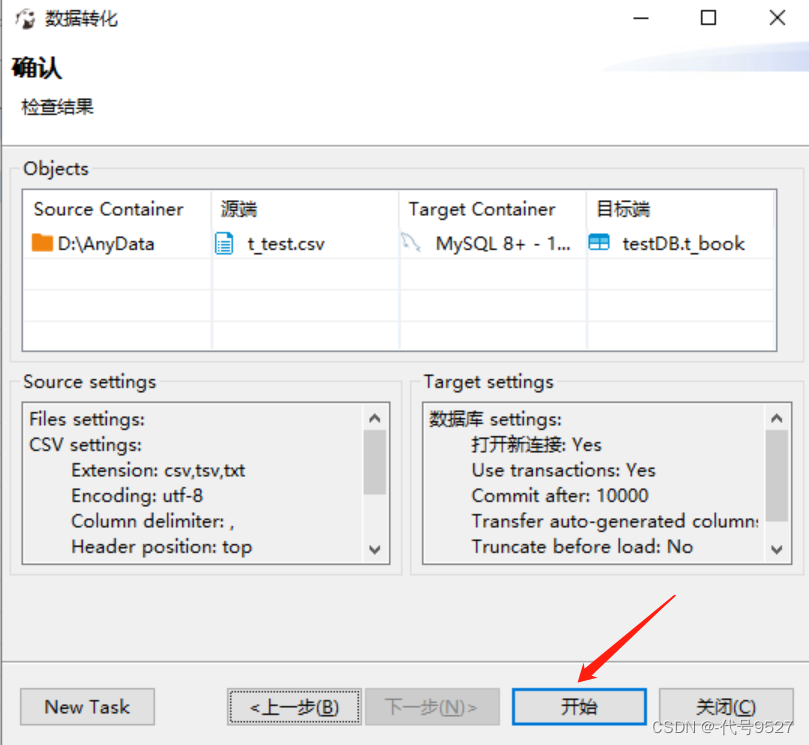
2、使用SQL
- excel转csv,逗号分隔,utf-8格式
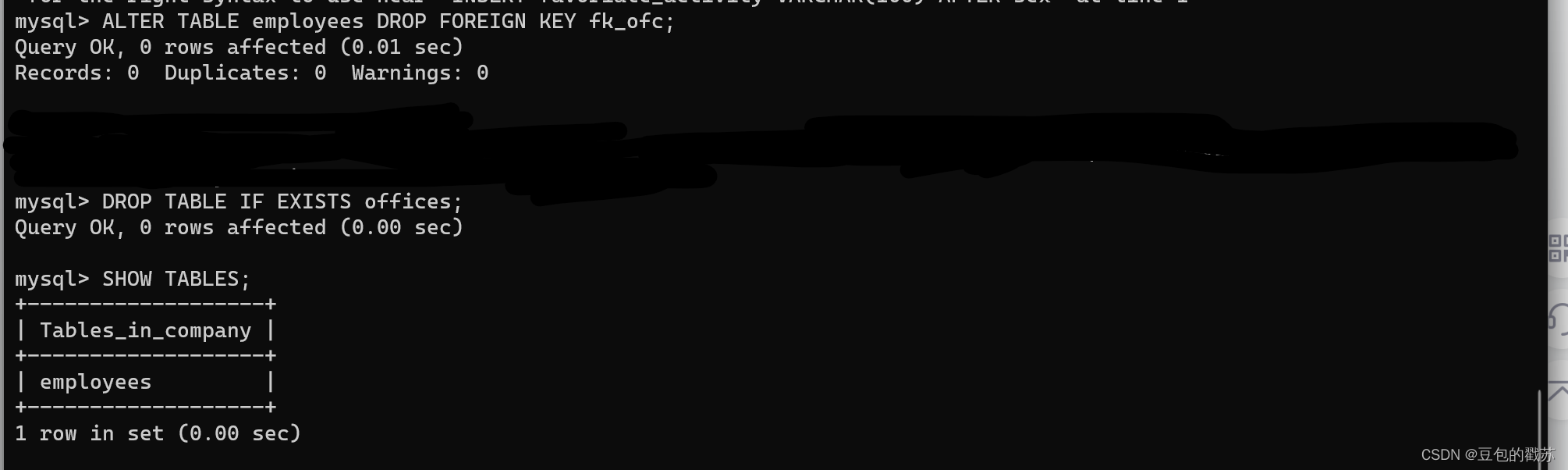
- 连接数据库执行以下SQL
load data local infile 'd:/test.csv'
into table testDB.t_book
fields terminated by ',';
# 注意这时excel中列的顺序和表的字段顺序是刚好对应的
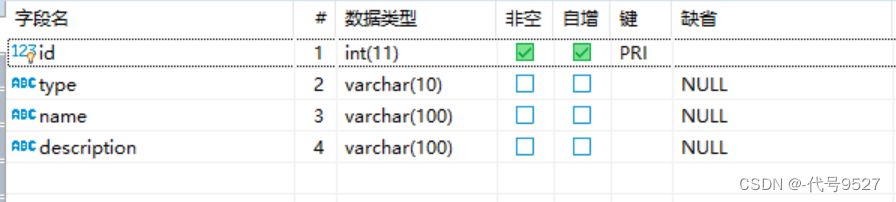
- 注意当excel和table字段不对应时,按照csv文件表头顺序写sql
load data local infile 'd:/test.csv'
into table testDB.t_book
fields terminated by ','
lines terminated by '\r\n'
ignore 1 lines (name,description);
# 即csv文件的第一列给数据库表的name字段,第二列给表的description字段
# 其余字段不管
比如我excel只有name和description两列数据,而库表中要四个字段,只管按csv的顺序分给表中的字段即可,其余字段没有就空着,不用管。

有的可视化数据库连接工具不支持load data local infile指令,换个命令行窗口执行SQL就行。

3、使用脚本
import pymysql #PyMySQL是在 Python3.x 版本中用于连接 MySQL 服务器的一个库
import pandas as pd #Pandas是Python的一个数据分析包 导入panda命名为pd
from sqlalchemy import create_engine # 导入引擎
file = r'd:/t_test.xlsx' #文件
df = pd.read_excel(file) #读文件
# 连接数据库
engine = create_engine("mysql+mysqlconnector://root:qwe123@localhost:3306/testDB")
df.to_sql('t_book',con=engine,if_exists='replace',index=False) #导入数据库,如果存在就替换
代码注释(参数):
engine = create_engine('dialect+driver://username:password@host:port/database')
dialect: 数据库类型
driver: 数据库驱动选择
username: 数据库用户名
password: 用户密码
host: 服务器地址
port: 端口
database: 数据库
if_exists='replace': 如果存在就替换
if_exists='append': 如果存在就追加
相反的,SQL导出到excel:
from sqlalchemy import create_engine
import pandas as pd
# 创建数据库连接
engine = create_engine('mysql+pymysql://root:passwd@localhost:port/testDB')
# 读取mysql数据
db = pd.read_sql(sql='select * from testDB.t_book', con=engine)
# 导出数据到excel
db.to_excel('data.xlsx')