链表学习
- 一、 缓存
- 1.1缓存介绍
- 1.2 缓存策略
- 二、链表结构
- 2.1 单链表
- 2.2 循环链表
- 2.3 双向链表
- 2.4 双向循环链表
- 2.5 链表与数组性能对比
- 三、如何基于链表实现LRU缓存淘汰算法
一、 缓存
1.1缓存介绍
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等
1.2 缓存策略
- 大小有限,当缓存被用满时,哪些数据应该被清理掉,哪些数据又应该保留呢?
- 先进先出策略 FIFO
- 最少使用策略 LFU
- 最近最少使用策略LRU
二、链表结构
2.1 单链表
数组结构和链表结构对比
- 数组需要一块连续的内存空间来存储,对内存的要求比较高
- 链表并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用
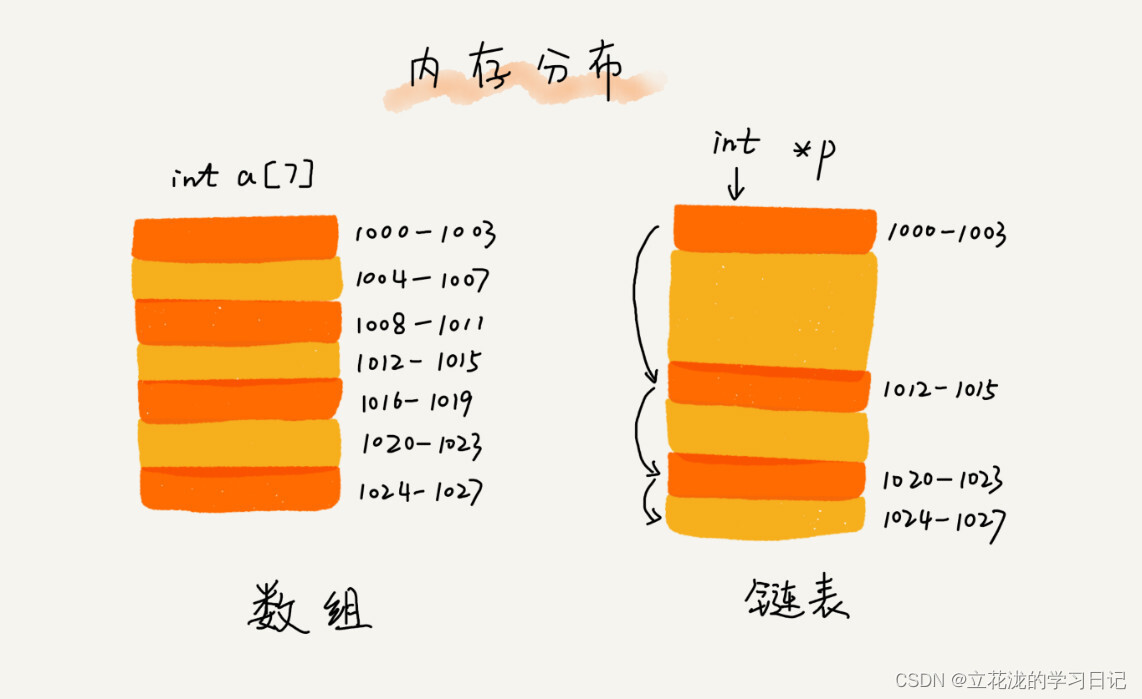
单链表
链表通过指针将一组零散的内存块串联在一起。把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。如图所示,记录下个结点地址的指针叫作后继指针 next

2.2 循环链表
循环链表是一种特殊的单链表。它跟单链表唯一的区别就在尾结点。单链表的尾结点指针指向空地址,表示这就是最后的结点了。而循环链表的尾结点指针是指向链表的头结点。

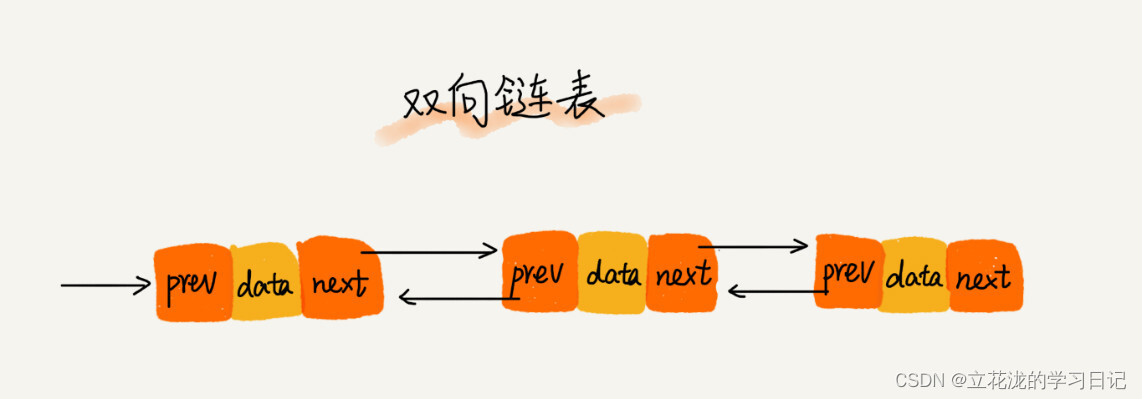
2.3 双向链表
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表,顾名思义,它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点
2.4 双向循环链表

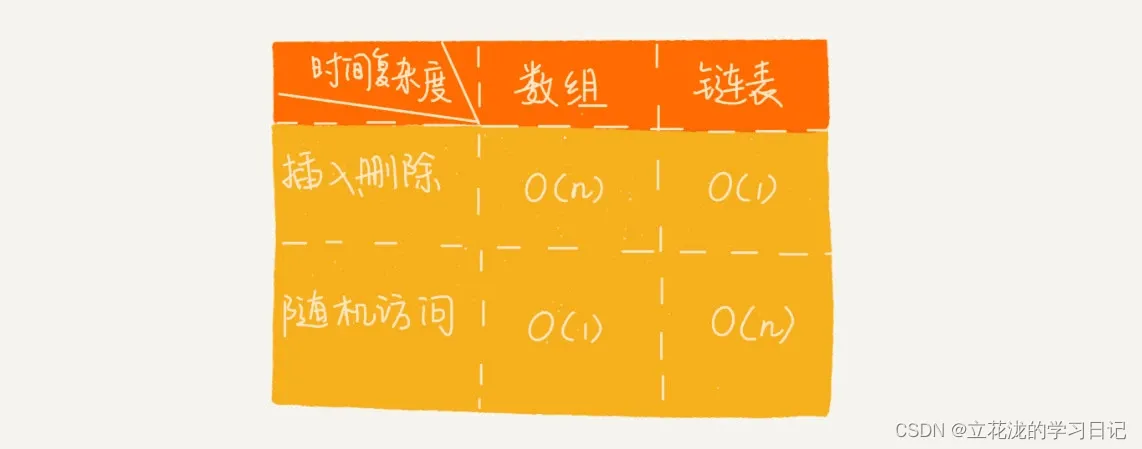
2.5 链表与数组性能对比
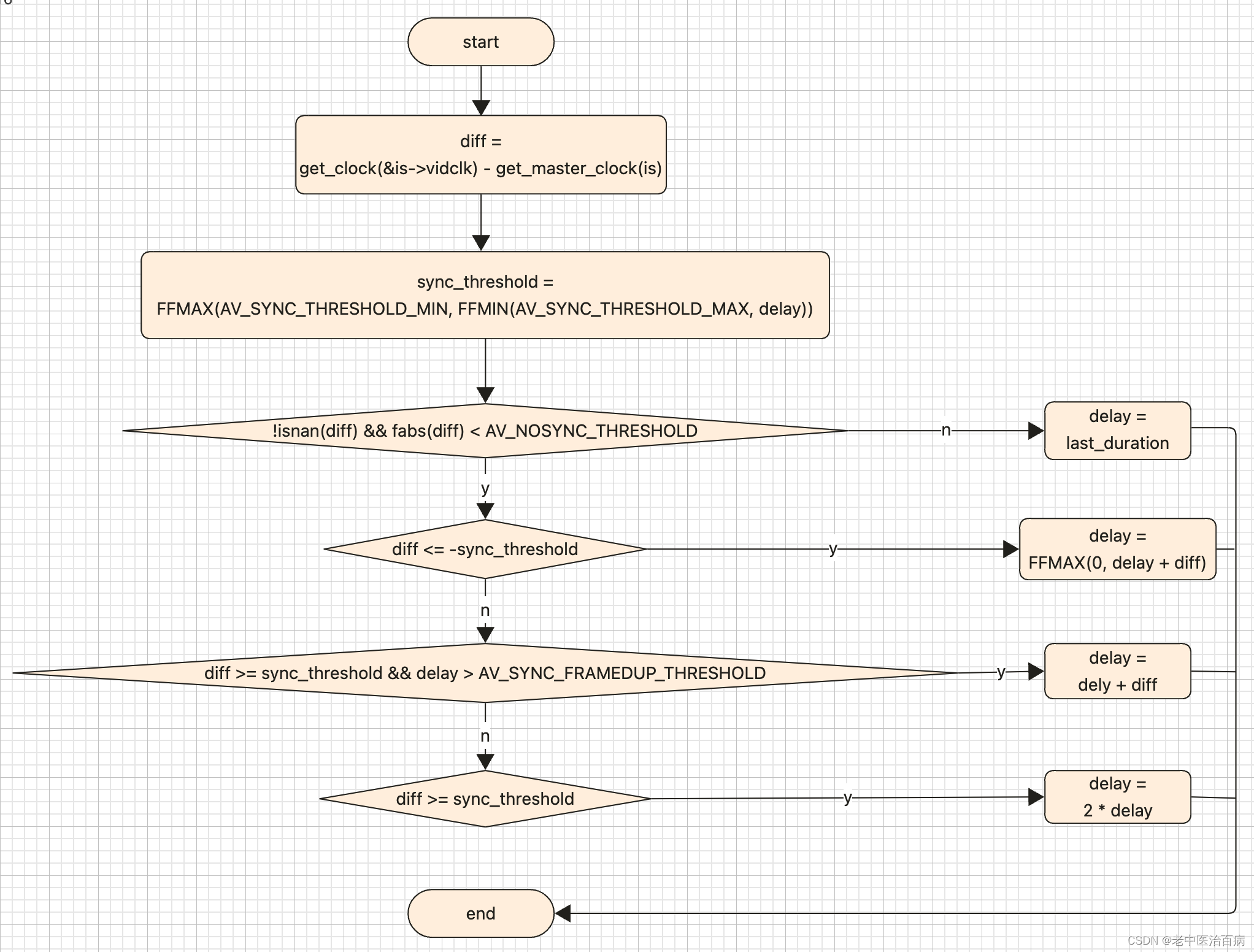
三、如何基于链表实现LRU缓存淘汰算法
维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,从链表头开始顺序遍历链表
-
如果此数据之前已经被缓存在链表中了,遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部
-
如果此数据没有在缓存链表中,又可以分为两种情况:
-
如果此时缓存未满,则将此结点直接插入到链表的头部
-
如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部