文章目录
- 前言
- 1. 引用入门
- 2. 引用作为函数传参
- 3. 引用作为函数返回值
- 4. 引用和指针
- 5. 其他区别
前言
引用是 C++ 的新增内容,在实际开发中会经常使用,它就如同C语言的指针一样重要,但它比指针更加方便和易用,有时候甚至是不可或缺的。
同指针一样,引用能够减少数据的拷贝,提高数据的传递效率。
1. 引用入门
我们知道,参数的传递本质上是一次赋值的过程,赋值就是对内存进行拷贝。所谓内存拷贝,是指将一块内存上的数据复制到另一块内存上。
对于像 char、bool、int、float 等基本类型的数据,它们占用的内存往往只有几个字节,对它们进行内存拷贝非常快速。而数组、结构体、对象是一系列数据的集合,数据的数量没有限制,可能很少,也可能成千上万,对它们进行频繁的内存拷贝可能会消耗很多时间,拖慢程序的执行效率。
C/C++ 禁止在函数调用时直接传递数组的内容,而是强制传递数组指针。而对于结构体和对象没有这种限制,调用函数时既可以传递指针,也可以直接传递内容;但是为了提高效率,建议尽量传递指针。
但是在 C++ 中,有一种比指针更加便捷的传递聚合类型数据的方式,那就是引用(Reference)。
在 C/C++ 中,我们将 char、int、float 等由语言本身支持的类型称为基本类型,将数组、结构体、类(对象)等由基本类型组合而成的类型称为聚合类型。
引用(Reference)是 C++ 相对于C语言的又一个扩充。引用可以看做是数据的一个别名,通过这个别名和原来的名字都能够找到这份数据。引用类似于 Windows 中的快捷方式,一个可执行程序可以有多个快捷方式,通过这些快捷方式和可执行程序本身都能够运行程序;引用还类似于人的绰号(笔名),使用绰号(笔名)和本名都能表示一个人。
引用的定义方式类似于指针,只是用 & 取代了 *,语法格式为:
type &name = data;
其中:
- type 是被引用的数据的类型
- name 是引用的名称
- data 是被引用的数据。
引用必须在定义的同时初始化,并且以后也要从一而终,不能再引用其它数据,这有点类似于常量(const 变量)。
示例如下:
int main()
{
int x = 100;
int& rx = x;
cout << x << " - " << rx << endl;
cout << &x << " - " << &rx << endl;
return 0;
}
运行结果如下:
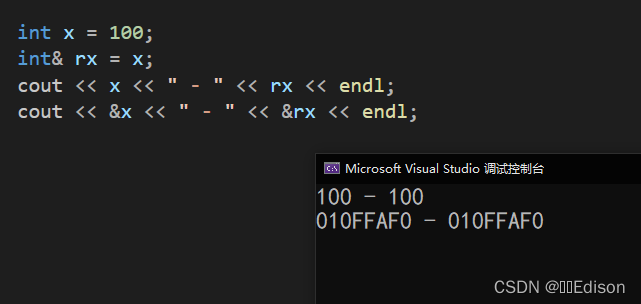
变量 rx 就是变量 x 的引用,它们用来指代同一份数据;也可以说变量 rx 是变量 x 的另一个名字。从输出结果可以看出,x 和 rx 的地址一样,都是 010FFAF0;或者说地址为10FFAF0 的内存有两个名字,x 和 rx,想要访问该内存上的数据时,使用哪个名字都行。
注意,引用在定义时需要添加 &,在使用时不能添加 &,使用时添加 & 表示取地址。除了这两种用法,& 还可以表示位运算中的与运算。
由于引用 rx 和原始变量 x 都是指向同一地址,所以通过引用也可以修改原始变量中所存储的数据,示例如下:
int main()
{
int x = 100;
int& rx = x;
rx = 50;
cout << x << " - " << rx << endl;
return 0;
}
运行结果如下:
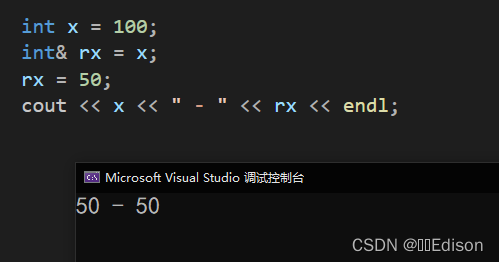
最终程序输出两个 50,可见原始变量 x 的值已经被引用变量 rx 所修改。
如果不希望通过引用来修改原始的数据,那么可以在定义时添加 const 限制,代码格式为:
const type &name = value;
或者:
type const &name = value;
这种加上 const 引用方式叫做:常引用
2. 引用作为函数传参
在定义或声明函数时,我们可以将函数的形参指定为引用的形式,这样在调用函数时就会将实参和形参绑定在一起,让它们都指代同一份数据。如此一来,如果在函数体中修改了形参的数据,那么实参的数据也会被修改,从而拥有 “在函数内部影响函数外部数据” 的效果。
示例代码如下:
//直接传递参数内容
void swap1(int a, int b) {
int temp = a;
a = b;
b = temp;
}
//传递指针
void swap2(int* p1, int* p2) {
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
//按引用传参
void swap3(int& r1, int& r2) {
int temp = r1;
r1 = r2;
r2 = temp;
}
int main()
{
int x = 10, y = 20;
swap1(x, y);
cout << x << " - " << y << endl;
swap2(&x, &y);
cout << x << " - " << y << endl;
swap3(x, y);
cout << x << " - " << y << endl;
return 0;
}
运行结果:
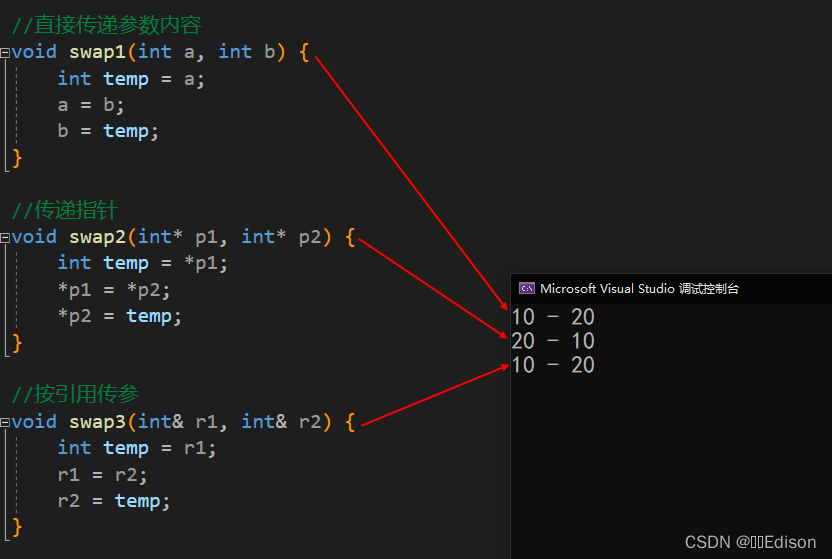
演示了三种交换变量的值的方法:
-
swap1()直接传递参数的内容,不能达到交换两个数的值的目的。对于 swap1() 来说,a、b 是形参,是作用范围仅限于函数内部的局部变量,它们有自己独立的内存,和 x、y 指代的数据不一样。调用函数时分别将 x、y 的值传递给 a、b,此后 x、y 和 a、b 再无任何关系,在 swap1() 内部修改 a、b 的值不会影响函数外部的 x、y,更不会改变 x、y 的值。 -
swap2()传递的是指针,能够达到交换两个数的值的目的。调用函数时,分别将 x、y 的指针传递给 p1、p2,此后 p1、p2 指向 a、b 所代表的数据,在函数内部可以通过指针间接地修改 a、b 的值。 -
swap3()是按引用传递,能够达到交换两个数的值的目的。调用函数时,分别将 r1、r2 绑定到 x、y 所指代的数据,此后 r1 和 x、r2 和 y 就都代表同一份数据了,通过 r1 修改数据后会影响 x,通过 r2 修改数据后也会影响 y。
从以上代码的编写中可以发现,按引用传参在使用形式上比指针更加直观。
3. 引用作为函数返回值
引用除了可以作为函数形参,还可以作为函数返回值。
示例代码如下:
int& sum(int& r) {
r += 10;
return r;
}
int main()
{
int x = 10;
int y = sum(x);
cout << x << " - " << y << endl;
return 0;
}
运行结果:
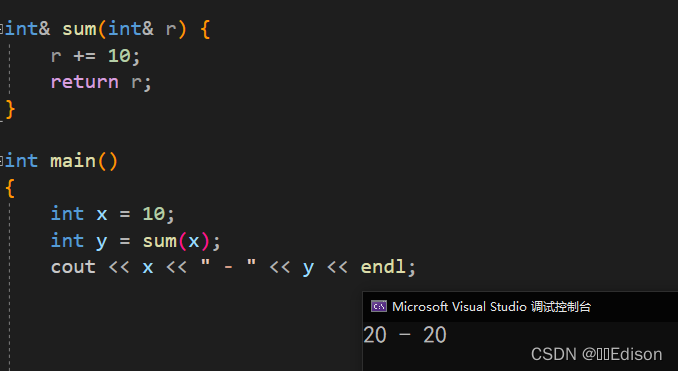
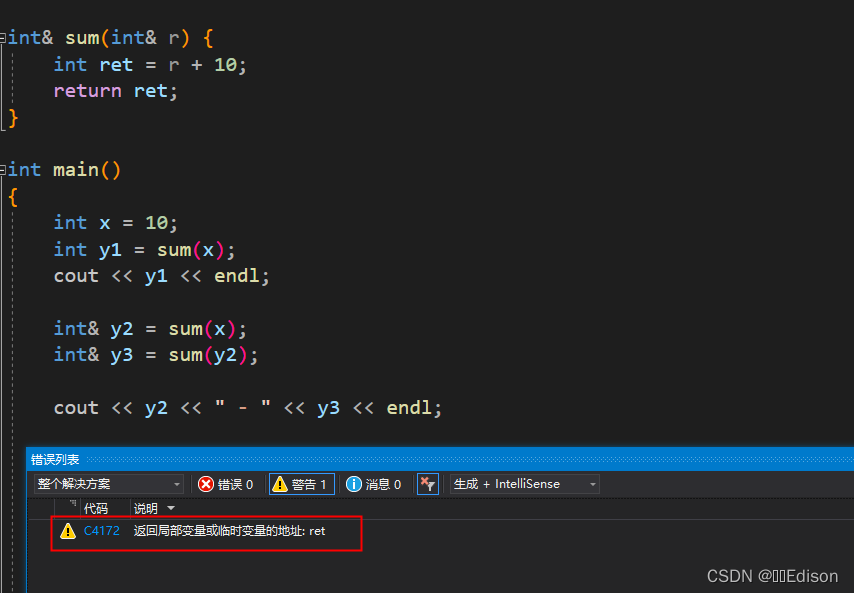
在将引用作为函数返回值时应该注意一个小问题,就是不能返回局部数据(例如局部变量、局部对象、局部数组等)的引用,因为当函数调用完成后局部数据就会被销毁,有可能在下次使用时数据就不存在了,C++ 编译器检测到该行为时也会给出警告。
更改上面的例子,让 sum 函数返回一个局部数据的引用:
int& sum(int& r) {
int ret = r + 10;
return ret;
}
int main()
{
int x = 10;
int y1 = sum(x);
cout << y1 << endl;
int& y2 = sum(x);
int& y3 = sum(y2);
cout << y2 << " - " << y3 << endl;
return 0;
}
运行结果:
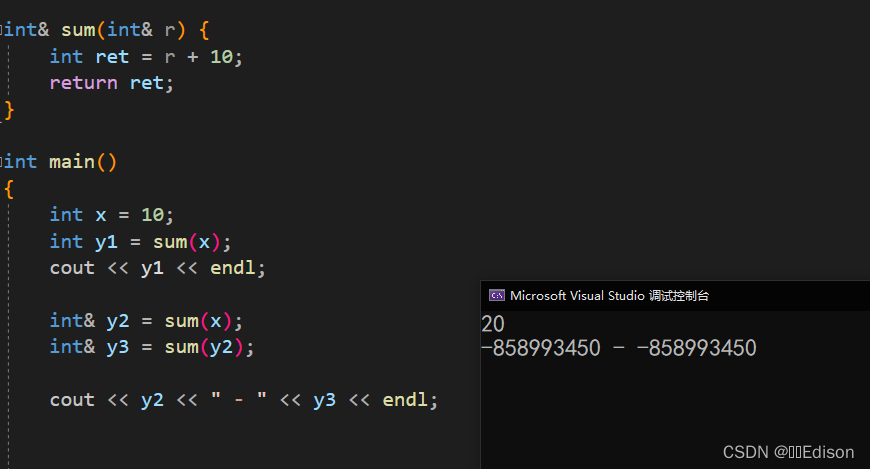
sum() 返回一个对局部变量 ret 的引用,这是导致运行结果非常怪异的根源,因为函数是在栈上运行的,并且运行结束后会放弃对所有局部数据的管理权,后面的函数调用会覆盖前面函数的局部数据。本例中,第二次调用 sum() 会覆盖第一次调用 sum() 所产生的局部数据,第三次调用 sum() 会覆盖第二次调用 sum() 所产生的局部数据。
当我们进行编译的时候,发现也会有警告:
4. 引用和指针
通过上面的例子,我们知道,虽然我们称 rx 为变量,但是通过 &rx 获取到的却不是 rx 的地址,而是 x 的地址,这会让我们觉得 rx 这个变量不占用独立的内存,它和 x 指代的是同一份内存。
int main()
{
int x = 100;
int& rx = x;
rx = 50;
cout << x << " - " << rx << endl;
return 0;
}
但是,请看下面这个例子:
int num = 100;
class A
{
public:
A()
:_n(0)
, _r(num)
{}
private:
int _n;
int& _r;
};
int main() {
A* a = new A();
cout << sizeof(A) << endl; //输出A类型的大小
cout << hex << showbase << *((int*)a + 1) << endl; //输出r本身的内容
cout << &num << endl; //输出num变量的地址
return 0;
}
运行结果:
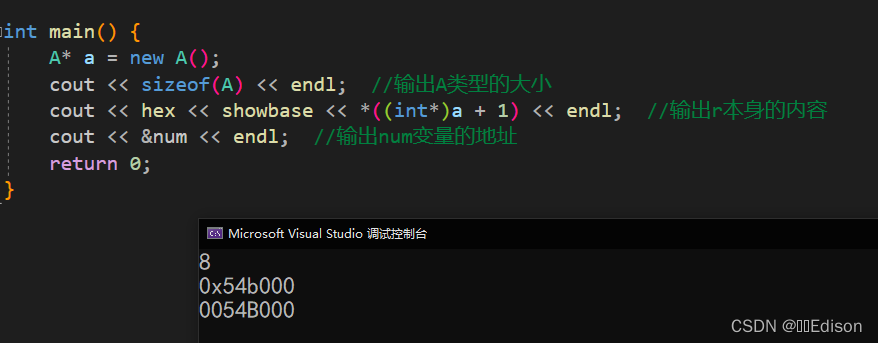
hex 表示以十六进制输出,showbase 表示添加十六进制前缀0x。
从运行结果可以看出:
- 成员变量 r 是占用内存的,如果不占用的话,
sizeof(A)的结果应该为 4。 - r 存储的内容是 0x54b000,也即变量 num 的地址。
这说明 r 的实现和指针非常类似。如果将 r 定义为 int * 类型的指针,并在构造函数中让它指向 num,那么 r 占用的内存也是 4 个字节,存储的内容也是 num 的地址。
其实引用只是对指针进行了简单的封装,它的底层依然是通过指针实现的,引用占用的内存和指针占用的内存长度一样,在 32 位环境下是 4 个字节,在 64 位环境下是 8 个字节,之所以不能获取引用的地址,是因为编译器进行了内部转换。以下面的语句为例:
int x = 100;
int &rx = x;
rx = 50;
cout << &r << endl;
编译时会被转换成如下的形式:
int x = 100;
int *rx = &x;
*rx = 50;
cout << rx << endl;
使用 &r 取地址时,编译器会对代码进行隐式的转换,使得代码输出的是 rx 的内容(x 的地址),而不是 rx 的地址,这就是为什么获取不到引用变量的地址的原因。也就是说,不是变量 rx 不占用内存,而是编译器不让获取它的地址。
当引用作为函数参数时,也会有类似的转换。以下面的代码为例:
//定义函数
void swap(int& r1, int& r2) {
int temp = r1;
r1 = r2;
r2 = temp;
}
int main()
{
//调用函数
int x = 10, y = 20;
swap(x, y);
return 0;
}
编译时会被转换成如下的形式:
//定义函数
void swap(int* r1, int* r2) {
int temp = *r1;
*r1 = *r2;
*r2 = temp;
}
int main()
{
//调用函数
int x = 10, y = 20;
swap(&x, &y);
return 0;
}
引用虽然是基于指针实现的,但它比指针更加易用,从上面的两个例子也可以看出来,通过指针获取数据时需要加 *,书写麻烦,而引用不需要,它和普通变量的使用方式一样。
C++ 的发明人 Bjarne Stroustrup 也说过,他在 C++ 中引入引用的直接目的是为了让代码的书写更加漂亮,尤其是在运算符重载中,不借助引用有时候会使得运算符的使用很麻烦。
5. 其他区别
(1)引用必须在定义时初始化,并且以后也要从一而终,不能再指向其他数据;而指针没有这个限制,指针在定义时不必赋值,以后也能指向任意数据。
(2)可以有 const 指针,但是没有 const 引用。也就是说,引用变量不能定义为下面的形式:
int x = 20;
int & const rx = x;
因为 rx 本来就不能改变指向,加上 const 是多此一举。
(3)指针可以有多级,但是引用只能有一级,例如,int** p 是合法的,而int &&r 是不合法的。如果希望定义一个引用变量来指代另外一个引用变量,那么也只需要加一个 &,如下所示:
int x = 10;
int &rx = x;
int &rrx = rx;
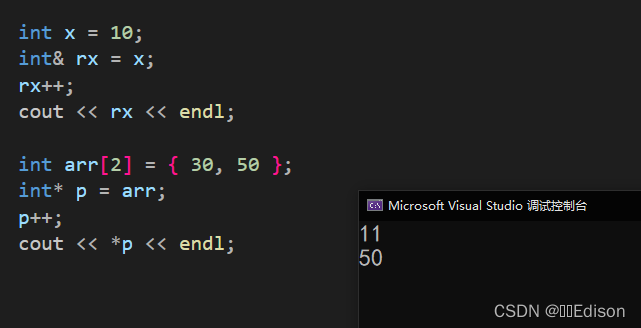
(4)指针和引用的自增 ++ 自减 -- 运算意义不一样。对指针使用 ++ 表示指向下一份数据,对引用使用 ++ 表示它所指代的数据本身加 1;自减 -- 也是类似的道理。示例如下:
int main()
{
int x = 10;
int& rx = x;
rx++;
cout << rx << endl;
int arr[2] = { 30, 50 };
int* p = arr;
p++;
cout << *p << endl;
return 0;
}
运行结果: