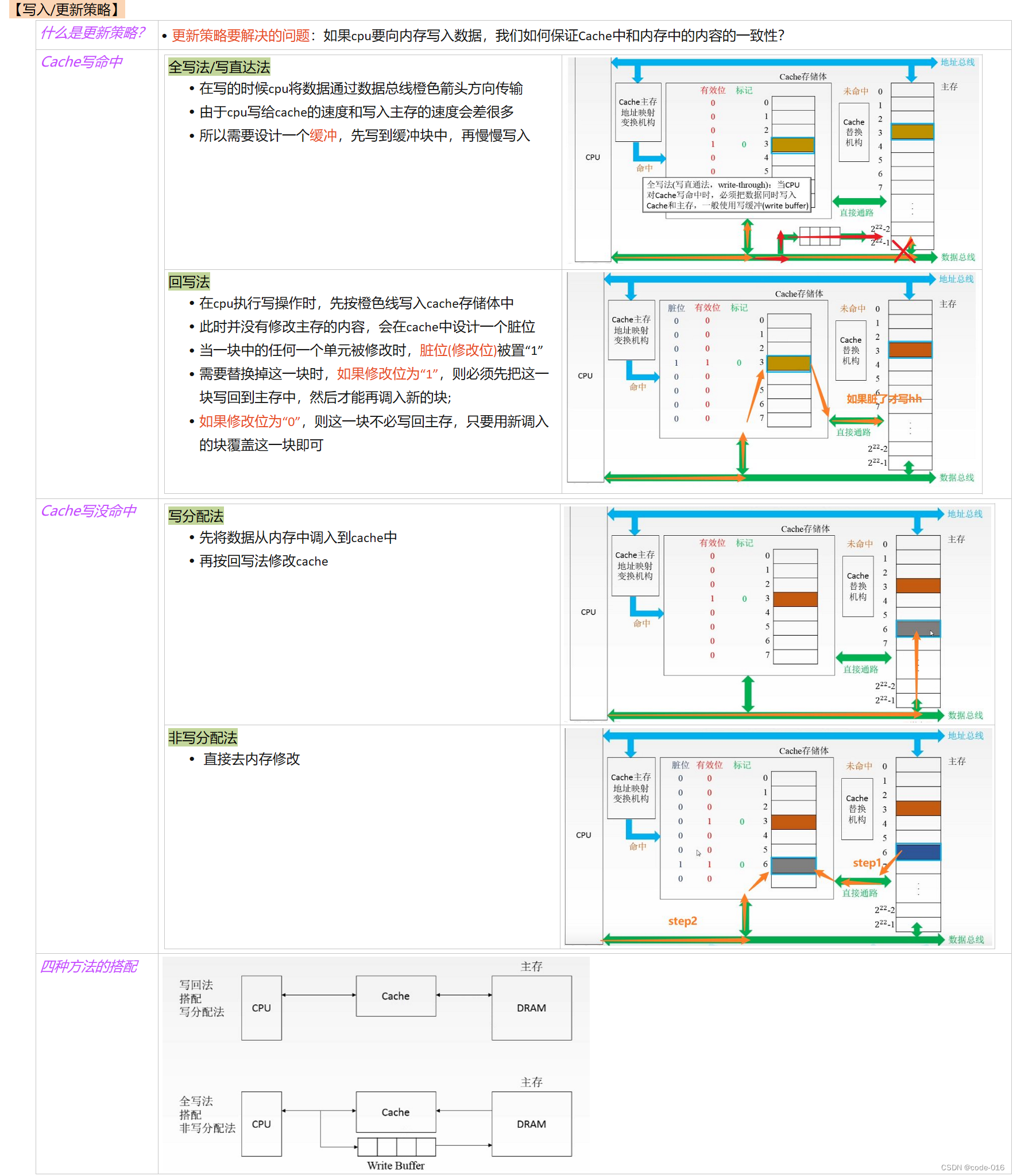
目录
- 准备
- 源文件和预训练文件下载
- python版本以及torch版本说明:
- 文件目录说明
- 测试文件
- detect.py使用
- 测试单张图片
- 测试一个文件夹里的图片
准备
源文件和预训练文件下载
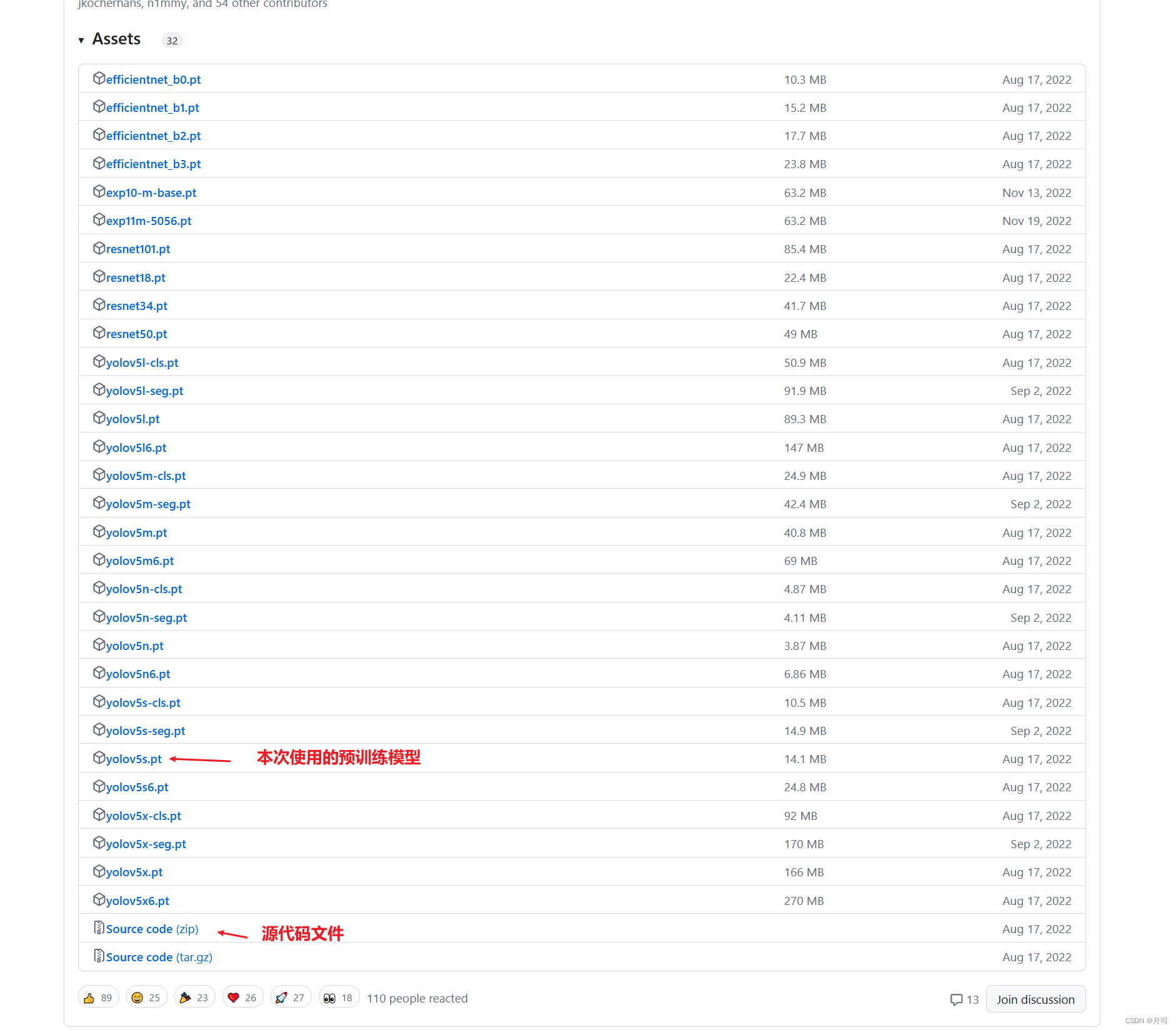
下载链接:https://github.com/ultralytics/yolov5/releases/tag/v6.2
源文件和预训练模型如下:
python版本以及torch版本说明:
- python:3.9.3
- pytorch:

因为我是cuda 11.8,所以是安装了这个版本的。但不是只有该版本才能使用
v5-6.2。由于6.2版本是2022年发布的,所以相近几年的都可以
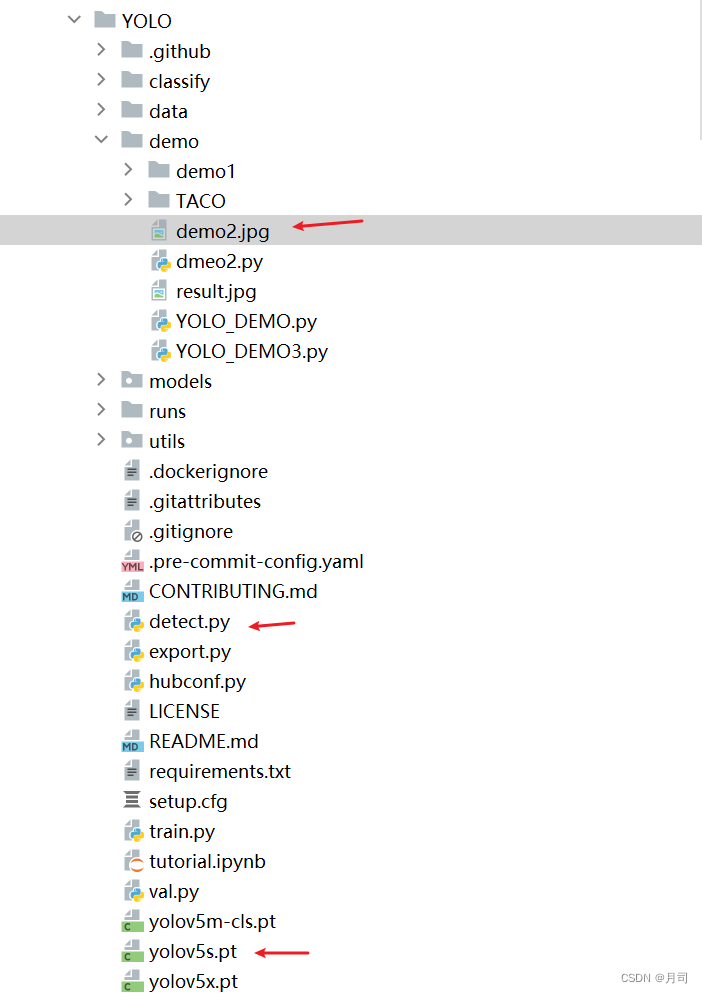
文件目录说明
如图:
测试文件
demo2.jpg
detect.py使用
测试单张图片
基本的命令:
python detect.py --source ./demo/demo2.jpg --weights YOLOv5s.pt --project "runs/detect/demo1" --device 0 --view-img --save-txt
参数解析:
-
--device:配置GPU加速,第一个GPU设备。 -
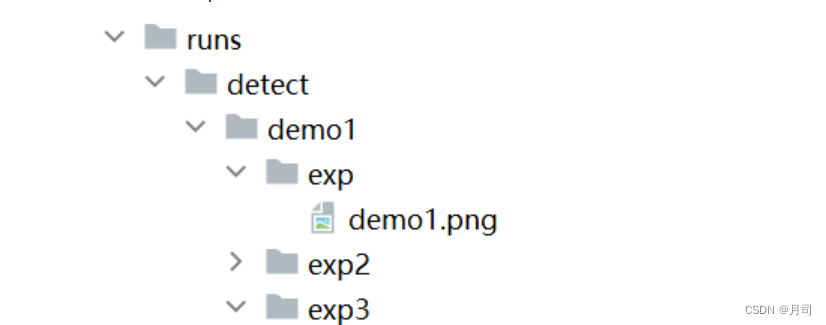
指定输出结果的文件夹:
--output ./demo/demo1project参数以及name来代替,及project/name。结果路径保存的地方runs/detect/demo1/exp。还有一个参数exist_ok,这个参数指定的话,就会存在exp文件里。如果不指定,在此运行,结果会存在exp+int(i)这样,递增的文件夹里,如:
-
--view-img:虽然会显示图片,但是会一闪而过的。 -
--save-txt:这里是保存的目标检测对应的标签,以及对象框的信息,如:
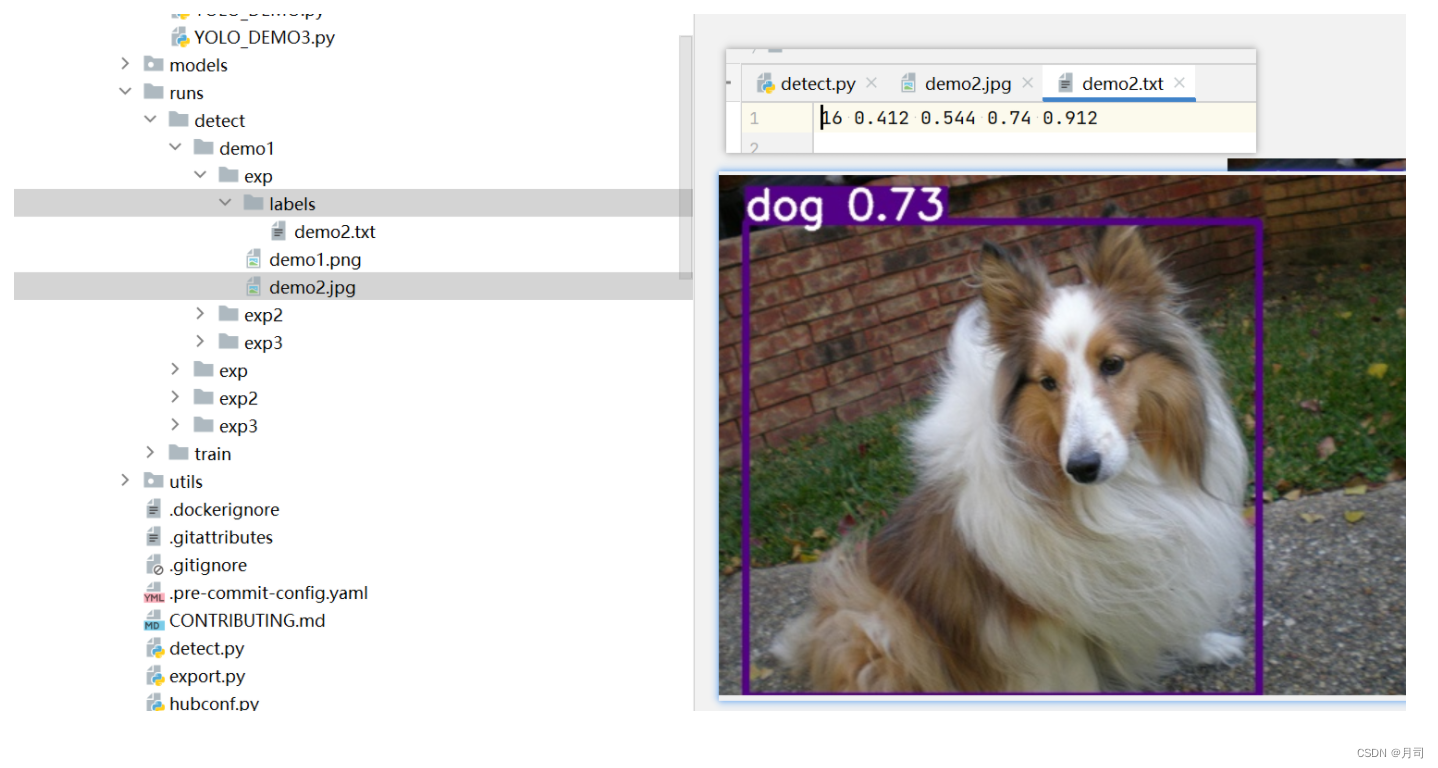
-
--save-crop:保存裁剪后的预测框的图片:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4E4vHpPZ-1681986914880)(YOLOV5笔记.assets/image-20230420175927763.png)]](https://img-blog.csdnimg.cn/da3babe8634f465db413e2886f107cc5.png)
-
--save-conf:保存预测的置信度到save-txt制定的txt文件里效果如下:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CLOFB9kz-1681986914881)(YOLOV5笔记.assets/image-20230420175842604.png)]](https://img-blog.csdnimg.cn/64e116c694e44bde8a2d1eff343defbf.png)
最后添加的0.734整好是预测框的置信度。
-
--visualize:这个关键字就比较有意思了,制定这个关键字,可以可视化detect时每个步骤捕捉到的特征。然后保存在指定的project/name里。比如:
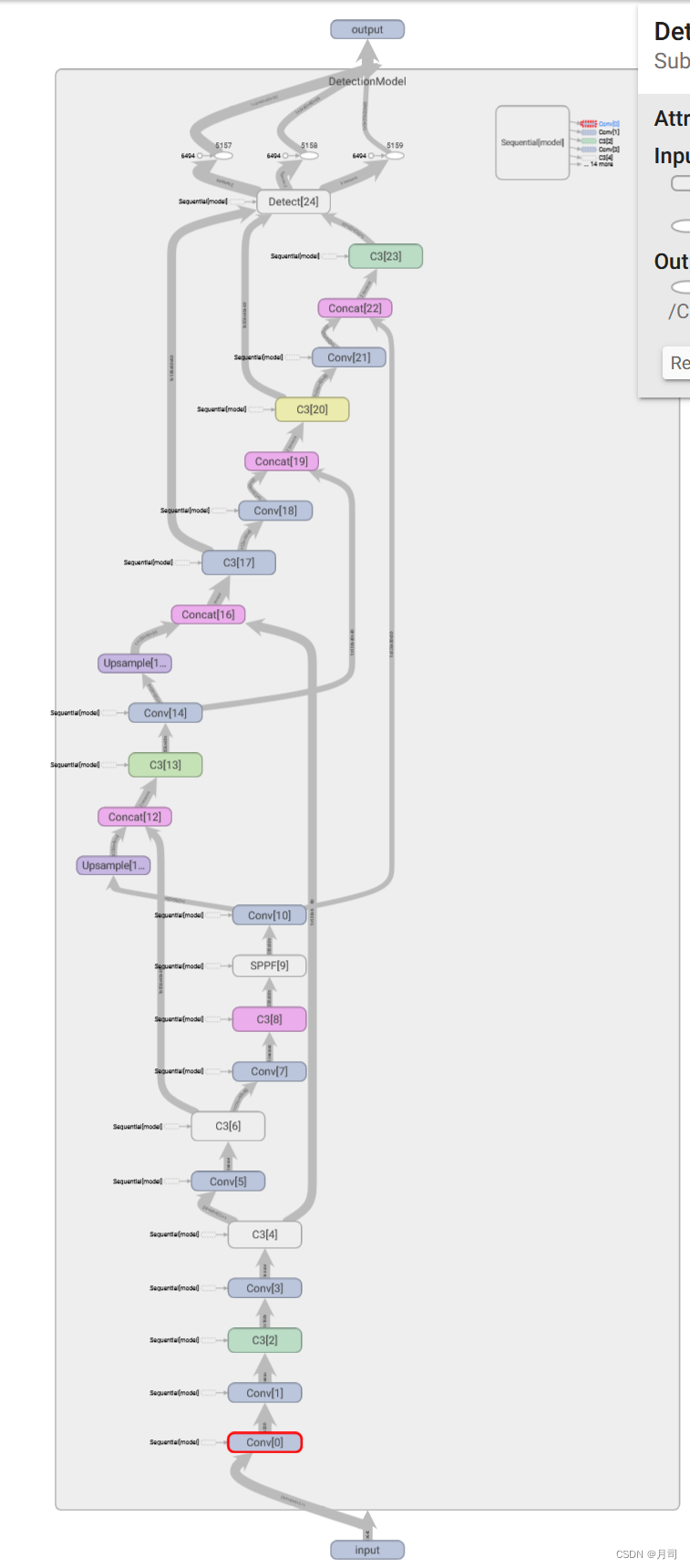
由于detect时,使用的是yolov5s的模型结构,在tensorboard中查看这个模型的结构,整好也是
ConV[0]-ConV[23]。
首先,查看stage0_Conv_features.png:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gX6HkRZK-1681986914882)(YOLOV5笔记.assets/image-20230420181352537.png)]](https://img-blog.csdnimg.cn/edf64f51560f41fb953a4e5183a5a528.png)
然后查看一下Covn[0]的结构:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OfNx9DGO-1681986914882)(YOLOV5笔记.assets/image-20230420181500713.png)]](https://img-blog.csdnimg.cn/145f3866f1e14eaea3cfec6fecaede89.png)
是上面方框是吻合的。
-
--augment:增强推理。精确度会上升,但是可能会导致--visualize关键字失效。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-72fheFV2-1681986914882)(YOLOV5笔记.assets/image-20230420181940579.png)]](https://img-blog.csdnimg.cn/188b86a21c414164af1aed725fb4afda.png)
detect.py里就是一个run()以及一个命令行解析函数parse_opt。命令行参数与run中的关键参数就差在连接符上。比如命令行参数exist-ok,而run里对应的关键字参数是`exist_ok
- 其他参数:后面有研究再更新…
测试一个文件夹里的图片
直接将--source制定为文件夹即可。其他没有任何不同