文章目录
- 概述
- 执行器(Executor)
- 执行器总结
- 缓存
- MyBatis缓存概述
- 一级缓存(LocalCache)
- Spring集成MyBatis后一级缓存失效的问题
- 二级缓存
- 二级缓存组件结构
- 二级缓存的使用
- 为什么要提交之后才能命中二级缓存?
- 二级缓存结构
- 二级缓存执行流程
概述
通过一条修改语句,我们来了解一下Mybatis的执行过程:
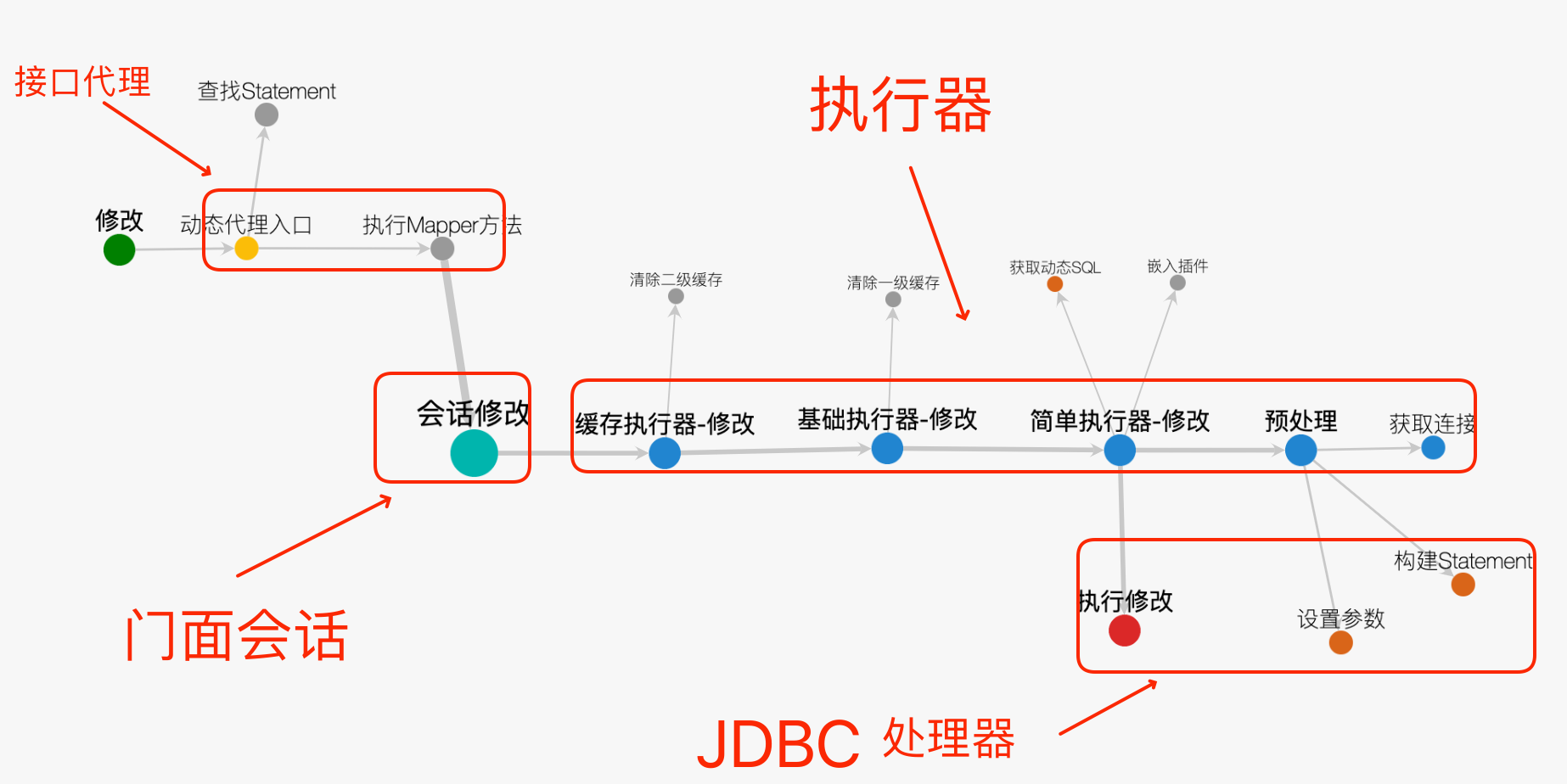
一般MyBatis在执行一条语句的时候会依次使用以下四个模块:

分别说下各个组件的作用
接口代理: 其目的是简化对MyBatis使用,底层使用动态代理实现。Sql会话: 提供增删改查API,其本身不作任何业务逻辑的处理,所有处理都交给执行器。这是一个典型的门面模式设计。执行器: 核心作用是处理SQL请求、事物管理、维护缓存以及批处理等 。执行器的角色更像是一个管理员,接收SQL请求,然后根据缓存、批处理等逻辑来决定如何执行这个SQL请求。并交给JDBC处理器执行具体SQL。JDBC处理器:他的作用就是用于通过JDBC具体处理SQL和参数的。在会话中每调用一次CRUD,JDBC处理器就会生成一个实例与之对应(命中缓存除外)。
请注意在一次SQL会话过程当中四个组件的实例比值分别是 1:1:1:n
各个组件关系可以通过下面这张图了解。一个SQL请求通过会话到达执行器,然后交给对应的JDBC处理器进行处理。另外所有的组件都不是线程安全的,不能跨线程使用。
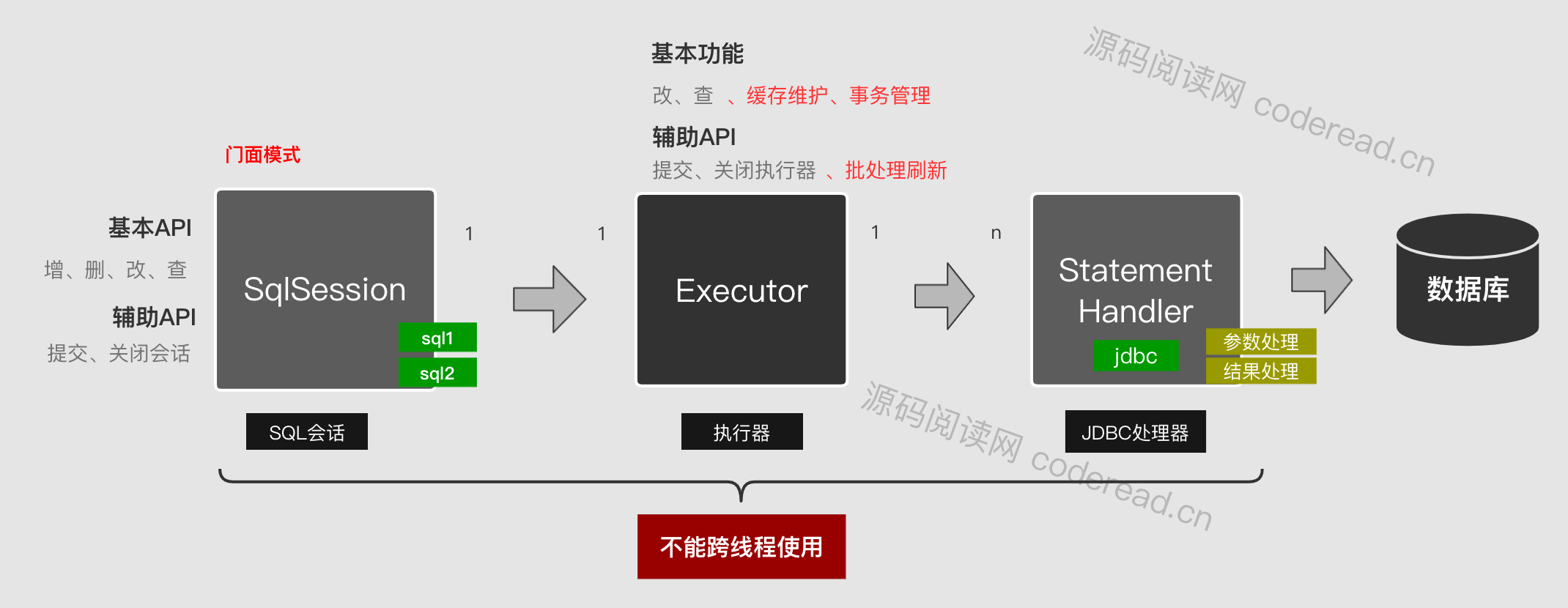
执行器(Executor)
SqlSession使用了一种设计模式叫做外观模式(也叫做门面模式)。这个模式提供了一个统一的门面接口API,使得系统更加容易使用。在SqlSession中提供了两种API:
- 基本API:增删改查
- 辅助API:提交、关闭会话

Sql仅仅只是提供API它不会提供具体的实现。就好像我们去饭店吃饭的时候的话,我们服务员的话,它只负责点单,但是的话它不负责具体的炒菜,炒菜交给厨房。那么这里的SqlSession,它具体的处理交给我们的执行器Executor。
在我们SqlSession的内部有一个属性叫做executor,它指向了我们的Executor执行器,当我们执行相关的增删改查的时候,对应的方法就会转交给Executor。
那么Executeor是怎么实现的呢?他提供了两个功能一个叫改、一个叫查。那为什么只有改和查,增和删哪里去了?在JDBC的标准API里面其实只有改和查,因为所有的增删改,它最终的话都可以归结于这个改。
而改和查都会涉及到缓存。查的话使用缓存效率更高、改的话缓存也要跟着更新,所以Executor还负责维护缓存。同时Executor还有一些辅助API,例如提交、关闭执行器,还有批处理的时候会涉及到批处理刷新等操作。
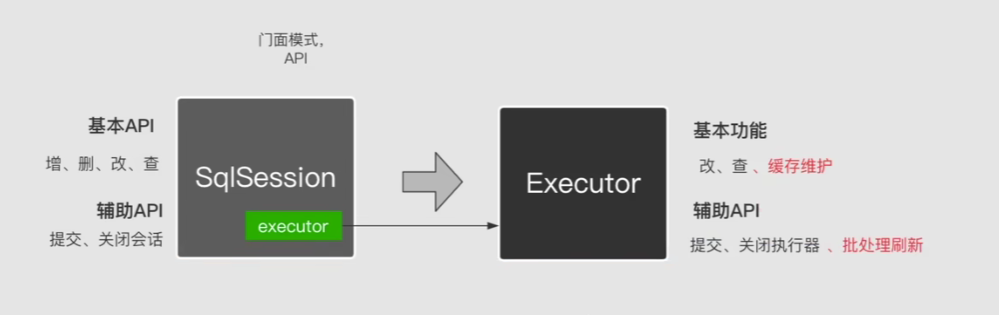
接下来我们看看Executor的实现:
对于这个接口MyBatis是有三个实现子类。分别是:
- SimpleExecutor(简单执行器)
- ReuseExecutor(重用执行器)
- BatchExecutor(批处理执行器)
先来看默认实现SimpleExecutor,也就是简单执行器
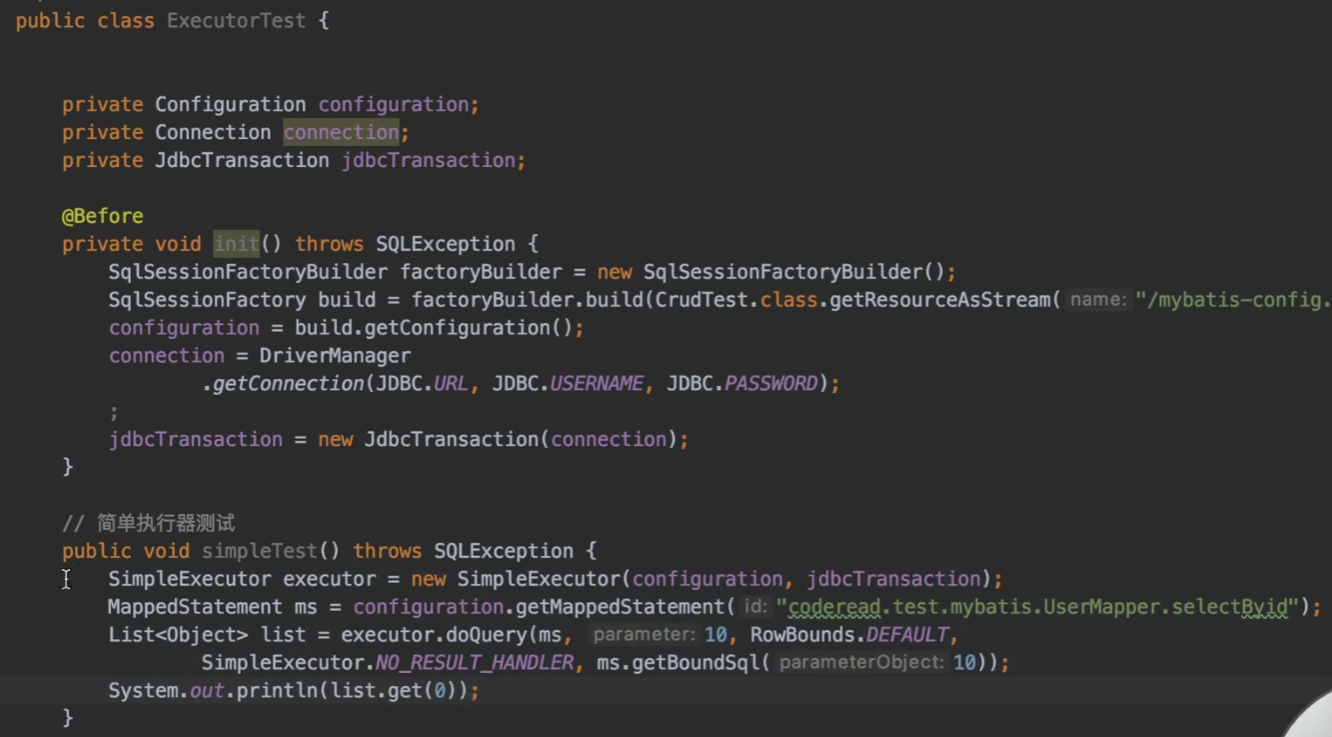
上面这段代码就直接使用了简单执行器帮我们完成了查询的操作。
代码解析:
我们想要使用这个SimpleExecutor简单执行器要传入两个参数,一个是配置类Configuration,另一个是事务对象。
使用xml配置文件构建会话工厂SqlSessionFactory,然后通过这个会话工厂我们就可以拿到配置类Configuration。
这个Configuration是通过XMLConfigBuilder.parse()方法解析我们的xml配置文件得来的,详情可以看我的另一篇文章:
思维导图手撕MyBatis源码
然后我们再来看看事务对象Transaction,在MyBatis中Transaction有两个作用:
- 包装数据库连接
- 数据库连接的工作其实是通过Configuration拿到Environment,再从Environment中拿到DataSource,DataSource有一个getConnection方法尝试去获取连接
- 处理连接生命周期,包括:连接的创建、准备、提交回滚和关闭
Transaction是一个接口,JdbcTransaction对其进行了实现。
此处的doQuery要传入五个参数:
- SQL声明映射MappedStatement
- 参数Object
- 行范围RowBounds:需不需要分页
- 结果处理器ResultHandler
- 动态SQL语句BoundSql:也就是获取映射绑定的sql语句
但是这个简单执行器有一个缺点就是无论SQL是否一样,每次都会进行预编译
什么是预编译?
我们知道一条SQL语句到达Mysql之后,Mysql并不是会马上执行它,而是需要经过几个阶段性的动作。那么这几个阶段肯定是需要一定的时间的。而有时候我们一条SQL语句可能需要反复的执行,只不过里面的参数可能不一样,比如where子句中的条件。如果每次都需要经过上面的几个步骤,那么效率就会下降。因此为了解决这种问题,就出现了预编译。
预编译语句就是将这类语句中的值用占位符替代,可以视为将SQL语句模板化或者说参数化。一次编译、多次运行,省去了解析优化等过程。
为了改善这一情况我们这个时候就可以选择ReuseExecutor(重用执行器)。他会将在会话期间内的Statement进行缓存,并使用SQL语句作为Key。所以当执行下一请求的时候,不在重复构建Statement,而是从缓存中取出并设置参数,然后执行。
那么我们的批处理执行器什么时候使用呢?
它就是用来作批处理的。但会将所 有SQL请求集中起来,最后调用Executor.flushStatements() 方法时一次性将所有请求发送至数据库。
而我们要注意批处理执行器只针对增删改有效,对我们的拆线语句是没有效果的。
我们总结一下:
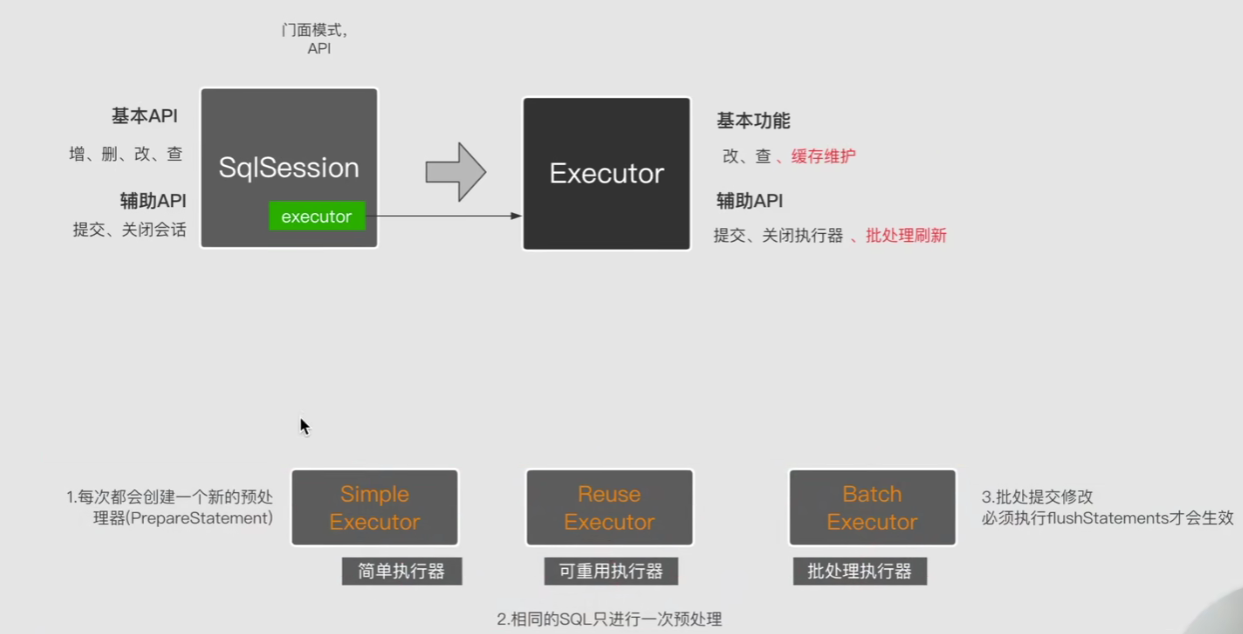
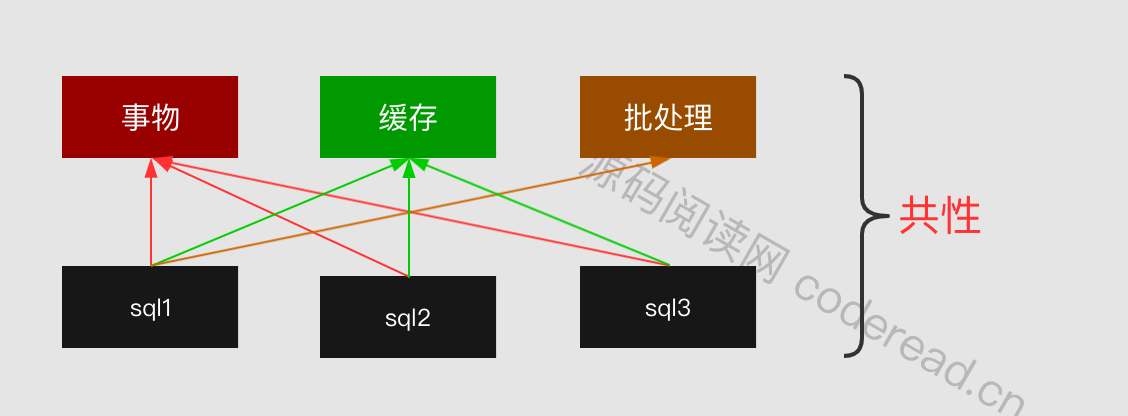
进行到这里我们发现到这里为止我们还没有涉及到Executor基本功能中的缓存维护。因为这三个执行器都涉及到缓存的操作,如果我们一个个都去写缓存相关的功能那么就会造成代码的冗余,因为这些缓存操作是通用的,那么我们就可以把他们抽象出来一个类,专门用来写入缓存方面的操作。这个类就是BaseExecutor。同时我们还将获取链接这个通用操作也放在BaseExecutor中,我们总结一下:
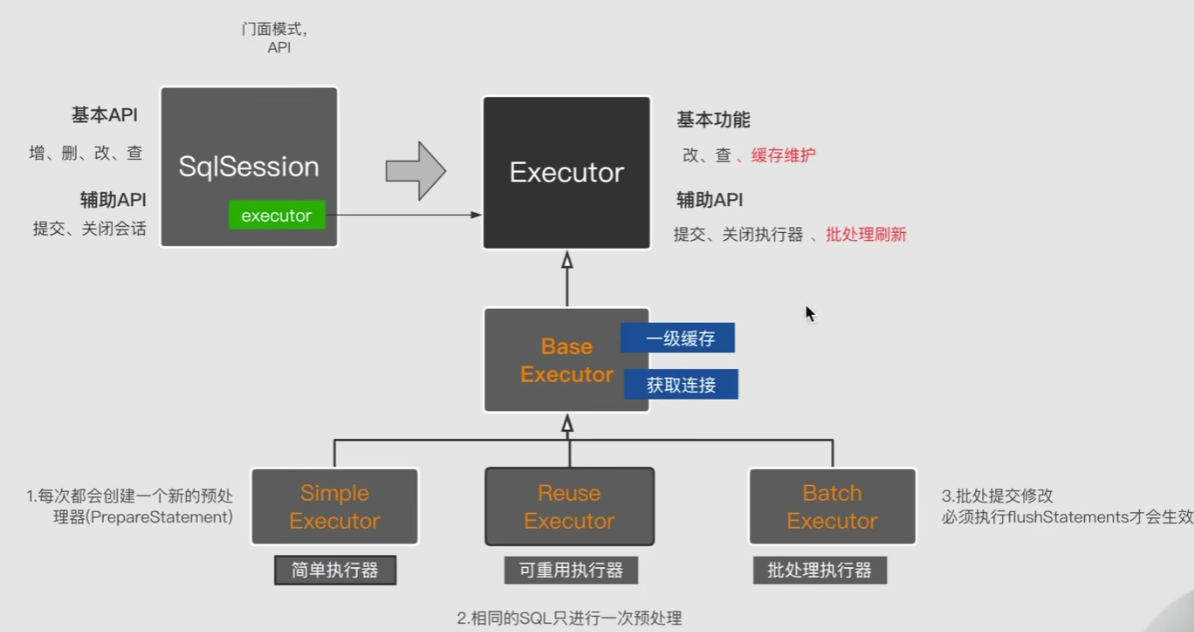
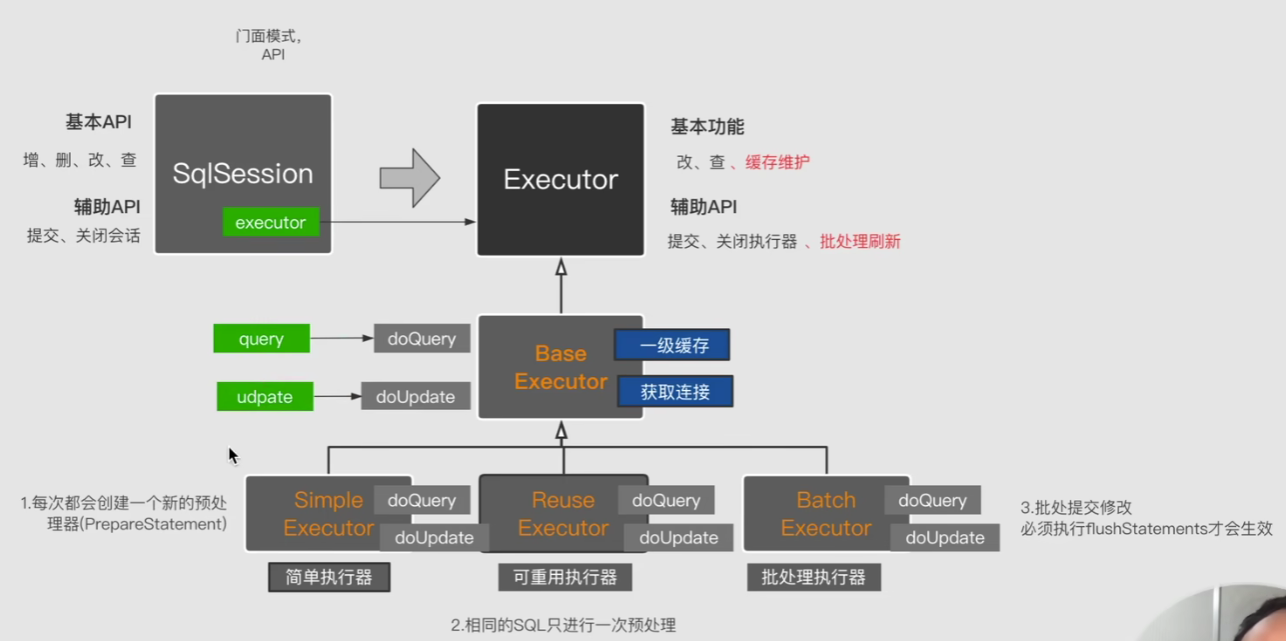
这个时候我们再次回头看看我们前面的代码,我们会发现因为我们直接调用的子类执行器当中的方法doQuery,压根没有走BaseExecutor,所以是没有缓存功能的:
//得到简单执行器
SimpleExecutor simpleExecutor = new SimpleExecutor(configuration,jdbcTransaction);
//使用简单执行器
MappedStatement ms = configuration.getMappedStatement("selectAll");
List<Stu> list = simpleExecutor.doQuery(ms, null, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER, ms.getBoundSql(null));
我们的BaseExecutor抽象类实现了Executor接口,当我们调用接口中的query()、update()方法的时候,就会调用BaseExecutor中的对应实现方法,在这些实现方法中,会先执行缓存相关操作,然后调用doQuery()、doUpdate()方法,这两个方法是抽象方法,而三个子类执行器对他们进行了实现:
实验代码:
查看Executor 的子类还有一个CachingExecutor,这是用于处理二级缓存的。为什么不把它和一级缓存一起处理呢?因为二级缓存和一级缓存相对独立的逻辑,而且二级缓存可以通过参数控制关闭,而一级缓存是不可以的。综上原因把二级缓存单独抽出来处理。抽取的方式采用了装饰者设计模式,即在CachingExecutor 对原有的执行器进行包装,处理完二级缓存逻辑之后,把SQL执行相关的逻辑交给实至的Executor处理。
装饰者模式:在不改变原有类结构和继承的情况下,通过包装原对象去拓展一个新功能。
当把CachingExecutor加进来之后整体结构如下图所示。
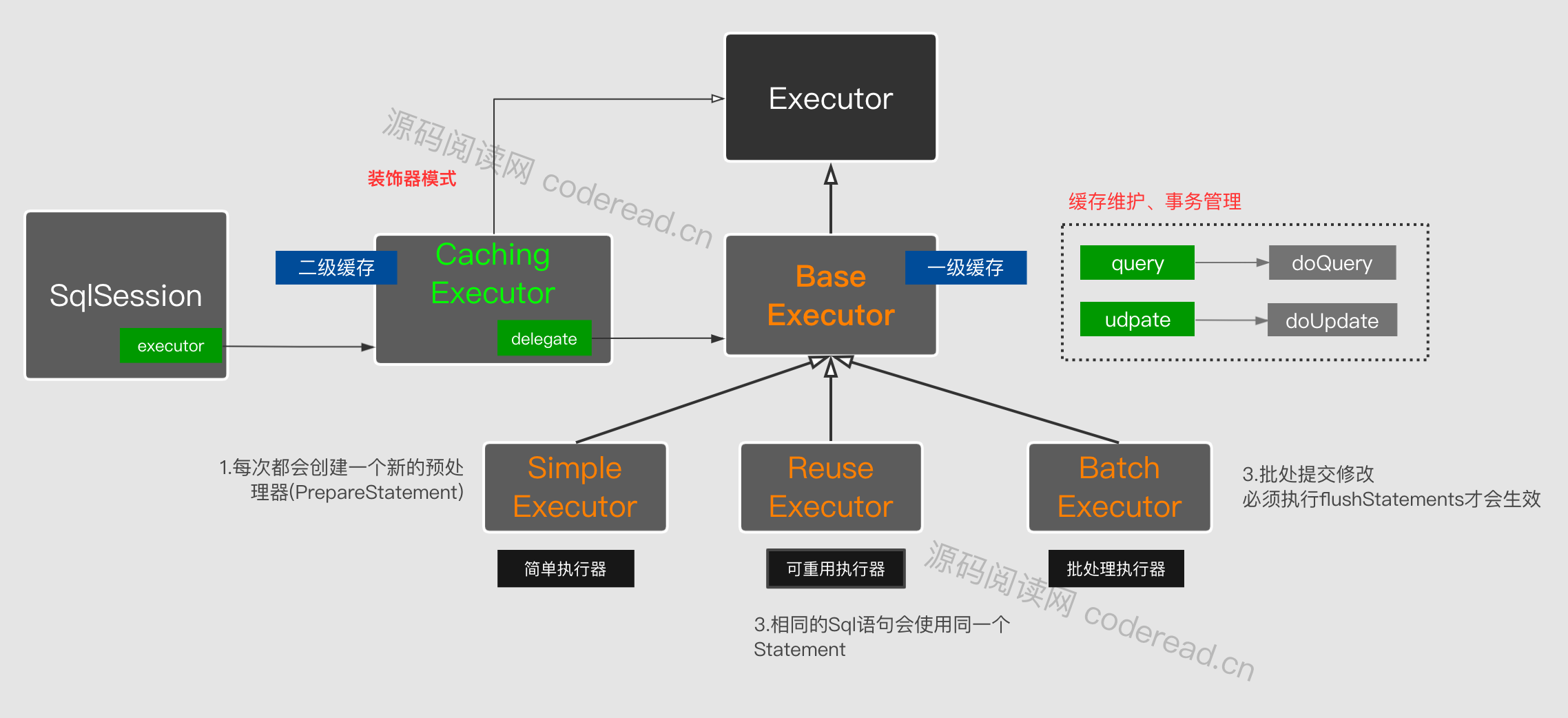
delegate就是被包装对象
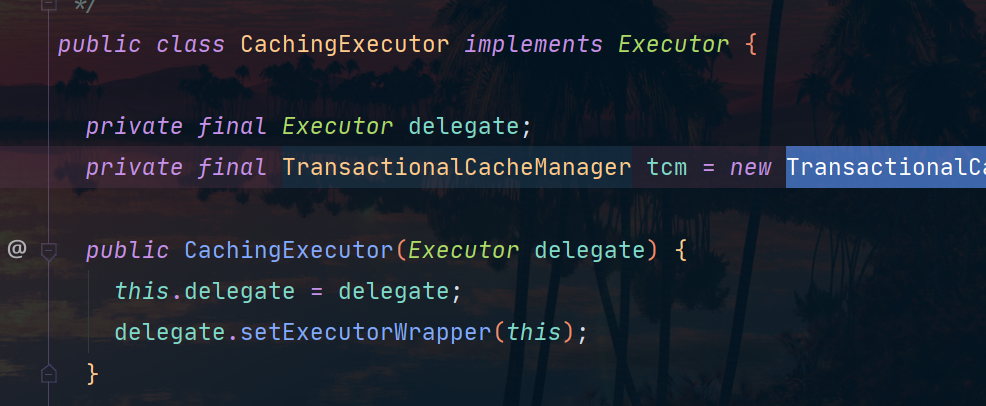
我们来测试一下:
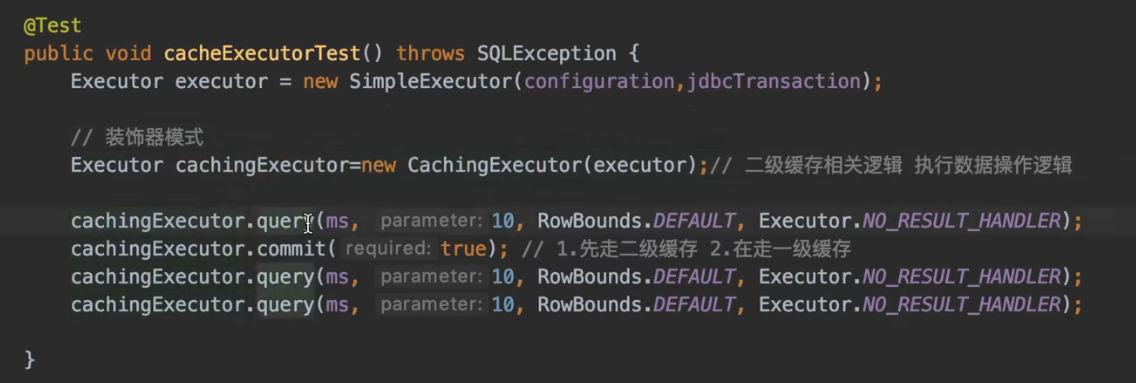
一级缓存、二级缓存这里不多赘述,后面会讲解
我们打断点可以发现CachingExecutor的query方法当中逻辑如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//在sql映射中获取缓存声明
Cache cache = ms.getCache();
//如果声明使用缓存则进入以下逻辑
if (cache != null) {
//根据设置决定是否在每次查询之前执行二级缓存的清空操作
flushCacheIfRequired(ms);
//如果使用缓存数据的结果集不能够进行自定义的处理
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked") //通过缓存事务管理器获取缓存
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//如果没有获取到缓存则直接将查询操作交给下一个执行器
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//将结果填充到二级缓存中去
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//在没有使用缓存的情况下直接调用下一个执行器
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
我们发现在执行不属于他职责范围之内的任务时,他都是直接调用下一个执行器

执行器总结
执行器的种类有:基础执行器、简单执行器、重用执行器和批处理执行器,此外通过装饰器形式添加了一个缓存执行器。对应功能包括缓存处理、事物处理、重用处理以及批处理,这些是多个SQL执行中有共性地方。执行器存在的意义就是去处理这些共性。 如果说每个SQL调用是独立的,不需要缓存,不需要事物也不需集中在一起进行批处理的话,Executor也就没有存在的必要。但事实上这些都是MyBatis中不可或缺的特性。所以才设计出Executor这个组件。
缓存
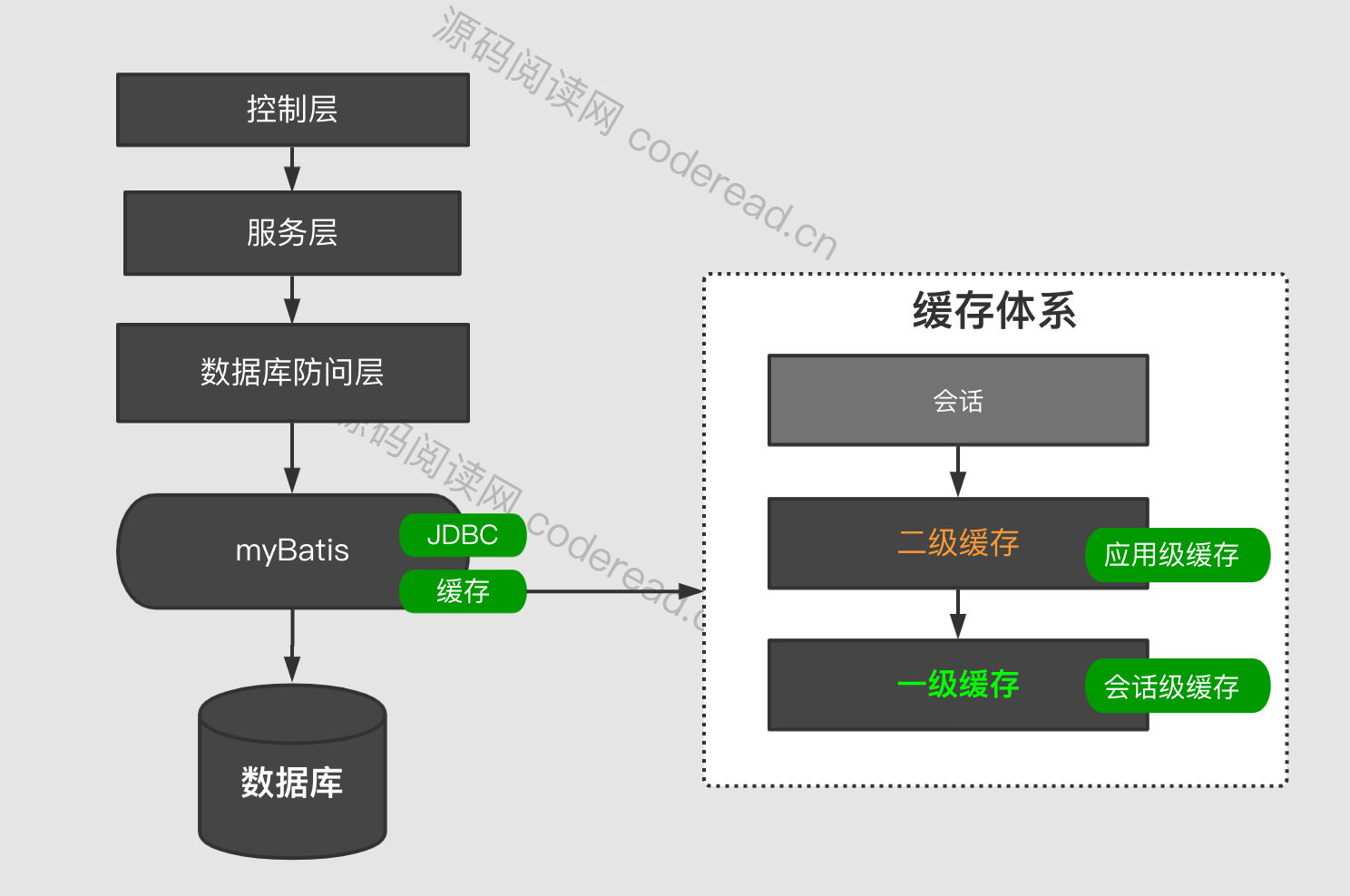
MyBatis缓存概述
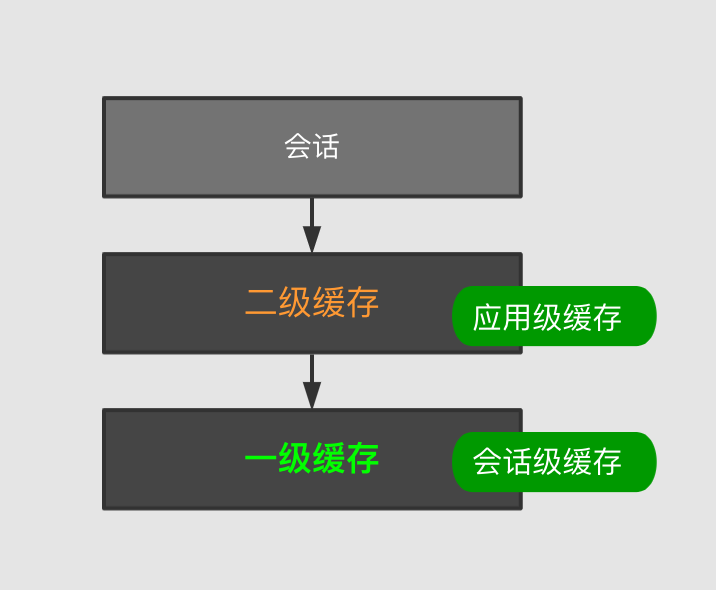
myBatis中存在两个缓存,一级缓存和二级缓存:
- 一级缓存(LocalCache):也叫做会话级缓存,生命周期仅存在于当前会话,不可以直接关闭。但可以通过flushCache和localCacheScope对其做相应控制。
- 二级缓存:也叫应用级性缓存,缓存对象存在于整个应用周期,而且可以跨线程使用。
一级缓存(LocalCache)
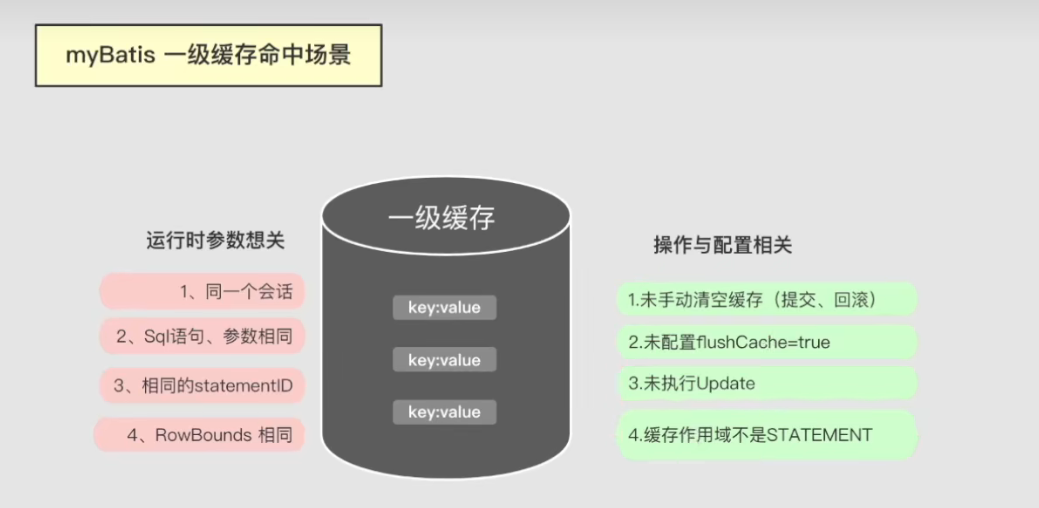
一级缓存的命中场景:
- 满足特定命中参数
- SQL与参数相同
- 同一个会话
- 相同的MapperStatement ID
- RowBounds行范围相同
- 不触发清空方法
- 手动调用clearCache
- 执行提交、回滚操作(也会执行清空缓存的操作)
- 执行update(因为执行更新操作会默认清空缓存)
- 配置flushCache=true(也就是执行完当前语句之后刷新缓存)
- 缓存作用域为Statement(缩小作用域,但并不是完全关闭缓存,比如我们的嵌套查询、子查询此时还会使用到缓存)
底层实现:HashMap
一级缓存源码解析
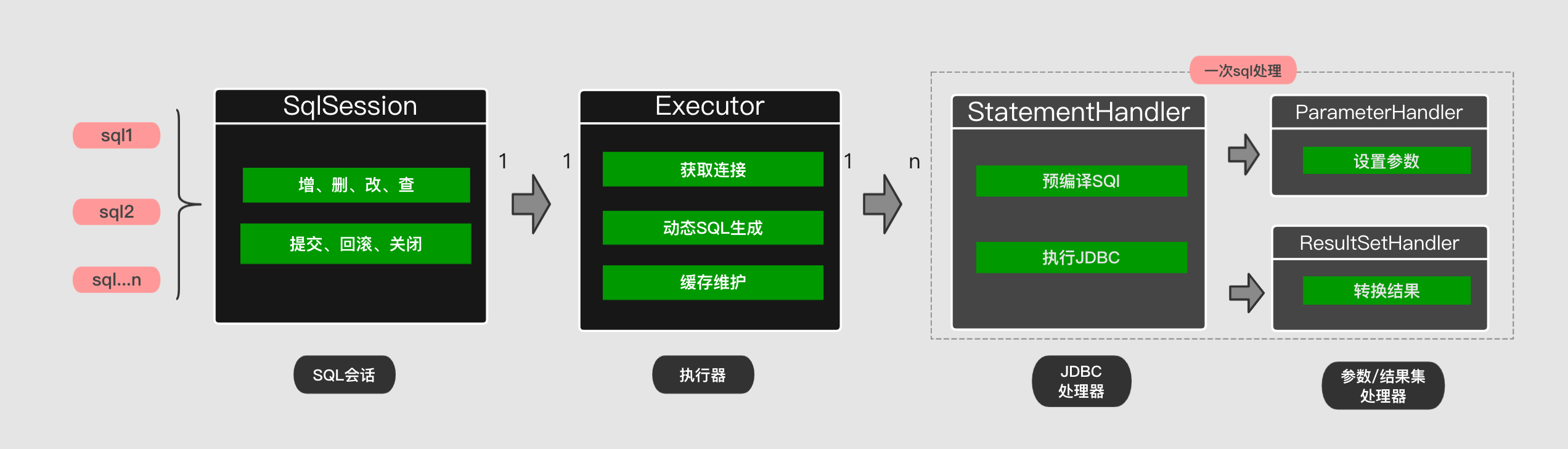
我们前面说过MyBatis的执行过程如下图:

一级缓存逻辑就存在于 BaseExecutor (基础执行器)里面。当会话接收到查询请求之后,会交给执行器的Query方法,在这里会通过 Sql、参数、分页条件等参数创建一个缓存key,在基于这个key去 PerpetualCache中查找对应的缓存值,如果有值直接返回。没有就会查询数据库,然后再填充缓存。
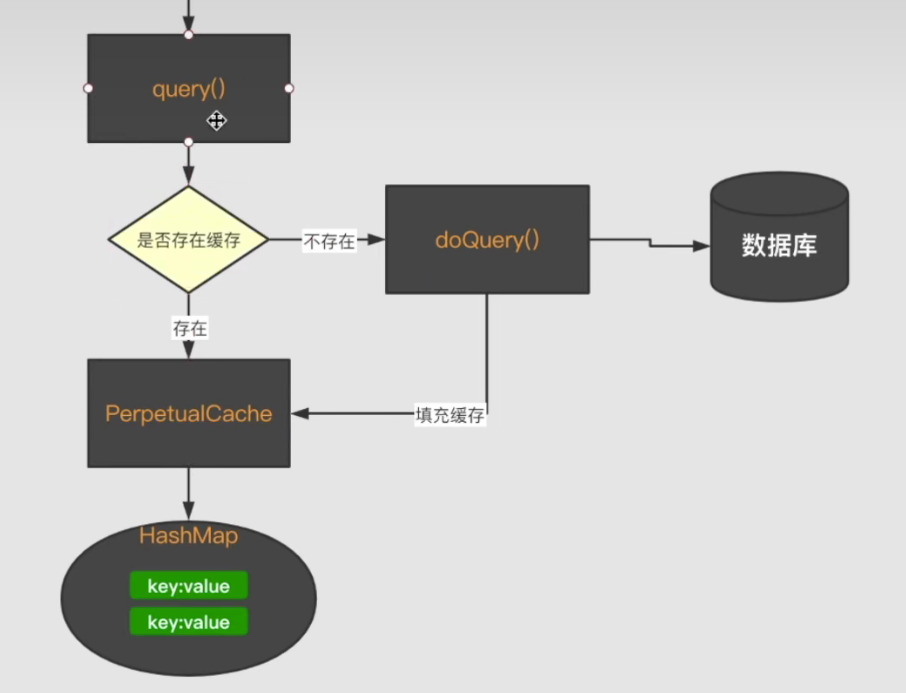
这里缓存的实现非常简单就是HashMap:
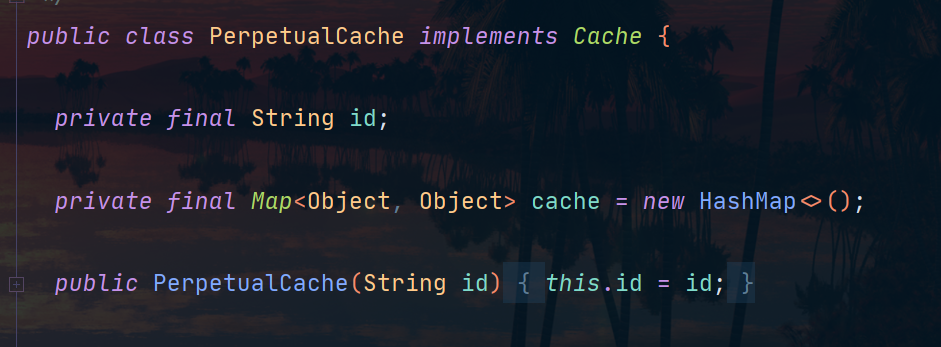
这里没有使用ConcurrentHashMap是因为会话本身就线程不安全,这里的缓存也没必要弄一个线程安全的。
然后我们debug一下源码:
我们发现缓存的key有以下六个值:
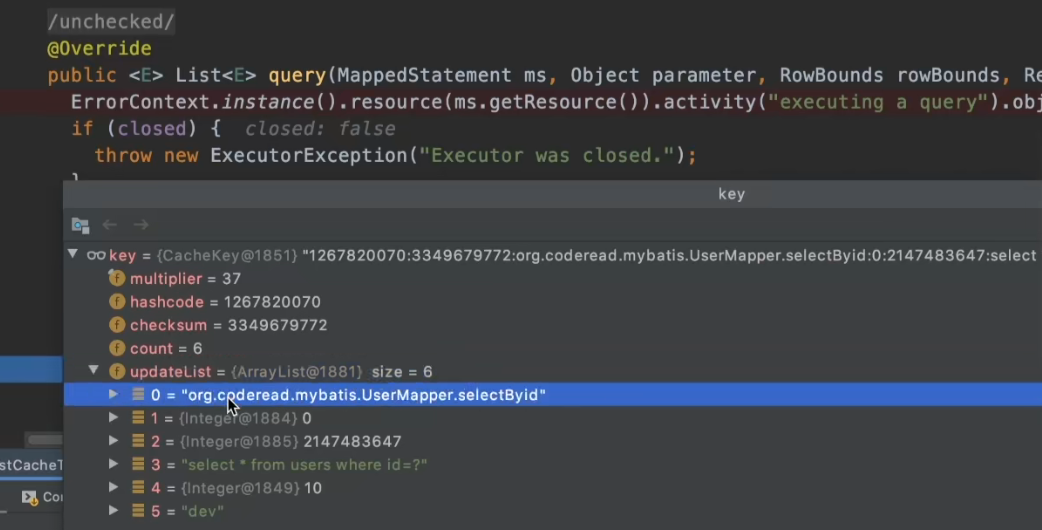
- StatementById
- 第2、3个值都是分页条件
- 查询条件
- 查询参数
- 环境变量(不过我们一般不会在一个应用程序里面去跑两套环境,所以这个可以忽略)
一级缓存的清空
缓存的清空对应BaseExecutor中的 clearLocalCache.方法。只要找到调用该方法地方,就知道哪些场景中会清空缓存了。
- update: 执行任意增删改
- select:查询又分为两种情况清空,一前置清空,即配置了flushCache=true。2后置清空,配置了缓存作用域为statement 查询结束合会清空缓存。
- commit:提交前清空
- Rolback:回滚前清空
注意:clearLocalCache 不是清空某条具体数据,而清当前会话下所有一级缓存数据。
一级缓存总结
- 与会话相关
- 与参数条件相关
- 提交、修改都会清空
Spring集成MyBatis后一级缓存失效的问题
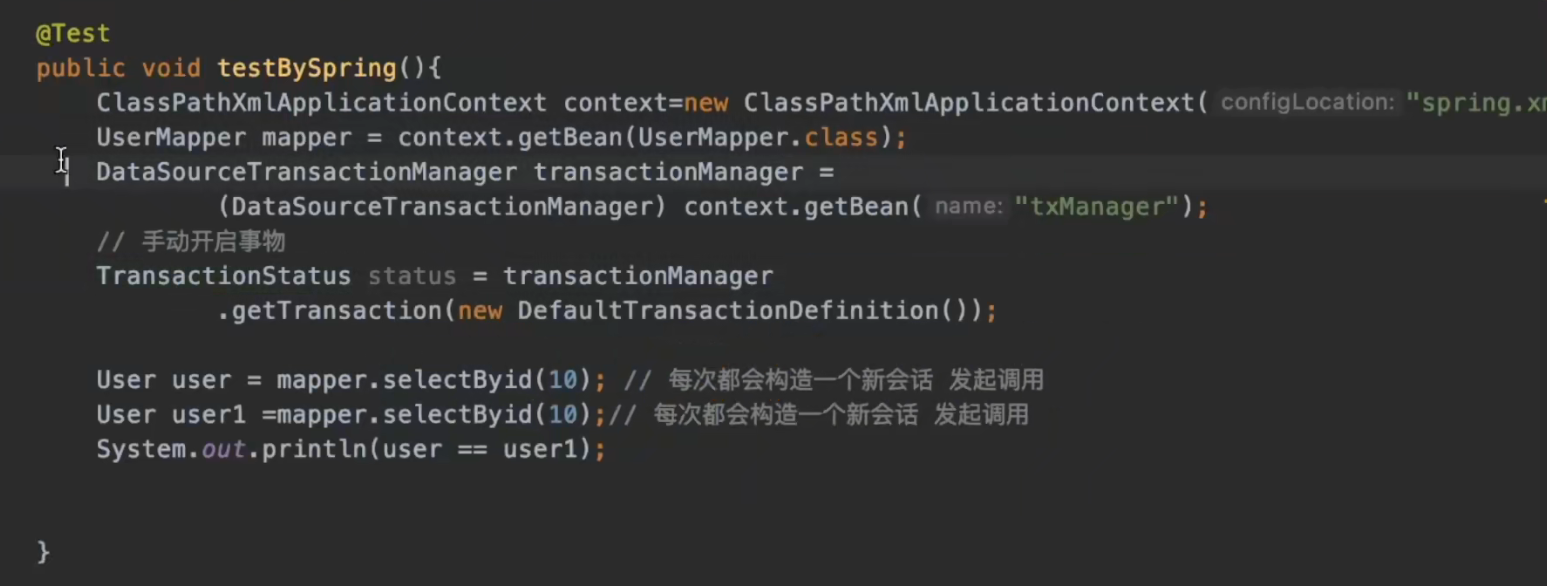
测试:
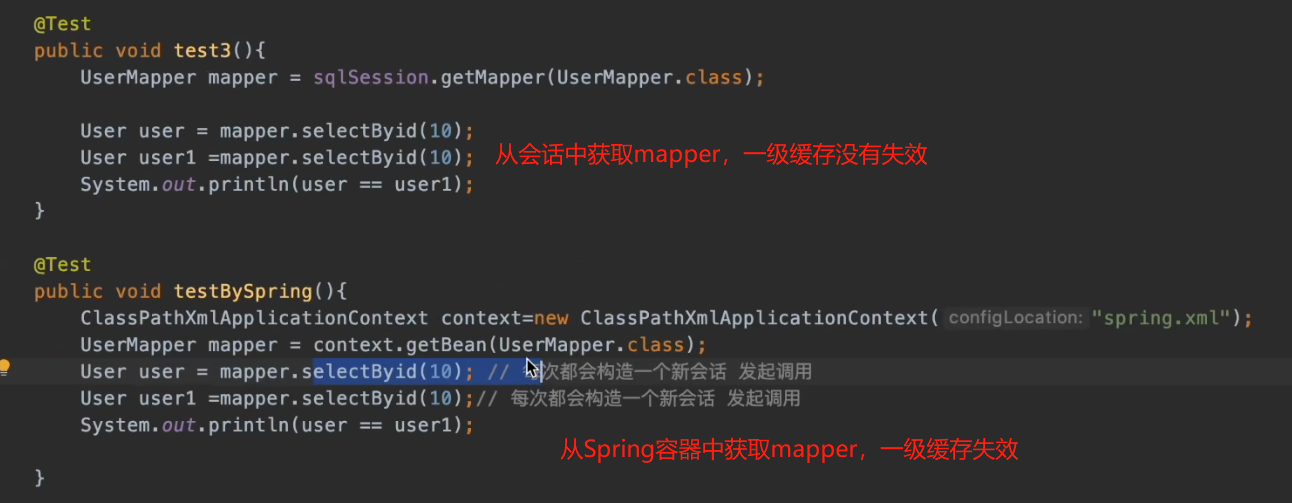
我们对下面的代码debug一下会发现两次查询使用的并不是一个执行器,所以那么必定也不是同一次会话,那么一级缓存也肯定会失效:
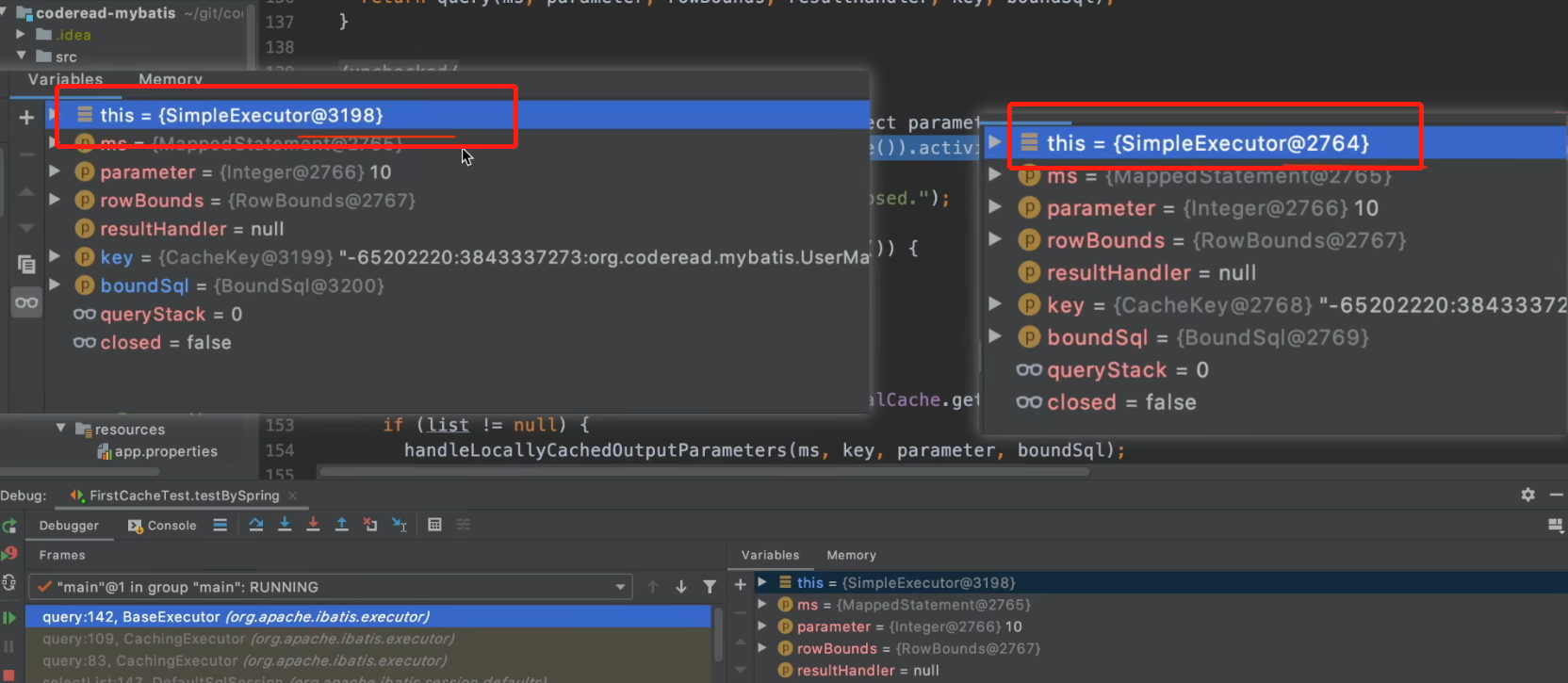
那么究竟是为什么让这两次查询没有处在同一个会话当中呢?
首先我们来回忆一下,在单独使用MyBatis框架的时候,我们使用Mapper接口中的方法直接就被代理到了sqlSession中的对应方法,然后再调用Executer中的方法。
Mapper接口这里的动态代理,是在解析配置文件的时候,使用了MapperRegistry中的add方法对映射器进行了注册,在注册的同时使用了MapperProxyFactory对Mapper接口进行了代理:
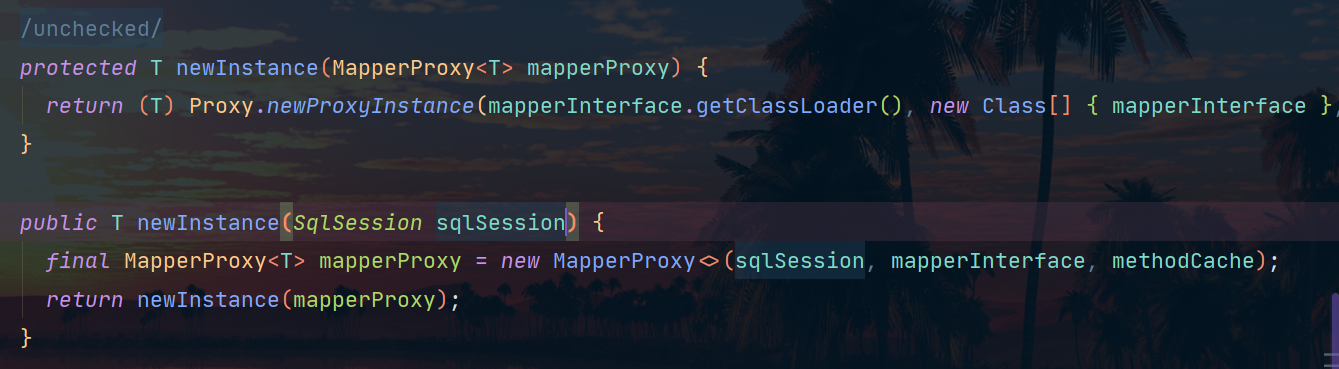
但是在Spring集成MyBatis时不是这样的。其具体过程如下图所示:
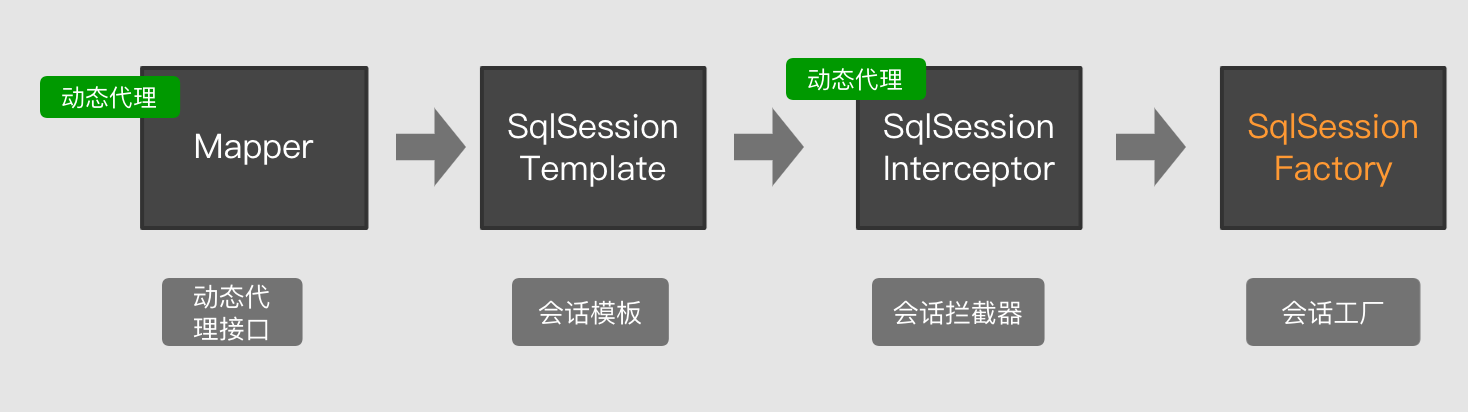
Mapper接口中的方法被代理到了SqlSessionTemplate中,而SqlSessionTemplate(SqlSession的一个实现类)中使用了代理,将所有的方法进行了拦截执行了SqlSessionInterceptor的逻辑。然后再在这个拦截器中通过SqlSessionFactory去调用SqlSession。
我们要知道动态代理的本质就是拦截
相当于将原来的步骤包了一层又一层。
我们在SqlSessionTemplate使用动态代理是因为每一个方法都要去构建DefaultSqlSession,那么我们干脆就全部拦截放在拦截器中去执行相关的逻辑。而在这个拦截器中有一个重要的方法叫做getSqlSession
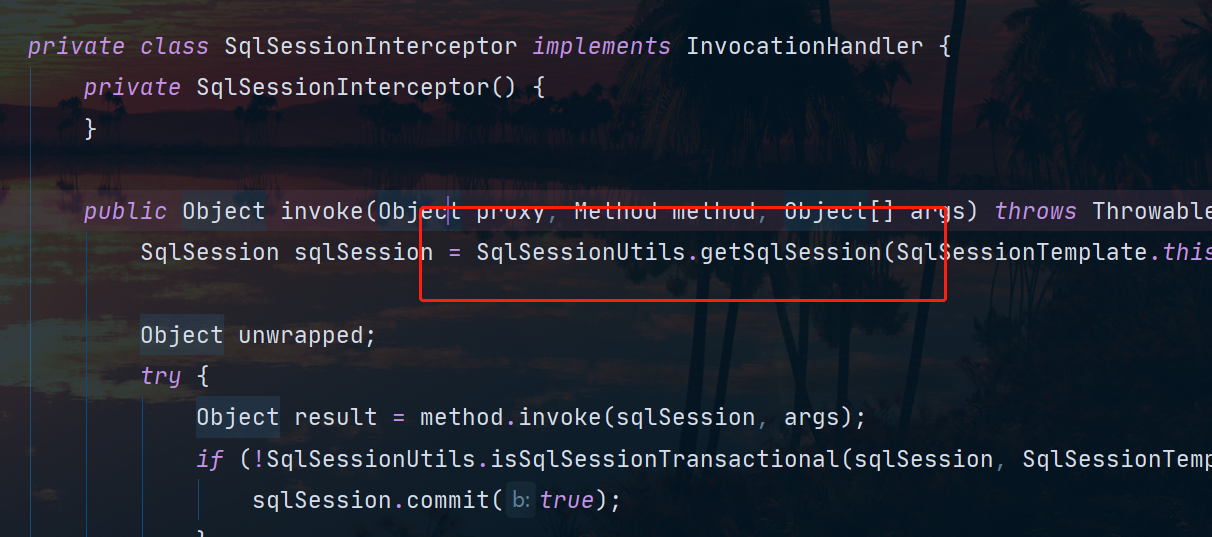
我们进入到这个方法中,可以看到一个叫做SqlSessionHolder的东西。这个SqlSessionHolder类似于ThreadLocal当我们再次构建会话完毕之后,会将这个会话保存在ThreadLocal中,当下次还要构建的时候如果符合相关条件就继续拿出来用,当我们没有开启事务的时候,这个地方从SqlSessionHolder中是拿不到会话的,于是会使用sessionFactory再新开一个会话:
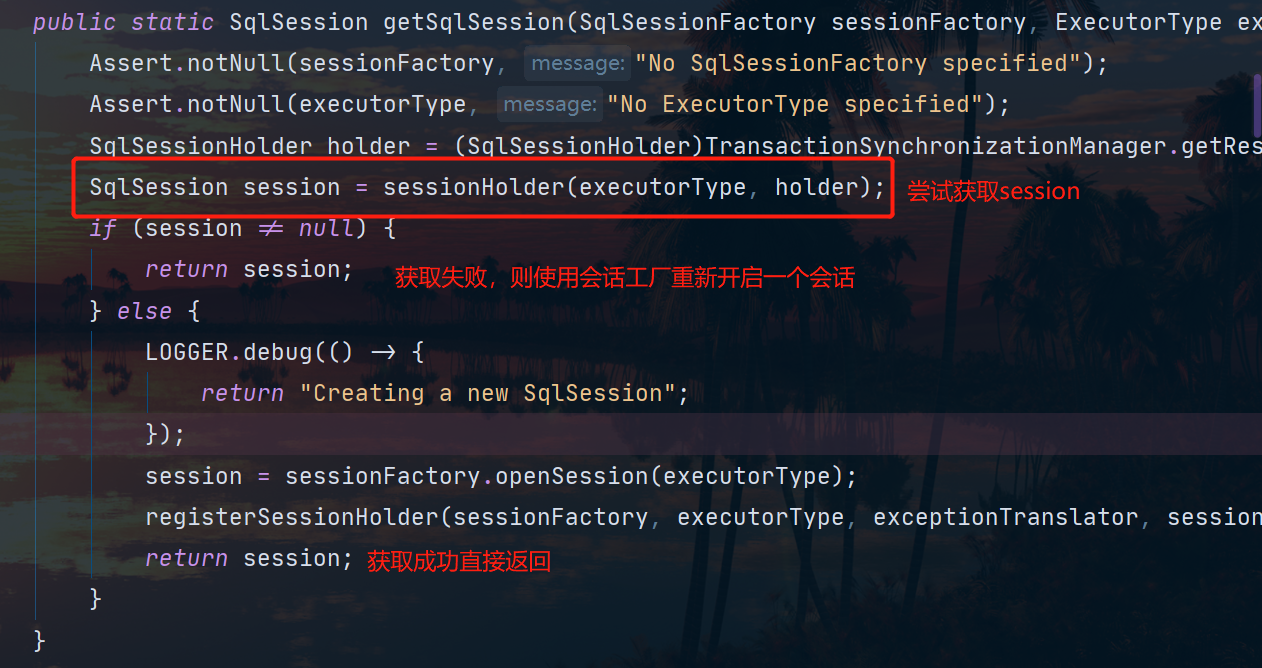
总结:
很多人发现,集成一级缓存后会话失效了,以为是spring Bug ,真正原因是Spring 对SqlSession进行了封装,通过SqlSessionTemplate ,使得每次调用Sql,都会重新构建一个SqlSession,具体参见SqlSessionInterceptor。而根据前面所学,一级缓存必须是同一会话才能命中,所以在这些场景当中不能命中。
怎么解决呢?给Spring 添加事物 即可。添加事物之后,SqlSessionInterceptor(会话拦截器)就会去判断两次请求是否在同一事物当中,如果是就会共用同一个SqlSession会话来解决。
二级缓存
二级缓存也称作是应用级缓存,与一级缓存不同的,是它的作用范围是整个应用,而且可以跨线程使用。所以二级缓存有更高的命中率,适合缓存一些修改较少的数据。在流程上是先访问二级缓存,再访问一级缓存。
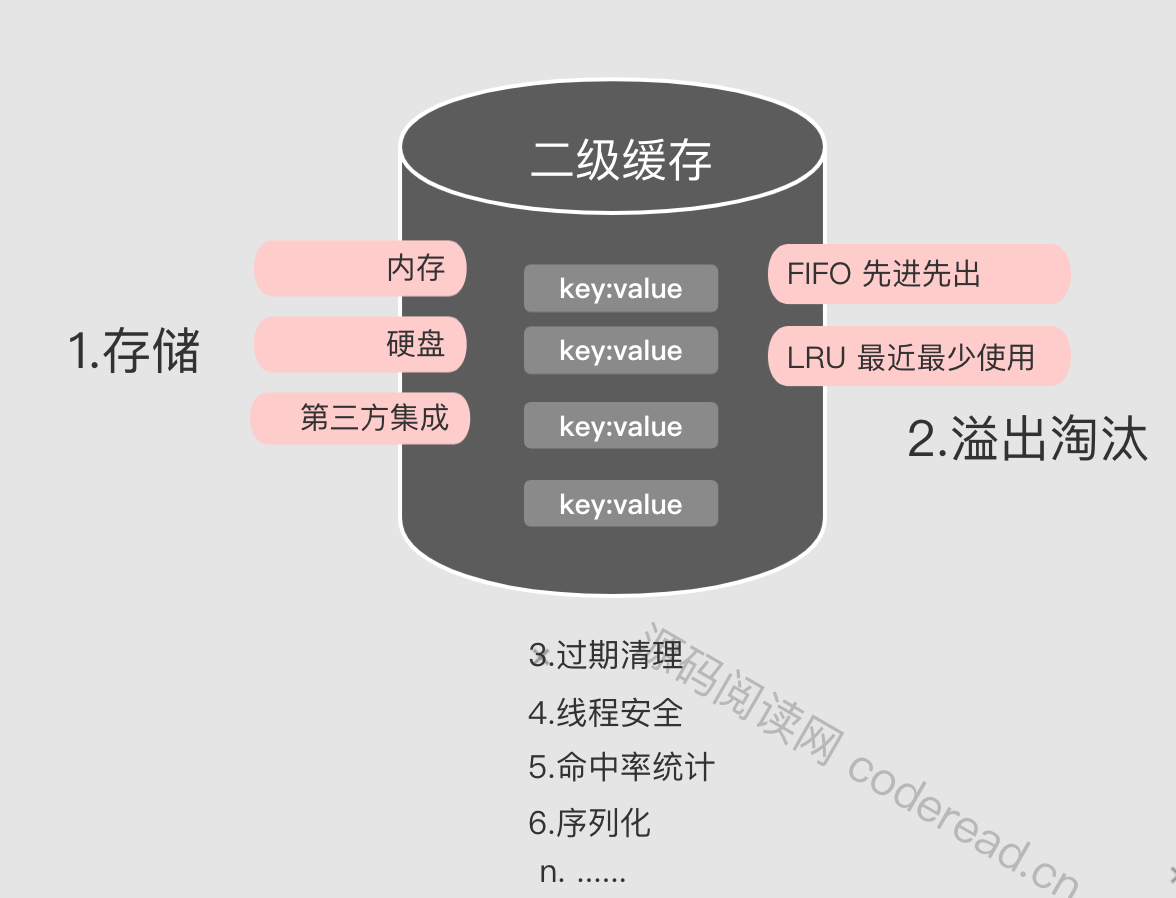
二级缓存是一个完整的缓存解决方案,那应该包含哪些功能呢?这里我们分为核心功能和非核心功能两类:
存储【核心功能】
即缓存数据库存储在哪里?常用的方案如下:
内存:最简单就是在内存当中,不仅实现简单,而且速度快。内存弊端就是不能持久化,且容易有限。硬盘:可以持久化,容量大。但访问速度不如内存,一般会结合内存一起使用。第三方集成:在分布式情况,如果想和其它节点共享缓存,只能第三方软件进行集成。比如Redis.
溢出淘汰【核心功能】
无论哪种存储都必须有一个容易,当容量满的时候就要进行清除,清除的算法即溢出淘汰机制。常见算法如下:
FIFO:先进先出LRU:最近最少使用WeakReference: 弱引用,将缓存对象进行弱引用包装,当Java进行gc的时候,不论当前的内存空间是否足够,这个对象都会被回收SoftReference:软引用,机理与弱引用类似,不同在于只有当空间不足时GC才回收软引用对象。
其它功能
-
过期清理:指清理存放数据过久的数据
-
线程安全:保证缓存可以被多个线程同时使用
-
写安全:当拿到缓存数据后,可对其进行修改,而不影响原本的缓存数据。通常采取做法是对缓存对象进行深拷贝。
二级缓存组件结构
这么多的功能,如何才能简单的实现,并保证它的灵活性与扩展性呢?这里MyBatis抽像出Cache接口,其只定义了缓存中最基本的功能方法:
- 设置缓存
- 获取缓存
- 清除缓存
- 获取缓存数量
然后上述中每一个功能都会对应一个组件类,并基于装饰者加责任链的模式,将各个组件进行串联。在执行缓存的基本功能时,其它的缓存逻辑会沿着这个责任链依次往下传递。
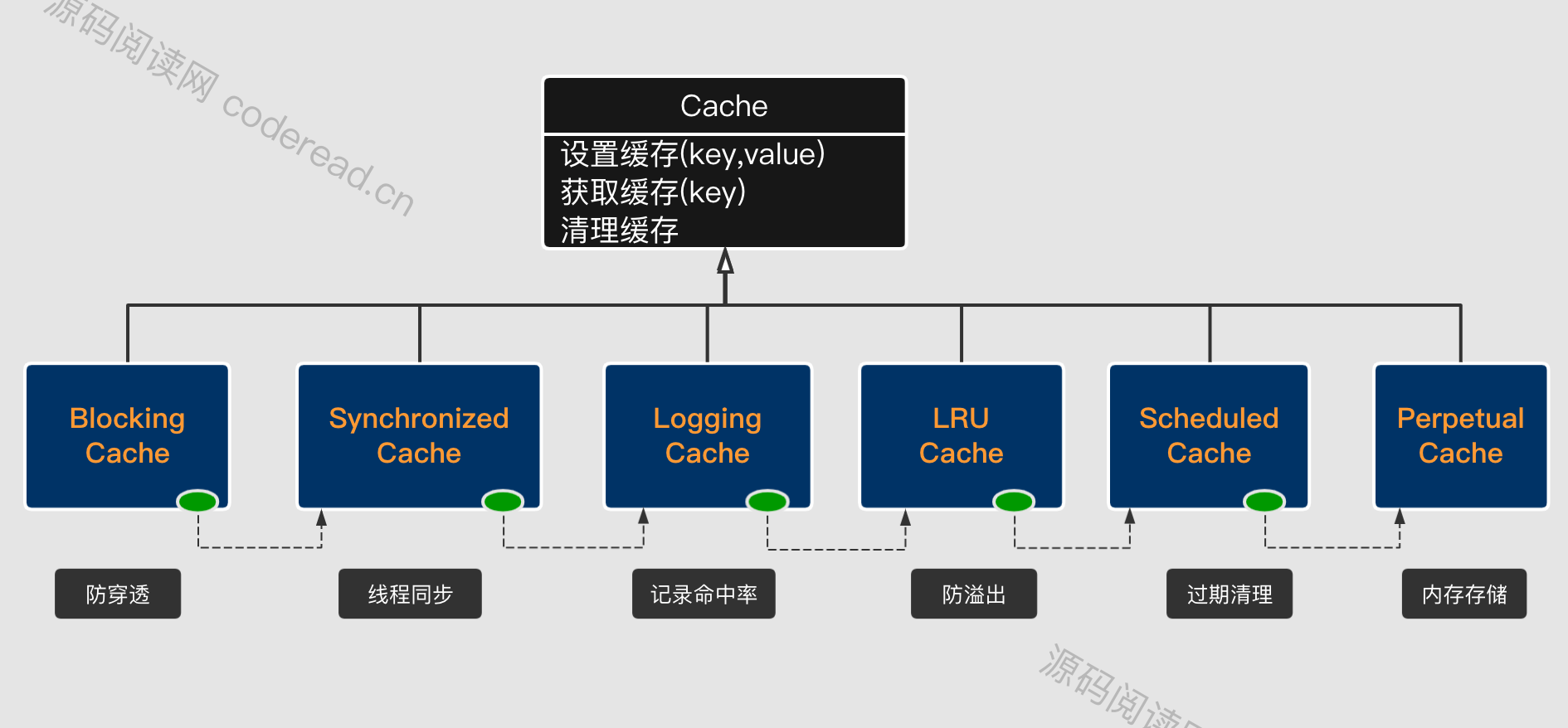
这样设计有以下优点:
- 职责单一:各个节点只负责自己的逻辑,不需要关心其它节点。
- 扩展性强:可根据需要扩展节点、删除节点,还可以调换顺序保证灵活性。
- 松耦合:各节点之间不没强制依赖其它节点。而是通过顶层的Cache接口进行间接依赖。
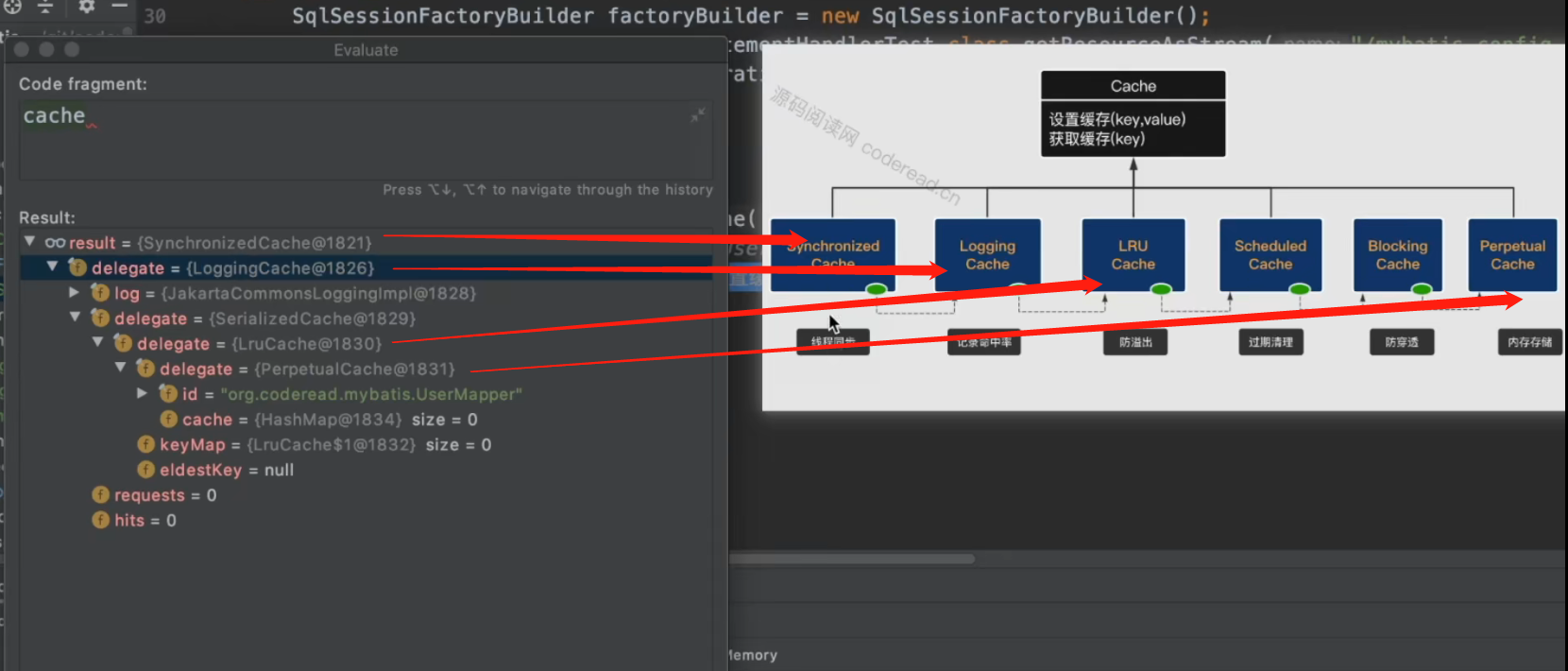
我们测试一下:
二级缓存的使用
二级默认缓存默认是不开启的,需要为其声明缓存空间才可以使用,有两种方法:
-
通过
@CacheNamespace
-
为指定的MappedStatement声明。
声明之后该缓存为该Mapper所独有,其它Mapper不能访问。如需要多个Mapper共享一个缓存空间可通过@CacheNamespaceRef 引用同一个缓存空间。
@CacheNamespace 详细配置见下表:

注:Cache中责任链条的组成即通过@CacheNamespace 指导生成。
除@CacheNamespace 还可以通过其它参数来控制二级缓存:

这里使用mybatis中的@Options注解进行配置:
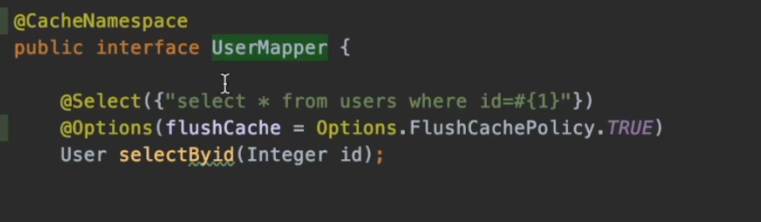
@Options注解用来自定义一些默认选项。
二级缓存命中条件
二级缓存的命中场景与一级缓存类似,不同在于二级缓存可以跨会话使用,还有就是二级缓存的更新,必须是在会话提交之后。
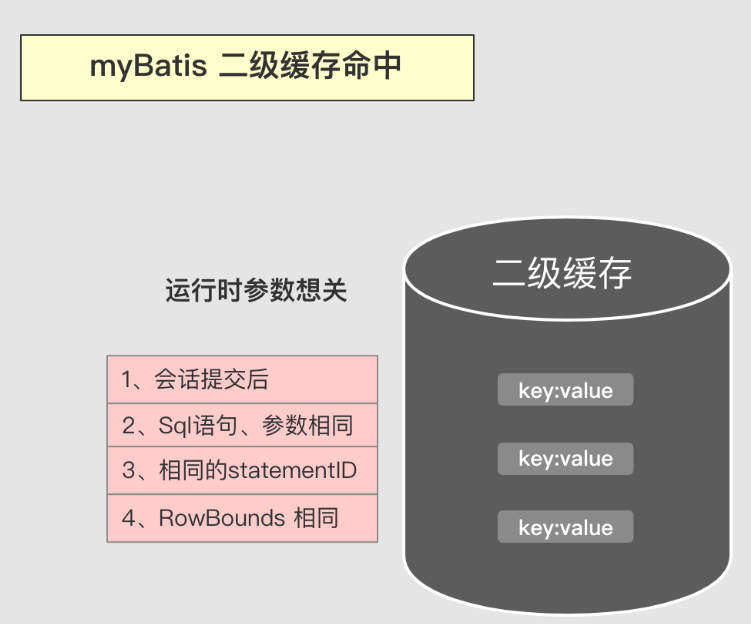
注意:
- 会话自动提交二级缓存不会生效
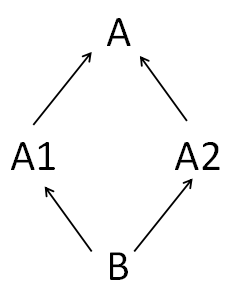
为什么要提交之后才能命中二级缓存?
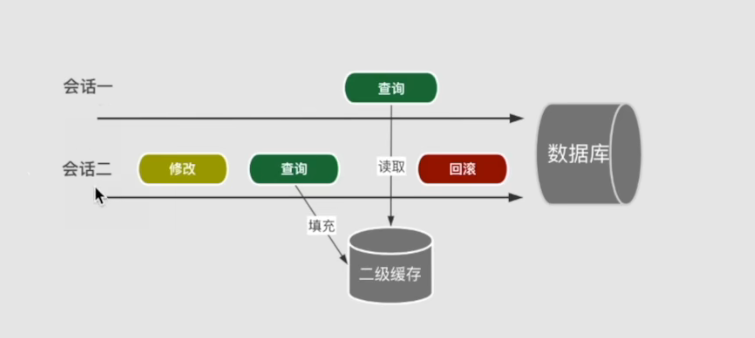
如上图两个会话在修改同一数据,当会话二修改后,再将其查询出来,假如它实时填充到二级缓存,而会话一就能过缓存获取修改之后的数据,但实质是修改的数据回滚了,并没真正的提交到数据库。这就会产生脏读的现象。
所以为了保证数据一至性,二级缓存必须是会话提交之才会真正填充,包括对缓存的清空,也必须是会话正常提交之后才生效。
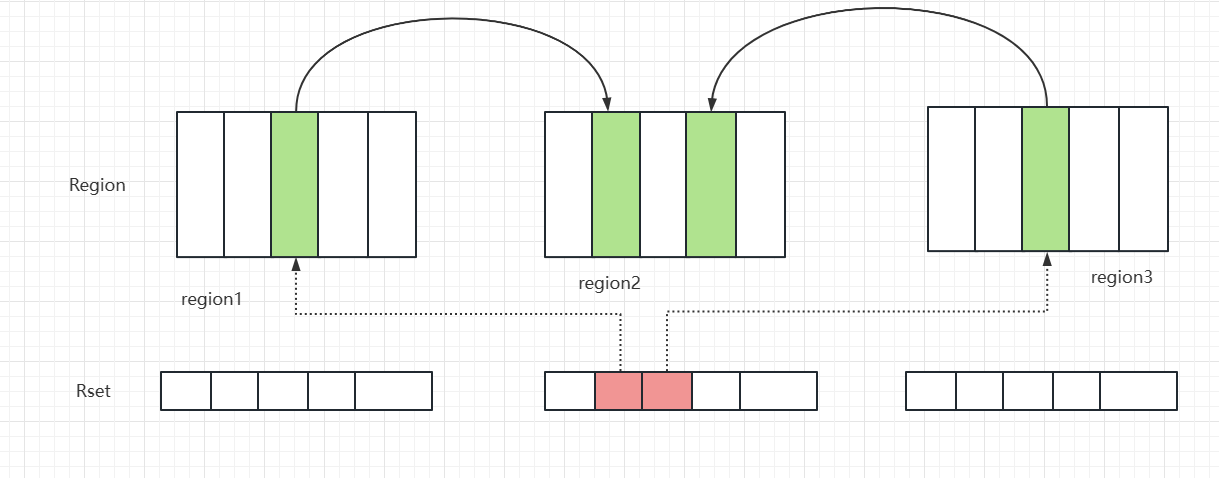
二级缓存结构
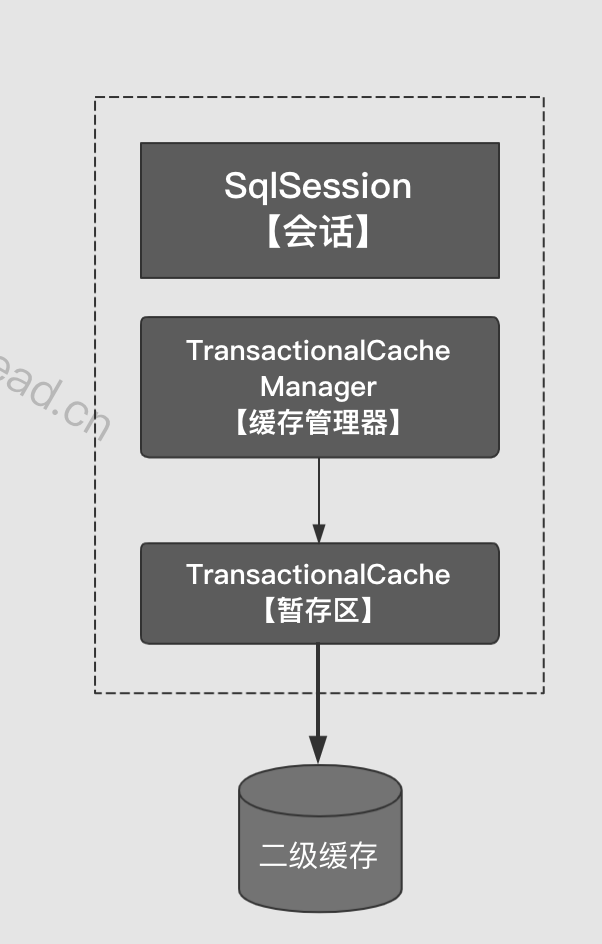
为了实现会话提交之后才变更二级缓存,MyBatis为每个会话设立了若干个暂存区,当前会话对指定缓存空间的变更,都存放在对应的暂存区,当会话提交之后才会提交到每个暂存区对应的缓存空间。为了统一管理这些暂存区,每个会话都一个唯一的事物缓存管理器。所以这里暂存区也可叫做事物缓存。
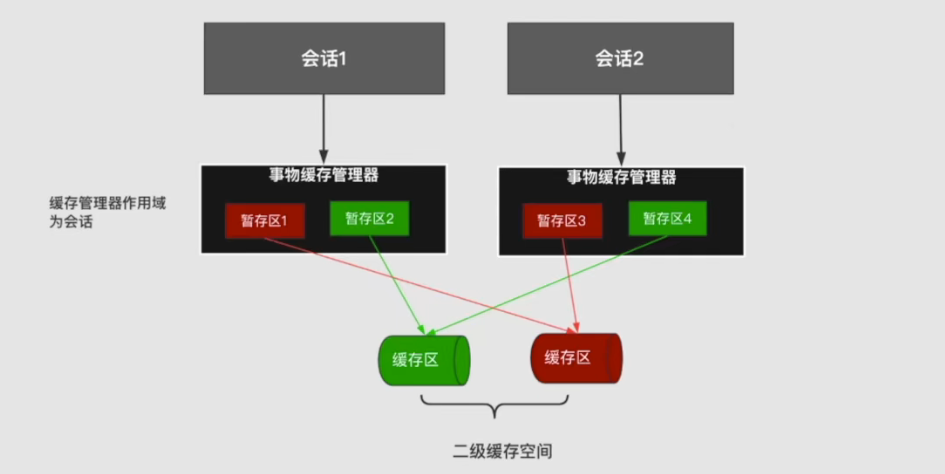
每一个会话对应一个事务缓存管理器。暂存区的个数就是你当前会话能访问到的缓存空间的个数
二级缓存执行流程
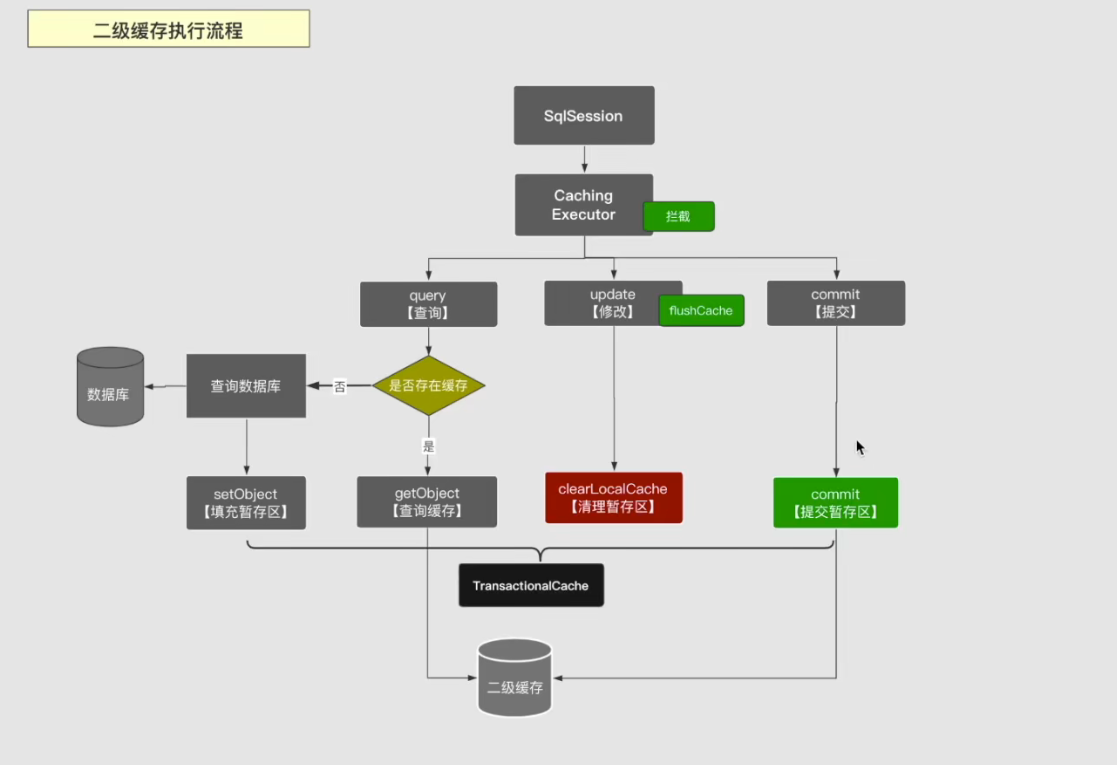
原本会话是通过Executor实现SQL调用,这里基于装饰器模式使用CachingExecutor对SQL调用逻辑进行拦截。以嵌入二级缓存相关逻辑:
查询操作query:当会话调用query() 时,会基于查询语句、参数等数据组成缓存Key,然后尝试从二级缓存中读取数据。读到就直接返回,没有就调用被装饰的Executor去查询数据库,然后在填充至对应的暂存区。- 请注意,这里的查询是实时从缓存空间读取的,而变更,只会记录在暂存区
更新操作update:当执行update操作时,同样会基于查询的语句和参数组成缓存KEY,然后在执行update之前清空缓存。这里清空只针对暂存区,同时记录清空的标记,以便当会话提交之时,依据该标记去清空二级缓存空间。- 如果在查询操作中配置了flushCache=true ,也会执行相同的操作。
提交操作commit:当会话执行commit操作后,会将该会话下所有暂存区的变更,更新到对应二级缓存空间去。