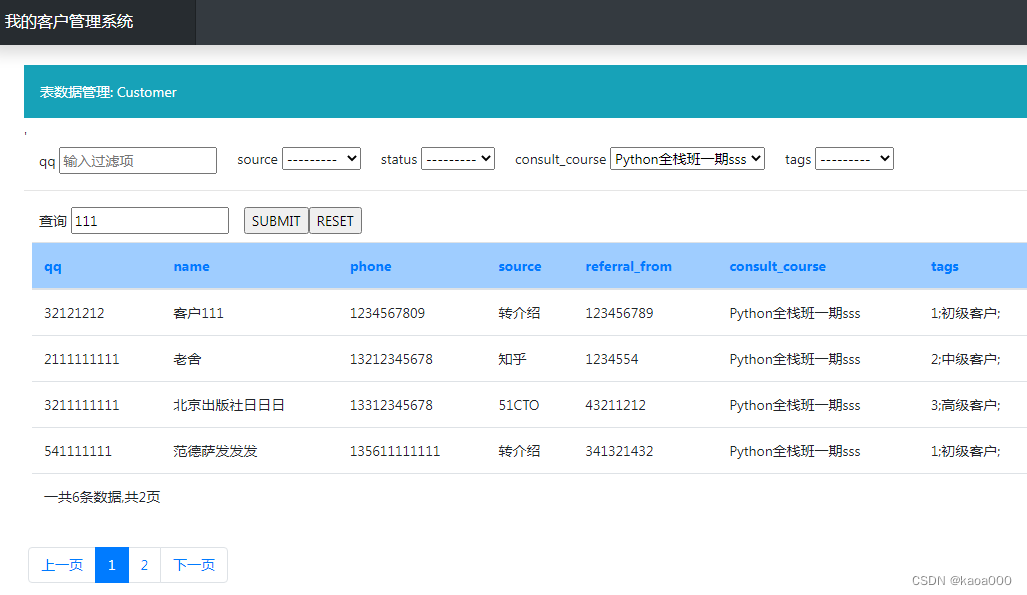
对于数据很多,就需要将数据进行分页显示,同时还要提供过滤功能。
当配置文件中配置了过滤条件,那就要在显示表信息的时候,显示过滤条件选择项,选择后进行过滤,然后下面显示过滤后的数据,如果数据过多,则分页显示。
配置文件在ClassAdmin中配置,如Customer的配置文件:
class CustomerAdmin(BaseAdmin):
list_display = ['qq','name','phone','source','referral_from','consult_course','tags','status']
list_per_page = 3
list_filter = ['source','status','qq']配置了过滤按source和status,每页显示3条。
一、显示页码的实现
实现如下样式页码:

实现方式是在后端形成页码的html代码,然后嵌入。前端部分代码
<div class="p-1 mb-2 text-info">
<nav aria-label="Page navigation">
<ul class="pagination">
{{ page_tag | safe }}
{# <li class="page-item"><a class="page-link" href="#">Previous</a></li>#}
{# <li class="page-item active"><a class="page-link" href="/mytestapp/plcrm/customer/?p=1">1</a></li>#}
{# <li class="page-item"><a class="page-link" href="/mytestapp/plcrm/customer/?p=2">2</a></li>#}
{# <li class="page-item"><a class="page-link" href="#">3</a></li>#}
{# <li class="page-item"><a class="page-link" href="#">Next</a></li>#}
</ul>
</nav>
</div>主要是page_tag,在视图函数中形成此页码代码:
def display_table_objs(req,app_name,table_name):
url_path = req.path
current_page = int(req.GET.get('p',1))
admin_class = mytestapp_admin.enable_admins[app_name][table_name]
per_page = admin_class.list_per_page
total_count = admin_class.model.objects.count()
obj_page = PageHelper(total_count,current_page,url_path,page_rec_count=per_page)
page_tag = obj_page.pager_tag_str()
return render(req,"mytestapp/table_objs.html",{"admin_class":admin_class,"model_class_name":admin_class.model.__name__,'page_tag':page_tag,'obj_page':obj_page,'total_count':total_count})
这里借助了以前写的页码形成的组件PageHelper类:
class PageHelper:
# 产生一个分页字符串,形式如下:
# 上一页 1 2 3 4 5 6 7 8 9 10 11 下一页
def __init__(self,total_rec_count,current_page,base_url,page_rec_count=10):
# total_rec_count:查询到的记录的总条数
# current_page:当前页码,即要显示哪一页,点击相应页码时的页码值
# base_url:查询使用的url
# page_rec_count:每页显示的记录条数,默认10条
self.total_rec_count = total_rec_count
self.current_page = current_page
self.page_rec_count = page_rec_count
self.base_url = base_url
@property
def page_rec_start(self):
# 返回当前显示页的记录的开始值
return (self.current_page - 1)*self.page_rec_count
@property
def page_rec_end(self):
# 返回当前显示页的记录的结束值
return self.current_page * self.page_rec_count
def total_page_count(self):
# 计算总共有多少页
v, a = divmod(self.total_rec_count, self.page_rec_count)
if a != 0:
v += 1
return v
def pager_tag_str(self):
# 返回一个页码字符串
v = self.total_page_count()
page_list = []
# 判断输入的页码是否在合理范围内,因为是get请求,可以在地址栏中随意输入
# 如果请求的页码小于1,就设为1,如果请求的页码大于总页码,就设为最后一个页码
if self.current_page < 1:
self.current_page = 1
elif self.current_page > v:
self.current_page = v
# 页码只显示最多N条,这里假设11条,加上前后的上一页和下一页
# 例如显示第10页,则页码显示10的前后5条,即从5到15页显示在页面上
if v <= 11:
# 页数小于11页,所有页码都显示出来就可以了
page_range_start = 1
page_range_end = v + 1
else:
if self.current_page < 6:
# 总的页数大于11,并且当前选择的页码小于6,显示的是从1开始的11个页码
page_range_start = 1
page_range_end = 12
else:
# 总的页数大于11,并且当前选择的页码大于等于6,显示的页码是当前页的前后5个加上当前页共11个页码
# 此时,显示的开始页码就是当前页-5,显示的最后页码就是当前页+5,range范围需要在加1.
page_range_start = self.current_page - 5
page_range_end = self.current_page + 5 + 1
if page_range_end > v:
page_range_end = v + 1
page_range_start = v - 10
if self.current_page == 1:
# 当前页码为1时,上一页不能在进行计算
page_list.append('<li class="page-item"><a class="page-link" href="javascript:void(0)">上一页</a></li>')
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?p=%s">上一页</a></li>' % (self.base_url,self.current_page - 1,))
for i in range(page_range_start, page_range_end):
if i == self.current_page:
# 对于当前选择的页码,需要突出显示
page_list.append('<li class="page-item active"><a class="page-link" href="%s?p=%s">%s</a></li>' % (self.base_url,i, i))
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?p=%s">%s</a></li>' % (self.base_url,i, i))
if self.current_page == v:
# 当前页码为最后一页时,下一页不能在进行计算
page_list.append('<li class="page-item"><a class="page-link" href="javascript:void(0)">下一页</a></li>')
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?p=%s">下一页</a></li>' % (self.base_url,self.current_page + 1,))
page_tag = "".join(page_list)
return page_tag二、实现过滤功能,就是增加查询项,将上面显示页面的测试,换成下列选择框,然后提交,后端做条件查询。
先在前端加上静态下拉框,
<form>
<div class="row" style="padding-left: 10px;">
<div class="col-sm">
<span>qq:</span>
<select name="qq">
<option value="">---------</option>
<option value="33333">333333</option>
</select>
</div>
<div class="col-sm">
<span>status:</span>
<select name="status">
<option value="">---------</option>
<option value="1">1</option>
</select>
</div>
<div class="col-sm">
<span>source:</span>
<select name="source">
<option value="">---------</option>
<option value="2">222222</option>
</select>
</div>
<div class="col-sm">
<input type="submit" value="SUBMIT"/>
</div>
</div>
</form>样子希望如下:
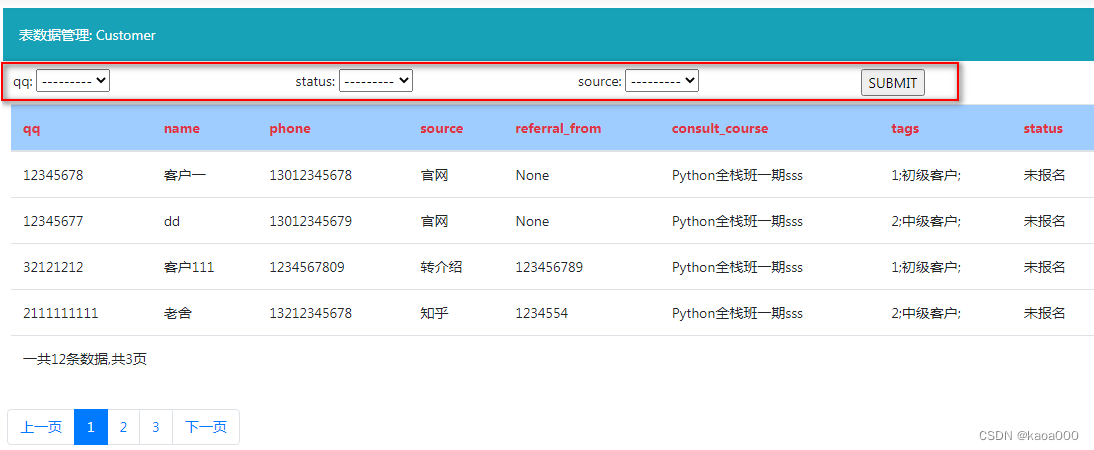
要动态生成红框中的部分,要解决的问题,一是根据Admin_class中的配置项filter_list动态生成下拉框,二是解决页码问题。有过滤项后,显示的数据是过滤后的数据,页码也应该是过滤后的记录的页码,而上一步生成页码,默认是全部数据进行分页。
在前端页面增加如下代码:

视图函数中生成一个filter_tag变量,这个变量保存生成的过滤栏的html代码,看一下视图函数:
def display_table_objs(req,app_name,table_name):
url_path = req.path # 请求的路径
current_page = int(req.GET.get('p',1)) # 当前页,如果没有,即第一次查询,页面为1
admin_class = mytestapp_admin.enable_admins[app_name][table_name]
filter_f_a = {} # 保存传递过来的过虑项键值对
for filter_f in admin_class.list_filter:
f_temp = req.GET.get(filter_f)
if f_temp:
filter_f_a[filter_f] = f_temp
filter_url = ""
if filter_f_a.__len__() != 0:
for k,v in filter_f_a.items():
filter_url = filter_url +"&"+ k + "=" + str(v)
# 按照过滤键值对,生成页码显示时的过滤字符串,如&source=1&tags=2,在有过滤的情况下,页码必须带上过滤条件,否则就是全部数据
per_page = admin_class.list_per_page # 每页多少条数据
total_count = admin_class.model.objects.filter(**filter_f_a).count() # 查询数据的总条数
obj_page = PageHelper(total_count,current_page,url_path,page_rec_count=per_page,filter_url=filter_url)
page_tag = obj_page.pager_tag_str()
filter_tag = myutils.built_filter_tag(admin_class,filter_f_a)
return render(req,"mytestapp/table_objs.html",{"admin_class":admin_class,"model_class_name":admin_class.model.__name__,'page_tag':page_tag,'obj_page':obj_page,'total_count':total_count,'filter_tag':filter_tag,'filter_f_a':filter_f_a})
url_path是请求的路径,在形成页码的a标签时,是href的值的一部分,href的格式如下:
href=/mytestapp/plcrm/customer/?consult_course=1&tags=2&p=1
url_path就是问号?前的部分,filter_url就是过滤部分,p也是过滤条件,但不是输入框输入的,是页码值,通过这个几个部分,共同组成页码对应的访问地址。
PageHelper类进行修改,增加参数filter_url,在形成页码时,将过滤条件加上。
filter_tag由built_filter_tag形成:
# 将分页做成一个通用的工具类
class PageHelper:
# 产生一个分页字符串,形式如下:
# 上一页 1 2 3 4 5 6 7 8 9 10 11 下一页
def __init__(self,total_rec_count,current_page,base_url,page_rec_count=10,filter_url=""):
# total_rec_count:查询到的记录的总条数
# current_page:当前页码,即要显示哪一页,点击相应页码时的页码值
# base_url:查询使用的url
# page_rec_count:每页显示的记录条数,默认10条
self.total_rec_count = total_rec_count
self.current_page = current_page
self.page_rec_count = page_rec_count
self.base_url = base_url
self.filter_url = filter_url
@property
def page_rec_start(self):
# 返回当前显示页的记录的开始值
return (self.current_page - 1)*self.page_rec_count
@property
def page_rec_end(self):
# 返回当前显示页的记录的结束值
return self.current_page * self.page_rec_count
def total_page_count(self):
# 计算总共有多少页
v, a = divmod(self.total_rec_count, self.page_rec_count)
if a != 0:
v += 1
return v
def pager_tag_str(self):
# 返回一个页码字符串
v = self.total_page_count()
page_list = []
# 判断输入的页码是否在合理范围内,因为是get请求,可以在地址栏中随意输入
# 如果请求的页码小于1,就设为1,如果请求的页码大于总页码,就设为最后一个页码
if self.current_page < 1:
self.current_page = 1
elif self.current_page > v:
self.current_page = v
# 页码只显示最多N条,这里假设11条,加上前后的上一页和下一页
# 例如显示第10页,则页码显示10的前后5条,即从5到15页显示在页面上
if v <= 11:
# 页数小于11页,所有页码都显示出来就可以了
page_range_start = 1
page_range_end = v + 1
else:
if self.current_page < 6:
# 总的页数大于11,并且当前选择的页码小于6,显示的是从1开始的11个页码
page_range_start = 1
page_range_end = 12
else:
# 总的页数大于11,并且当前选择的页码大于等于6,显示的页码是当前页的前后5个加上当前页共11个页码
# 此时,显示的开始页码就是当前页-5,显示的最后页码就是当前页+5,range范围需要在加1.
page_range_start = self.current_page - 5
page_range_end = self.current_page + 5 + 1
if page_range_end > v:
page_range_end = v + 1
page_range_start = v - 10
if self.current_page == 1:
# 当前页码为1时,上一页不能在进行计算
page_list.append('<li class="page-item"><a class="page-link" href="javascript:void(0)">上一页</a></li>')
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?%sp=%s">上一页</a></li>' % (self.base_url,self.filter_url,self.current_page - 1,))
for i in range(page_range_start, page_range_end):
if i == self.current_page:
# 对于当前选择的页码,需要突出显示
page_list.append('<li class="page-item active"><a class="page-link" href="%s?%sp=%s">%s</a></li>' % (self.base_url,self.filter_url,i, i))
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?%sp=%s">%s</a></li>' % (self.base_url,self.filter_url,i, i))
if self.current_page == v:
# 当前页码为最后一页时,下一页不能在进行计算
page_list.append('<li class="page-item"><a class="page-link" href="javascript:void(0)">下一页</a></li>')
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?%sp=%s">下一页</a></li>' % (self.base_url,self.filter_url,self.current_page + 1,))
page_tag = "".join(page_list)
return page_tagfrom django.utils.timezone import datetime,timedelta
def built_filter_tag(admin_class,filter_f):
filter_tag = ""
if admin_class.list_filter.__len__()>0:
filter_tag = filter_tag + ''''<form>
<div class="row" style="padding-left: 10px;">'''
for filter_item in admin_class.list_filter:
filter_tag = filter_tag + '''
<div style="float:left;margin-left:20px;">
<span> %s</span>
%s
</div>''' %(filter_item,filter_tag_value(admin_class,filter_item,filter_f))
filter_tag = filter_tag + '''<div class="col-sm">
<input type="submit" value="SUBMIT"/><input type="reset" value="RESET" />
</div>
</div>
</form>'''
return filter_tag
def filter_tag_value(admin_class,filter_item,filter_f):
models_class = admin_class.model
option_tag =""
field_obj = models_class._meta.get_field(filter_item)
# 如果是外键,使用select标签
if type(field_obj).__name__ in ['ForeignKey','OneToOneFiled','ManyToManyField']:
option_tag =option_tag + '<select name="%s">'%(filter_item)
tt = field_obj.get_choices()
for t in tt:
if (filter_item in filter_f) and str(t[0]) == filter_f[filter_item]:
option_tag = option_tag + '<option value="%s" selected>%s</option>'%(str(t[0]),t[1])
else:
option_tag = option_tag + '<option value="%s">%s</option>' % (str(t[0]), t[1])
option_tag = option_tag + '</select>'
# 如果含有choices,使用select标签
elif field_obj.choices:
option_tag = option_tag + '<select name="%s">'%(filter_item)
option_tag = option_tag + '<option value="" >---------</option>'
for t in field_obj.choices:
# print('显示choices:',print(t[0],type(t[0]),filter_f[filter_item],type(filter_f[filter_item])) if (filter_item in filter_f) else print('bucunzai'))
if (filter_item in filter_f) and str(t[0]) == filter_f[filter_item]:
option_tag = option_tag + '<option value="%s" selected>%s</option>' % (str(t[0]), t[1])
else:
option_tag = option_tag + '<option value="%s">%s</option>' % (str(t[0]), t[1])
option_tag = option_tag + '</select>'
# 如果是日期型,构造如下的结构,使用select标签
elif type(field_obj).__name__ in ['DateTimeField','DateField']:
date_els = []
today_ele = datetime.now().date()
date_els.append(['今天', datetime.now().date()])
date_els.append(["昨天", today_ele - timedelta(days=1)])
date_els.append(["近7天", today_ele - timedelta(days=7)])
date_els.append(["本月", today_ele.replace(day=1)])
date_els.append(["近30天", today_ele - timedelta(days=30)])
date_els.append(["近90天", today_ele - timedelta(days=90)])
date_els.append(["近180天", today_ele - timedelta(days=180)])
date_els.append(["本年", today_ele.replace(month=1, day=1)])
date_els.append(["近一年", today_ele - timedelta(days=365)])
option_tag = option_tag + '<select name="' + filter_item + '">'
option_tag = option_tag + '<option value="" >---------</option>'
for t in date_els:
option_tag = option_tag + '<option value="%s">%s</option>'%(t[1],t[0])
option_tag = option_tag + '</select>'
# 以上类型都不是,就使用输入框input text
else:
if (filter_item in filter_f):
option_tag = option_tag + '<input type="text" placeholder="输入过滤项" name="%s" value="%s"/>' % (filter_item,filter_f[filter_item])
else:
option_tag = option_tag + '<input type="text" placeholder="输入过滤项" name="%s"/>' % (filter_item)
return option_tag关于过滤标签的形成,关键的几点:
1)根据字段类型,形成不同的标签,如下拉标签、输入框等;
2)在进行页码切换时,需要保持过虑项的原值;
三、数据排序,点击数据列表的字段,实现按相关字段进行排序,排序是在过滤以后的结果上进行的。
首先是对表头字段的修改,改为a标签:
<thead> <!-- 表头显示要显示表的各字段名称-->
<tr class="text-danger" style="background-color: #9fcdff;">
{# {% for column in admin_class.list_display %}#}
{# <!-- 对admin_class中list_display列表进行遍历,就是取出要显示的字段,作为表头字段-->#}
{# <th colspan="6">{{ column }} </th>#}
{# {% endfor %}#}
{{ header_order_tag | safe }}
</tr>
</thead>这里直接在视图函数中组装表头标签,动态生成,在三种状态间转换:默认无排序,点击第一次,按升序排序,字段后边加上上箭头“↑”,点击第二次,按降序排序,字段后边加上下箭头“↓”,第三次点击,又变为默认无排序。
def display_table_objs(req,app_name,table_name):
url_path = req.path
current_order_mark = req.GET.get('order_mark','0')
current_page = int(req.GET.get('p',1))
admin_class = mytestapp_admin.enable_admins[app_name][table_name]
filter_f_a = {} # 保存传递过来的顾虑项键值对
for filter_f in admin_class.list_filter:
f_temp = req.GET.get(filter_f)
if f_temp:
filter_f_a[filter_f] = f_temp
print('filter_f_a:',filter_f_a)
filter_url = ""
# 过滤条件形成请求地址的参数串
if filter_f_a.__len__() != 0:
for k,v in filter_f_a.items():
filter_url = filter_url + k + "=" + str(v) +"&"
print(filter_url)
order_url = ""
if current_order_mark == '0':
order_url = filter_url
else:
order_url = order_url + "order_mark=" + current_order_mark +"&"
per_page = admin_class.list_per_page
total_count = admin_class.model.objects.filter(**filter_f_a).count()
print('url_path:',url_path)
obj_page = PageHelper(total_count,current_page,url_path,page_rec_count=per_page,filter_url=filter_url,order_url=order_url)
page_tag = obj_page.pager_tag_str()
filter_tag = myutils.built_filter_tag(admin_class,filter_f_a,url_path)
header_order_tag = myutils.order_tag(admin_class,url_path,filter_url,current_order_mark)
return render(req,"mytestapp/table_objs.html",{"admin_class":admin_class,"model_class_name":admin_class.model.__name__,
'page_tag':page_tag,'obj_page':obj_page,'total_count':total_count,
'filter_tag':filter_tag,'filter_f_a':filter_f_a,'header_order_tag':header_order_tag,'order_mark':current_order_mark})增加current_order_mark,记录当前排序标志,如果是没有排序,前端不传递order_mark参数,默认取值‘0’,否则,就是传递过来的值,主要是“字段名”或“-字段名”,减号+字段名,在使用model类的order_by()时,字段名前加减号,就是降序排序。
order_url,是形成排序参数字段的,即形成order_mark=id&这种形式,然后拼接到a标签的请求地址中传递到后台,后台根据这个值进行排序。
注意三个url串:url_path、filter_url、order_url的区别,url_path是请求的地址,filter_url是请求的过滤参数,order_url是请求的排序参数。
字段头的html字符串是header_order_tag,其形成函数:myutils.order_tag(admin_class,url_path,filter_url,current_order_mark)
def order_tag(admin_class,url_path,filter_url,order_mark):
header_order_tag = ""
if order_mark == 0:
for column in admin_class.list_display:
header_order_tag = header_order_tag + '<th colspan="6"><a href="%s?%sorder_mark=%s"> %s</a></th>'%(url_path,filter_url,column,column)
elif not order_mark.startswith('-'):
for column in admin_class.list_display:
if order_mark == column:
header_order_tag = header_order_tag + '<th colspan="6"><a href="%s?%sorder_mark=%s"> %s</a><span>↑</span></th>'%(url_path,filter_url,'-'+column,column)
else:
header_order_tag = header_order_tag + '<th colspan="6"><a href="%s?%sorder_mark=%s"> %s</a></th>' % (url_path, filter_url, column, column)
else:
for column in admin_class.list_display:
if order_mark[1:] == column:
header_order_tag = header_order_tag + '<th colspan="6"><a href="%s?%s"> %s</a><span>↓</span></th>'%(url_path,filter_url,column)
else:
header_order_tag = header_order_tag + '<th colspan="6"><a href="%s?%sorder_mark=%s"> %s</a></th>' % (url_path, filter_url, column, column)
return header_order_tag这里要注意的是:order_mark='0',表明当前不排序,但是其a标签的href,即请求地址,是下一次点击的地址,即升序排序的地址,order_mark值是字段名,依此类推。
同时,分页标签也要进行修改,页码的地址要将排序参数加上:
obj_page = PageHelper(total_count,current_page,url_path,page_rec_count=per_page,filter_url=filter_url,order_url=order_url)
# 将分页做成一个通用的工具类
class PageHelper:
# 产生一个分页字符串,形式如下:
# 上一页 1 2 3 4 5 6 7 8 9 10 11 下一页
def __init__(self,total_rec_count,current_page,base_url,page_rec_count=10,filter_url="",order_url=""):
# total_rec_count:查询到的记录的总条数
# current_page:当前页码,即要显示哪一页,点击相应页码时的页码值
# base_url:查询使用的url
# page_rec_count:每页显示的记录条数,默认10条
self.total_rec_count = total_rec_count
self.current_page = current_page
self.page_rec_count = page_rec_count
self.base_url = base_url
self.filter_url = filter_url
self.order_url = order_url # 增加排序标志字段
# ..... 中间不变的省略
def pager_tag_str(self):
# ..... 中间不变的省略
if self.current_page == 1:
# 当前页码为1时,上一页不能在进行计算
page_list.append('<li class="page-item"><a class="page-link" href="javascript:void(0)">上一页</a></li>')
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?%s%sp=%s">上一页</a></li>' % (self.base_url,self.filter_url,self.order_url,self.current_page - 1,))
for i in range(page_range_start, page_range_end):
if i == self.current_page:
# 对于当前选择的页码,需要突出显示
page_list.append('<li class="page-item active"><a class="page-link" href="%s?%s%sp=%s">%s</a></li>' % (self.base_url,self.filter_url,self.order_url,i, i))
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?%s%sp=%s">%s</a></li>' % (self.base_url,self.filter_url,self.order_url,i, i))
if self.current_page == v:
# 当前页码为最后一页时,下一页不能在进行计算
page_list.append('<li class="page-item"><a class="page-link" href="javascript:void(0)">下一页</a></li>')
else:
page_list.append('<li class="page-item"><a class="page-link" href="%s?%s%sp=%s">下一页</a></li>' % (self.base_url,self.filter_url,self.order_url,self.current_page + 1,))
page_tag = "".join(page_list)
return page_tag主要注意a标签的href变化。
最后就是数据的形成:
@register.simple_tag
def get_query_sets_1(admin_class,obj_page,filter_f,order_mark):
print('order_mark:',order_mark)
if order_mark == '0':
return_sets = admin_class.model.objects.filter(**filter_f)[obj_page.page_rec_start:obj_page.page_rec_end]
else:
return_sets = admin_class.model.objects.filter(**filter_f).order_by(order_mark)[obj_page.page_rec_start:obj_page.page_rec_end]
print('数据清单标签...>>>',return_sets)
return return_sets总结上述功能实现,关键点是相关参数在前端和后端的传递,前端相关html代码的自动生成,尤其是下一次请求的请求参数的拼接形成。
四、查询功能实现,类似过滤功能。这里的过滤是按照AdminClass类中配置的list_search,进行查询,list_search可以配置多个字段,也就是在这多个字段中查询,只要包含相应数据,就要查询出来,相当于或关系查询。此时就需要使用Q查询。
前端查询标签的生成,与过滤标签做在一个form中:
def built_filter_tag(admin_class,filter_f,url_path,search_mark):
filter_tag = ""
if (admin_class.list_filter.__len__()+admin_class.list_search.__len__())>0:
filter_tag = filter_tag + ''''<form action="%s">
<div class="row" style="padding-left: 10px;">'''%(url_path)
if admin_class.list_filter.__len__()>0:
for filter_item in admin_class.list_filter:
filter_tag = filter_tag + '''
<div style="float:left;margin-left:20px;">
<span> %s</span>
%s
</div>''' %(filter_item,filter_tag_value(admin_class,filter_item,filter_f))
if admin_class.list_search.__len__()>0:
filter_tag = filter_tag + '</div><hr>' # 如果有查询,关闭上面的div,另起一个div,即另起一行
if search_mark.__len__()==0:
filter_tag = filter_tag + '''
<div class="row" style="padding-left: 10px;">
<div style="float:left;margin-left:20px;">
<span> 查询</span>
<input type="text" placeholder="输入查询值" name="search_mark" />
</div>'''
else:
filter_tag = filter_tag + '''
<div class="row" style="padding-left: 10px;">
<div style="float:left;margin-left:20px;">
<span> 查询</span>
<input type="text" name="search_mark" value="%s"/>
</div>'''%search_mark
filter_tag = filter_tag + '''<div class="col-sm">
<input type="submit" value="SUBMIT"/><input type="reset" value="RESET" />
</div>
</div>
</form>'''
print(filter_tag)
return filter_tag要注意的是对于分页时,要将查询输入的值带入其他页中。
后台查询数据时,要使用Q查询,因为是在几个字段中查找包含查询值的记录,所以是或关系,同时要与过滤条件与关系查询,即先过虑,在过滤的基础上在或查询。
@register.simple_tag
def get_query_sets_1(admin_class,obj_page,filter_f,order_mark,search_mark):
print('order_mark:',order_mark,'search_mark',search_mark)
if order_mark == '0':
if search_mark.__len__() == 0:
return_sets = admin_class.model.objects.filter(**filter_f)[obj_page.page_rec_start:obj_page.page_rec_end]
else:
q_and = Q()
q_or = Q()
q_or.connector = 'OR'
for column in admin_class.list_search:
q_or.children.append(("%s__contains" % column, search_mark))
q_and.connector = "AND"
# q_and.children.append(**filter_f)
# q_and.children.append(q_or)
return_sets = admin_class.model.objects.filter(**filter_f).filter(q_or)[obj_page.page_rec_start:obj_page.page_rec_end]
else:
if search_mark.__len__() == 0:
return_sets = admin_class.model.objects.filter(**filter_f).order_by(order_mark)[obj_page.page_rec_start:obj_page.page_rec_end]
else:
q_and = Q()
q_or = Q()
q_or.connector = 'OR'
for column in admin_class.list_search:
q_or.children.append(("%s__contains" % column, search_mark))
q_and.connector = "AND"
# q_and.children.append(**filter_f)
# q_and.children.append(q_or)
return_sets = admin_class.model.objects.filter(**filter_f).filter(q_or).order_by(order_mark)[obj_page.page_rec_start:obj_page.page_rec_end]
print('数据清单标签...>>>',return_sets)
return return_sets
# return admin_class.model.objects.values_list(*admin_class.list_display)
通过过滤、查询、排序、分页四项功能的实现,开发这类系统的关键点就是前后端参数的传递、数据的查询、前端将数据与相关标签的组装,形成最终的显示HTML代码,传递到前端显示。
最终的页面: