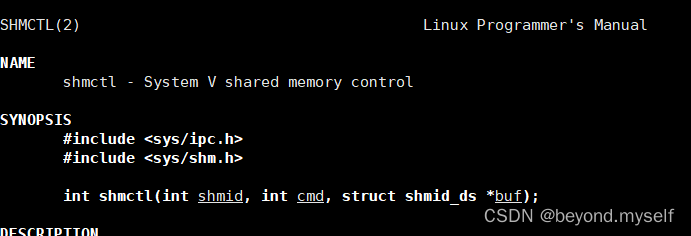
前言
本文是该专栏的第22篇,后面会持续分享python的干货知识,记得关注。
在信息爆炸的年代,爬虫对于在工作中进行信息的抽取,获取重要的数据源是一项非常不错的技能,可以说很久之前的爬虫几乎没什么难度,直到互联网的持续发展,陆陆续续出现了一大堆的反爬措施,给爬虫也间接的增加了一些难度,众多的反爬例子,小编这里就不举例说明了。
回到如今大数据爆炸的环境,面对反爬的难度增加,对于爬虫攻城狮来说,相应的也需要提高一些反爬技术。而本文要介绍的就是,如何解决图文验证码的登录情况。其实,面对图文验证码的问题,难度并不大,只需要精确的识别出图文信息即可。
废话不多说,跟着小编继续深入探讨。
正文
这里以古诗文网为例
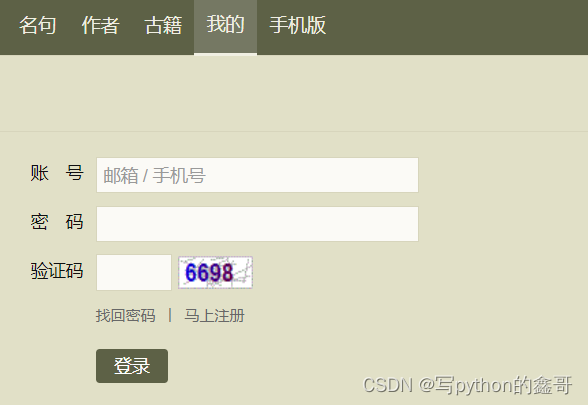
看到这种情况,相信很多同学也都清楚,第一时间需要将验证码的信息获取到才行。
整个的解决思路大致分3步
1.请求页面获取验证码的图片url将地址保存下来,或者是通过截图的形式将图片保存下来
2.将图片验证码的信息识别出来