文章目录
- 一、2D open-vocabulary object detection的发展和研究现状
- 二、基于大规模外部图像数据集
- 2.1 OVR-CNN:Open-Vocabulary Object Detection Using Captions,CVPR 2021
- 2.2 Open Vocabulary Object Detection with Pseudo Bounding-Box Labels,ECCV 2022
- 2.2.1 伪标签的生成
- 2.2.2 检测模型训练
- 2.3 Detic: Detecting Twenty-thousand Classes using Image-level Supervision,ECCV 2022
- 2.4 Grounded Language-Image Pre-training (CVPR 2022 oral)
- 三、总结
- 四、基于多模态大模型
- 4.1 ViLD:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation,ICLR 2022
- 4.2 RegionCLIP: Region-based Language-Image Pretraining,CVPR 2022
- 4.3 Aligning Bag of Regions for Open-Vocabulary Object Detection
- 4.4 CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching
一、2D open-vocabulary object detection的发展和研究现状
Open-Vocabulary Object Detection (OVD)可以翻译为**“面向开放词汇下的目标检测”,**该任务和 zero-shot object detection 非常类似,核心思想都是在可见类(base class)的数据上进行训练,然后完成对不可见类(unseen/ target)数据的识别和检测,除了核心思想类似外,很多论文其实对二者也没有进行很好的区分。
2D OVD 任务是由Shih-Fu Chang在CVPR2021上发表的论文 “Open-Vocabulary Object Detection Using Captions”(OVR-CNN)中提出,其出发点是制定一种更加通用的目标检测问题,目的是借助于大量的 image-caption 数据来覆盖更多的Object Concept,使得Object Detection不再受限于带标注数据的少数类别,从而实现更加泛化的Object Detection,识别出更多novel的物体类别。
随着OVR-CNN的提出,越来越多的OVD工作涌现出来。例如:ViLD、RegionCLIP、GLIP、VL-PLM、Detic、VL-Det等。本节将按照如下两个方面对上述文章进行整理和汇总。
二、基于大规模外部图像数据集
2.1 OVR-CNN:Open-Vocabulary Object Detection Using Captions,CVPR 2021
Open-Vocabulary Object Detection的初衷就是利用大规模的 image-caption 数据来改善对未知类的检测能力。基于此,OVR-CNN是该领域的第一篇工作。
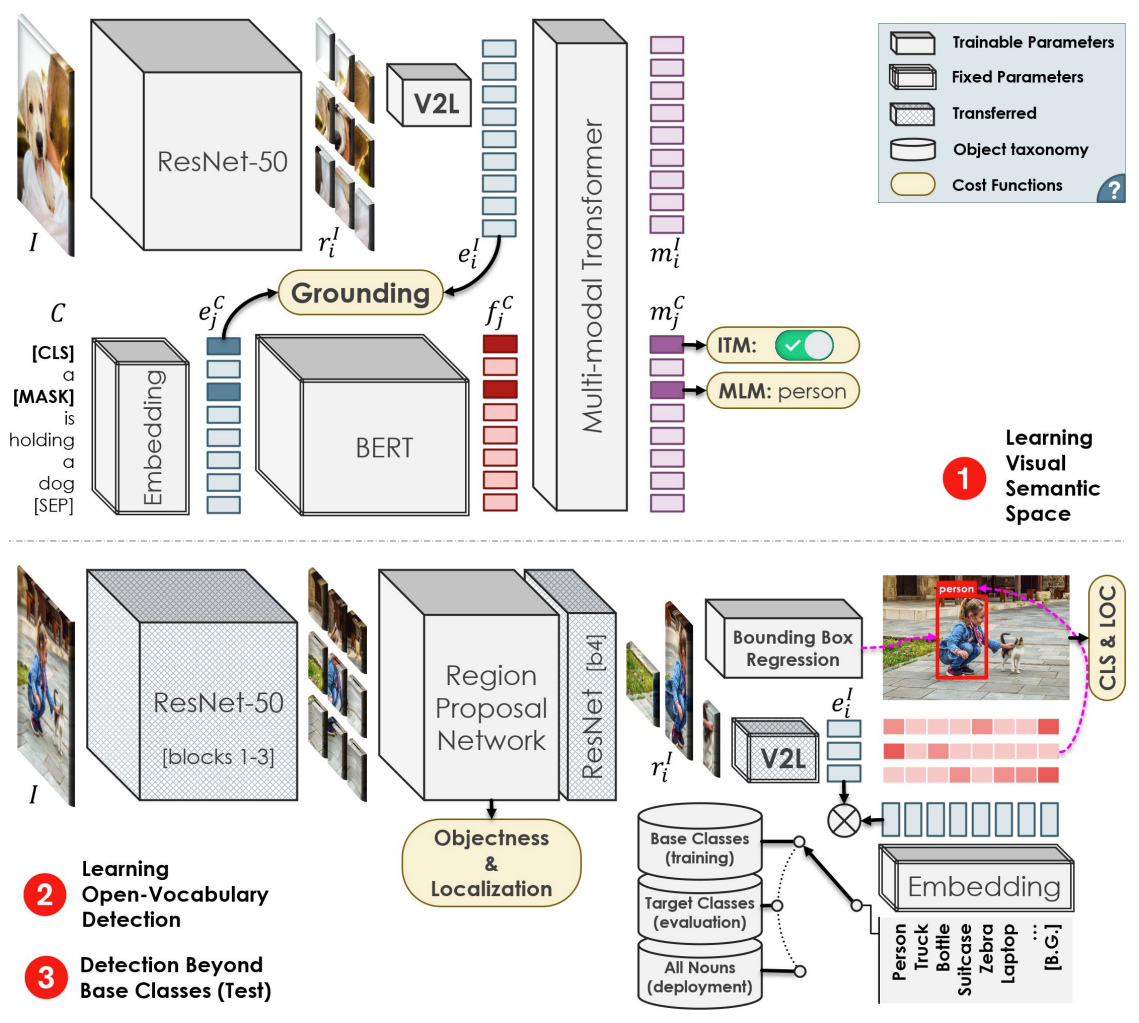
该工作的核心主要是利用image-caption数据来对视觉编码器进行pre-training。由于caption中存在着丰富的对于图像区域等细粒度特征的描述单词和短语,能够覆盖更多的物体类别,因此经过大规模image-caption的预训练,Vision encoder便能够学习到更加泛化的视觉-语义对应空间。因此训练好的vision encoder便可以用于替换faster-rcnn中encoder,提告检测模型的zero-shot检测能力。
展开讨论预训练流程,整体的预训练流程有些类似于PixelBert,可参考如下:
- 分别输入image和对应的caption,视觉编码器和文本编码器将分别提取特征。
- 在vision embedding和text embedding的基础上,利用V2L层对视觉embedding映射到文本embedding空间,构建grounding任务,计算对应图文对的grounding分数,然后利用对比学习拉近匹配对图文,推远非匹配对图文。这样利用word-region级别的grounding任务,实现丰富语义信息的学习。
- 后续利用Transformer模型进行多模态融合,同时构建下游MLM、ITM代理任务进行预训练。
一旦预训练结束后,trained vision encoder和trained V2L层,便可以替换至Faster RCNN框架中,通过在base数据集上进行finetune vision encoder,使其适配ROI区域特征,固定V2L层,保持其学习到的泛化的视觉-语义空间,即可进行target类别数据的检测。
总结来看,OVR-CNN通过在Image-Caption数据集上的预训练,学习到了丰富的文本词汇和图像区域表征,这样泛化的表征空间覆盖的物体类别,是远超过现阶段的带标注的目标检测数据集中物体的类别数。
2.2 Open Vocabulary Object Detection with Pseudo Bounding-Box Labels,ECCV 2022
该工作的动机和出发点是现阶段的OVD和zero-shot检测都是受限于base class数据,即使OVD引入了外部数据知识来进行泛化,但是还是无法摆脱base class数据有限的问题,从而无法泛化到非常不同的novel class数据。
因此,该工作提出:
- 能否通过自动生成的方式得到更多的物体bounding box标注,以此来scale现存的数据?
- 生成的未标注能否改善open-vocabulary object detection?
由此本工作可分为两部分来阐述:(1)伪标签的生成(2)检测模型的训练
2.2.1 伪标签的生成
该工作提出使用VLP模型来帮助生成伪标签。首先输入image-caption数据,利用VLP模型的双编码器对image和text进行编码,以此得到各自模态的feature embedding,然后利用cross-attention计算图像区域和文本单词之间的注意力权重,利用GradCAM对上述注意力权重进行可视化,得到感兴趣名词(racket)的Activation Map区域;同时利用RPN网络生成ROI区域,得到和Activation Map区域重叠程度最大的ROI,此ROI和感兴趣名词(racket)一起构成了伪标签区域。
2.2.2 检测模型训练
基于得到的伪标签数据,便可以训练open-vocabulary object detection模型了,OVD检测的过程和传统的目标检测相比,使用Text Embedding替换掉了之前的Classification Head。因此,图像数据根据伪标签获取ROI,经过编码器得到vision embedding,base class文本经过文本编码器得到text embedding,之后计算跨模态embedding的相似度,并根据伪标签计算交叉熵损失函数。
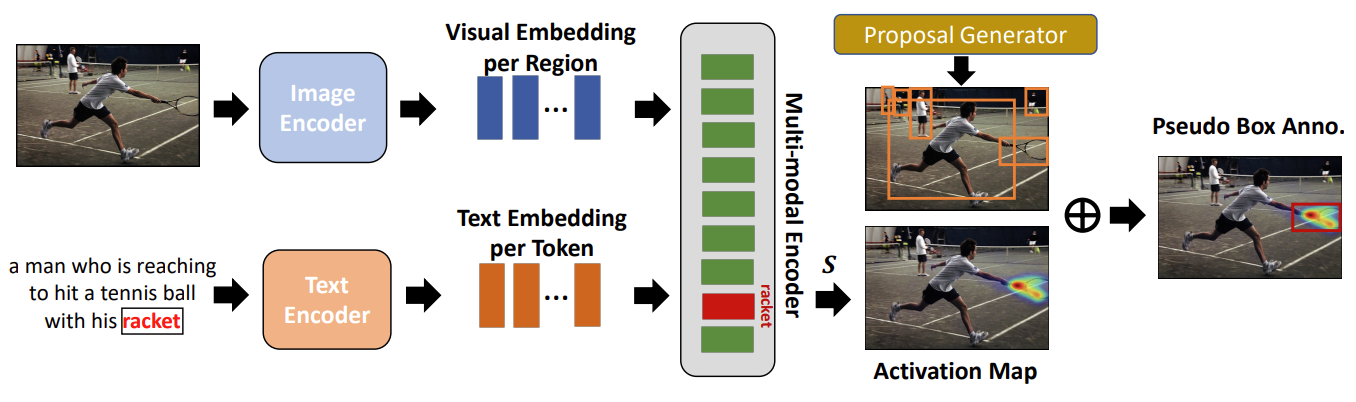
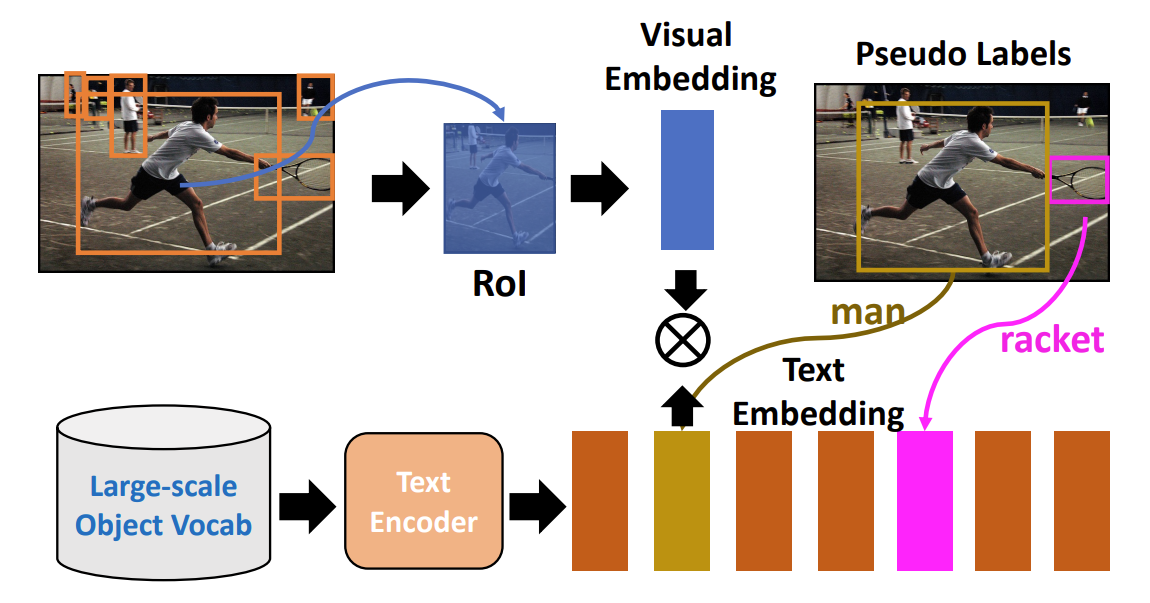
总结来看,这篇文章最主要的验证了利用VLP大模型生成的伪标签,即使带有噪声,但也是可以改善OVD任务的性能的。在后续的内容中,我们还会看到其他使用伪标签的工作。
2.3 Detic: Detecting Twenty-thousand Classes using Image-level Supervision,ECCV 2022
Detic与OVR-CNN和GradOVD相比,想法更加直接,做法更加粗暴。
实际上对比目标检测模型来说,真正限制其OVD能力的不是Regression Head,而是Classification Head。或者说OVD的最终目标是检测模型能够识别出更多novel的类别。基于此,Detic提出直接使用ImageNet21K的分类图像数据集和目标检测数据集一起,对检测模型进行联合训练。具体步骤如下:
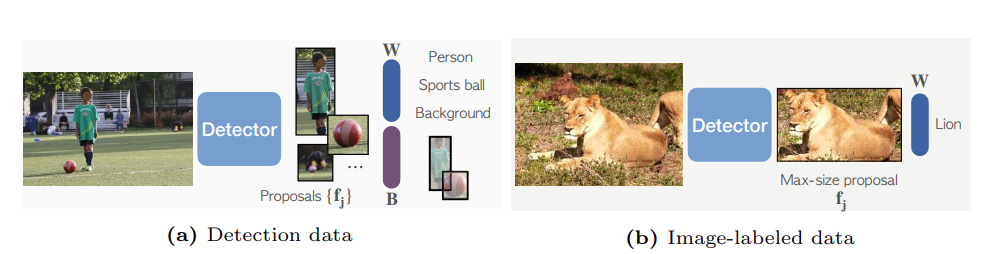
- minibatch中包含目标检测数据和ImageNet21K的分类图像数据;
- 如果是检测数据,则直接进行正常的两阶段目标检测流程,由RPN获取ROI,Reg Head回归bbox,Classification Head分类;
- 如果是ImageNet21K图像数据,则使用检测器检测Max-size的图像区域并截取,然后送入Classification Head进行分类;
- 通过共享Classification Head实现更多的ImageNet21K中的object concept知识的迁移。
2.4 Grounded Language-Image Pre-training (CVPR 2022 oral)
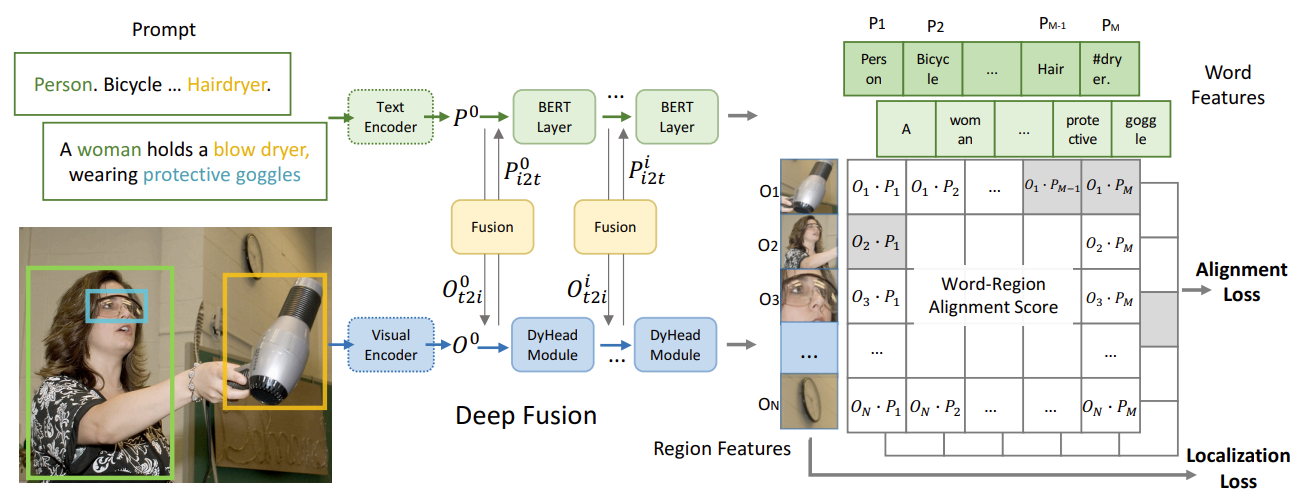
大名鼎鼎的GLIP,这篇工作不愧是Oral,立意和出发点很不一样,同时这篇工作的野心和目标也很宏大,他们不再局限于提高OVD的性能,而是将OVD和Visual Grounding进行了统一,完成了region-word级别的大规模预训练,实际上是相当于CLIP,只不过CLIP是在image-language 层面的。
如何统一object detection和Visual Grounding?
本文的观点是:object detection实际上是context-free的visual grounding任务,而visual grounding是contextualized的object detection任务。从这点出发,本文将检测任务转换为Visual grounding任务,然后采用统一的框架结构进行训练。这样做的好处是,统一的架构使得可以同时在Visual grounding数据集上进行训练,而不局限于检测数据集。要强调的是,Visual Grounding数据集包含了十分rich的视觉物体名词和概念,这可以极大的促进OVD和Zero-shot目标检测性能的提升,有趣的是,在论文中,作者也不断强调grounding数据的重要,称其为gold data。
具体的流程:
- 将检测转为visual grounding,输入检测图像,文本端为所有检测类别的逗号字符串连接。
- 将GLIP预训练在检测数据集和grounding数据集上,通过双编码器提取feature embedding,经过中间的Deep Fusion模块,直接进行类似于CLIP的cross-modal embedding alignment。
总体流程就是这么简单,但是GLIP是首个建立在groudning任务上,同时实现了细粒度跨模态对齐的工作,与CLIP一样,它同样具备着强大的zero-shot能力。在后文的讨论环节中,本文还会涉及到GLIP的拓展前景。
三、总结
利用大规模外部数据特别是caption数据来提升OVD的性能,也是OVD任务的初衷。不过无论是使用什么类型的外部数据,例如ImageNet、Image-caption、Grounding data,其本质目的都是希望挖掘更多的物体名词语义信息,使其不再受限于少量的base class数据。这才是OVD相较于Zero-shot更加成功、更加泛化的关键。
四、基于多模态大模型
除了将大规模外部数据引入之外,OVD的另外一个分支是引入多模态模型的预训练知识来改善性能。
4.1 ViLD:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation,ICLR 2022
引入多模态模型例如CLIP来促进OVD性能,ViLD应该是开山之作了。
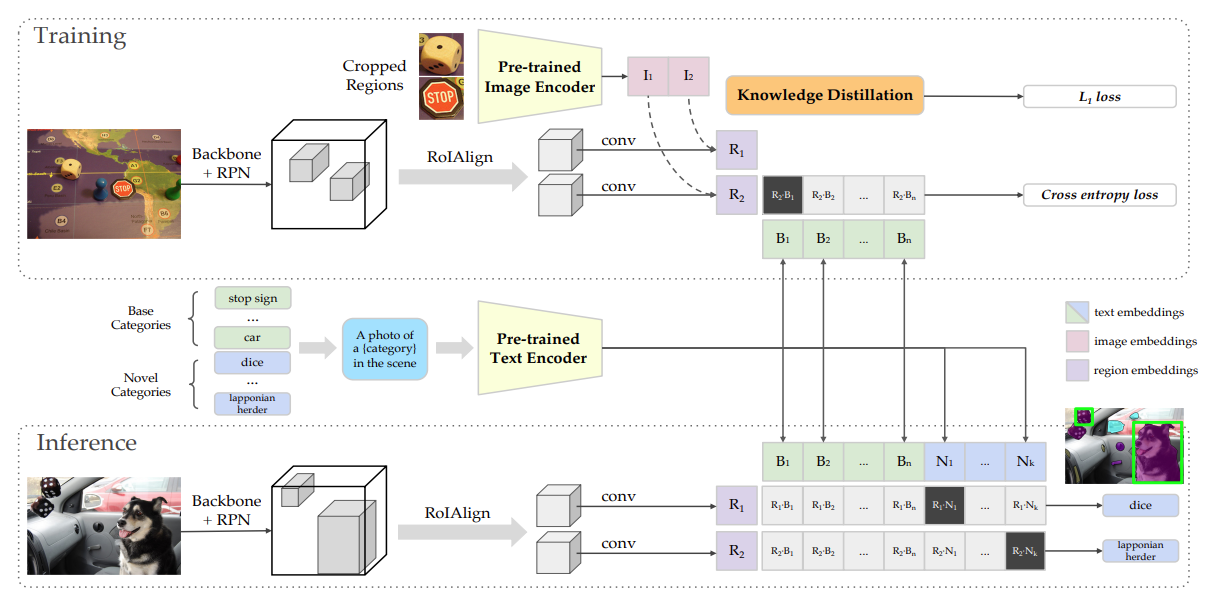
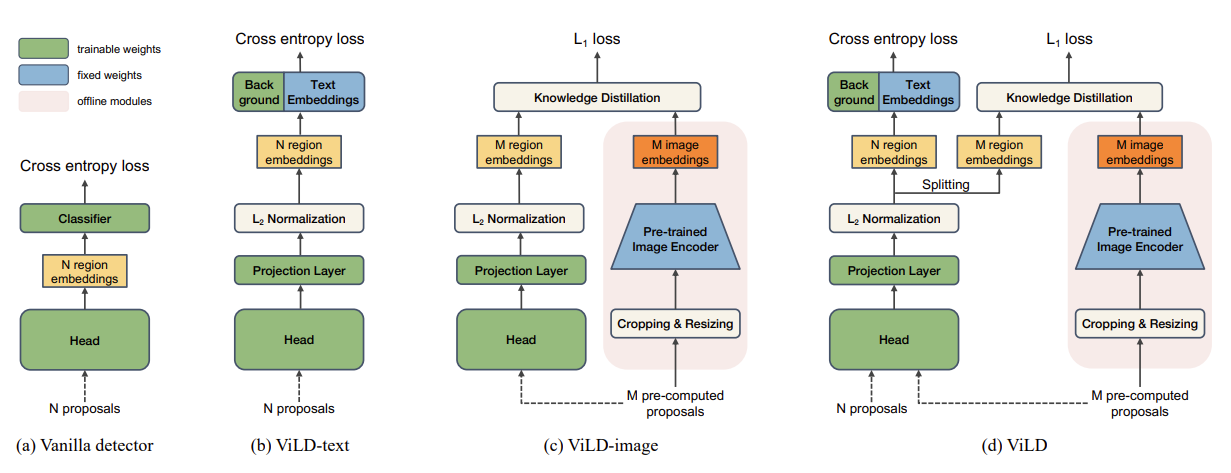
整体的流程如下:
- 输入base class的待检测图像,同时基于base class构建CLIP形式的text prompt输入至CLIP text encoder端得到Embedding,然后图像输入至Mask RCNN中得到ROI区域的图像特征,然后进行跨模态特征匹配。
- 输入base class的待检测图像,同时基于base class构建CLIP形式的text prompt输入至CLIP text encoder端得到Embedding,然后图像输入至Mask RCNN中得到ROI区域的图像特征,然后进行跨模态特征匹配。
- 推理的时候,利用CLIP文本编码器替换检测模型的分类头,进行分类。
总结来看,ViLD主要是依靠蒸馏学习将CLIP视觉端的能力迁移至检测模型中,再利用文本编码器完成和检测模型的识别工作。
4.2 RegionCLIP: Region-based Language-Image Pretraining,CVPR 2022
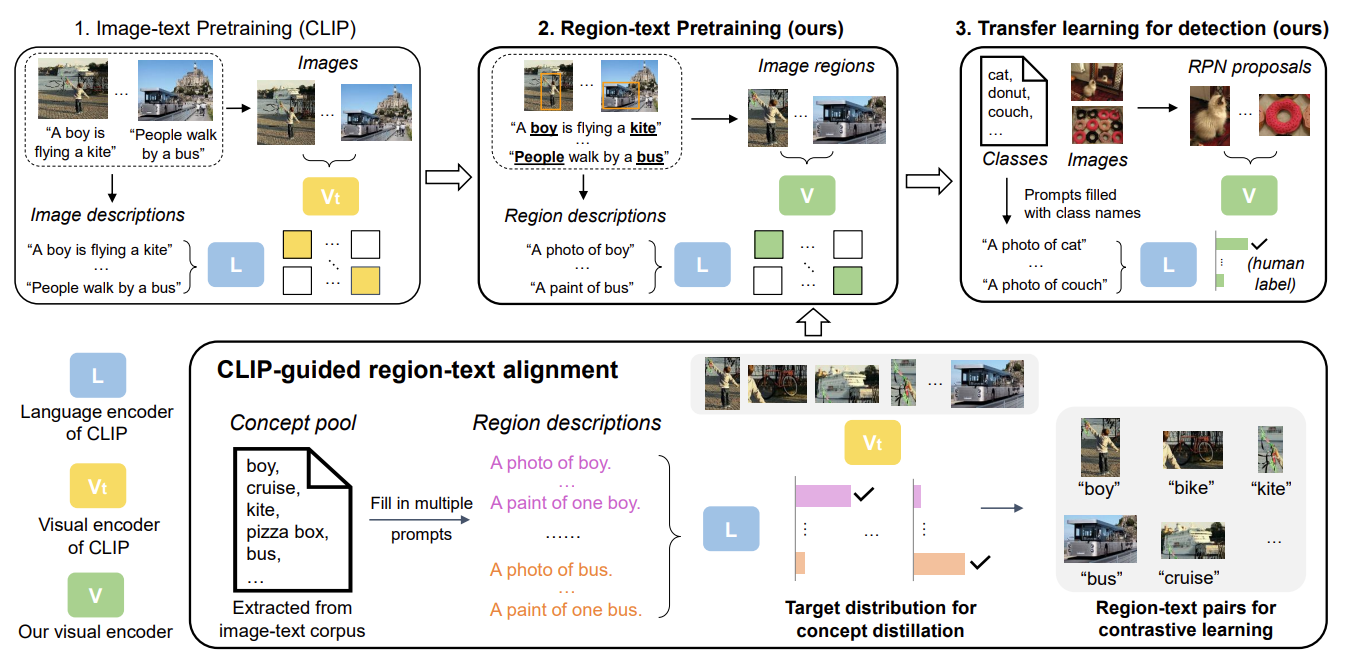
可以将RegionCLIP理解为CLIP在Region-word级别的拓展。
本文的出发点是观察到CLIP在Region区域上的识别很差,这是由于CLIP是在Image-Language level上进行的预训练导致的。因此,RegionCLIP从这一点出发,将CLIP在region图像和单词层面进行了预训练,提高了区域级别的检测能力。
主要流程如下:
- 首先利用文本数据,构建object名词语料库;
- 利用RPN网络提取图像上的object区域,输入至CLIP视觉编码器,同时输入语料库至CLIP文本编码器得到文本特征,然后做匹配对提取的图像区域进行伪标签标注;
- 在得到伪标签标注区域图像的基础上,构建视觉文本双编码器,在Region层面上进行CLIP式的预训练;
- 训练损失主要就是区域级别的对比损失+原始CLIP的对比损失+RegionCLIP-CLIP的视觉端蒸馏损失。
这篇文章提出的问题,也就是CLIP无法对区域级别的图像进行很好的识别,这一点其实在很多其他的文章中也有涉及,比如在ViLD中用RPN的分数来辅助CLIP在区域级别的预测。
总之,区域级别的CLIP也被拓展出来了。但是GLIP的性能更强,而且RegionCLIP和GLIP还是同一组的工作,就是pengchuan zhang,也是做了很多VLP工作。
4.3 Aligning Bag of Regions for Open-Vocabulary Object Detection
开放词汇目标检测旨在检测到模型训练中未标注的类别的物体,该任务的常见方法是对预训练过的视觉语言模型进行蒸馏,是检测器模型学到视觉语言模型的表征,从而可以识别训练中未标注的类别的物体。现有的方法主要是让检测器在单个区域上,学习视觉语言模型对单个物体概念的表征。然而在预训练中,视觉语言模型从图像文本对上学到的是对一组语义概念进行表征。
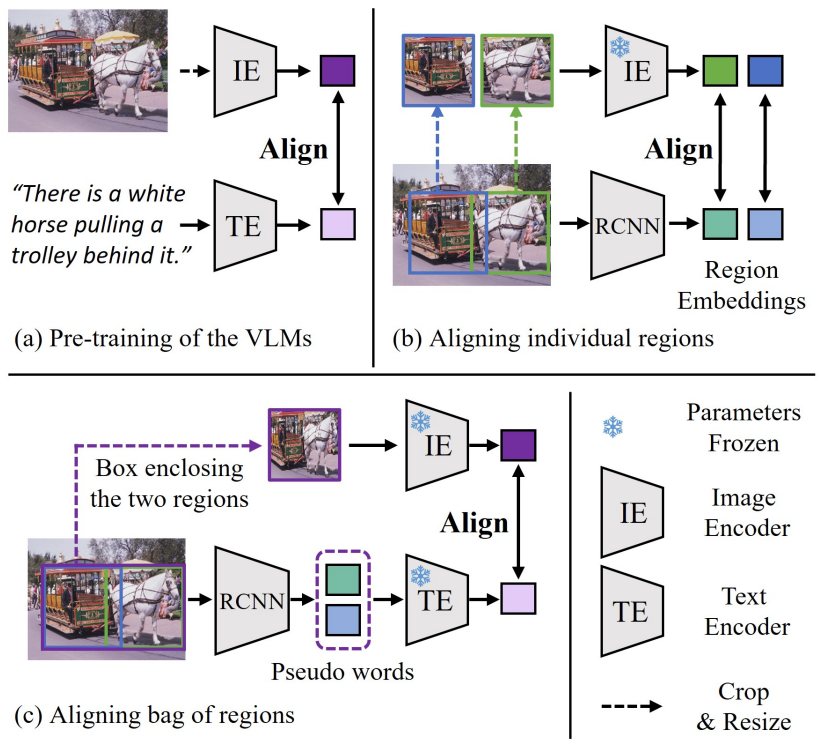
最新论文Aligning Bag of Regions for Open-Vocabulary Object Detection,介绍一种学习视觉语言模型表征的新思路,即在一组区域上进行蒸馏。为了充分利用视觉语言模型对一组语义概念的表征,论文提出在候选区域的邻域进行采样,得到有空间和语义相关性的区域组合(a bag of regions)。为了得到组合起来的区域的表征,论文将区域的表征对齐到词向量空间,将区域组合中的个体视为句子中的词,使得视觉语言模型中的文本编码器可以对一组区域进行表征。论文采用对比学习的方式,通过对齐文本编码器和图像编码器的表征,间接学习到区域表征。
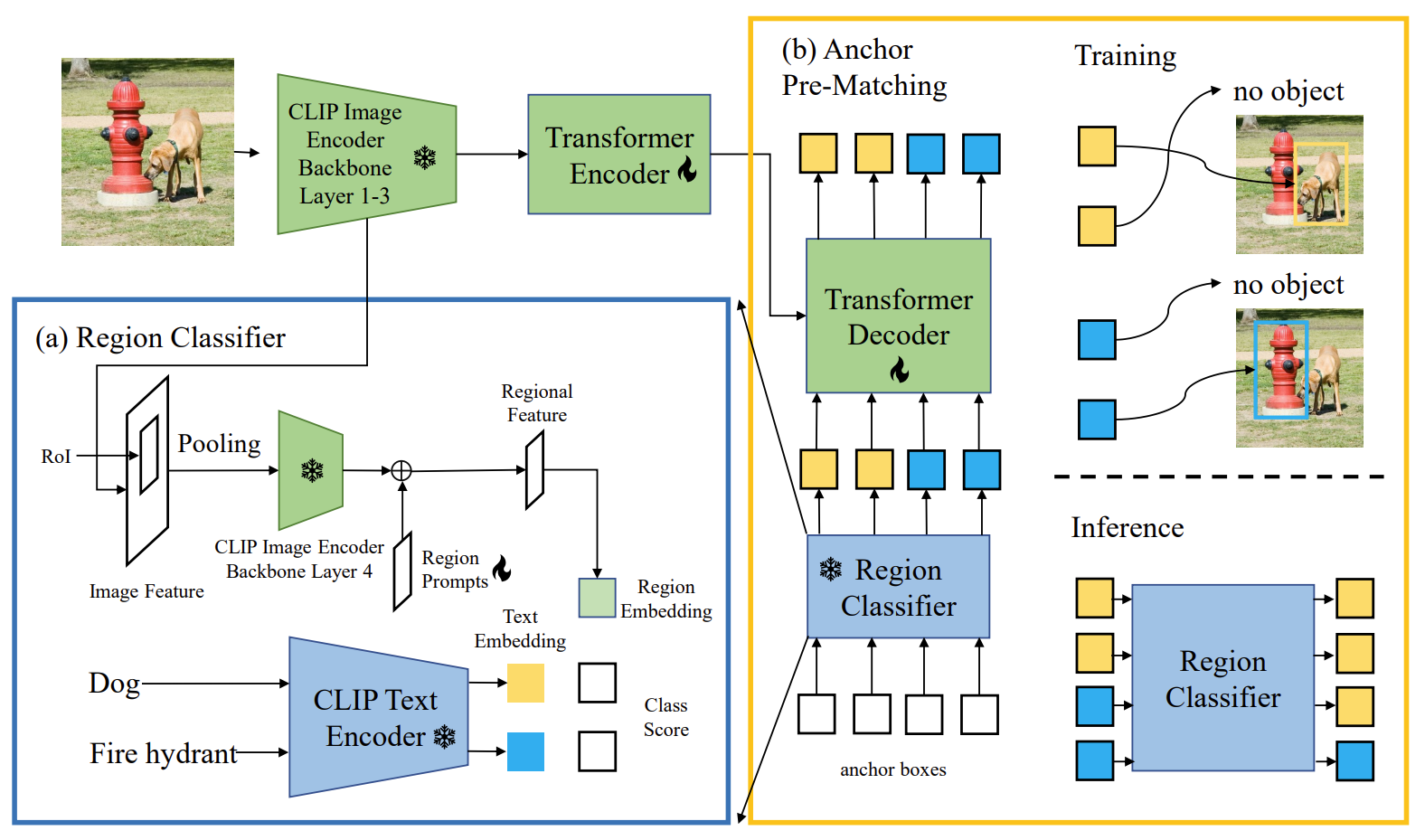
4.4 CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching
OVD是一种目标检测任务,旨在检测超出检测器训练基础类别的新类别的对象。最近的OVD方法依赖于大规模的视觉语言预训练模型,例如CLIP,用于识别新对象。
方法:为了克服将这些模型纳入检测器训练时遇到的两个核心障碍,作者提出了CORA,一种DETR风格的框架,通过区域提示和锚点预匹配来适应CLIP进行开放词汇检测。区域提示通过提示基于CLIP的区域分类器的区域特征来减轻整体到区域分布差异。锚点预匹配通过一种类别感知的匹配机制来帮助学习可推广的对象定位。
结果:作者在COCO OVD基准测试中评估了CORA,其中在新类别上实现了41.7 AP50,即使不使用额外的训练数据也比以前的SOTA高出2.4 AP50。当有额外的训练数据时,作者在基于真实标注的基础类别标注和由CORA计算的额外伪边界框标签上训练了CORA+。CORA+在COCO OVD基准测试中实现了43.1 AP50,在LVIS OVD基准测试中实现了28.1 box APr。