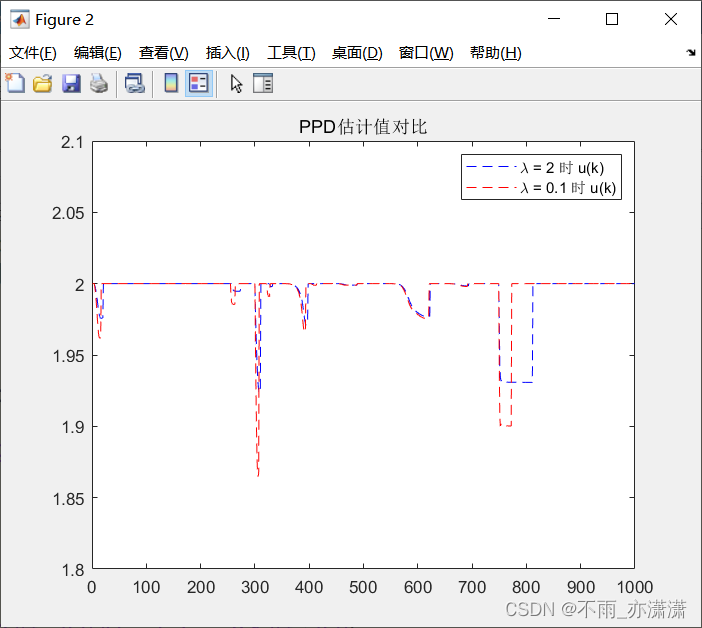
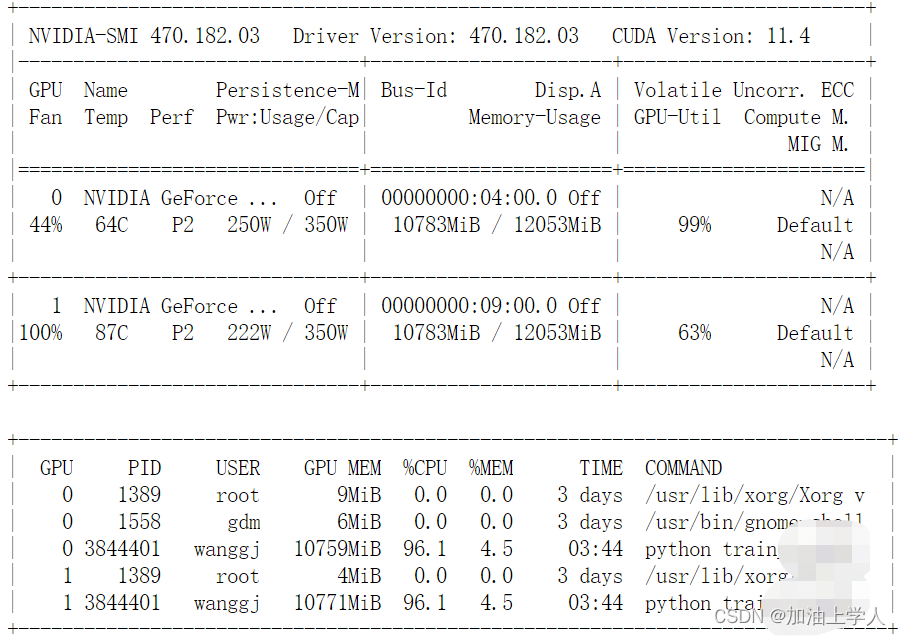
由于最近训练transformer,在单卡上显存不够,另外一块卡上也无法加载,故尝试使用双卡并行的策略。将基本的流程、遇见的难题汇总在这里。
分布策略解释
使用官方给出的tf.distribute.MirroredStrategy作为分布策略。这个策略通过如下的方式运行:
1)所有变量和模型计算图都会在副本之间复制。
2)输入都均匀分布在副本中。
3)每个副本在收到输入后计算输入的损失和梯度。
4)通过求和,每一个副本上的梯度都能同步。
5)同步后,每个副本上的复制的变量都可以同样更新。
正文
初始化分布策略
可以使用如下的命令,查看当前设备有几块GPU可以供使用。
strategy = tf.distribute.MirroredStrategy()
print(strategy.num_replicas_in_sync)
一、数据加载
使用分布式训练,会将总的batch分散到多块GPU上。我这里有两块GPU,使用的batch是32,那么在每个上面就是16。这里,在数据加载的时候就需要做处理,具体处理过程如下:
1)创建一个总的batchsize
GLOBAL_BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
2) 加载数据集
train_ds = DataLoader().make_batch(PARA['train_'], GLOBAL_BATCH_SIZE, PARA['max_len_sequence'])
valid_ds = DataLoader().make_batch(PARA['vaild_'], GLOBAL_BATCH_SIZE, PARA['max_len_sequence'])
test_ds = DataLoader().make_batch(PARA['testt_'], GLOBAL_BATCH_SIZE, PARA['max_len_sequence'])
3)对数据做分发
train_ds = strategy.experimental_distribute_dataset(train_ds)
valid_ds = strategy.experimental_distribute_dataset(valid_ds)
test_ds = strategy.experimental_distribute_dataset(test_ds)
经过上面这些操作,数据已经处理好了,接下来处理训练策略。
二、 定义损失函数
注:这里有几个地方需要特别注意,tf.losses/tf.keras.losses 中的损失函数通常会返回输入最后一个维度的平均值。损失类封装这些函数。在创建损失类的实例时传递 reduction=Reduction.NONE,表示“无额外缩减”。对于样本输入形状为 [batch, W, H, n_classes] 的类别损失,会缩减 n_classes 维度。对于类似 losses.mean_squared_error 或 losses.binary_crossentropy 的逐点损失,应包含一个虚拟轴,使 [batch, W, H, 1] 缩减为 [batch, W, H]。如果没有虚拟轴,则 [batch, W, H] 将被错误地缩减为 [batch, W]。
增加虚拟轴的方式也很简单,labels = labels[:, tf.newaxis]。如果没有这个,回归模型是跑不起来的!!!
1)使用 tf.distribute.Strategy 时应如何计算损失?
例如,假设有 2 个 GPU,批次大小为 64。一个批次的输入会分布在各个副本(2 个 GPU)上,每个副本获得一个大小为 32 的输入。
每个副本上的模型都会使用其各自的输入进行前向传递,并计算损失。现在,不将损失除以其相应输入中的样本数 (BATCH_SIZE_PER_REPLICA = 32),而应将损失除以 GLOBAL_BATCH_SIZE (64)。
之所以需要这样做,是因为在每个副本上计算完梯度后,会通过对梯度求和在副本之间同步梯度。
2)计算方法
如果使用自定义训练循环,则应将每个样本的损失相加,然后将总和除以 GLOBAL_BATCH_SIZE: scale_loss = tf.reduce_sum(loss) * (1. / GLOBAL_BATCH_SIZE),或者使用 tf.nn.compute_average_loss,它会将每个样本的损失、可选样本权重和 GLOBAL_BATCH_SIZE 作为参数,并返回经过缩放的损失。比较而言,选择tf.nn.compute_average_loss这个会好一些。
由于我这里使用的是 tf.keras.losses 类,则需要将损失归约显式指定为 NONE 或 SUM。与 tf.distribute.Strategy 一起使用时,不允许使用 AUTO 和 SUM_OVER_BATCH_SIZE。不允许使用 AUTO,因为用户应明确考虑他们想要的归约量,以确保在分布式情况下归约量正确。不允许使用 SUM_OVER_BATCH_SIZE,因为当前它只能按副本批次大小进行划分,而将按副本数量划分留给用户,这可能很容易遗漏。因此,您需要自己显式执行归约操作。
我做的是回归任务,具体的代码如下,可以看到,loss损失里面使用了reduction=tf.keras.losses.Reduction.NONE,返回损失值的时候使用了tf.nn.compute_average_loss。
GLOBAL_BATCH_SIZE = PARA['batch_size']*strategy.num_replicas_in_sync
with strategy.scope():
# Set reduction to `NONE` so you can do the reduction afterwards and divide by
# global batch size.
loss_object = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.NONE)
def compute_loss(labels, predictions):
# 这里有个坑,见最开始的注
# 使用Reduction.NONE之后,回归损失会减少一个维度,故要在后面添加一列
# https://tensorflow.google.cn/tutorials/distribute/custom_training?hl=zh-cn
labels = labels[:,tf.newaxis]
predictions = predictions[:, tf.newaxis]
per_example_loss = loss_object(labels, predictions)
return tf.nn.compute_average_loss(per_example_loss, global_batch_size=GLOBAL_BATCH_SIZE)
三、定义评价指标
评价指标根据自己的实际情况来,我这里使用了loss跟rmse
with strategy.scope():
test_loss = tf.keras.metrics.Mean(name='test_loss')
train_rmse = tf.keras.metrics.RootMeanSquaredError(name='train_rmse')
test_rmse = tf.keras.metrics.RootMeanSquaredError(name='test_rmse')
四、初始化模型
模型、优化器和checkpoint务必要放在strategy.scope
with strategy.scope():
model = Transformer(PARA['num_layers'], PARA['input_vocab_size'], PARA['target_vocab_size'],PARA['target_class'],PARA['max_len_sequence'],PARA['d_model'],PARA['num_heads'],PARA['dff'],rate=PARA['dropout_rate'])
# 加载优化器:
learning_rate = CustomizedSchedule(PARA['d_model'])
optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
# 记录模型
check = tf.train.Checkpoint(model=model, optimizer=optimizer)
check_manager = tf.train.CheckpointManager(check, PARA['model_save'], max_to_keep=5)
if check_manager.latest_checkpoint:
check.restore(check_manager.latest_checkpoint)
五、构建训练策略
1) 先构建并行的策略,再构建train_step
with strategy.scope():
# `run` replicates the provided computation and runs it
# with the distributed input.
@tf.function
def distributed_train_step(dataset_inputs):
per_replica_losses = strategy.run(train_step, args=(dataset_inputs,))
return strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses, axis=None)
@tf.function
def distributed_test_step(dataset_inputs):
return strategy.run(test_step, args=(dataset_inputs,))
2) 构建train_step
def train_step(inputs):
train_rmse.reset_states()
sequence, tm, label = inputs
with tf.GradientTape() as tape:
predictions = model(sequence, training=True)
loss = compute_loss(tm, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_rmse.update_state(tm, predictions)
return loss
def test_step(inputs):
sequence, tm, label = inputs
predictions = model(sequence, training=False)
t_loss = loss_object(tm, predictions)
test_loss.update_state(t_loss)
test_rmse.update_state(tm, predictions)
六、自定义训练过程
def fit(train_ds, valid_ds, test_ds):
steps = 0
start = time.time()
for epoch in range(PARA['EPOCH']):
# TRAIN LOOP
total_loss, num_batches, batch = 0.0, 0, 0
for (batch, x) in enumerate(train_ds):
# 这里返回每一个批次的损失值
per_loss= distributed_train_step(x)
total_loss += per_loss
steps += 1
# 这是自定义的记录函数,可以直接print当前值
save_smurry('train','-', epoch, batch, steps, [per_loss, train_rmse.result()])
if batch % (PARA['REPORT_STEP']*2) == 0 and batch:
# 每次处理完之后,需要对test_loss及test_rmse做重置
for (batch, x) in enumerate(valid_ds):
distributed_test_step(x)
# 这里需要得到的是在整个验证集上的结果
save_smurry('vaild','-', epoch, batch, steps, [test_loss.result(), test_rmse.result()])
test_loss.reset_states()
test_rmse.reset_states()
# 每50次做一次benchmark验证
if batch % (PARA['REPORT_STEP']*5) == 0 and batch:
for x in test_ds:
distributed_test_step(x)
save_smurry('test','-', epoch, batch, steps, [test_loss.result(), test_rmse.result()])
test_loss.reset_states()
test_rmse.reset_states()
time_used = 'Time take for 1 epoch:{} secs\n'.format(time.time()-start)
fout(time_used)
至此,分布程序构建完成。欢迎一起讨论