初识C++ 下篇
- 1.引用
- 1.1引用的概念
- 1.2引用的特点
- 1.3常引用
- 1.4引用使用的场景
- 1.5引用和指针的区别
- 2.指针空值 --- nullptr
- 3.内联函数
- 3.1 内联函数的概念
- 3.2内联函数的使用场景
- 3.3内联函数的特性
1.引用
1.1引用的概念
相信大家小时候, 肯定有小名、绰号、亲朋好友的昵称… …
这些称呼,在一定程度上就是你自己本人。
假如,你的小名叫做二蛋, 别人喊二蛋的时候, 你就会不由自主地回头去确定是否是在喊你…
想想这些, 儿时的回忆就渐渐涌上心头, 时而捧腹大笑, 时而陷入沉思。
把情绪收回来, 让我们一起来了解这个带着回忆(亲切)色彩的 “引用” 。
引用不是新定义一个变量, 而是给已存在变量取了一个别名。在语法逻辑上, 编译器不会为引用变量开辟内存空间, 它和它引用的变量共用同一块空间(你的别名在一定程度上, 代替了你本人, 并不会平白无故地多出一个人来)。
让我们通过下面的代码来深刻地理解一下:
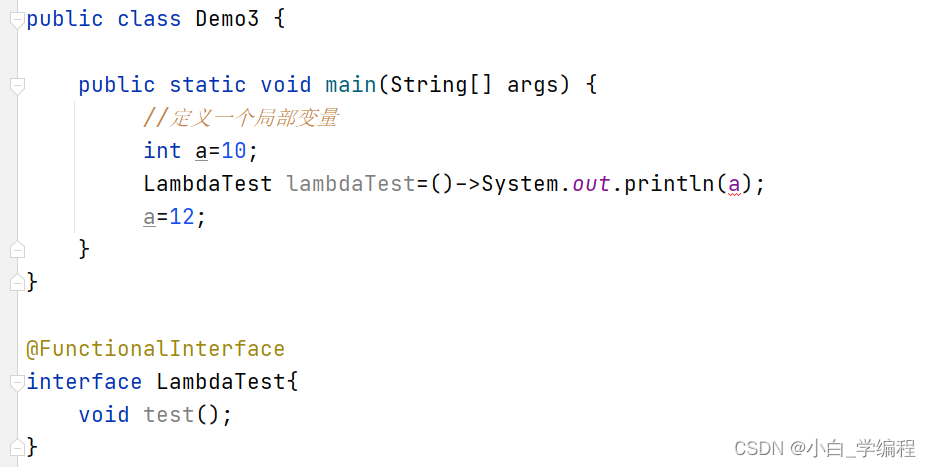
int main()
{
int a = 10;
int& b = a;
cout << a << endl; // 10
cout << b << endl; // 10
b += 10;
cout << a << endl; // 20
cout << b << endl; // 20
return 0;
}
总结:
- 引用的基本构成: (实体)类型 + & + 引用变量名(别名)= 引用实体(原本的自己)
- 引用类型 必须和 引用实体 是一样的类型
1.2引用的特点
- 引用在定义时必须初始化(要确定是谁的别名)
- 一个变量可以有多个引用(一个人可以有多个别名)
- 引用一旦引用一个实体, 就不能在引用其他的实体(一个别名只属于你自己)
在这里插入代码片int main()
{
int tem = 10;
// int& a; // 报错, 引用定义时没有初始化
int& a = tem;
int& b = tem;
int& c = b; // 引用的引用/ 别名的别名 也是你啊
cout << a << endl; // 10
cout << b << endl; // 10
cout << c << endl; // 10
printf("%p\n", &a); // 0000008EAE3DFBF4
printf("%p\n", &b); // 0000008EAE3DFBF4
printf("%p\n", &c); // 0000008EAE3DFBF4
return 0;
}
1.3常引用
首先, 先表明本人的一个观点: 感觉这个常引用就很鸡肋, 食之无味,弃之可惜。原本人家就不能改变, 还给人家去一个别名,多此一步。 也有可能是我的能力太差了, 还没领会到常引用的妙用。
常引用的概念; 顾名思义, 就是给不能改变的量起个别名
看下面的代码, 来验证各位的猜想:
int main()
{
const int a = 10;
int& b = a; // error C2440: “初始化”: 无法从“const int”转换为“int &”
const int& b = a;
cout << b << endl;
b += 10; // error C3892: “b”: 不能给常量赋值
}
喏, 常引用就是这么简单, 没啥说的啦, 进入下一部分吧😁😁
1.4引用使用的场景
- 做参数
这肯定要跟普通的参数有所区别才能体现引用的强大啊!
一般, 引用做输出型参数(就是跟传了指针一样, 出了函数, 参数的值发生了变化)
- 通过Swap函数来加深你的理解:
void Swap(int& a, int& b)
{
int tem = a;
a = b;
b = tem;
}
int main()
{
int a = 5, b = 10;
cout << a << " " << endl; // 5 10
Swap(a, b);
cout << a << " " << endl; // 10 5
return 0;
}
肯定有些老铁会问: 老陈,这跟用指针没啥两样呗, 直接用指针不就行了??
这个问题问的好啊!! 下一部分,你就会知道why !! 不要走开哦, 下一节更精彩!😁😁
-
做返回值
首先, 先让我们来看一下两个函数:
int Add1() { static int tem = 4; return tem; } int main() { int ret = Add(); cout << ret << endl; } int& Add2() { static int tem = 4; return tem; } int main() { int ret = Add2(); cout << ret << endl; }
- 老铁们, 可以猜一下这俩个Add函数的返回值是一样的吗?? 这俩个函数有什么不同?? 我为啥要写这两个函数??
提示一个点, 后面要讲述的是有关 函数栈帧 的知识, 不知道的赶快去百度, 或者可以去看看我的博客.
先给一个结论: 其实这两个函数的本质是一样的, 但是在细节方面是有一点区别的:
- 先分析一下Add1, 函数里面的变量是一个用 static 修饰的静态常量, 函数调用结束, 函数栈帧被销毁, 注意这里销毁的是栈空间里面的东西(比如, 局部变量), 而静态常量是建立在常量区的, 并不会被销毁.在这个过程, 同样不会被销毁的还有 全局变量, 动态申请的空间(在堆区上). 而在普通的C语言函数中(就是不带有引用& ), 一般返回函数值的时候, 会创建临时变量来存储函数返回的值, 再将临时变量赋值给外面的变量.
这时候, 有些老铁又要疑问了: 静态常量不是在常量区的嘛, 生命周期是整个工程, 直接变过去就行了, 为啥还要创建临时变量, 这多浪费空间和时间啊!!!
原因: 注意看函数返回类型, 这里的 Add1 的返回类型是 int. 在C 语言中中, 是否要生成临时拷贝要看函数返回类型:
如果函数返回类型是 void, 就不用创建临时拷贝, 直接返回(建立在函数栈帧没有被销毁的前提)
如果函数返回类型不是 void, 那么就"傻瓜式"的创建临时拷贝(不管你是不是全局变量, 还是static修饰的静态常量)
- 再来分析一下Add2, 前面的分析跟Add1函数一样. 返回值不一样, Add2函数返回的是 tem 的引用, 它就不会生成临时拷贝, 就直接返回 tem 自己即可(因为引用也是自己啊).

- 由上面的例子不难看出, 引用作为函数的返回值的好处:节省拷贝, 提升效率(对象是大对象/ 深拷贝对象 时, 效果更显著)~~
看到这里, 有些老铁就会说: 以后所有的函数返回值都用引用返回多简单!!
老陈嘿嘿一笑, 你就知道答案了😁😁
- 重点(现讲理论知识, 后面会实践):
返回局部变量的引用是十分危险的, 其危险来自于两个方面:
- 函数出栈, 栈帧有么有被清理
- 栈是否会被覆盖掉
还是通过上面的例子, 来让我们深化对引用做返回值的理解:
int& Add3(int x)
{
int a = x;
a++;
return a;
}
int main()
{
int ret = Add3(5); // 6
cout << ret << endl;
rand(); // 作用:覆盖掉
cout << ret << endl; // 随机值
return 0;
}
我们使用的编译器是Vs2013, 根据上图结果可知: Vs2013在函数调用结束后没有清理掉这块栈帧, 我们只好让这块栈帧覆盖掉来验证我们的结论.
如图所示:当我们返回局部变量的引用是十分危险的, 且不方便调试(因为我们一般会直接跳过这个问题).
-
关于引用作为返回值的总结:
- 任何场景都可以用作(输出型)参数~~
- 用作函数返回值的时候要注意: 出了函数作用域, 对象不在了, 就不能引用返回; 如果对象还在, 就可以引用返回~~
-
补充一下:
-
引用作为函数返回值是有两个方面的功能/ 权限 : 读取 和 修改(简称"读写")
-
权限可以缩小或平移, 但是不能放大
-
生成的临时变量是具有常性的, 即如果是用引用返回值会造成权限的平移, 如果是用引用来接收函数返回值 会造成权限的缩小; 即这两种方式都是合乎要求的.

-
如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回, 如果已经还给系统了,则必须使用传值返回
-
空间被回收后, 是指这块栈空间暂时不能被使用, 但是这块空间还存在(所以存在被覆盖的可能). 比如: 你去酒店开房间, 等你归还房间时, 这个房间你就暂时不能用了, 但是这个房间还存在
-
1.5引用和指针的区别
在语法逻辑上, 引用是一个别名, 没有独立空间, 和引用实体共用一块空间
在底层实现上, 引用其实是有空间的, 引用是按照指针方式来实现的
指针和引用的不同点:
- 引用概念上定义一个变量的别名, 指针存储一个变量地址
- 引用在定义时必须初始化, 而指针没有要求
- 一个引用只能有一个引用实体, 而指针可以指向任何一个同类型的实体
- 有多级指针, 但是没有多级引用
- 没有NULL引用, 但是有NULL指针
- 引用 + 1是引用实体 + 1, 而指针 + 1 是指针向后移动一个类型的大小
- 访问实体方式不同: 引用是编译器自己处理, 而指针需要显示解引用
- sizeof含义不同: 引用的结果是引用实体类型的大小, 而指针的结果是地址空间所占字节数(32位平台下始终是32字节)
- 引用比指针使用起来更安全(指的是内存泄漏类型的问题)
2.指针空值 — nullptr
有不少老铁(包括我)看到这里, 有点懵圈. 不是已经有NULL了吗, 为啥还要有nullptr的存在啊??
在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现不可预料的 错误,比如未初始化的指针。如果一个指针没有合法的指向,我们基本都是按照如下方式对其进行初始化:
void test()
{
int* ptr1 = NULL;
int* ptr2 = 0;
//...
}
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何种定义,在 使用空值的指针时,都不可避免的会遇到一些麻烦,比如:
void f(int)
{
cout<<"f(int)"<<endl;
}
void f(int*)
{
cout<<"f(int*)"<<endl;
}
int main()
{
f(0); // f(int)
f(NULL); // f(int)
f((int*)NULL); // f(int*)
return 0;
}
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下 将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0
- 注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr
3.内联函数
3.1 内联函数的概念
调用函数是有栈帧消耗的(最主要的消耗)
如果我们多次(特指很多次)调用函数, 那么消耗的栈帧将会是巨大的
那我们改如何解决这种消耗?? 有些老铁说: 如果我们调用函数不是通过建立栈帧, 而是直接把这个函数展开简单啊!! 突然, 眼前一亮, 这, 符合这所有特性的, 不就是宏函数嘛
首先, 先复习一下宏函数:
-
宏是一种替换
-
宏的优势是: 不需要建立栈帧, 提高了调用效率
-
宏的缺点是: 复杂, 容易出错(尤其是跟函数形式弄混), 可读性差, 不能进行调试
-
这时, 有些老铁就会说: 要是能够解决宏函数的这些缺点就完美了!!
我们的祖师爷也感觉这个宏函数有点鸡肋, 就决定把它升级一下
内联函数就应运而生.(当然, 宏函数还是存在的. 我们语言的改版都是兼顾下面版本的)
内联函数的关键字是 inline, 编译时C++会在调用内联函数的地方展开, 以提升函数的运行效率.
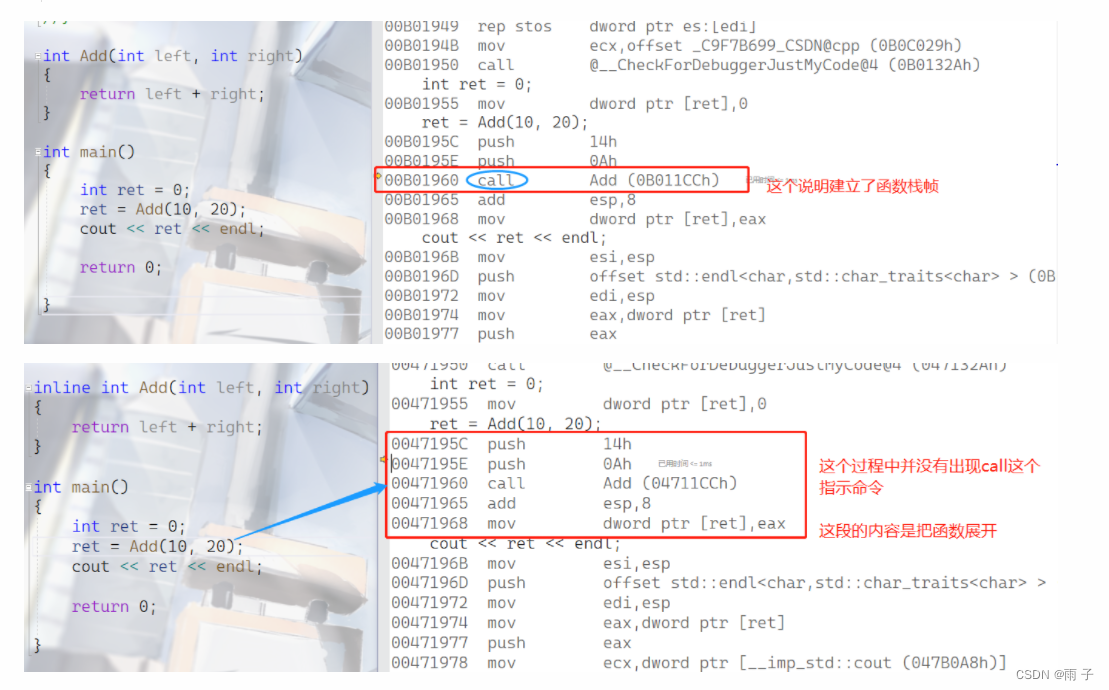
要注意的是:
- 默认的debug版本下, 函数不会展开, 需要自己对编译器进行设置(因为默认debug模式下, 编译器不会对代码进行优化)
- release模式下, 已经对代码进行了优化, 可以清楚地看到内联函数将函数展开了
3.2内联函数的使用场景
有人看到这里就兴奋了, 就说: 那我们以后都用内联函数!!! 这个多方便啊~
提醒大家一下: 万事, 有其利, 必有其弊.
试想一下: 如果一个函数很长, 且我们使用了内联函数, 那么会有什么结果??
答案就是: 会导致代码膨胀, 最后生成的可执行文件会变得很大!
这时候我们就要思考内联函数的应用场景 和 不能应用场景.
- 建议使用的场景: 函数内容短小且使用频率高
- 不能使用的场景:
- 函数内容过长
- 递归函数
- 默认的debug模式下
其实, inline(内联函数)对编译器来说仅仅只是一个建议, 最终的决定权掌握在编译器自己手中🤦♂️🤦♂️
3.3内联函数的特性

最后, 来两个问题巩固一下内联函数:
- 宏的优缺点?
优点:
- 提高代码的运行效率, 提高程序的性能
- 增强代码的复用性
缺点:
- 不方便调试(因为编译阶段,进行了替换)
- 没有类型安全的检查
- 代码可读性差, 可维护性差, 容易误用(函数)
- C++有哪些技术可以替代宏?
- 短小函数定义内联函数
- 常量定义 换用 const enum