MongoDB的语法平时接触的不错,更多的是使用关系型数据库。最近遇到一个问题,在MongoDB中,需要找出三个字段重复的数据,有点类似于SQL数据中的三个字段组成的唯一键。并且需要将重复的数据保留一条,其余删除。但是在MongoDB中却不知道如何实现。经过查询相关资料,终于在最后实现了。相关代码记录如下:
版本
- MongoDB 3.4.17
查询重复数据
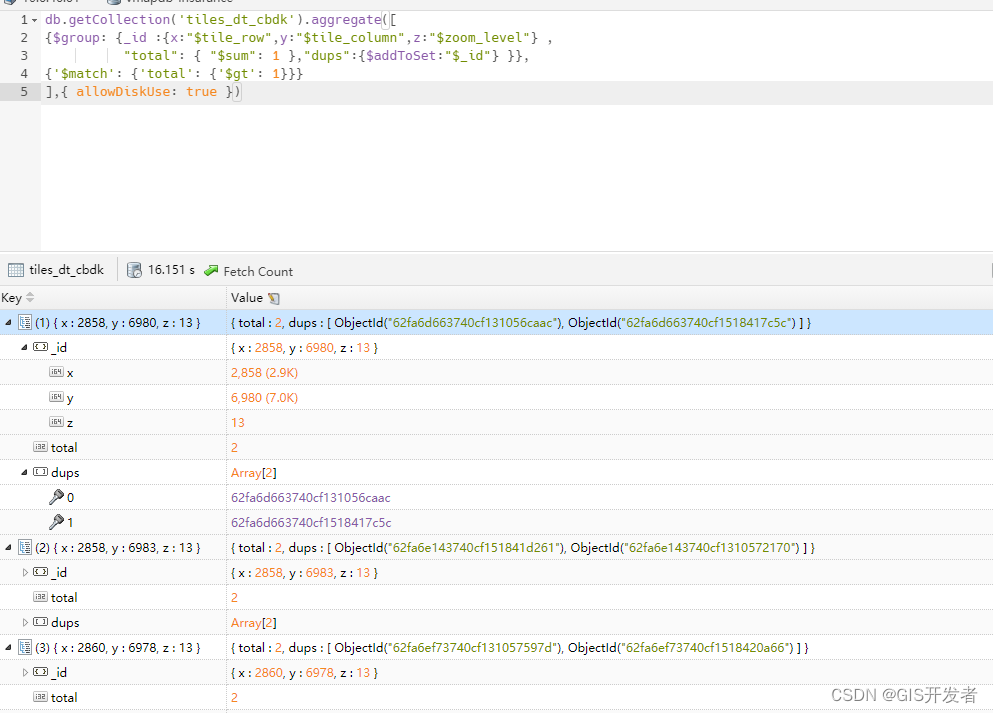
db.getCollection('test_collection').aggregate([
{$group: {_id :{x:"$tile_row",y:"$tile_column",z:"$zoom_level"} ,
"total": { "$sum": 1 },"dups":{$addToSet:"$_id"} }},
{'$match': {'total': {'$gt': 1}}}
],{ allowDiskUse: true })
tile_row、tile_column、zoom_level是需要判重的三个字段名。allowDiskUse指示符,表示在聚合任何阶段是否因内存超出限制而将数据写入临时文件。数据量过大时,需要增加这个配置项。
运行结果如下图所示:
删除重复数据
db.getCollection('test_collection').aggregate([
{$group: {_id :{x:"$tile_row",y:"$tile_column",z:"$zoom_level"} ,
"total": { "$sum": 1 },"dups":{$addToSet:"$_id"} }},
{'$match': {'total': {'$gt': 1}}}
],{ allowDiskUse: true }).forEach(function(doc){
doc.dups.pop();
db.test_collection.deleteMany({"_id":{$in:doc.dups}});
});
注意
- 根据uid分组并统计数量, g r o u p 只会返回参与分组的字段,使用 group只会返回参与分组的字段,使用 group只会返回参与分组的字段,使用addToSet在返回结果数组中增加_id字段_
- 使用$match匹配数量大于1的数据
- doc.dups.pop();表示从数组最后一个值开始删除;作用是弹出数组的最后一个_id,根据数组中剩余的_id删除所有重复的数据
- 使用forEach循环根据关键字重复的行来删除数据
- a d d T o S e t 操作符只有在字段不存在于数组中时才会向数组中添加一个字段。如果字段已经存在于数组中, addToSet 操作符只有在字段不存在于数组中时才会向数组中添加一个字段。如果字段已经存在于数组中, addToSet操作符只有在字段不存在于数组中时才会向数组中添加一个字段。如果字段已经存在于数组中,addToSet返回,不会修改数组。
- 注意:forEach和$addToSet的驼峰写法不能全部写成小写,因为mongodb严格区分大小写