MIT6.S081操作系统实验2021——lab1
参考文章
sleep
要求为xv6实现UNIX 程序sleep;其应该暂停用户指定的ticks number。tick是 xv6 内核定义的时间概念,即计时器芯片的两次中断之间的时间(两次时钟中断之间的时间)。您的解决方案应该在文件user/sleep.c中。
- 如果用户忘记传递参数,sleep 应该打印一条错误消息。
- 确保main调用exit()以退出程序。
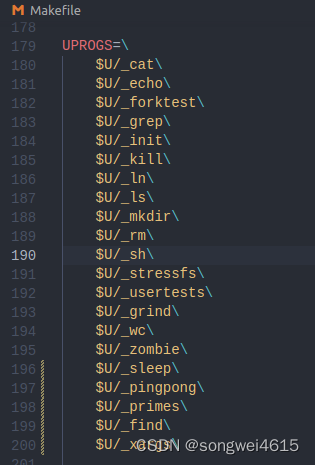
- 在 Makefile 中将你的sleep程序添加到UPROGS;完成后,make qemu将编译您的程序,您将能够从 xv6 shell 运行它。
Run the program from the xv6 shell:
$ make qemu
...
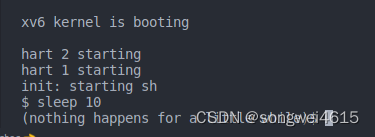
init: starting sh
$ sleep 10
(nothing happens for a little while)
$
提示
- 查看 user/ 中的一些其他程序( 例如user/echo.c、user/grep.c和user/rm.c),了解如何获取传递给程序的命令行参数。(argc是包括程序名本身的参数个数,argv是包括程序名本身在内的所有参数的字符串指针数组)
- 命令行参数作为字符串传递;您可以使用atoi将其转换为int(请参阅 user/ulib.c)。
- 使用系统调用sleep。
思路
实现首先检查参数个数,然后把参数中给出的ticks number转变为int,之后使用sleep系统调用,输出提示信息即可。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int argc,char *argv[])
{
if(argc == 1)
{
printf("sleep need one argument\n");
exit(1);
}
uint ticks = atoi(argv[1]);
sleep(ticks);
printf("(nothing happens for a little while)");
exit(0);
}

pingpong
要求编写一个程序,使用 UNIX 系统调用通过一对管道在两个进程之间“pingpong”一个字节,一个管道用于每个方向。父进程应该向子进程发送一个字节;子进程应该打印“: received ping”,其中 是它的进程 ID,将管道上的字节写入父进程,然后退出;父进程应该从子进程那里读取字节,打印“: received pong”,然后退出。您的解决方案应该在文件user/pingpong.c中。
Run the program from the xv6 shell and it should produce the following output:
$ make qemu
...
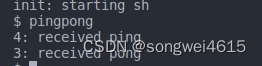
init: starting sh
$ pingpong
4: received ping
3: received pong
$
提示
- 使用pipe创建管道。
- 使用fork创建一个子进程。
- 使用read从管道读取,并使用write写入管道。
- 使用getpid查找调用进程的进程 ID。
- 将程序添加到Makefile 中的UPROGS。
- xv6 上的用户程序有一组有限的库函数可供他们使用。您可以在 user/user.h中看到声明;定义(系统调用除外)位于user/ulib.c user/printf.c和user/umalloc.c中。
思路
- 父进程关闭管道1读端,向写端写入ping,关闭管道1写端。关闭管道2写端,从管道2读端读出pong,关闭管道2读端。使用wait让子进程先打印ping,然后打印pong.
- 子进程关闭管道1写端,从管道1读端读出ping,关闭管道1读端。关闭管道2读端,向写端写入pong,关闭管道2写端,然后打印ping。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#define READ 0
#define WRITE 1
int main(int argc, char *argv[])
{
if(argc != 1) printf("dont input arguments\n");
int pipeParToChr[2];
int pipeChrToPar[2];
char buf[8];
pipe(pipeParToChr);
pipe(pipeChrToPar);
int pid = fork();
if( pid == 0 ) // 子进程
{
close(pipeParToChr[WRITE]);
read(pipeParToChr[READ] , buf , sizeof(buf));
close(pipeParToChr[READ]);
close(pipeChrToPar[READ]);
write(pipeChrToPar[WRITE],"pong\n",5);
close(pipeChrToPar[WRITE]);
printf("%d: received %s",getpid(),buf);
exit(0);
}else // 父进程
{
close(pipeParToChr[READ]);
write(pipeParToChr[WRITE] , "ping\n" , 5);
close(pipeParToChr[WRITE]);
close(pipeChrToPar[WRITE]);
read(pipeChrToPar[READ],buf,sizeof(buf));
close(pipeChrToPar[READ]);
wait((int*)0);
printf("%d: received %s",getpid(),buf);
exit(0);
}
}

primes
要求
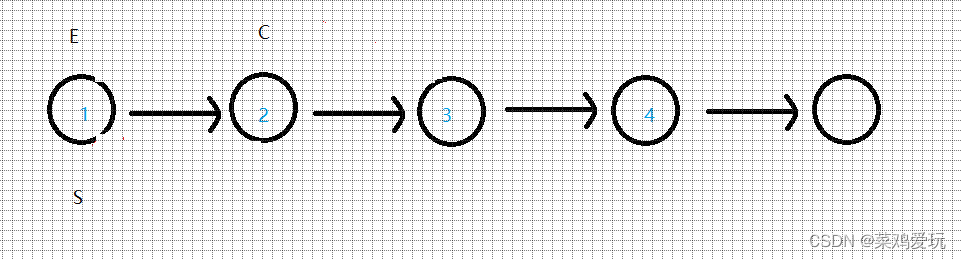
使用管道编写一个并发版本的初筛。这个想法归功于 Unix 管道的发明者 Doug McIlroy。本页中间的图片和周围的文字说明了如何做到这一点。您的解决方案应该在文件user/primes.c 中。您的目标是使用pipe和fork来设置管道。第一个过程将数字 2 到 35 输入管道。对于每个素数,您将安排创建一个进程,该进程通过管道从其左邻居读取并通过另一管道向其右邻居写入。由于 xv6 的文件描述符和进程数量有限,第一个进程可以在 35 处停止。
Your solution is correct if it implements a pipe-based sieve and produces the following output:
$ make qemu
...
init: starting sh
$ primes
prime 2
prime 3
prime 5
prime 7
prime 11
prime 13
prime 17
prime 19
prime 23
prime 29
prime 31
$
提示
- 尽早关闭进程不需要的文件描述符,否则你的程序将在第一个进程达到 35 之前耗尽 xv6 的资源。
- 一旦第一个进程达到 35,它应该等到整个程序终止,包括所有子孙进程。因此,主进程(产生2~35数字的进程)应该只在所有输出都被打印出来,并且在所有其他子孙进程都退出之后才退出。
- 提示:当管道的写端关闭时,读取该管道的read()立即返回零。
- 将 32 位(4 字节)的int直接写入管道是最简单的,而不是使用格式化的 ASCII I/O。
- 您应该仅在需要时在管道流水线中创建进程。
- 将程序添加到Makefile 中的UPROGS。
实现
并发的素数筛模型:根据该图,我们可以看出需要一个主进程将2~35的int数据输入到第一个子进程。而从子进程的视角看,所有子进程的任务都是从父进程那里读取数据。将读到的第一个数据print出来,并以此为基,将所有读到的不是它的倍数的数据传递给自己的子进程。此外,流水线停止的条件是一个子进程从父进程那里读不到数据,说明所有数据已经筛选完毕。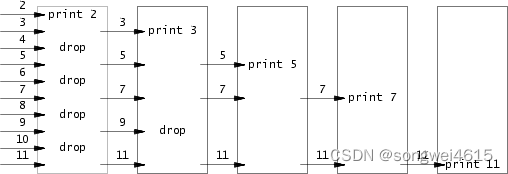
思路
- 父进程输出一个数组和数组的个数
- 子进程接收数组,接收数组的第一个为最小素数,为基数。输出
- 之后数据分别判断是否为基数的整数倍,如果是抛弃,不是则给下一级子进程
- 最后实现递归,当输入数组的元素个数为1时,输出,结束进程
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#define READ 0
#define WRITE 1
void function(int num[] , int size)
{
int pipe1[2];
pipe(pipe1);
int pid = fork();
if(pid > 0)
{
close(pipe1[READ]);
for(int i=0; i<size; i++)
{
write(pipe1[WRITE],&num[i],sizeof(num[i]));
}
close(pipe1[WRITE]);
wait((int*)0);
}else
{
close(pipe1[WRITE]);
int numchr[34] , indnx = 0;
int tmp , min;
while(read(pipe1[READ] ,&tmp,sizeof(tmp) ))
{
if(indnx == 0)
{
min = tmp;
printf("prime %d\n", min);
indnx++;
}
if(tmp%min != 0)
{
numchr[indnx-1] = tmp;
indnx++;
}
}
close(pipe1[READ]);
function(numchr,indnx-1);
exit(0);
}
}
int main(int argc, char *argv[])
{
int num[34];
int indnx = 0;
for(int i = 2; i <= 35 ;i++)
{
num[indnx] = i;
indnx++;
}
function(num,34);
exit(0);
}
find
要求编写一个简单版本的 UNIX 查找程序:查找目录树中具有特定名称的所有文件。您的解决方案应该在文件user/find.c中。
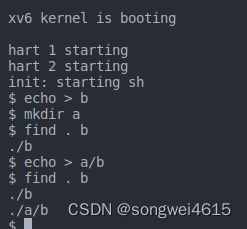
Your solution is correct if produces the following output (when the file system contains the files b and a/b):
$ make qemu
...
init: starting sh
$ echo > b
$ mkdir a
$ echo > a/b
$ find . b
./b
./a/b
$
即find的功能是在argv[1]所给目录和它的所有子目录(不包括.和…)中查找名为argv[2]的文件。
提示
- 查看 user/ls.c 以了解如何读取操纵目录。
- 使用递归允许 find 进入到子目录。
- 不要递归到 . 和 …
- 对文件系统的更改在 qemu 运行中持续存在;运行干净的文件系统make clean,然后make qemu.
- 用 strcmp()比较字符串。
- 将程序添加到Makefile 中的UPROGS。
为了支持递归,我们需要实现一个在给定目录中查找给定文件的find()函数:
void find(char *path,char *name);
提示告诉我们研究ls.c来了解对目录和文件的读取,其中主要是函数void ls(char *path):
首先以读的方式打开path这个file(unix中一切皆file,包括普通文件、目录、设备),返回一个fd.接着使用fstat()把这个file的一些文件系统相关的信息填充进st结构体中。
对于要实现的函数void find(char *path,char *name),path必为目录,则直接仿照ls中case T_DIR的情况处理就行。和ls不同的是,我们不需要输出所有文件的所有信息,即在stat(buf, &st)之后,我们不需要printf出文件的信息,而是进行筛选,当这个file类型是文件并且名字与要找的name相同,则输出buf中存储的相对路径即可。如果这个file类型是目录并且不是.和…,就进入此目录递归查找。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
void find(char *path , char *target)
{
char buf[512], *p;
int fd;
struct dirent de;
struct stat st;
if((fd = open(path, 0)) < 0){
fprintf(2, "find: cannot open %s\n", path);
return;
}
if(fstat(fd, &st) < 0){
fprintf(2, "find: cannot stat %s\n", path);
close(fd);
return;
}
switch(st.type)
{
case T_FILE:
if(strcmp( path + strlen(path) - strlen(target) , target ) ==0)
{
printf("%s\n", path);
}
break;
case T_DIR:
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){
printf("find: path too long\n");
break;
}
strcpy(buf, path);
p = buf+strlen(buf);
*p++ = '/';
while(read(fd, &de, sizeof(de)) == sizeof(de))
{
if(de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
if(stat(buf, &st) < 0)
{
printf("find: cannot stat %s\n", buf);
continue;
}
if(strcmp(".", de.name) != 0 && strcmp("..", de.name) != 0)
{
find(buf, target);
}
}
break;
}
close(fd);
}
int main(int argc, char *argv[])
{
if(argc != 3)
{
printf("input arguments : find <path> <file name>\n");
exit(1);
}
find(argv[1], argv[2]);
exit(0);
}

xargs
要求编写一个简单版本的 UNIX xargs 程序:从标准输入读取行。为每一行将该行作为参数提供给命令,并运行命令。您的解决方案应该在文件user/xargs.c中。
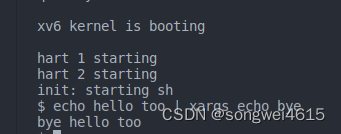
以下示例说明了 xargs 的行为:
$ echo hello too | xargs echo bye
bye hello too
$
注意这里的命令是“echo bye”,附加参数是“hello too”,使得命令“echo bye hello too”输出“bye hello too”。
提示
- 使用fork和exec对每一行输入调用命令。在父进程中使用wait等待子进程完成命令。
- 要读取单行输入,请一次读取一个字符,直到出现换行符 (‘\n’)。
- kernel/param.h 声明了 MAXARG,如果您需要声明 argv 数组,这可能很有用。
- 将程序添加到Makefile 中的UPROGS。
实现
- 我们已经知道,shell中可以使用管道 | 将’|‘之前的命令的标准输出作为之后的命令的标准输入。而xargs的作用是将’| xargs’之前的命令的标准输出作为之后的命令的附加的命令行参数。标准输入和命令行参数,有很大的不同。
- 以$ echo hello too | xargs echo bye为例,其argc为3。即实际的命令行参数从xargs开始算起。
- 程序的功能应是维护一个新的new_argv数组,先从argv[1]开始把本来的参数复制到new_argv中,然后从stdin(文件描述符0)读取字节,每读取到’\0’就把这个新参数添加到new_argv末尾,读取到’\n’就fork出一个子进程以new_argv为基础使用exec来执行命令。然后从本来的参数末尾重新开始添加参数。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/param.h"
int main(int argc, char *argv[])
{
char *new_argv[MAXARG];
int cur_argv = 1;
for( cur_argv = 1 ;cur_argv <= argc - 1 ; cur_argv++)
{
new_argv[cur_argv - 1] = argv[cur_argv];
}
char ch;
char buf[128];
char *cur_buf = buf;
new_argv[cur_argv-1] = buf;
while(read(0,&ch,sizeof(char)))
{
if( ch == ' ')
{
*cur_buf = '\0';
cur_buf++;
new_argv[cur_argv ] = cur_buf;
cur_argv++;
}else if( ch == '\n' )
{
*cur_buf = '\0';
new_argv[cur_argv] = 0;
int pid = fork();
if( pid == 0)
{
exec(new_argv[0] , new_argv);
exit(0);
}else
{
wait((int*)0);
cur_buf = buf;
cur_argv = argc;
}
}else
{
*cur_buf = ch;
cur_buf++;
}
}
exit(0);
}

makefile