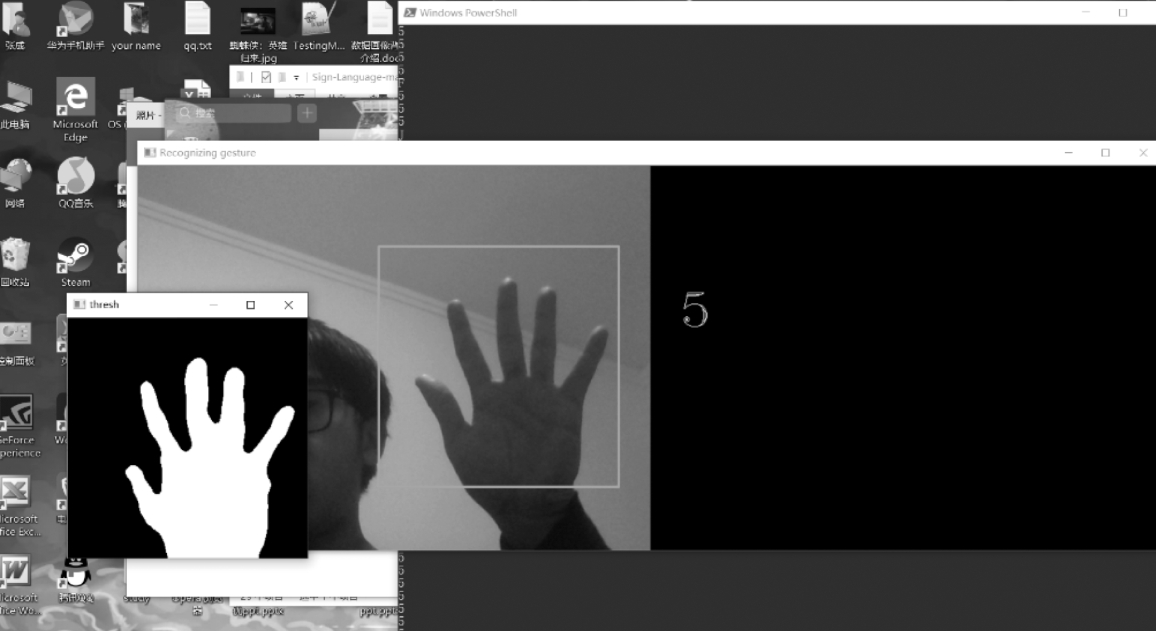
0x00 背景
前不久,Meta前脚发布完开源大语言模型LLaMA,
随后就被网友“泄漏”,直接放了一个磁力链接下载链接。
然而那些手头没有顶级显卡的朋友们,就只能看看而已了
但是 Georgi Gerganov 开源了一个项目llama.cpp
ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++ (github.com)
次项目的牛逼之处就是没有GPU也能跑LLaMA模型
大大降低的使用成本,本文就是时间如何在我的 mac m1 pro 上面跑起来这个模型
llama.cpp:提供了一种模型量化和在本地CPU上部署方式
文本介绍了如何使用llama.cpp工具将深度学习模型进行量化并在本地CPU上部署的详细步骤。
以下是具体步骤的解释:
ç
0x01 Step1 环境准备
- 高版本python 3.10
pip install protobuf==3.20.0
pip install transformers 最新版
pip installsentencepiece (0.1.97测试通过)
pip install peft (0.2.0测试通过)
pip install git+https://github.com/huggingface/transformers
pip install sentencepiece
pip install peft
-
确保机器有足够的内存加载完整模型 ,7B模型需要13-15G
-
下载原版LLaMA模型的权重和tokenizer.model文件
下载参考这个[PR]https://github.com/facebookresearch/llama/pull/73/files
压缩包内文件目录如下(LLaMA-7B为例):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
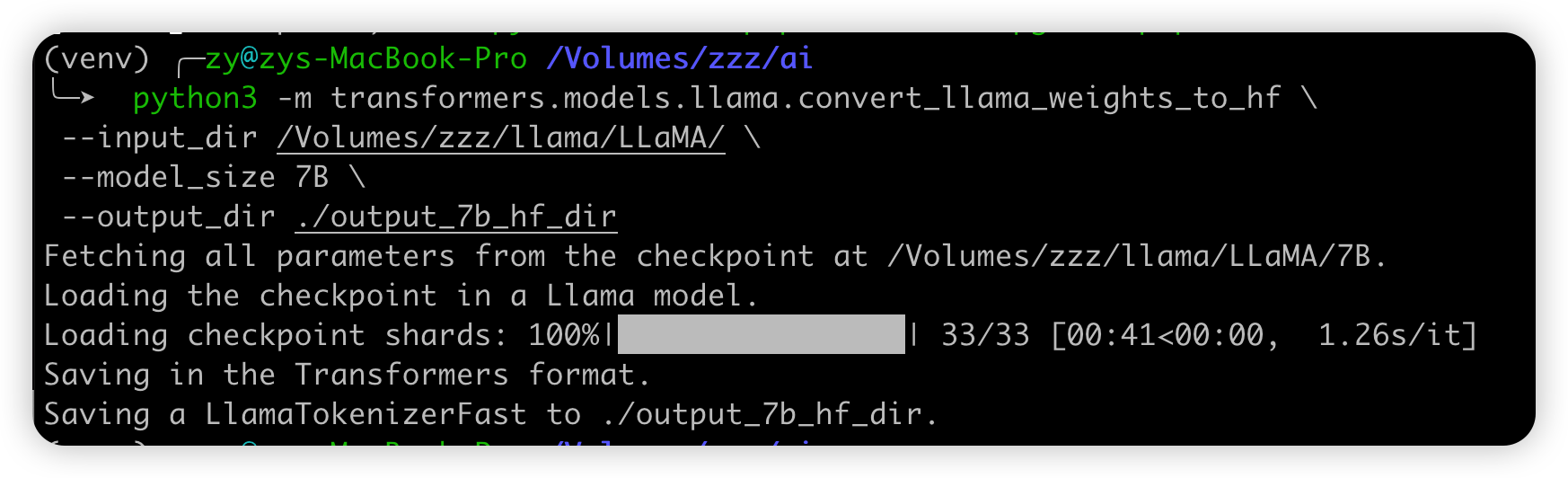
Step 2: 将原版LLaMA模型转换为HF格式
请使用transformers提供的脚本convert_llama_weights_to_hf.py
将原版LLaMA模型转换为HuggingFace格式。
将原版LLaMA的tokenizer.model放在--input_dir指定的目录,其余文件放在${input_dir}/${model_size}下。 执行以下命令后,--output_dir中将存放转换好的HF版权重。
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir path_to_original_llama_root_dir \
--model_size 7B \
--output_dir path_to_original_llama_hf_dir
Step 2: 合并LoRA权重,生成全量模型权重
使用ymcui/Chinese-LLaMA-Alpaca at v2.0 (github.com)里面的scripts/merge_llama_with_chinese_lora.py脚本
对原版LLaMA模型(HF格式)扩充中文词表,并与LoRA权重进行合并,生成全量模型权重consolidated.*.pth(建议检查生成模型的SHA256值)和配置文件params.json。请执行以下命令:
此处可有两种选择:
- 输出PyTorch版本权重(
.pth文件),使用merge_llama_with_chinese_lora.py脚本- 使用llama.cpp工具进行量化和部署
- 输出HuggingFace版本权重(
.bin文件),使用merge_llama_with_chinese_lora_to_hf.py脚本(感谢@sgsdxzy 提供)- 使用Transformers进行推理
- 使用text-generation-webui搭建界面
以上两个脚本所需参数一致,仅输出文件格式不同。下面以生成PyTorch版本权重为例,介绍相应的参数设置。
python scripts/merge_llama_with_chinese_lora.py \
--base_model path_to_original_llama_hf_dir \
--lora_model path_to_chinese_llama_or_alpaca_lora \
--output_dir path_to_output_dir
参数说明:

我这里直接使用了Model Hub上的模型,因为很小就直接下载了使用,懒惰下载到本地
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录(Step 1生成)--lora_model:这就是你要合并的 LoRA模型 所在目录,也可使用Model Hub上的模型名:ziqingyang/chinese-alpaca-lora-7b或ziqingyang/chinese-llama-lora-7b--output_dir:指定保存全量模型权重的目录,默认为./- (可选)
--offload_dir:对于低内存用户需要指定一个offload缓存路径
Step 3: llama.cpp 本地快速部署
大模型在自己的电脑上进行本地部署(CPU推理)
下载llama.cpp工具https://github.com/ggerganov/llama.cpp
推荐使用MacOS和Linux系统,Windows好像有bug
运行前请确保:
- 模型量化过程需要将未量化模型全部载入内存,请确保有足够可用内存(7B版本需要13G以上)
- 加载使用Q4量化后的模型时(例如7B版本),确保本机可用内存大于4-6G(受上下文长度影响)
- 系统应有
make(MacOS/Linux自带)或cmake(Windows需自行安装)编译工具 - 推荐使用Python 3.9或3.10编译运行llama.cpp工具(因为
sentencepiece还不支持3.11)
1. 下载和编译llama.cpp
运行以下命令对llama.cpp项目进行编译,生成./main和./quantize二进制文件。
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make
2.生成量化版本模型
把合并模型(选择生成.pth格式模型)中最后一步生成的tokenizer.model文件放入xx-models目录下,模型文件consolidated.*.pth和配置文件params.json放入xx-models/7B目录下。
请注意LLaMA和Alpaca的tokenizer.model不可混用
目录结构类似:
- 7B/
- consolidated.00.pth
- params.json
- tokenizer.model
将上述.pth模型权重转换为ggml的FP16格式,生成文件路径为xx-models/7B/ggml-model-f16.bin。
python3 ./llama.cpp/convert-pth-to-ggml.py ./xx_model/7B/ 1

进一步对FP16模型进行Q4量化,生成量化模型文件路径为zh-models/7B/ggml-model-q4_0.bin。
./quantize ./xx-models/7B/ggml-model-f16.bin ./xx-models/7B/ggml-model-q4_0.bin 2

3.加载并启动模型
运行./main二进制文件,-m命令指定Q4量化模型(也可加载ggml-FP16的模型)。以下是解码参数示例:
./main -m xx-models/7B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3
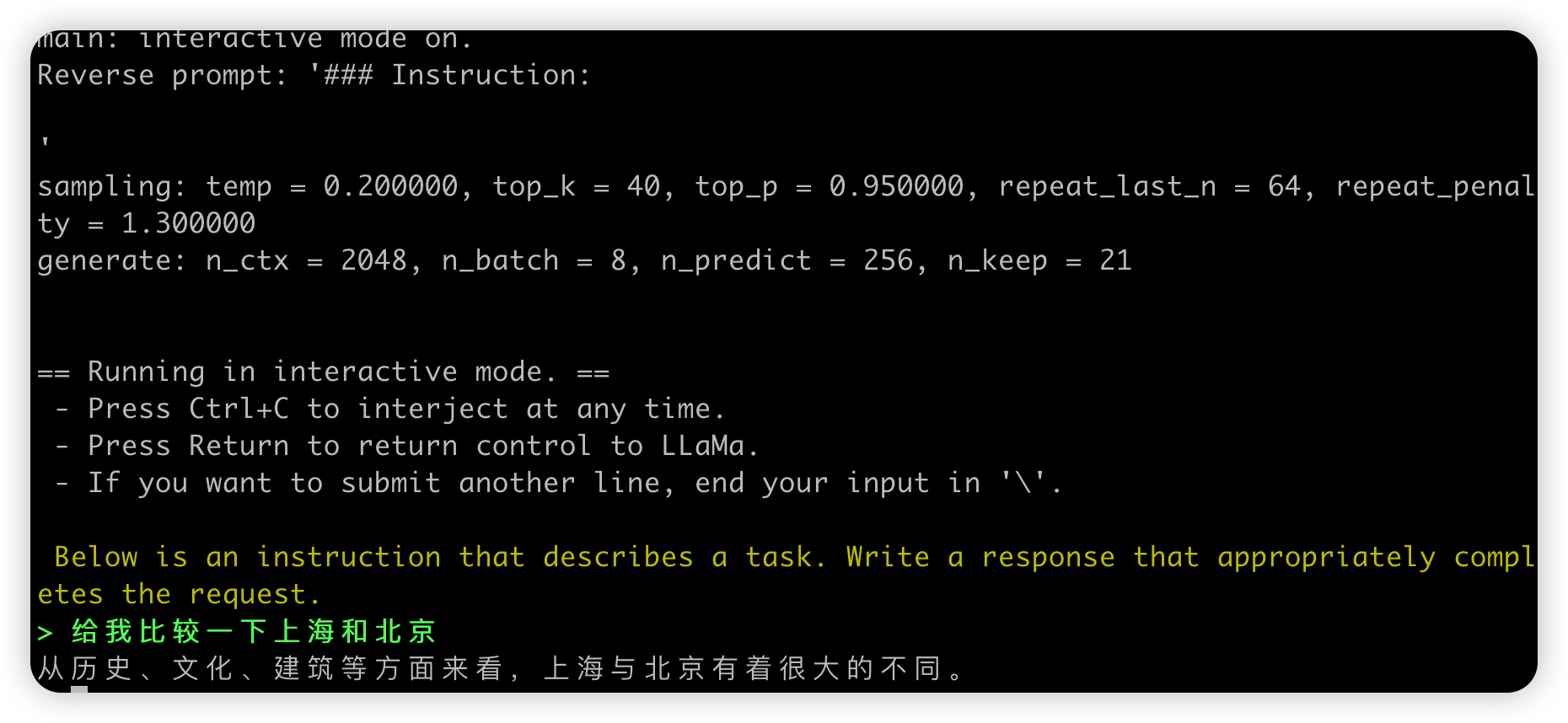
在提示符 > 之后输入你的prompt,command+c中断输出,多行信息以\作为行尾。如需查看帮助和参数说明,请执行./main -h命令。
重要参数说明:
-ins 启动类ChatGPT的对话交流模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-c 控制上下文的长度,值越大越能参考更长的对话历史
-n 控制回复生成的最大长度
--repeat_penalty 控制生成回复中对重复文本的惩罚力度
--temp 温度系数,值越低回复的随机性越小,反之越大
--top_p, top_k 控制采样的相关参数