前言:
机器学习模型性能度量标准之一: 泛化能力
泛化能力强的模型才是好的模型,在评价泛化能力
时候,我们经常遇到过拟合和欠拟合问题

目录:
1: Overfitting
2: underfitting
一 Overfitting
refers to a model that models the training data too well. In other words, the model is still learning patterns but they do not generalize beyond the training set。
Overfitting happens when a model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data. This means that the noise or random fluctuations in the training data is picked up and learned as concepts by the model. The problem is that these concepts do not apply to new data and negatively impact the models ability to generalize.
Overfitting is particularly typical for models that have a large number of parameters, like deep neural networks.
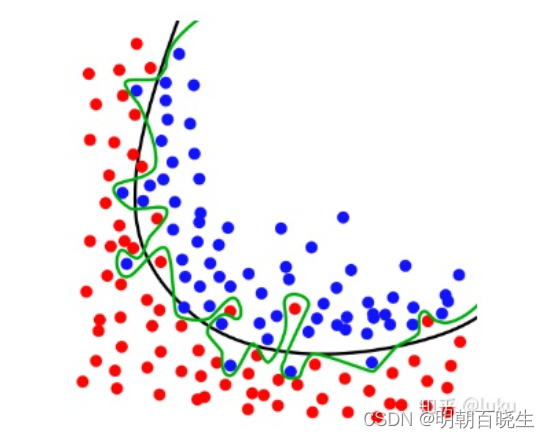
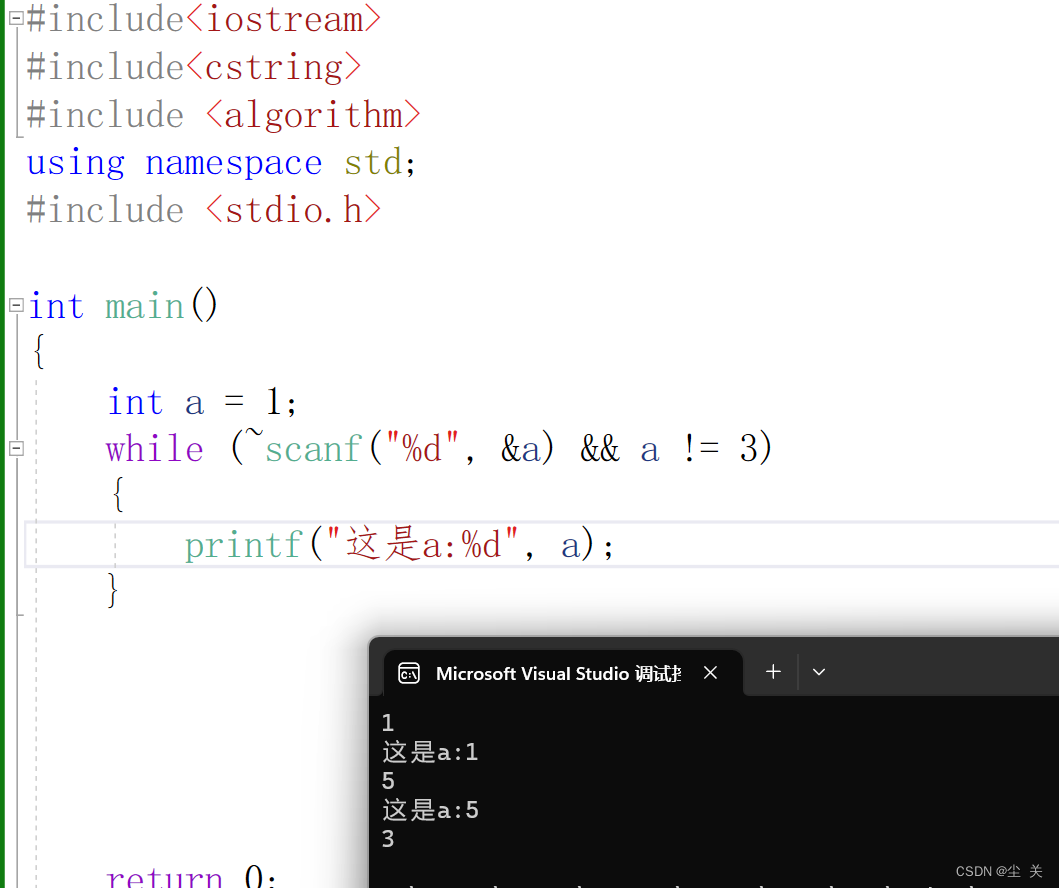
模型在训练集上表现很好,但是泛化能力很差,在测试集或者验证集上表现很差
过拟合会导致高 Variance
机器学习防止过拟合方法
- simpler model structure(选择合适模型)
- regularization(正则化)
- data augmentation(数据集扩增)
- dropout(删除隐藏层结点个数)
- Bootstrap/Bagging(封装)
- ensemble(集成)
- early stopping(提前终止迭代)
- utilize invariance(利用不变性)
- Bayesian(贝叶斯方法)
二 Underfitting(欠拟合)
refers to a model that can neither model the training data nor generalize to new data.
An underfit machine learning model is not a suitable model and will be obvious as it will have poor performance on the training data.
欠拟合 是训练集上表现能力很差,测试集合验证集同样很差
欠拟合会导致高 Bias
解决方案:
1: 增加特征维度
2: 增加模型复杂度(网络深度,层次)
3 集成学习
参考:
欠拟合(Underfitting)& 过拟合(Overfitting) - 知乎
机器学习防止欠拟合、过拟合方法 - 知乎