文章目录
- Bean生命周期源码
- 生成BeanDefinition
- Spring容器启动时创建单例Bean
- 合并BeanDefinition
- getBean()方法
- 加载类
- 实例化前
- 实例化
- BeanDefinition的后置处理
- 实例化后
- 依赖注入
- 执行Aware回调
- 初始化前
- 初始化
- 初始化后
- 销毁逻辑
Bean生命周期源码
我们创建一个ApplicationContext对象时,这其中主要会做两件时间:包扫描得到BeanDefinition的set集合,创建非懒加载的单例Bean
public static void main(String[] args) {
// 创建一个Spring容器
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
UserService userService = (UserService) context.getBean("userService");
userService.test();
}
生成BeanDefinition
在线流程图
首先我们来看AnnotationConfigApplicationContext的构造方法
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
// 构造DefaultListableBeanFactory、AnnotatedBeanDefinitionReader、ClassPathBeanDefinitionScanner
// 这里创建ClassPathBeanDefinitionScanner时,还会添加一个includeFilters,包含@Component注解
this();
register(componentClasses);
refresh();
}
接下来是refresh()方法
public void refresh() throws BeansException, IllegalStateException {
...
// 会拿到上一步创建的ClassPathBeanDefinitionScanner,调用scan方法进行包扫描
invokeBeanFactoryPostProcessors(beanFactory);
/// 会创建非懒加载单例bean
finishBeanFactoryInitialization(beanFactory);
...
}
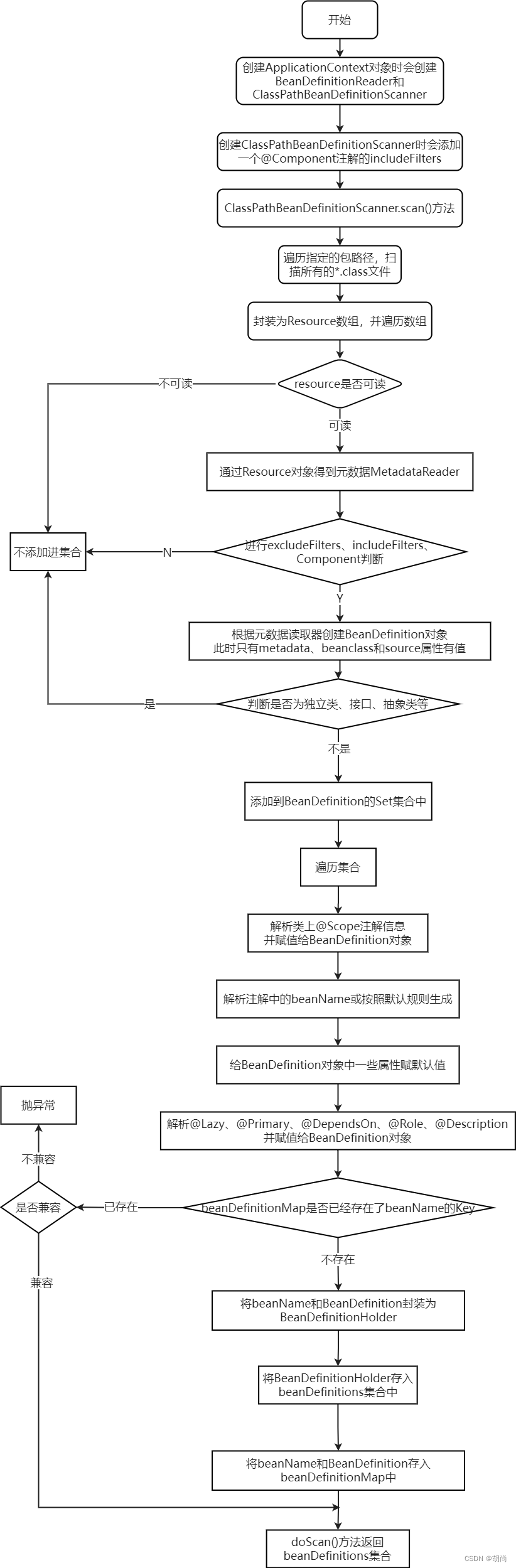
先看包扫描的逻辑,ClassPathBeanDefinitionScanner类主要做的事情就是包扫描完后再将得到的BeanDefinition注册进Spring容器中。
在scan(String... basePackages)方法中会调用doScan(String... basePackages)方法
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
// 创建一个set集合存放扫描到的BeanDefinition
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 可以传多个包路径,但我们一般都只传一个包路径
for (String basePackage : basePackages) {
// 调这个方法就会得到BeanDefinition集合,该方法扫描得到的BeanDefinition对象中主要只是有metadata、beanclass和source属性
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 遍历BeanDefinition集合,解析类的元数据信息为BeanDefinition的其他属性赋值
for (BeanDefinition candidate : candidates) {
// 解析类上@Scope注解信息
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 得到beanName,首先解析@Component注解中有没有指定beanName,如果没有指定再去按照默认是生成规则生成
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 包扫描的ScannedGenericBeanDefinition和AnnotatedGenericBeanDefinition,这两个BeanDefinition都满足下面两个if
if (candidate instanceof AbstractBeanDefinition) {
// 给BeanDefinition赋一些默认值
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 解析@Lazy、@Primary、@DependsOn、@Role、@Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检查Spring容器beanDefinitionMap中是否已经存在该beanName,不存在才会走下面的if逻辑
if (checkCandidate(beanName, candidate)) {
// BeanDefinition中没有存beanName,而是把他们封装为了一个BeanDefinitionHolder对象
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
// 保存到set集合中
beanDefinitions.add(definitionHolder);
// 这里又从BeanDefinitionHolder取出beanName和BeanDefinition,把BeanDefinition注册进容器中的beanDefinitionMap中
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
findCandidateComponents(String basePackage)方法逻辑
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
// 我们可以定义一个resources/META-INF/Spring.components文件,然后就仅仅匹配个文件中指定的类与注解
// 而不扫描指定包路径下的所有*.class文件
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 我们创建的Spring项目一般会走这个逻辑
return scanCandidateComponents(basePackage);
}
}
scanCandidateComponents(String basePackage)方法逻辑,该方法扫描得到的BeanDefinition对象中主要只是有beanclass和source属性
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
// 返回值 存放BeanDefinition对象的Set集合
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 获取指定包路径下所有的*.class文件资源,将 com.hs 变为 classpath*:com/hs/**/*.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 封装为Resource对象
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// 遍历每一个class文件资源对象
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
// 判断当前资源是否可读
if (resource.isReadable()) {
try {
// 得到元数据读取器
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// excludeFilters、includeFilters判断,判断类上是否有@Component,再去判断是否符合@Conditional
if (isCandidateComponent(metadataReader)) {
// 当上面的条件满足后,才会将当前类封装为BeanDefinition对象
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
// 这里还会对当前类进行进一步判断,这个条件满足之后才会将BeanDefinition对象添加进set集合中
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
... ...
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException("Failed to read candidate component class: " + resource, ex);
}
}
else {
...
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
Spring容器启动时创建单例Bean
在线流程图网址
首先我们来看AnnotationConfigApplicationContext的构造方法
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
// 构造DefaultListableBeanFactory、AnnotatedBeanDefinitionReader、ClassPathBeanDefinitionScanner
// 这里创建ClassPathBeanDefinitionScanner时,还会添加一个includeFilters,包含@Component注解
this();
register(componentClasses);
refresh();
}
接下来是refresh()方法
public void refresh() throws BeansException, IllegalStateException {
...
// 会拿到上一步创建的ClassPathBeanDefinitionScanner,调用scan方法进行包扫描
invokeBeanFactoryPostProcessors(beanFactory);
/// 会创建非懒加载单例bean
finishBeanFactoryInitialization(beanFactory);
...
}
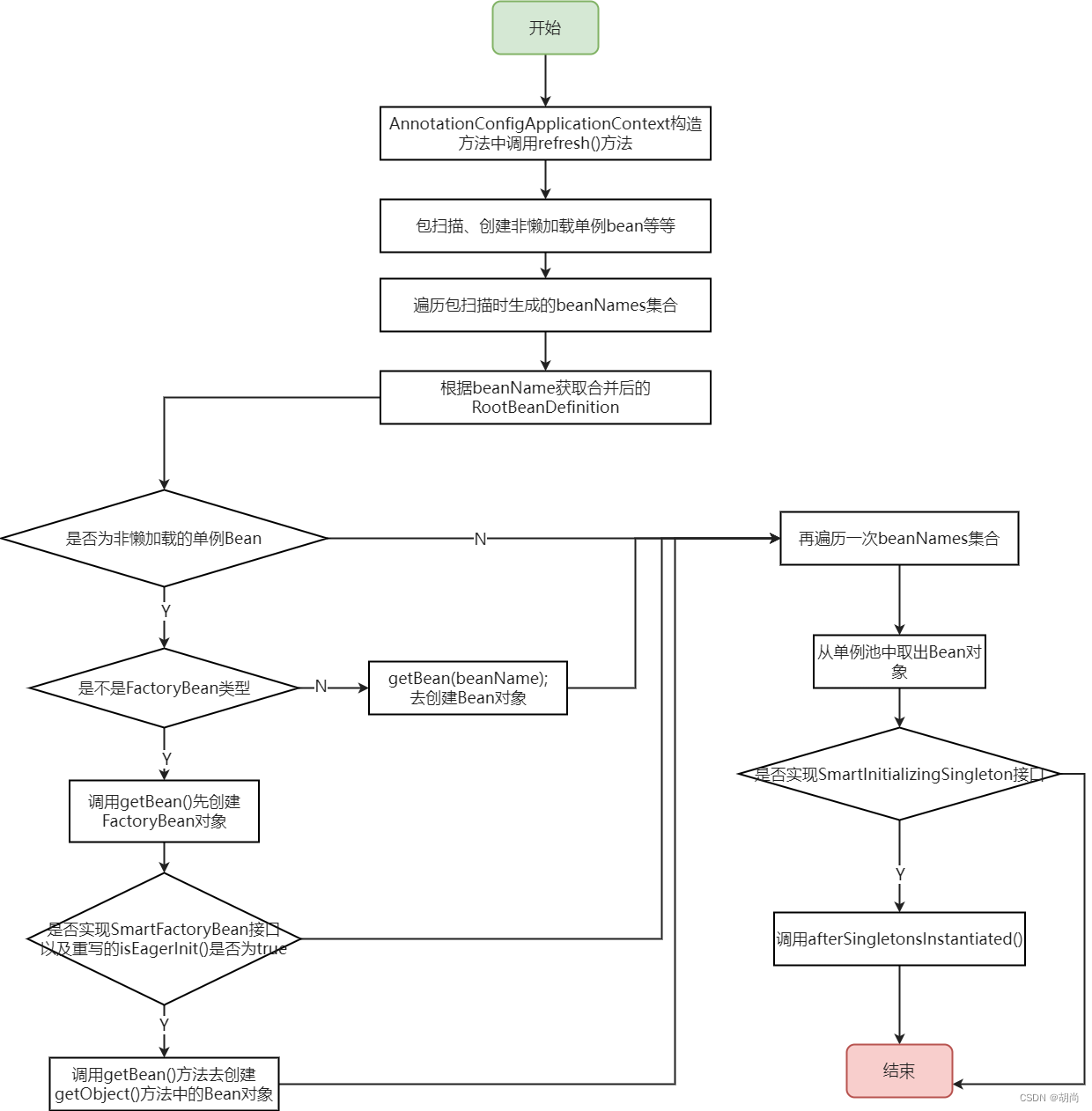
现在就跟finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory)方法
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
... ...
// 实例化非懒加载的单例Bean
beanFactory.preInstantiateSingletons();
}
最终创建的方法是preInstantiateSingletons()
// 首先遍历beanNames集合,将包扫描时创建的BeanDefinition全部完成合并操作
// 判断非懒加载的单例bean
// 判断是不是FactoryBean,如果是则创建FactoryBean对象,如果不是则创建Bean对象
// 所有非懒加载单例Bean都存入单例池之后,再遍历一次beanNames集合,判断有没有实现SmartInitializingSingleton接口
public void preInstantiateSingletons() throws BeansException {
if (logger.isTraceEnabled()) {
logger.trace("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// 所以非懒加载单例Bean初始化
for (String beanName : beanNames) {
// 根据beanName 获取合并后的BeanDefinition,具体合并方法在下面会详细分析
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
// 判断不是抽象的BeanDefinition、单例、不是懒加载
// 一般使用注解方式创建的Bean都不是抽象的,使用XML方式定义Bean时有一个abstract属性来指定
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 判断当前类是不是FactoryBean
if (isFactoryBean(beanName)) {
// 获取FactoryBean对象,加&前缀后获取的是factoryBean对象,而不是getObject()方法返回的对象
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
// 判断当前类有没有实现SmartFactoryBean接口,如果实现了则调用isEagerInit()方法,将方法返回值赋值给isEagerInit
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
// 所以我们一般实现FactoryBean接口,在Spring容器启动时是不会去创建getObject()方法的Bean对象
// 除非我们实现的是SmartFactoryBean接口重写isEagerInit()方法并返回true
if (isEagerInit) {
// 创建FactoryBean.getObject()方法返回的对象
getBean(beanName);
}
}
}
else {
// 一般的Bean都不是FactoryBean,就会直接调用getBean()方法去创建Bean对象
getBean(beanName);
}
}
}
// 所有的非懒加载单例Bean都创建完了后,又会进行一次遍历
// Trigger post-initialization callback for all applicable beans...
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
// 判断当前已经创建好了的单例Bean有没有实现SmartInitializingSingleton接口,如果实现了则调用重写的afterSingletonsInstantiated()方法
if (singletonInstance instanceof SmartInitializingSingleton) {
StartupStep smartInitialize = this.getApplicationStartup().start("spring.beans.smart-initialize")
.tag("beanName", beanName);
SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
smartInitialize.end();
}
}
}
合并BeanDefinition
通过扫描得到所有BeanDefinition之后,就可以根据BeanDefinition创建Bean对象了,但是在Spring中支持父子BeanDefinition
父子BeanDefinition实际用的比较少,使用是这样的,比如:
<bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/>
<bean id="child" class="com.zhouyu.service.Child"/>
这么定义的情况下,child是单例Bean。
<bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/>
<bean id="child" class="com.zhouyu.service.Child" parent="parent"/>
但是这么定义的情况下,child就是原型Bean了。
因为child的父BeanDefinition是parent,所以会继承parent上所定义的scope属性。
如果child它自己定义了scope属性那么就用自己的,如果没有定义那么就用的parent的
之后child需要根据BeanDefinition来生成Bean对象之前,需要进行BeanDefinition的合并,得到完整的child的BeanDefinition,也就是RootBeanDefinition。
上面的两行代码最终会生成四个BeanDefinition,合并之后不会在原BeanDefinition上修改,而是会创建一个RootBeanDefinition,会保存在mergedBeanDefinitions这个Map<String, RootBeanDefinition>中
我们现在所知的就有两个Map了:beanDefinitions、mergedBeanDefinitions。
在线流程图网址
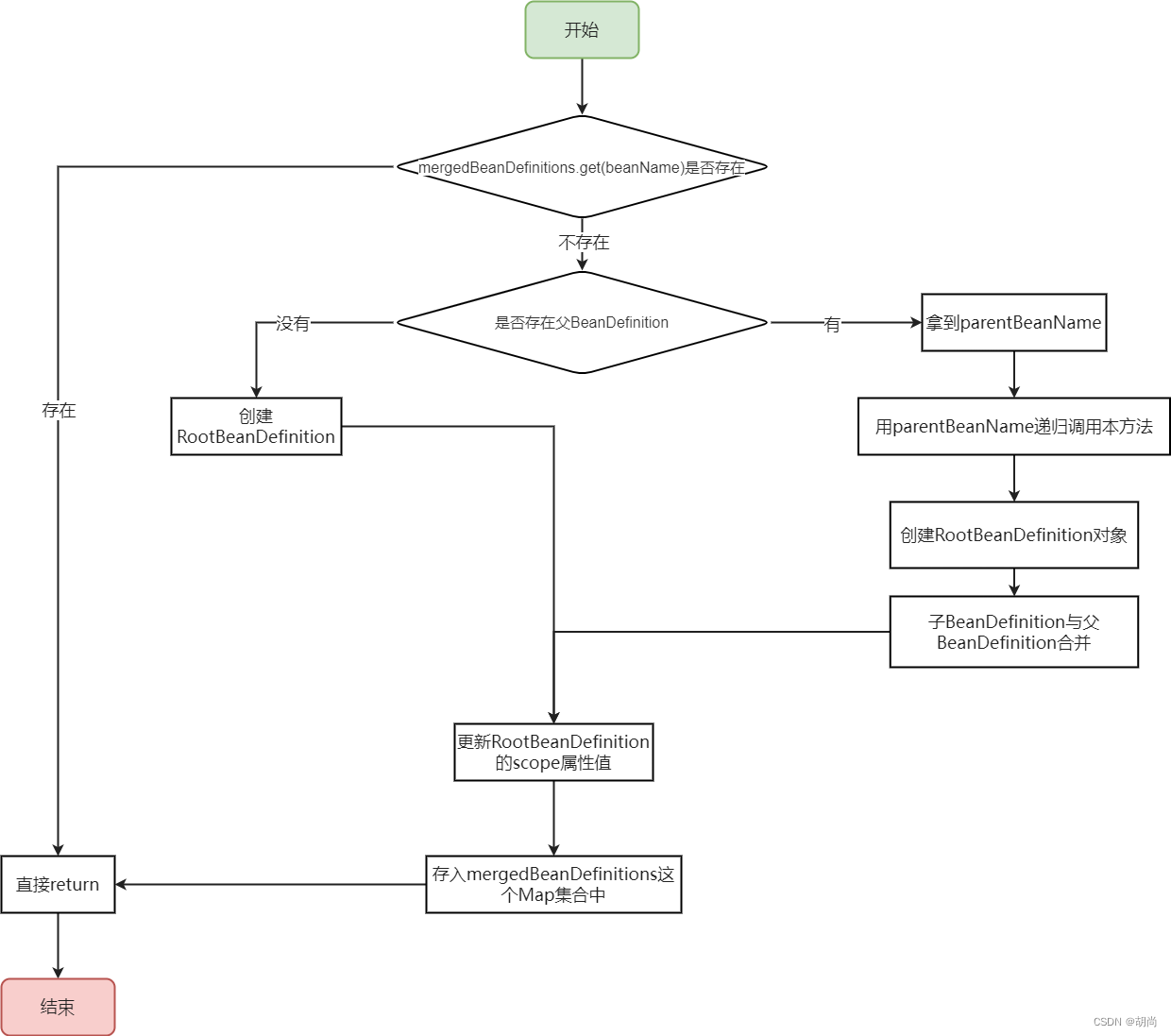
底层源码是在AbstractBeanFactory类的 getMergedLocalBeanDefinition(String beanName)方法中进行合并的
protected RootBeanDefinition getMergedBeanDefinition(
String beanName, BeanDefinition bd, @Nullable BeanDefinition containingBd)
throws BeanDefinitionStoreException {
synchronized (this.mergedBeanDefinitions) {
RootBeanDefinition mbd = null;
RootBeanDefinition previous = null;
if (containingBd == null) {
mbd = this.mergedBeanDefinitions.get(beanName);
}
if (mbd == null || mbd.stale) {
previous = mbd;
// 如果当前BeanDefinition没有指定parentName属性,那么就会根据当前BeanDefinition直接创建一个RootBeanDefinition
if (bd.getParentName() == null) {
// Use copy of given root bean definition.
if (bd instanceof RootBeanDefinition) {
mbd = ((RootBeanDefinition) bd).cloneBeanDefinition();
}
else {
mbd = new RootBeanDefinition(bd);
}
}
else {
// 如果当前BeanDefinition指定parentName属性那么走下面的逻辑
// pbd表示parentBeanDefinition,是父BeanDefinition,下面的逻辑是为pdb赋值,采用的方式的递归调用本方法
BeanDefinition pbd;
try {
String parentBeanName = transformedBeanName(bd.getParentName());
if (!beanName.equals(parentBeanName)) {
pbd = getMergedBeanDefinition(parentBeanName);
}
else {
BeanFactory parent = getParentBeanFactory();
if (parent instanceof ConfigurableBeanFactory) {
pbd = ((ConfigurableBeanFactory) parent).getMergedBeanDefinition(parentBeanName);
}
else {
throw new NoSuchBeanDefinitionException(...);
}
}
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanDefinitionStoreException(...);
}
// 子BeanDefinition的属性覆盖父BeanDefinition的属性,这就是合并
mbd = new RootBeanDefinition(pbd);
mbd.overrideFrom(bd);
}
// 如果scope没值就给默认值singleton
if (!StringUtils.hasLength(mbd.getScope())) {
mbd.setScope(SCOPE_SINGLETON);
}
if (containingBd != null && !containingBd.isSingleton() && mbd.isSingleton()) {
mbd.setScope(containingBd.getScope());
}
// 将新创建的RootBeanDefinition存入Map集合中
if (containingBd == null && isCacheBeanMetadata()) {
this.mergedBeanDefinitions.put(beanName, mbd);
}
}
if (previous != null) {
copyRelevantMergedBeanDefinitionCaches(previous, mbd);
}
return mbd;
}
}
getBean()方法
从前面一部分的源码中可以知道,当合并完BeanDefinition之后就会调用getBean()方法来创建非懒加载的单例Bean了。
接下来就从这个方法开始分析
getBean()方法有四个重载方法,关键参数也就三个
@Override
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
@Override
public <T> T getBean(String name, Class<T> requiredType) throws BeansException {
return doGetBean(name, requiredType, null, false);
}
@Override
public Object getBean(String name, Object... args) throws BeansException {
// 这个参数args需要注意
// 如果是单例Bean,在Spring启动就创建好了,我们显示调用此方法传参数其实是无效的,它直接去singletonObjects中拿对象而不会再去调用构造方法创建
return doGetBean(name, null, args, false);
}
/**
* @param name Bean的名字
* @param requiredType 返回Bean对象的类型,如果单例池中得到的Bean对象不是我们指定的class类型则会去进行类型转换,如果失败则抛异常
* @param args 创建Bean实例时要用的参数,也就到调用构造方法创建普通对象的参数,与选择构造方法有关。
*/
public <T> T getBean(String name, @Nullable Class<T> requiredType, @Nullable Object... args)
throws BeansException {
return doGetBean(name, requiredType, args, false);
}
接下来就是doGetBean(...)的逻辑
在线流程图
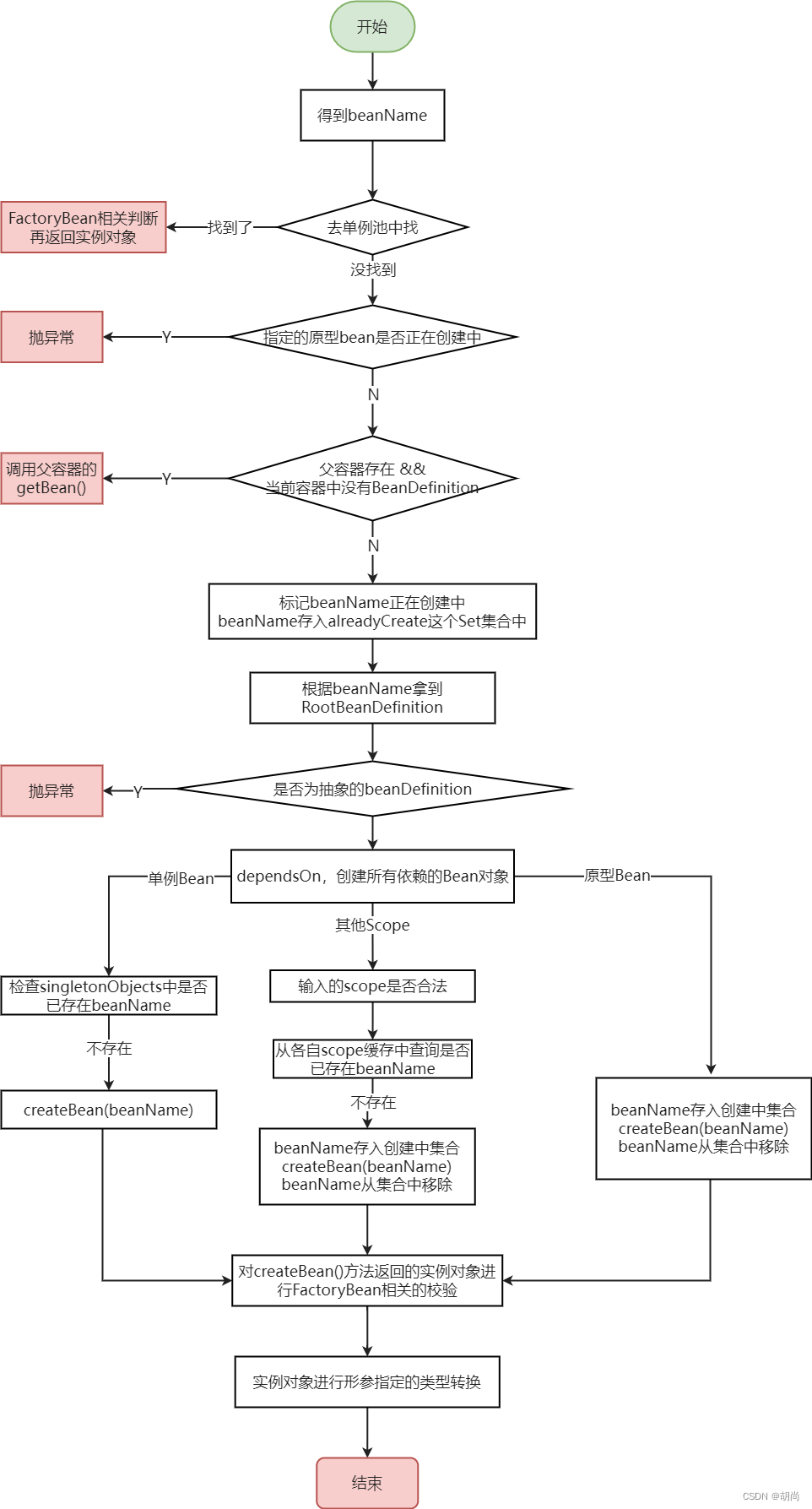
源码如下:
protected <T> T doGetBean(
String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly)
throws BeansException {
// name有可能是 &xxx 或者 xxx,如果name是&xxx,那么该方法返回的beanName是xxx
// name有可能传入进来的是别名,那么该方法返回的beanName就是id
String beanName = transformedBeanName(name);
Object beanInstance;
// 单例池拿到了就直接返回,原型Bean是不会存入singletonObjects中的
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
if (logger.isTraceEnabled()) {
if (isSingletonCurrentlyInCreation(beanName)) {
logger.trace("Returning eagerly cached instance of singleton bean '" + beanName +
"' that is not fully initialized yet - a consequence of a circular reference");
}
else {
logger.trace("Returning cached instance of singleton bean '" + beanName + "'");
}
}
// 如果sharedInstance不是FactoryBean就直接返回当前sharedInstance对象
// 如果sharedInstance是FactoryBean,name是&xxx,那么就直接返回单例池中当前sharedInstance对象
// 如果sharedInstance是FactoryBean,name是xxx,那么就调用getObject()返回对象,这里的name是&XXX,beanName是XXX
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
// 返回指定的原型bean当前是否正在创建中,循环依赖会用到
// Fail if we're already creating this bean instance:
// We're assumably within a circular reference.
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// 检查BeanDefinition是否存在父容器中
// Check if bean definition exists in this factory.
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// Not found -> check parent.
// &&&&xxx---->&xxx
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
return ((AbstractBeanFactory) parentBeanFactory).doGetBean(
nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
// Delegation to parent with explicit args.
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else if (requiredType != null) {
// No args -> delegate to standard getBean method.
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
else {
return (T) parentBeanFactory.getBean(nameToLookup);
}
}
// getBean()方法传的typeCheckOnly为false,标记beanName正在创建中,其实就是把beanName存入了alreadyCreated这个Set集合中
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
StartupStep beanCreation = this.applicationStartup.start("spring.beans.instantiate")
.tag("beanName", name);
// 接下来就是真正要看的流程了
try {
if (requiredType != null) {
beanCreation.tag("beanType", requiredType::toString);
}
RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
// 检查BeanDefinition是不是Abstract的
checkMergedBeanDefinition(mbd, beanName, args);
// 保证当前bean所依赖的bean的初始化。
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
// dependsOn表示当前beanName所依赖的,当前Bean创建之前dependsOn所依赖的Bean必须已经创建好了
for (String dep : dependsOn) {
// beanName是不是被dep依赖了,如果是则出现了循环依赖,直接抛异常
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// dep被beanName依赖了,存入dependentBeanMap中,dep为key,beanName为value
// dependentBeanMap表示是的某个bean被那些bean依赖了
registerDependentBean(dep, beanName);
// 创建所依赖的bean
try {
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
// 在getSingleton()方法中 ,先调用createBean去创建单例Bean,创建完成之后在存入单例池singleton中
// Create bean instance.
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
// 创建单例Bean
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
// 首先在当前bean在单例池中移除,再删除所有依赖了当前bean的对象
destroySingleton(beanName);
throw ex;
}
});
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
else if (mbd.isPrototype()) {
// It's a prototype -> create a new instance.
Object prototypeInstance = null;
try {
// 创建之前将beanName存入一个set集合中,用ThreadLocal保存set集合
beforePrototypeCreation(beanName);
// 创建原型bean
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
// 创建完成之后再从Set集合中删除beanName
afterPrototypeCreation(beanName);
}
beanInstance = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
else {
// 其他作用域 先检查@Scope注解写的值是否正确
String scopeName = mbd.getScope();
if (!StringUtils.hasLength(scopeName)) {
throw new IllegalStateException("No scope name defined for bean ´" + beanName + "'");
}
Scope scope = this.scopes.get(scopeName);
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + scopeName + "'");
}
try {
// 再去调用各个Scope作用域的get()方法,lambda的延迟加载,一样判断各自缓存中是否存在对象,如果不存在就去创建
// 类似于:request.getAttribute(beanName)
Object scopedInstance = scope.get(beanName, () -> {
beforePrototypeCreation(beanName);
try {
return createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
});
beanInstance = getObjectForBeanInstance(scopedInstance, name, beanName, mbd);
}
catch (IllegalStateException ex) {
throw new ScopeNotActiveException(beanName, scopeName, ex);
}
}
}
catch (BeansException ex) {
beanCreation.tag("exception", ex.getClass().toString());
beanCreation.tag("message", String.valueOf(ex.getMessage()));
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
finally {
beanCreation.end();
}
}
// 检查通过name所获得到的beanInstance的类型是否是requiredType
return adaptBeanInstance(name, beanInstance, requiredType);
}
接下来就是分析createBean()方法的逻辑了
加载类
要创建一个bean对象,首先需要加载类
在AbstractAutowireCapableBeanFactory类的createBean(String beanName, RootBeanDefinition mbd, Object[] args)方法开始就会进行类加载
// 马上就要实例化Bean了,确保beanClass被加载了
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
// 类加载完成之后,再更新BeanDefinition中的beanClass属性,将之前的全路径类名字符串改为Class对象
mbdToUse.setBeanClass(resolvedClass);
}
实例化前
我们知道BeanPostProcessor接口的作用是在bean初始化前和初始化后执行一些方法,Spring提供了该接口的子接口来进行实例化前后执行的一些方法。
比如InstantiationAwareBeanPostProcessor接口
public interface InstantiationAwareBeanPostProcessor extends BeanPostProcessor {
// 我们可以在实例化之前,自己根据class对象去进行实例化对象,再返回。
// 这种方式返回的对象不会走之后依赖注入、初始化相关的步骤,但是会走初始化后的步骤
@Nullable
default Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
return null;
}
default boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
return true;
}
@Nullable
default PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName)
throws BeansException {
return null;
}
}
例如
@Component
public class MyBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
if ("userService".equals(beanName)) {
System.out.println("实例化前");
return new UserService();// userService对象不会再经过依赖注入、初始化等步骤,但是会走初始化后的步骤
}
return null;
}
}
接下来看源码,类加载完成之后就会准备进行实例化了,在进行实例化之前会调用下面方法
// 实例化前,去执行InstantiationAwareBeanPostProcessors接口的方法
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
@Nullable
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
// synthetic表示合成,如果某些Bean式合成的,那么则不会经过BeanPostProcessor的处理。
// 之后的方法是判断当前容器中是否存在InstantiationAwareBeanPostProcessors
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
// 这是上一步类加载的class
Class<?> targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
// 然后真正去执行实现接口重写的抽象方法
// 遍历所有的InstantiationAwareBeanPostProcessors去执行它们的before方法
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
// 实例化前的前置方法如果不返回null则去执行BeanPostProcessor的after方法
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}
// 取出所有的InstantiationAwareBeanPostProcessors进行遍历执行,如果有一个返回值不为null则直接返回
protected Object applyBeanPostProcessorsBeforeInstantiation(Class<?> beanClass, String beanName) {
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
Object result = bp.postProcessBeforeInstantiation(beanClass, beanName);
if (result != null) {
return result;
}
}
return null;
}
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName) throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
实例化
接下来会调用doCreateBean()方法,真正进行创建bean对象
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {
// 实例化bean,BeanWrapper其实就是的bean实例对象进行了一个包装
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
// 有可能在本Bean创建之前,就有其他Bean把当前Bean给创建出来了(比如依赖注入过程中、FactoryBean)
// 有值的情况比较少见,可以先不用管
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
// 创建Bean实例
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
...
}
实例化的核心就是调用createBeanInstance()方法,此方法在后续会详细分析
BeanDefinition的后置处理
Bean实例化之后,Spring提供了一个对BeanDefinition的扩展点,可以自定义对BeanDefinition进行加工
其实就是MergedBeanDefinitionPostProcessor接口的postProcessMergedBeanDefinition()方法
public interface MergedBeanDefinitionPostProcessor extends BeanPostProcessor {
void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName);
default void resetBeanDefinition(String beanName) {
}
}
比如
@Component
public class MyMergedBeanDefinitionPostProcessor implements MergedBeanDefinitionPostProcessor {
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
if ("userService".equals(beanName)) {
// 比如指定一个初始化方法。还可以对BeanDefinition进行各种自定义操作
beanDefinition.setInitMethodName("init");
// 给某个属性赋值
beanDefinition.getPropertyValues().add("orderService", new OrderService());
}
}
}
在doCreateBean()方法中对应的源码是
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {
// 实例化... ...
// 后置处理合并后的BeanDefinition
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
...
}
接下来再是applyMergedBeanDefinitionPostProcessors()方法
protected void applyMergedBeanDefinitionPostProcessors(RootBeanDefinition mbd, Class<?> beanType, String beanName) {
// 其实就是把Spring容器中所有的MergedBeanDefinitionPostProcessor进行遍历,并调用重写的抽象方法
for (MergedBeanDefinitionPostProcessor processor : getBeanPostProcessorCache().mergedDefinition) {
processor.postProcessMergedBeanDefinition(mbd, beanType, beanName);
}
}
实例化后
实例化之后的postProcessAfterInstantiation()其实是在下一步依赖注入populateBean()方法中进行调用的
public interface InstantiationAwareBeanPostProcessor extends BeanPostProcessor {
// 实例化之前调用的方法
@Nullable
default Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
return null;
}
// 实例化之后调用的方法
// 如果下面返回了false,那么就会跳过依赖注入的步骤
default boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
return true;
}
// 此方法也是在依赖注入的populateBean()方法中调用的
// @Autowired、@Resource、@Value这些注解也都是在下面这个方法中实现的
@Nullable
default PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName)
throws BeansException {
return null;
}
}
依赖注入
BeanDefinition后置处理之后就是给属性赋值进行依赖注入了
先是把beanName、BeanDefinition、bean实例对象当成方法参数存入第三级缓存singletonFactories中,循环依赖的过程中会用到
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
然后再调用populateBean()方法进行属性填充 依赖注入
populateBean(beanName, mbd, instanceWrapper);
populateBean()方法详情如下
在线流程图
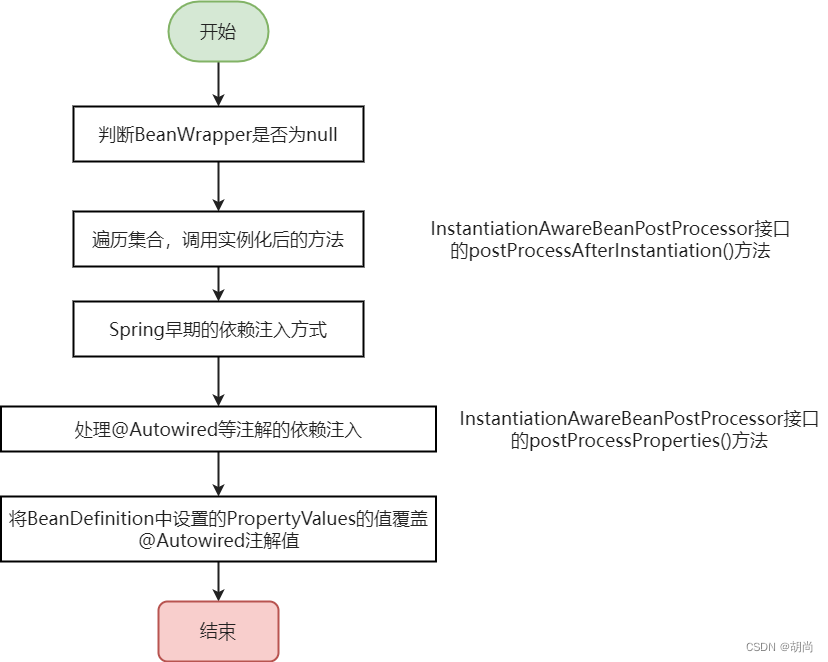
源码:
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
// 经过实例化createBeanInstance()方法之后,一般情况下BeanWrapper都不为null
if (bw == null) {
if (mbd.hasPropertyValues()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
return;
}
}
// 实例化之后,属性注入之前,调用InstantiationAwareBeanPostProcessor接口的after后置方法
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
if (!bp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
// 下面这一段是Spring自带的依赖注入方式,已过时了解即可。
// 我们除了@Autowired注解之外,还可以使用 @Bean(autowire = Autowire.BY_NAME) ,然后就会遍历set方法进行依赖注入
// 需要注意的是如果是BY_NAME的方式,它不是用的方法形参变量名,而是用的setXXX()方法名中的XXX
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
// MutablePropertyValues是PropertyValues具体的实现类
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
// 再一次判断Spring容器中有没有InstantiationAwareBeanPostProcessor类型的Bean对象
// @Autowired、@Resource、@Value这些注解也都是在下面这段for循环中实现的
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
// pvs就是我们可以在BeanDefinition后置处理MergedBeanDefinitionPostProcessor接口中的方法给BeanDefinition的PropertyValue设置一些值
// Spring在@Autowired依赖注入的时候就会判断 我事先有没有利用pvs自定义给某属性赋值,如果有,那么Spring就不用再给这个属性注入一次了
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
// @Autowired注解 这里会调用AutowiredAnnotationBeanPostProcessor的postProcessProperties()方法,会直接给对象中的属性赋值
// AutowiredAnnotationBeanPostProcessor内部并不会处理pvs,直接返回了
PropertyValues pvsToUse = bp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
pvsToUse = bp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
if (needsDepCheck) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
checkDependencies(beanName, mbd, filteredPds, pvs);
}
// 如果当前Bean中的BeanDefinition中设置了PropertyValues,那么最终将是PropertyValues中的值,覆盖@Autowired
if (pvs != null) {
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
执行Aware回调
在AbstractAutowireCapableBeanFactory类的doCreateBean()方法中,属性注入populateBean()之后就会调用initializeBean()初始化方法了。
在initializeBean()初始化方法的开头会调用invokeAwareMethods()方法执行Aware回调方法
private void invokeAwareMethods(String beanName, Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
初始化前
在initializeBean()初始化方法调用invokeAwareMethods()方法执行Aware回调方法之后,就会调用下面方法执行初始化前的逻辑
Object wrappedBean = bean;
// 初始化前
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
其实就是执行BeanPostProcessor接口中的postProcessBeforeInitialization()方法,我们可以对进行了依赖注入的Bean进行处理。
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
// 方法的返回值又会作为下一个方法的入参
// 如果返回null,则之后的before方法就不会执行了
Object current = processor.postProcessBeforeInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
InitDestroyAnnotationBeanPostProcessor会在初始化前这个步骤中执行@PostConstruct的方法,ApplicationContextAwareProcessor会在初始化前这个步骤中进行其他Aware的回调:- EnvironmentAware:回传环境变量
- EmbeddedValueResolverAware:回传占位符解析器
- ResourceLoaderAware:回传资源加载器
- ApplicationEventPublisherAware:回传事件发布器
- MessageSourceAware:回传国际化资源
- ApplicationStartupAware:回传应用其他监听对象,可忽略
- ApplicationContextAware:回传Spring容器ApplicationContext
初始化
在initializeBean()初始化方法中接下来会调用初始化方法
invokeInitMethods(beanName, wrappedBean, mbd);
protected void invokeInitMethods(String beanName, Object bean, @Nullable RootBeanDefinition mbd)
throws Throwable {
// 判断bean实例对象是否实现了InitializingBean接口,如果实现了该接口就调用重写后的afterPropertiesSet()方法
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
if (logger.isTraceEnabled()) {
logger.trace("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");
}
if (System.getSecurityManager() != null) {
try {
AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () -> {
((InitializingBean) bean).afterPropertiesSet();
return null;
}, getAccessControlContext());
}
catch (PrivilegedActionException pae) {
throw pae.getException();
}
}
else {
((InitializingBean) bean).afterPropertiesSet();
}
}
// 调用RootBeanDefinition的initMethodName属性指定的初始化方法
if (mbd != null && bean.getClass() != NullBean.class) {
String initMethodName = mbd.getInitMethodName();
if (StringUtils.hasLength(initMethodName) &&
!(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
invokeCustomInitMethod(beanName, bean, mbd);
}
}
}
初始化后
initializeBean()初始化方法,调用下面的方法进行初始化之后的业务逻辑代码执行
// 初始化后 AOP
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
其实就是执行BeanPostProcessor接口的postProcessAfterInitialization()方法
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
// 遍历BeanPostProcessor集合,并执行after方法
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
可以在这个步骤中,对Bean最终进行处理,Spring中的AOP就是基于初始化后实现的,初始化后返回的对象才是最终的Bean对象。
销毁逻辑
销毁方式:
-
实现
DisposableBean接口,重写destroy()抽象方法。 -
实现
AutoCloseable接口 -
实现
DestructionAwareBeanPostProcessor接口Spring中的
@PreDestroy注解的实现就是基于这种机制在InitDestroyAnnotationBeanPostProcessor类中实现的, -
使用
@PreDestroy注解
销毁的方法如果是单例Bean,会先暂存在Spring容器的一个Map中,则会在Spring容器销毁时调用。
// 我们可以注册一个关闭的钩子,这样就不用显示的调用close()方法了
context.registerShutdownHook();
// 我们可以显示的调用close()方法 容器关闭
context.close();
除了原型的 其他Scope的Bean,则会存在各自具体的实现类中
在AbstractAutowireCapableBeanFactory类的doCreateBean()方法中,最后还有一个销毁相关的代码
try {
// Bean的销毁
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
registerDisposableBeanIfNecessary()方法逻辑如下:
protected void registerDisposableBeanIfNecessary(String beanName, Object bean, RootBeanDefinition mbd) {
AccessControlContext acc = (System.getSecurityManager() != null ? getAccessControlContext() : null);
// 当前bean不是原型,并且判断bean在关闭时是否需要调用调回方法
if (!mbd.isPrototype() && requiresDestruction(bean, mbd)) {
// 单例
if (mbd.isSingleton()) {
// 使用适配器设计模型,封装为一个DisposableBeanAdapter对象,然后存入disposableBeans这个Map集合中。
// 因为有很多种销毁的方式,所以这里就要使用适配器设计模式
registerDisposableBean(beanName, new DisposableBeanAdapter(
bean, beanName, mbd, getBeanPostProcessorCache().destructionAware, acc));
}
else {
// 非原型 其他scope的Bean
Scope scope = this.scopes.get(mbd.getScope());
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + mbd.getScope() + "'");
}
scope.registerDestructionCallback(beanName, new DisposableBeanAdapter(
bean, beanName, mbd, getBeanPostProcessorCache().destructionAware, acc));
}
}
}
判断bean在关闭时是否需要调用调回方法的逻辑如下:
/**
* 就是判断当前Bean对象有没有销毁的业务逻辑。有没有实现接口、有没有@PreDestroy注解方法
* DisposableBeanAdapter.hasDestroyMethod(bean, mbd)判断有没有实现相应接口、BeanDefinition中销毁方法属性值相关的判断
* 之后的就是DestructionAwareBeanPostProcessors的判断
*/
protected boolean requiresDestruction(Object bean, RootBeanDefinition mbd) {
return (bean.getClass() != NullBean.class && (DisposableBeanAdapter.hasDestroyMethod(bean, mbd) ||
(hasDestructionAwareBeanPostProcessors() && DisposableBeanAdapter.hasApplicableProcessors(
bean, getBeanPostProcessorCache().destructionAware))));
}
接下来看一下容器关闭时,如何调用销毁的逻辑代码。
具体代码在AbstractApplicationContext类的doClose()方法 --> destroyBeans()方法 --> destroySingletons()方法
public void destroySingletons() {
// 执行bean的销毁方法
super.destroySingletons();
// 清空manualSingletonNames集合
updateManualSingletonNames(Set::clear, set -> !set.isEmpty());
clearByTypeCache();
}
执行bean的销毁方法
public void destroySingletons() {
if (logger.isTraceEnabled()) {
logger.trace("Destroying singletons in " + this);
}
synchronized (this.singletonObjects) {
this.singletonsCurrentlyInDestruction = true;
}
// 执行bean的销毁方法,从disposableBeans这个Map集合中取出来
String[] disposableBeanNames;
synchronized (this.disposableBeans) {
disposableBeanNames = StringUtils.toStringArray(this.disposableBeans.keySet());
}
for (int i = disposableBeanNames.length - 1; i >= 0; i--) {
destroySingleton(disposableBeanNames[i]);
}
// 清空dependent依赖的map集合
this.containedBeanMap.clear();
this.dependentBeanMap.clear();
this.dependenciesForBeanMap.clear();
// 清空三级缓存的map集合
clearSingletonCache();
}

![[pgrx开发postgresql数据库扩展]3.hello world全流程解析](https://img-blog.csdnimg.cn/img_convert/cc692a6dd100f34e4abbf8835f70d9a0.webp?x-oss-process=image/format,png)