推荐语
4月5日,Meta发布 Segment Anything 模型和 SA-1B 数据集,引发CV届“地震”,其凭借一己之力,成功改写了物体检测、数据标注、图像分割等任务的游戏规则。
复旦大学ZVG实验室团队基于此最新开源了SSA语义分割框架和SSA-engine自动注释引擎,可以为所有mask自动地生成细粒度语义标签,填补了SA-1B中缺乏的细粒度语义标注的空白,为构建大规模语义分割数据集打下基础,也可以用于多模态的特征对齐等研究。
最后,我们提供了包含SA-1B在内的多个数据集快速下载地址,欢迎大家关注与探索。
本文已授权,作者丨复旦大学ZVG实验室
Semantic Segment Anything 丨 复旦大学ZVG实验室
Repo: https://github.com/fudan-zvg/Semantic-Segment-Anything
Demo:https://replicate.com/cjwbw/semantic-segment-anything

SAM是一种强大的图像分割模型,SA-1B是目前为止最大的分割数据集。然而,SAM缺乏为每个mask预测语义类别的能力。为了弥补上述不足,我们提出了一个基于SAM的语义分割框架,不仅能准确地分割mask,还能预测每个mask的语义类别,称为Semantic Segment Anything (SSA)。
此外,我们的SSA可以作为一个自动化的稠密开放词汇标注引擎,称为Semantic segment anything labeling engine (SSA-engine),为SA-1B或任何其他数据集提供丰富的语义类别注释。该引擎显著减少了人工注释及相关成本的需求。
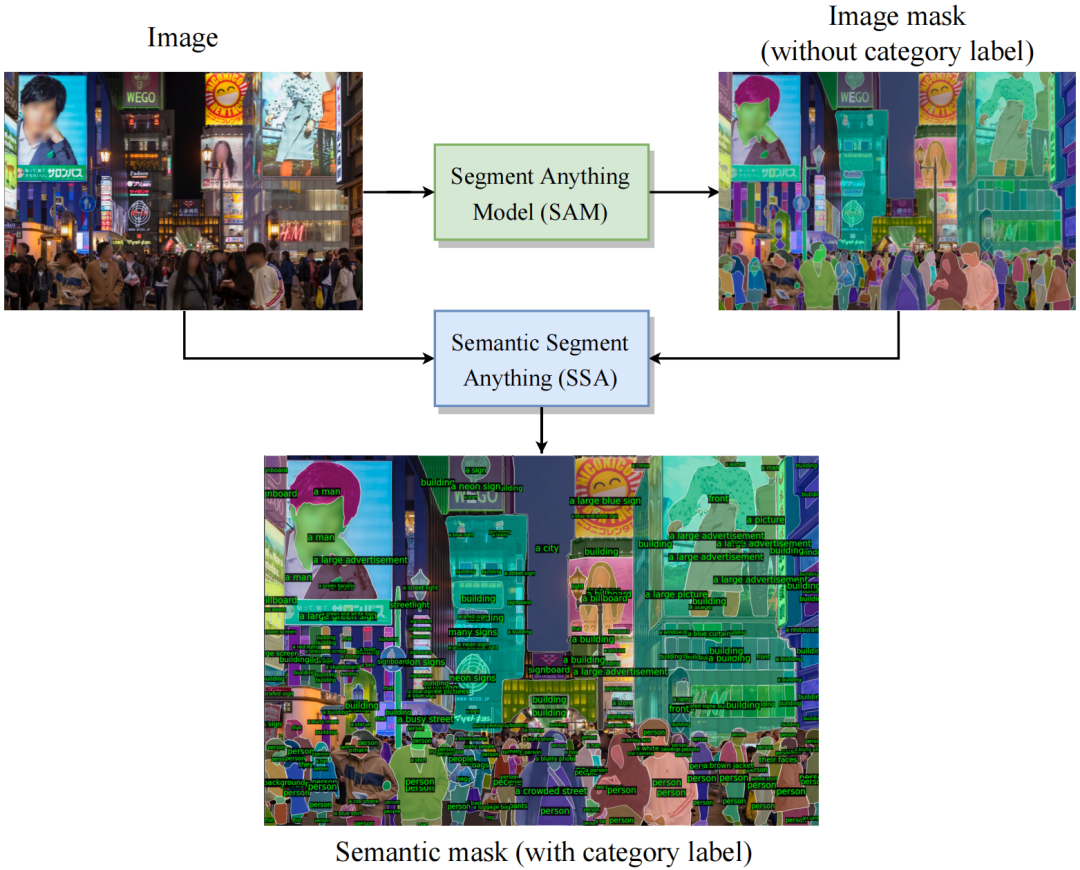
为什么我们需要SSA:
-
SAM是一种高度可泛化的图像分割算法,可以提供精确的mask分割。SA-1B是迄今为止最大的图像分割数据集,提供了精细的mask分割注释。但是,SAM和SA-1B都没有为每个mask提供类别预测或注释。这使得研究人员难以直接使用强大的SAM算法来解决语义分割任务,或者利用SA-1B来训练自己的模型。
-
先进的close-set分割器,如Oneformer,open-set分割器,如CLIPSeg,以及image caption方法,如BLIP,可以提供丰富的语义注释。不过,它们的mask分割预测可能无法分割出像SAM那么精确和细腻的边界。
-
因此,通过将SAM和SA-1B的精细图像分割mask与这些先进模型提供的丰富语义类别标注相结合,我们可以生成具有更强泛化能力的语义分割模型,以及一个大规模语义分割的图像分割数据集。
SSA能做什么?
● SSA: 这是第一个利用SAM进行语义分割任务的开放框架。它支持用户将其现有的语义分割器与SAM无缝集成,无需重新训练或微调SAM的权重,从而实现更好的泛化和更精确的掩模边界。
● SSA-engine: SSA-engine为大规模的SA-1B数据集提供了密集的开放词汇类别注释。在手动审核和精细化之后,这些注释可以用于训练分割模型或细粒度的CLIP模型。
下面为大家详细介绍一下。
SSA:语义分割一切
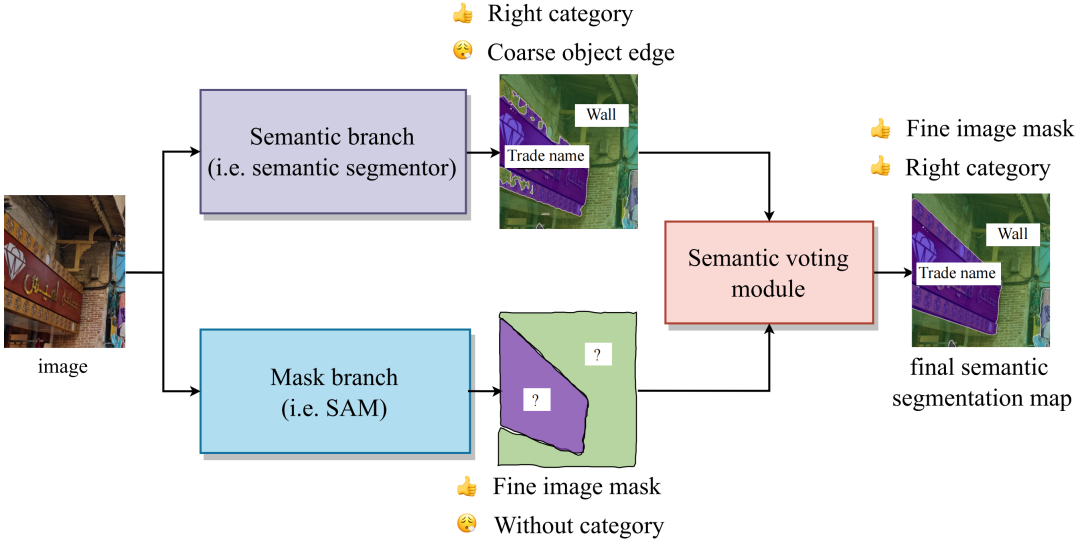
在引入SAM之前,大多数语义分割应用场景已经有了自己的模型。这些模型可以为区域提供粗略的类别分类,但在边缘处模糊不清,缺乏精确的掩模。为了解决这个问题,我们提出一种利用SAM来增强原有模型性能的开放框架——SSA,即使用原始语义分割模型提供类别,同时利用强大的SAM提供掩模。
如果您已经在数据集上训练了一个语义分割模型,您不需要为了更精准的分割能力,重新训练一个基于SAM的新模型。相反,您可以继续使用旧模型作为语义分支(Semantic branch)。SAM强大的泛化和图像分割能力可以提高原有模型的性能。值得注意的是,SSA适用于原本的分割器预测的掩模边界不是非常精确的场景,如果原有模型的分割已经非常精确了,则SSA很难带来提升。
SSA包含两个分支,Mask Branch和Semantic Branch,以及一个投票模块来决定每个mask的类别。
-
Mask branch(蓝色)。SAM可以作为Mask branch提供一组有清晰边界的mask。
-
Semantic branch(紫色)。这个分支为每个像素提供语义类别,它由一个语义分割器实现,用户可以自定义用户感兴趣的类别的分割器。这个分割器不需要具有非常精细的边界预测能力,但应该尽可能准确地对每个区域进行分类。
-
Semantic Voting module(红色)。这个模块根据mask的位置裁剪出相应的像素类别。在这些像素类别中,像素数量排名第一的类别将被视为该mask的分类结果。
SSA-engine:自动化类别标注引擎
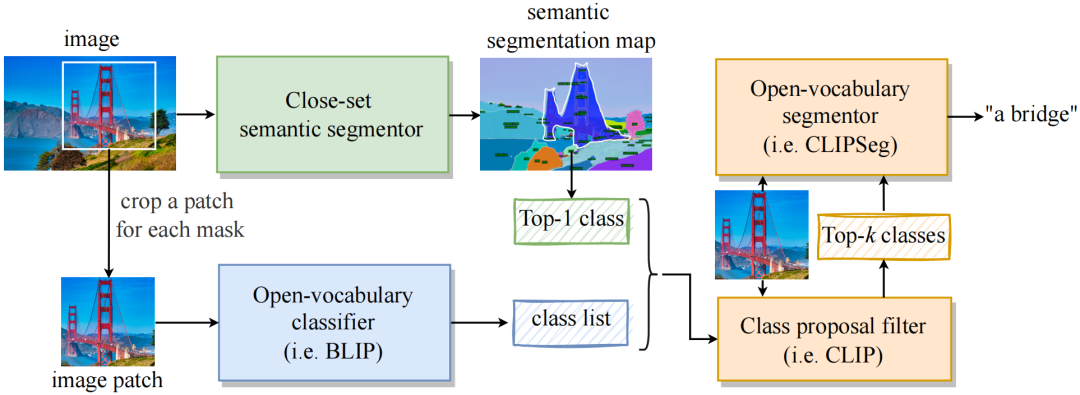
SSA-engine是一个自动化注释引擎,可以为SA-1B数据集或者任何一个数据集提供初始的语义标注。SSA-engine利用close-set分割模型来预测基础类别,并结合image caption模型来提供open-vocabulary的标注。得益于这样的设计,SSA-engine一方面可以为大多数样本提供令人满意的类别标注,另一方面,可以利用image caption方法提供更详细的语义类别标注。
SSA-engine填补了SA-1B缺乏的细粒度语义标注的空白,显著减少了人工类别标注需求。它有潜力成为训练大规模视觉感知模型和更细粒度CLIP模型的基础。
SSA-engine由三个组件组成:
1. Close-set语义分割器(绿色)。它是两个分别在COCO和ADE20K数据集上训练close-set语义分割模型,用于分割图像并获取粗略的类别信息。预测的类别仅包括简单、基本的类别,以确保每个mask都获得相关的标签。
2. Open-vocabulary分类器(蓝色)。利用image caption模型来描述与每个mask对应的图像区域。然后提取名词或短语作为候选的open-vocabulary类别。这个过程提供了更多样化的类别标签。
3. 最终决策模块(橙色)。SSA-engine使用一个类别过滤器(即CLIP)从l来自Close-set语义分割器和Open-vocabulary分类器的类别列表中,过滤出最合理的top-k个预测。最后,Open-vocabulary Segmentor(即CLIPSeg)根据top-k类别和图像区域预测最适合的类别。
实验
1. 推理时间
我们在单个NVIDIA A6000 GPU上测试了模型的推理速度,结果如下表所示:
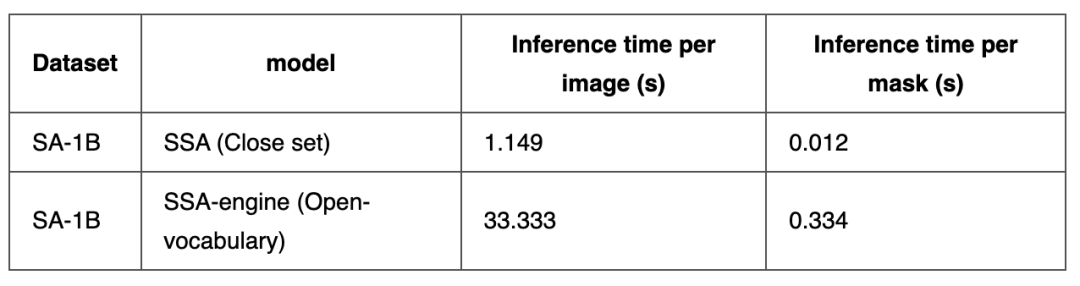
在被用于测试的200张图像中,平均每张图像包含了99.9个mask。
2. 显存开销

3. Close-set的语义分割结果
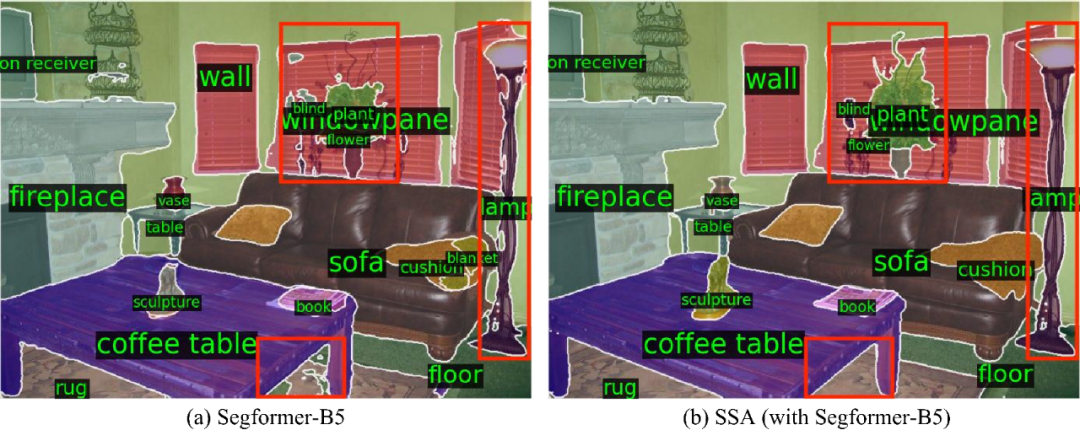
为了验证SSA架构的提升,我们选用了Huggiing face上的不同参数量和精度的Segformer模型(包括B0,B2和B5版本),作为一个mask预测没有那么准确的Seamntic branch。实验结果表明,在原本的语义分割模型(作为Semantic branch)的性能一般的情况下,SSA可以带来明显的准确度提升。

注意,本实验的Segformer的模型权重和代码均由NVIDIA公开,下载自Hugging face,而这些模型的mIoU略低于Github仓库中的实验结果。
4. Close-set的语义分割结果
我们验证了SSA在雾天语义分割数据集Foggy Driving上的性能。实验中,我们是用了OneFormer作为Semantic branch,其权重和代码来自于Hugging face。

实测效果
SSA的Close-set语义分割实测
1. Cityscapes

2. ADE20K
3. Foggy Driving

SSA-engine的Open-vocabulary标注实测





快速安装:
Semantic-Segment-Anything
conda env create -f environment.yaml
conda activate ssa
python -m spacy download en_core_web_sm# install segment-anythingcd ..
git clone git@github.com:facebookresearch/segment-anything.gitcd segment-anything;
pip install -e .; cd ../Semantic-Segment-Anything
1. SSA的快速上手
1.1 数据准备
● 下载 ADE20K 或者 Cityscapes dataset,并在 data 文件夹解压.
● 下载SAM 的权重并放在 ckp 下.
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pthcd ..
1.2 SSA模型推理
使用8卡GPU在ADE20K上推理SSA
python scripts/main_ssa.py --ckpt_path ./ckp/sam_vit_h_4b8939.pth --save_img --world_size 8 --dataset ade20k --data_dir data/ade20k/ADEChallengeData2016/images/validation/ --gt_path data/ade20k/ADEChallengeData2016/annotations/validation/ --out_dir output_ade20k_test
使用8卡GPU在Cityscapes上推理SSA
python scripts/main_ssa.py --ckpt_path ./ckp/sam_vit_h_4b8939.pth --save_img --world_size 8 --dataset cityscapes --data_dir data/cityscapes/leftImg8bit/val/ --gt_path data/cityscapes/gtFine/val/ --out_dir output_cityscapes
1.3 SSA验证
获取 ADE20K的验证结果
python evaluation.py --gt_path data/cityscapes/gtFine/val/ --result_path output_cityscapes/ --dataset cityscapes
获取 Cityscapes的验证结果
python evaluation.py --gt_path data/cityscapes/gtFine/val/ --result_path output_cityscapes/ --dataset cityscapes
2.SSA-engine的快速上手
● 下载SA-1B数据集并放在data路径下
● 运行SSA-engine对SA-1B进行自动类别标注
python scripts/main_ssa_engine.py --data_dir=data/examples --out_dir=output --world_size=8 --save_img
致谢
● Segment Anything 提供 SA-1B 数据集。
● HuggingFace 提供代码和预训练模型。
● CLIPSeg、OneFormer、BLIP 和 CLIP提供强大的语义分割、图像说明和分类模型。
引用
如果您觉得我们的工作对您有帮助,请引用我们的仓库:
@misc{chen2023semantic,
title = {Semantic Segment Anything},
author = {Chen, Jiaqi and Yang, Zeyu and Zhang, Li},
howpublished = {\url{https://github.com/fudan-zvg/Semantic-Segment-Anything}},
year = {2023}
}
数据集快速下载链接
COCO 2017
https://opendatalab.com/COCO_2017
ADE20K
https://opendatalab.com/ADE20K_2016
CityScapes
https://opendatalab.com/CityScapes
Foggy Driving
https://people.ee.ethz.ch/~csakarid/SFSU_synthetic/
SA-1B
https://opendatalab.com/SA-1B
-END-
更多公开数据集,欢迎访问OpenDataLab官网查看与下载:https://opendatalab.org.cn/