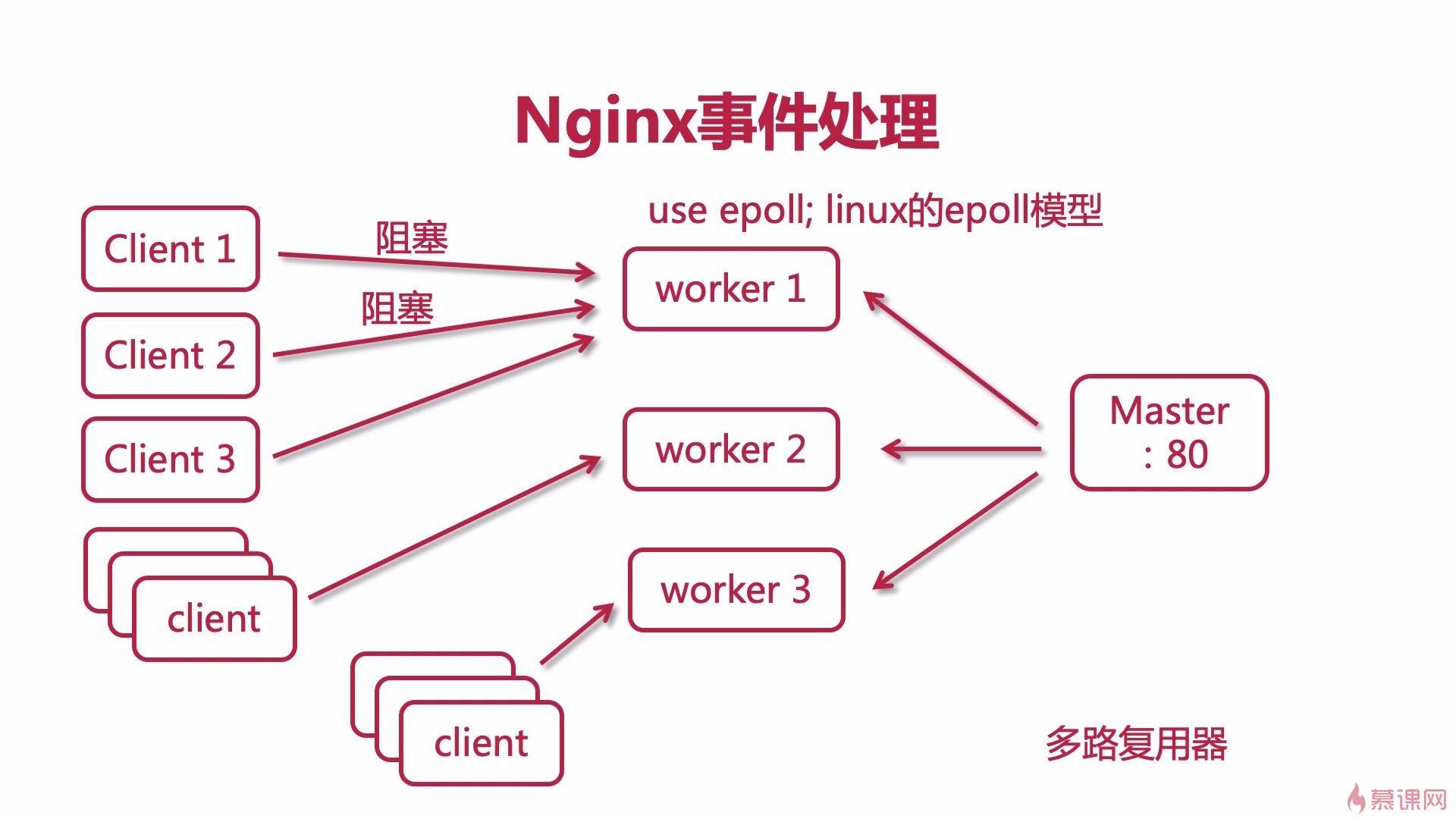
内部排序和外部排序

内部排序:整个的排序过程都在内存中进行排序
外部排序:对大文件进行排序,无法将整个需要排序的文件复制到内存,所以会把文件存储到外村,等排序时再把数据一部分一部分地调入内存进行排序,整个排序继续多次内存和外存的交换。
外部排序一般都采用归并排序!
当然归并排序可以作为内部排序和外部排序,这完全取决于使用场景。
多路归并的常见的使用场景BAT 经典算法笔试题 —— 磁盘多路归并排序 - 掘金
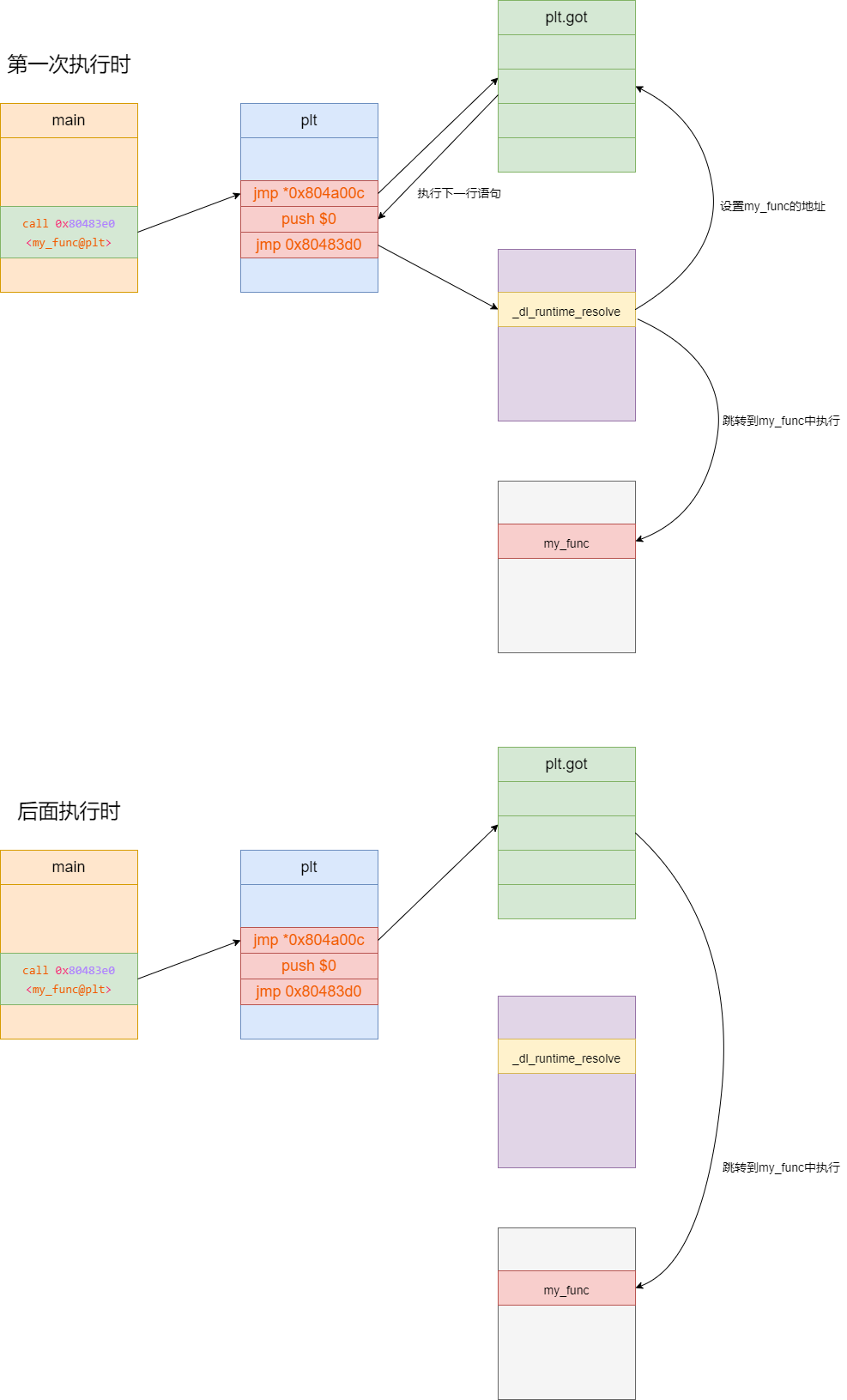
假定现在有一包含大量整数的文本文件存放于磁盘中,其文件大小为10GB,而本机内存只有4GB。此时若我们要对该文件中的所有整数进行升序排序,肯定不能直接将文件中的所有数据一次性读入内存中,再使用快速、归并等排序算法对这么大规模的整数进行排序。
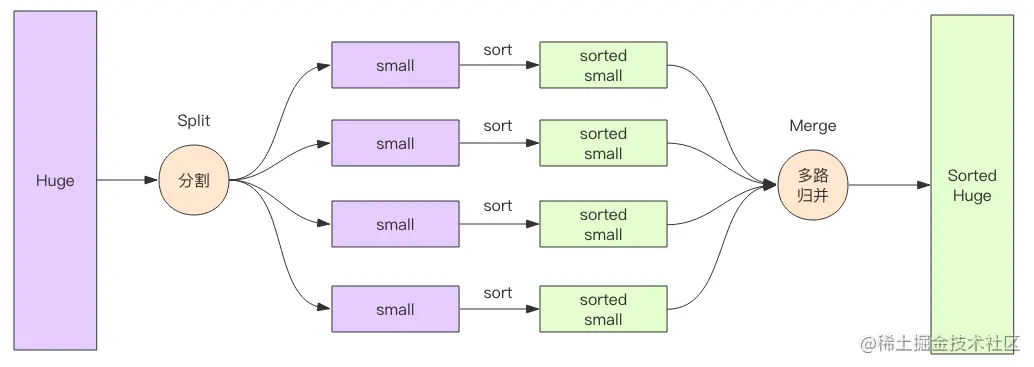
好像陷入了难题? 我们不妨换一个思路,为何不将10GB大文件拆分为10个1GB的小文件呢? 逐个对10个文件进行排序后,再将其写入磁盘中,此时就得到了10份已排序后的临时文件。
每一份文件都是一个升序序列,这时问题就转换为如何合并这10路升序序列为1路升序序列。正因为待合并的数据路数比较多,所以才有了多路归并这一说法。
————————————————
版权声明:本文为CSDN博主「留恋单行路」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/a574780196/article/details/122646309
简单来说就是:
多路归并排序在大数据领域也是常用的算法,常用于海量数据排序。当数据量特别大时,这些数据无法被单个机器内存容纳,它需要被切分位多个集合分别由不同的机器进行内存排序(map 过程),然后再进行多路归并算法将来自多个不同机器的数据进行排序(reduce 过程),这是流式多路归并排序
作者:老錢
链接:https://juejin.cn/post/6844903762621005837
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
二路归并参考力扣
void mergeSort(int[] nums, int l, int r) {
// 终止条件
if (l >= r) return;
// 递归划分
int m = (l + r) / 2;
mergeSort(nums, l, m);
mergeSort(nums, m + 1, r);
// 合并子数组
int[] tmp = new int[r - l + 1]; // 暂存需合并区间元素
for (int k = l; k <= r; k++)
tmp[k - l] = nums[k];
int i = 0, j = m - l + 1; // 两指针分别指向左/右子数组的首个元素
for (int k = l; k <= r; k++) { // 遍历合并左/右子数组
if (i == m - l + 1)
nums[k] = tmp[j++];
else if (j == r - l + 1 || tmp[i] <= tmp[j])
nums[k] = tmp[i++];
else {
nums[k] = tmp[j++];
}
}
}
// 调用
int[] nums = { 3, 4, 1, 5, 2, 1 };
mergeSort(nums, 0, len(nums) - 1);
作者:Krahets
链接:https://leetcode.cn/circle/article/zeM9YK/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。二路归并排序的思路


2路归并图
5路归并图
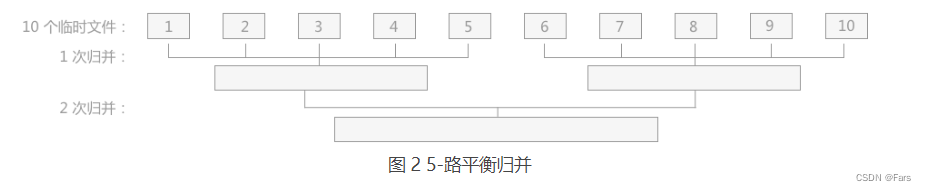
时间优化
外部排序的总时间=内部排序所需的时间+外存信息读写的时间+内部归并所需的时间
显然,外存信息读写的时间远大于内部排序和内部归并的时间,因此应适当减少I/O次数
可以适当,增大归并路数,可减少归并趟数,进而减少总的磁盘I/O次数
引入胜者树,败者树https://www.cnblogs.com/qianye/archive/2012/11/25/2787923.html
不能用普通的内部归并->引入败者树
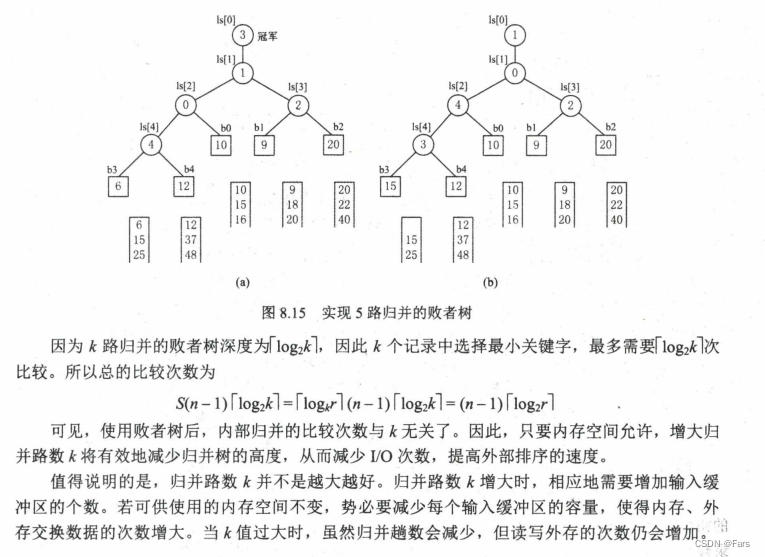
- 一般外部排序用的是败者树
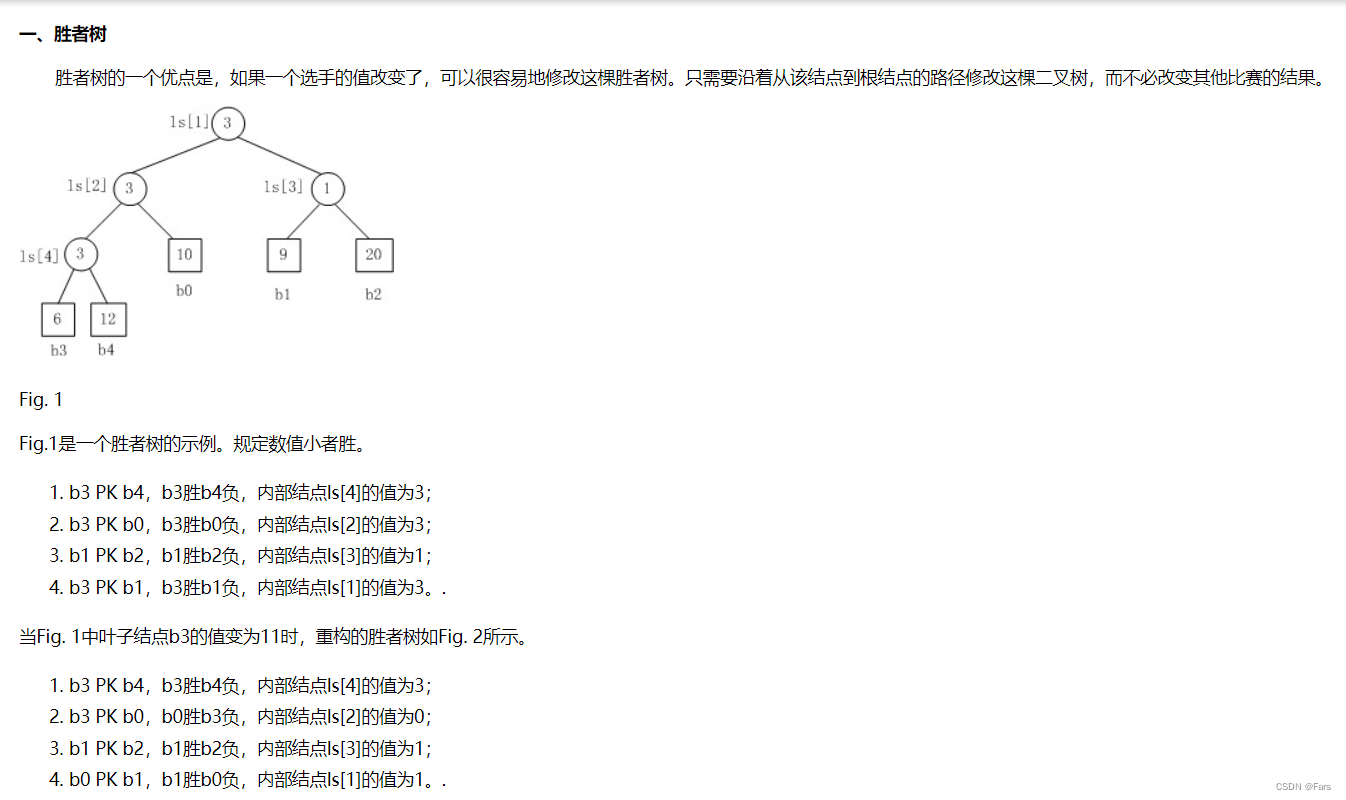
- 胜者树的优点:一个选手的值改变了,可以很方便的修改当前胜者树
- 败者树可以说是胜者树的一个变种,是胜者树的一种优化,当一个选手的值改变了,比败者树可以很方便的修改当前胜者树
- 历史上:外部排序先用的最小堆,然后优化变种成了胜者树,再优化变种成了败者树
理解胜者树和败者树的关键:
胜者树和败者树都是拿赢家去比下一轮,但是不同的是,胜者树的中间结点记录的是胜者的标号;而败者树的中间结点记录的败者的标号。(败者树虽然记录的是败者标号,但是也依然会把胜者传给下一轮去比)
胜者树图
败者树图