- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第P2周:彩色图片识别
- 🍖 原作者:K同学啊|接辅导、项目定制
目录
- 一、数据准备
- 二、构建简单CNN网络
- ⭐1. `torch.nn.Conv2d()`详解
- ⭐2. torch.nn.Linear()详解
- ⭐3. torch.nn.MaxPool2d()详解
- ⭐4. torch.nn.BatchNorm2d()详解
- ⭐5. 关于卷积层、池化层的计算:
- 6.构建稀疏卷积的CNN
- 三、总结
一、数据准备
torchvision.datasets详解 :http://t.csdn.cn/DCqMk
本次案例依然使用Pytorch自带的一个数据库torchvision.datasets,通过代码在线下载数据,这里使用的是torchvision.datasets中的CIFAR10数据集。
具体代码:
train_ds = torchvision.datasets.CIFAR10('data',
train=True,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
test_ds = torchvision.datasets.CIFAR10('data',
train=False,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
在这里简单展示一下部分彩色图片:

后面具体实现操作可参考:http://t.csdn.cn/DCqMk,这里直接进入构建网络部分。
二、构建简单CNN网络
⭐1. torch.nn.Conv2d()详解
函数原型如下:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
参数说明:
- in_channels:输入特征图的通道数;
- out_channels:输出特征图的通道数,即卷积核的个数;
- kernel_size:卷积核的大小,可以是int、tuple型变量。如kernel_size=3表示使用3x3的卷积核进行卷积;
- stride:卷积核的步长,可以是int、tuple型变量。如stride=2表示每隔1行/列卷积一次;
- padding:填充的长度,可以是int、tuple型变量。如padding=1表示在输入特征图的四周各加1圈0,以减小特征图尺寸;
- dilation:空洞卷积操作的空洞率(dilation rate),可以是int、tuple型变量;
- groups:组卷积的分组数量,默认为1,表示普通卷积操作;
- bias:是否添加偏置项,默认添加;
- padding_mode:填充模式,可取’zeros’或’circular’。
例子:
import torch
import torch.nn as nn
conv = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
input_data = torch.randn(1, 3, 32, 32) # 输入特征图大小为[1, 3, 32, 32]
output = conv(input_data) # 输出特征图大小为[1, 16, 32, 32]
以上代码定义了一个输入特征图通道数为3,输出特征图通道数为16,卷积核大小为3x3,步长为1,填充长度为1的卷积层。将随机生成的大小为[1, 3, 32, 32]的张量作为输入,经过一次卷积操作后得到输出特征图大小为[1, 16, 32, 32]的张量。
⭐2. torch.nn.Linear()详解
torch.nn.Linear()用于实现线性变换或全连接层。它将大小为in_features的输入张量映射到大小为out_features的输出张量,通过以下公式实现:
y = xA^T + b
函数原型:
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数说明:
- in_features:每个输入样本的大小
- out_features:每个输出样本的大小
其中,x是输入张量,A是权重矩阵,b是偏置向量,y是输出张量。
使用torch.nn.Linear()可以方便地定义神经网络模型中的全连接层,并自动管理权重和偏置等参数。例如:
import torch
import torch.nn as nn
# 定义一个输入维度为3,输出维度为4的全连接层
linear_layer = nn.Linear(3, 4)
# 随机生成一个大小为(2, 3)的输入张量
input_tensor = torch.randn(2, 3)
# 将输入张量传入全连接层进行前向计算
output_tensor = linear_layer(input_tensor)
# 查看输出张量的形状
print(output_tensor.shape)
上述代码定义了一个输入维度为3,输出维度为4的全连接层,并随机生成了一个大小为(2,3)的输入张量进行前向计算。输出张量的形状应该为(2, 4)。
除了输入维度和输出维度之外,torch.nn.Linear()还可以设置其他参数,如是否包括偏置项、权重初始化方法等。这些参数可以通过传递关键字参数进行设置。
⭐3. torch.nn.MaxPool2d()详解
torch.nn.MaxPool2d() 用于进行 2D 最大池化操作的函数。它可以将输入的二维数据张量按照指定大小进行划分,并在每个子区域中取最大值,从而得到一个更小的输出张量。
函数原型:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
以下是 torch.nn.MaxPool2d() 的常用参数:
kernel_size:池化窗口的大小,可以是一个整数(表示正方形)或一个元组(表示长方形)。如果设置为 ( k , k ) (k,k) (k,k) 或者 k k k,则表示使用 k × k k\times k k×k 的池化窗口。stride:池化窗口的步幅,可以是一个整数(表示横向和纵向相同的步幅),也可以是一个元组(表示横向和纵向不同的步幅)。padding:填充的大小,可以是一个整数(表示正方形)或一个元组(表示长方形),与卷积的 padding 参数类似。dilation:卷积核的扩张率,即卷积核中各个元素之间的间隔距离。return_indices:是否返回最大值的索引。ceil_mode:当 stride 不被整除时,是否向上取整,可以避免出现边界像素没有参与池化的情况。
具体用法如下:
import torch.nn as nn
maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
input = torch.randn(1, 3, 64, 64)
output = maxpool(input)
上面的代码中,我们创建了一个 3x3 的池化窗口,步幅为 2,填充大小为 1 的最大池化层,并将其应用于一个输入张量。最后得到的输出张量形状会因为池化操作而变小。
⭐4. torch.nn.BatchNorm2d()详解
torch.nn.BatchNorm2d()用于批量标准化(Batch Normalization)操作。它可以对输入数据进行标准化,并将其缩放和移位以使其均值为0,方差为1。该层通常用于神经网络中,可使训练更稳定且加快收敛速度。
该层的输入是形状为 (batch_size, num_channels, height, width) 的4D张量,其中 batch_size 表示批次大小,num_channels 表示通道数,height 和 width 分别表示输入数据的高度和宽度。
参数说明:
- num_features (int):输入特征的数量(即
num_channels)。 - eps (float, optional):防止除以0的小数,默认为1e-5。
- momentum (float, optional):用于计算统计信息的动量,应在0到1之间,默认为0.1。
- affine (bool, optional):是否使用可学习的仿射变换,默认为True。
- track_running_stats (bool, optional):是否计算并跟踪运行时统计数据,默认为True。
首先通过 nn.Conv2d 进行卷积操作,然后传递给 nn.BatchNorm2d 层进行标准化操作,接着再使用ReLU激活函数进行非线性变换。最后,将做过标准化和非线性变换的输出传递到全连接层,以生成最终的预测结果。
⭐5. 关于卷积层、池化层的计算:
下面的网络数据shape变化过程为:
3, 32, 32(输入数据)
-> 64, 30, 30(经过卷积层1)-> 64, 15, 15(经过池化层1)
-> 64, 13, 13(经过卷积层2)-> 64, 6, 6(经过池化层2)
-> 128, 4, 4(经过卷积层3) -> 128, 2, 2(经过池化层3)
-> 512 -> 256 -> num_classes(10)
(注:此处计算过程只是作为例子参考)
6.构建稀疏卷积的CNN
定义一个基于稀疏卷积神经网络的分类器,包括了三个主要的组成部分:卷积层、批量归一化层以及全连接层。
首先,在初始化函数(__init__)中,我们定义了卷积层conv1,使用的卷积核大小为3x3,有16个输出通道。然后,我们加入了一个批量归一化层bn1,其输入通道数为16。接下来,我们定义了一个稀疏卷积层sparse_conv,其输入通道数为16,输出通道数为32,且不使用padding。最后,我们添加了另一个批量归一化层bn2,其输入通道数为32,用于归一化稀疏卷积层的输出。最终,我们加入了一个全连接层fc1,将32个特征图转换为10个类别的概率值。
在前向传递函数(forward)中,我们首先对输入数据x应用第一层卷积操作,然后使用ReLU激活函数和批量归一化对其进行处理。接着,我们将输出结果再次通过稀疏卷积层、批量归一化层及ReLU激活函数处理。之后,我们使用平均池化层将特征图压缩成一个1x1的向量,以便我们可以将其送入一个全连接层进行分类。在最后一步中,我们应用softmax激活函数,并返回对数值作为输出结果,这个输出结果包含每个类别出现的概率。
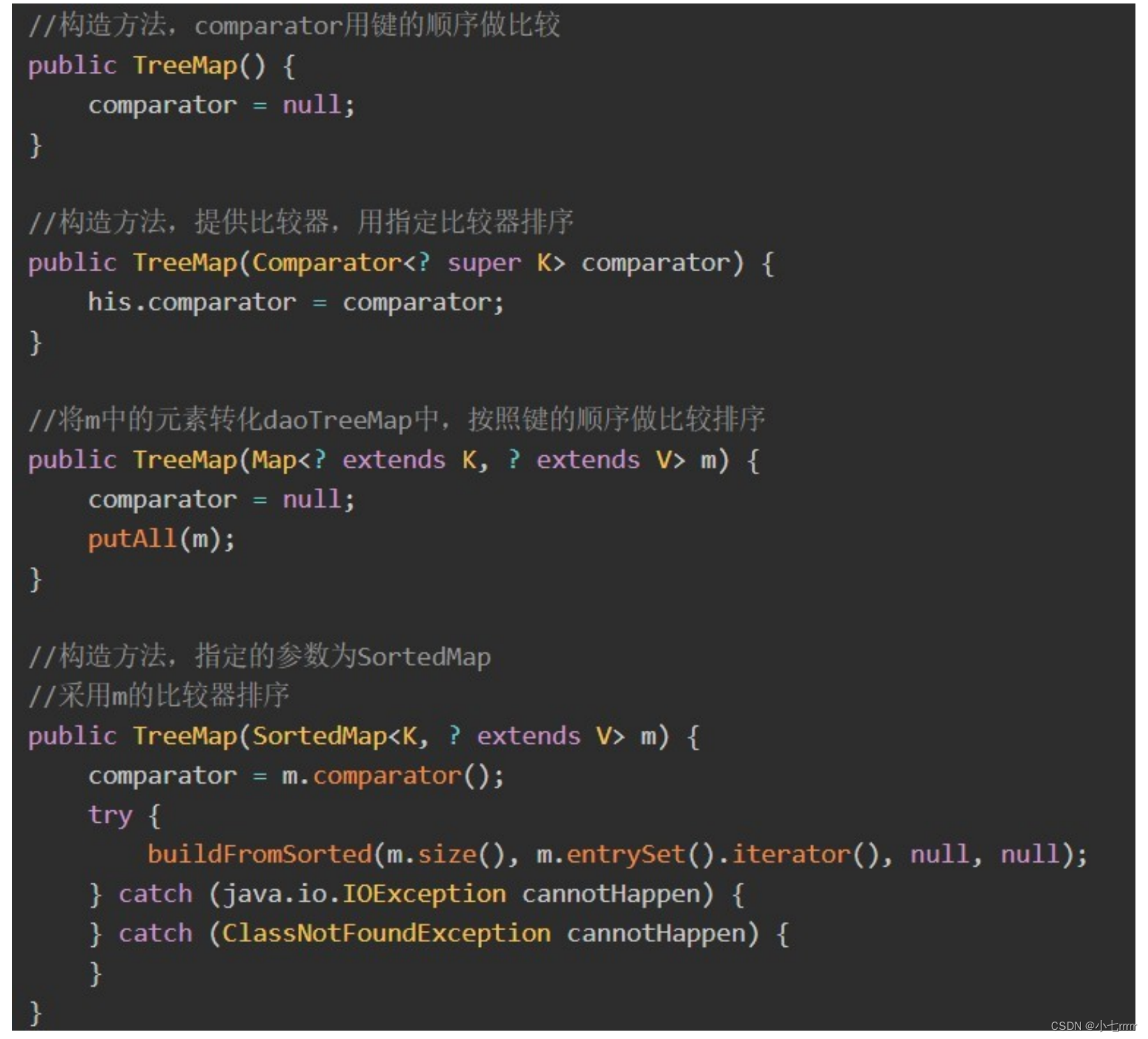
class SparseConvNet(nn.Module):
def __init__(self):
super(SparseConvNet, self).__init__()
# 第一层卷积
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16) # 批量归一化层
# 稀疏卷积层
self.sparse_conv = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(32) # 批量归一化层
# 全连接层
self.fc1 = nn.Linear(32, 10)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x))) # 第一层卷积 + 批量归一化 + 激活函数(ReLU)
x = F.relu(self.bn2(self.sparse_conv(x))) # 稀疏卷积层 + 批量归一化 + 激活函数(ReLU)
x = F.avg_pool2d(x, kernel_size=x.size()[2:]) # 平均池化层
x = x.view(-1, 32) # 将特征图拉成向量
x = self.fc1(x) # 全连接层
return F.log_softmax(x, dim=1) # 输出层应用softmax激活函数,并返回对数值
网络结构展示:

训练模型与结果可视化在上一篇PyTorch实战1:实现mnist手写数字识别已有详细的赘述
在此就直接摆出本文案例的运行结果图:


三、总结
本文实战并没有使用深度学习训练营中的网络结构进行模型训练,而是自己设计了一个较为简单的、易于理解的网络结构,发现亲手设计从0到1的网络会遇到一些问题,比如每个层的参数该如何设置,卷积层、池化层如何计算,使用多少个卷积层、池化层、全连接层,尝试不用正规卷积而改用稀疏卷积如何去实现等等。
本次实战运用自己设计的网络结构开始训练模型,最终结果证明效果一般般,毕竟这是第一次且刚入门的小案例,后续熟练了再试着去调参优化,将模型的精度提高至80,甚至90。