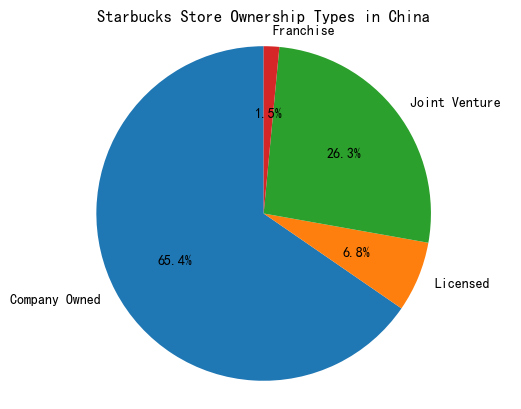
介绍
投资组合管理是量化交易的一个长期组成部分,其目标是通过在某些金融产品中不断重新分配资金来满足预定义的效用函数。投资组合管理的方法有以下三种类型之一:1) 传统方法(例如动量[1]和反向策略[2]),2) 机器学习方法(例如模式匹配[3]),以及 3)基于强化学习 (RL) 的方法[4]、[5]。随着深度神经网络的蓬勃发展,许多研究人员将深度学习与 RL 相结合,在多个金融领域取得了令人瞩目的成绩,例如外汇交易[6]、投资组合管理[4] , [5] , [7] , [8]和做市[9]。
大多数成功的 RL 研究都使用逼真的物理引擎或动态交互实体来构建训练环境。例如,AlphaZero [10]训练代理人通过自我对弈来玩棋盘游戏。在这里,self-play 意味着代理所面对的环境,即玩家代理对抗的环境,是由神经网络训练的最佳玩家(代理)从所有先前的迭代中生成的。训练代理获得持续的反馈以响应其自身的行为,从而在训练环境和代理之间形成稳健且合理的相互关系。然而,基于 RL 的投资组合管理的研究不太成功。在此类研究中,历史价格数据仍然直接用于构建培训环境[4], [5] , [7] , [8]. 从代理人的角度来看,来自此类培训环境的反馈对代理人的行为没有反应。因此,代理在针对这种无响应的训练环境优化其动作时面临几个问题。首先,从环境中获得的状态与代理的行为无关。代理与这种无响应环境的交互可能违反了马尔可夫决策过程 (MDP) 的定义——其中 MDP 定理明确地将状态转换定义为取决于当前状态和操作的状态转换。由于 MDP 定理是 RL 的基本定理,违反 MDP 的定义会导致基于 RL 的投资组合代理的优化过程不合理。第二,这种反应迟钝意味着环境无法对代理人的行为做出适当的市场反应。换句话说,基于历史价格数据构建的环境无法模拟代理人对市场的影响。因此,使用历史价格数据优化的代理可能会产生较差的泛化:从样本内(训练)数据构建的交易知识无法应用于样本外(测试)。无论模型与训练数据的拟合程度如何,泛化能力差的模型对于解决实际决策问题毫无用处。因此,泛化性可以被认为是构建基于 RL 的投资组合管理模型必须克服的最大障碍。[9]、[11]通过向环境中注入随机化来提高基于 RL 的交易代理的泛化能力。然而,这些研究大多使用历史价格数据来构建环境;随机噪声的注入并不能直接解决上述问题。
我们认为,可以使用两种解决方案来解决上述问题。第一个是将基于 RL 的投资组合代理与真实证券交易所数据进行交互以优化投资组合。第二种是使用另一个 AI 模型为 RL 智能体构建一个真实的虚拟市场进行交互。第一个解决方案基于真实金融市场中交易结果的奖励。然而,由于此解决方案成本高昂,并且需要相对较长的数据收集时间才能使代理收敛,因此无法实际应用于基于 RL 的投资组合优化。第二种方法是我们的主要贡献所在。在我们的研究中,提出了一种生成对抗网络 (GAN) 的变体,通过对历史限价订单的分布进行建模来模拟市场订单行为。然后使用生成模型构建合成证券交易所作为代理的训练环境。所提出的学习框架使代理能够获得模拟市场对其交易决策的反应。通过这样做,状态和行动之间的因果关系得到加强。此外,由于允许代理参与状态转换过程,因此模拟证券交易所可以防止代理违反 MDP 的定义;通过确保支撑 RL 框架的基本定理成立,这使得 RL 在投资组合优化中的使用变得合理。通过与模拟证券交易所互动,代理人能够探索更大范围的以前无法预见的市场情况;训练数据集也更加多样化。据我们所知,这是第一项使用生成模型在基于 RL 的投资组合管理模拟中重建金融市场的研究,目的是提高代理的泛化能力。本研究的主要贡献如下:
-
一种被称为限价订单簿 (LOB)-GAN 的生成模型对历史限价订单下的分布进行建模。LOB-GAN用于模拟市场整体投资者的下单行为。
-
引入限价订单转换模块,让 LOB-GAN 合成相对订单数量,而不是直接预测订单价格和相应数量。
-
通过让 LOB-GAN 中的生成器与安全匹配系统合作,构建了一个称为虚拟市场的综合证券交易所。虚拟市场可以根据代理人的交易决策呈现模拟的市场反应。
-
提出了一种利用虚拟市场的新型基于 RL 的投资组合优化学习框架。该框架通过在动作和过渡状态之间建立更紧密的相互关系,确保永远不会违反 MDP 的定义。
本文的其余部分组织如下:第二部分回顾文献;第三部分陈述假设并定义问题;第四节介绍了提出的市场行为模拟器、虚拟市场的构建以及其他泛化策略;第五节介绍了提出的基于 RL 的投资组合优化框架;第六节介绍了实验结果;第七节总结了论文并讨论了未来的研究方向。
文献综述
本节回顾了三个文献体系:关于在金融中利用 RL、RL 泛化技术和人工市场模拟。
A. 金融强化学习
RL 已广泛应用于金融的多个领域,例如做市和外汇交易,在投资组合管理中尤为重要。在本节中,我们重点回顾有关基于 RL 的投资组合管理的文献。根据经验,投资组合管理可分为三个主要步骤:投资组合选择、加权和再平衡。在组合选择中,重点是选择组合资产;在投资组合加权中,过程决定资本分配;并且,在投资组合再平衡中,决定是否以及何时改变投资组合权重。斯布鲁齐等人。 [12]关注投资组合选择并使用 RL 框架,其中资产池选择代理优化选择策略。王等。 [4]通过使用他们提出的 AlphaStock 方法,桥接了投资组合选择和加权的过程。具体来说,作者在 AlphaStock 中制定了专门的跨资产注意力网络 (CAAN) 机制,以捕捉投资组合资产之间的相互关系。姜等。 [7]专注于投资组合权重,并提出了他们的相同独立评估器集成 (EIIE) 拓扑结构。他们的投资组合选择策略直接以交易量为基础,在他们的学习框架中考虑了交易成本(算法交易策略执行中的一个关键问题)。作者使用他们的 EIIE 拓扑检查了几个时间序列特征提取模型。施等。 [5]在他们的相同独立初始 (EIII) 拓扑集成中扩展了 EIIE 拓扑,该拓扑利用初始网络同时考虑不同规模的价格变动。他们的实验结果表明,EIII 拓扑比原始 EIIE 产生更好的投资组合性能。叶等。 [8]还在其状态增强 RL (SARL) 拓扑中扩展了 EIIE 拓扑,其中将合作引入异构数据集以帮助代理做出更好的预测。唐等。 [13]还强调结合多个来源,其中传统指标和预训练 GAN 的模块各自构成不同的数据流。李等。 [14]应用了一种新颖的 RL 算法,该算法利用堆叠式去噪自动编码器 (SDAE) 构建代理,目的是获得稳健的状态表示。尽管取得了这些进步,基于 RL 的投资组合优化的研究大多使用历史数据来优化代理,这可能导致代理的泛化能力较差。
B. 强化学习中的泛化
RL 中的泛化问题已在各个领域进行了研究。怀特森等人。 [15]将泛化问题分为任务内和任务外变体。在任务内变体中,如果在训练轨迹上优化的代理在同一环境的测试轨迹上表现良好,则泛化能力令人满意。在任务外变体中,当代理在不同于训练环境的环境中表现良好时,泛化能力令人满意。用于解决 RL 泛化问题的方法可分为五类。
-
正则化方法:应用了多种技术,例如 dropout 和 L2 正则化,以防止代理在有限的状态空间中过度拟合[16]。Igl等人。 [17]提出了选择性噪声注入(SNI),它保留了正则化效果,但减轻了对梯度的副作用,以提高对 RL 的适应性。
-
对抗训练: Different settings of the perturbation generation strategy are introduced in RL-based trading [9], [11]. The injected noise can 1) help the agent to learn how to furnish a robust representation and 2) diversify the training environment.
-
数据增强:为了使数据更加多样化,对状态[18]、[19]应用了转换。
-
迁移学习:通过专注于帮助代理泛化到新任务,它被广泛用于领域适应[20]。Gamrian 和 Goldberg [21]进一步利用 GAN 将视觉观察从目标域映射到源域。
-
元学习:代理学习元策略,帮助它快速适应其他领域[22]。王等。 [23]也关注让代理快速适应新任务的问题;他们通过扩展循环网络来支持 RL 中的元学习来实现这一点。
C. 人工市场模拟
长期以来,研究人员一直试图模拟投资者的行为。开创性的研究集中在有效市场假说 (EMH) [24]的潜力上,该假说认为人们总是有足够的理性来做出最佳决策。然而,其他研究人员发现,人们确实会做出不合理的决定,例如在羊群效应下[25]。因此提出了行为经济学来模拟这种非理性。最近的研究集中在行为预测上。根据 Lovric等人的说法。 [26],投资决策可以建模为投资者与环境相互作用的结果。研究还提出了几个影响投资过程的相互依赖的变量,例如时间偏好、风险态度和性格。此外,在 Shantha等人 提出的框架中。[27],投资者从他们的交易经验中学习(个体学习)或通过模仿他人(社会学习)。
人工市场模拟使研究人员能够构建无法在历史数据中捕获的情况。因此,此类模拟被广泛用于分析金融中的各种问题,例如卖空规定[28]、交易税[29]和订单匹配系统的速度[30]。基于代理的模拟结合了多个代理来再现真实市场中的程式化事实,是人工市场模拟中最常见的技术。模拟过程包括几个部分。首先,定义了相关主体的智力水平、效用函数和学习能力[31]。二、资产价格确定[32]. 三是申报人工市场建设涉及的交易资产种类和数量[33]。第四,确定与智能体智能水平高度相关的学习过程[34],[35]。第五,最后,对模拟市场进行校准和验证。具体来说,校准是选择使模拟市场表现最接近真实市场的参数,而验证则涉及模拟市场的表现是否与真实市场一样。除了使用基于代理的模型构建模拟市场外,Li等人。 [36]提出 Stock-GAN 以高保真度生成限价订单数据,以支持连续交易系统中的市场设计和分析。在这项研究中,我们利用生成模型来构建金融市场。我们不仅重构了一个具有现实定价机制的金融市场,还将模拟市场与RL交易代理相结合。通过将市场模拟与基于 RL 的投资组合优化框架相结合,我们克服了上述使用历史价格数据进行代理优化的缺点。
预赛
本节陈述假设,讨论本研究的局限性,并阐述在投资组合管理中应用 RL 的问题。
A. 假设
我们提出了一个生成模型来模拟市场对代理人行为的反应。因此必须做出以下假设:
-
由于模拟金融市场负责对代理人的行为产生合理的反应,因此假定代理人有能力影响市场上其他投资者的行为。
-
投资者的订货行为充分反映了外生变量对金融市场的影响。因此,我们在综合合理的市场反应时,只对市场排序行为进行建模。
B. 问题定义
投资组合管理是一个决策过程,其中资金不断地重新分配到不同的资产。投资组合策略制定的过程可以表述为 MDP。MDP 表示为一个元组<小号,一个,磷, , ,p0, c> , 在哪里小号 是状态空间,A 行动空间,P 状态转移函数,R 奖励函数,p0 初始状态的概率分布,以及C∈ [ 0 , 1 ) 奖励折扣系数。在投资组合管理的情况下,代理旨在找到最优策略π(一个|s ) , 其中动作一个∈一个 关于状态是最优的小号∈小号 . 在这个最优策略中,期望回报最大化:
1)环境
环境的设计包括以下要素: (1) 状态秒吨∈小号 ,其中包含代理的交易状态或环境提供的价格序列的周期;(2) 状态转移P( ··· _秒吨,A吨) ,呈现下一个状态秒吨+ 1 给定先前的状态和动作;(3) 奖励函数R (秒吨,A吨) ,这是定义代理的投资组合绩效的效用函数,并作为代理最大化的目标函数。