4.4 使用分组聚合进行组内计算
- 4.4.1 使用groupby方法拆分数据
- groupby方法的参数及其说明:
- groupby对象常用的描述性统计方法如下:
- 4.4.2 使用agg方法聚合数据
- agg函数和aggregate函数的参数说明
- 1、使用agg求出当前数据对应的统计量
- 2、使用agg分别求字段的不同统计量
- 3、使用agg方法求不同字段的不同数目统计量
- 4、在agg方法中使用自定义函数
- 5、agg方法中使用的自定义函数含Numpy中的函数
- 6、使用agg方法做简单的聚合
- 7、使用agg方法对分组数据使用不同的聚合函数
- 4.4.3使用apply方法聚合数据
- apply方法的常用参数及其说明
- 4.4.4 使用transform方法聚合数据
- 4.4.5 任务实现
- 数据
- 完整代码
4.4.1 使用groupby方法拆分数据
该方法提供的是分组聚合步骤中的拆分功能,能根据索引或字段对数据进行分组
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
groupby方法的参数及其说明:

by参数的特别说明
如果传入的是一个函数则对索引进行计算并分组。
如果传入的是一个字典或者Series则字典或者Series的值用来做分组依据。
如果传入一个NumPy数组则数据的元素作为分组依据。
如果传入的是字符串或者字符串列表则使用这些字符串所代表的字段作为分组依据。
# 4.4 使用分组聚合进行组内计算
## 4.4.1使用groupby方法拆分数据
import pandas as pd
import numpy as np
data = pd.read_csv('E:/Input/ptest.csv')
# print(data.head(3))
datagroup = data[['id', 'counts', 'amounts']].groupby(by='id')
print(datagroup) # 分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000020717BF0DF0>

用groupby方法分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。实际上分组后的数据对象GroupBy类似Series与DataFrame,是pandas提供的一种对象。
groupby对象常用的描述性统计方法如下:
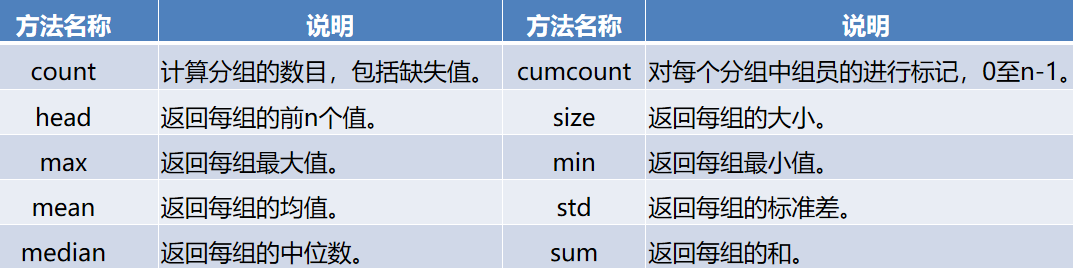
# 可以查看groupby对象常用的描述性统计方法
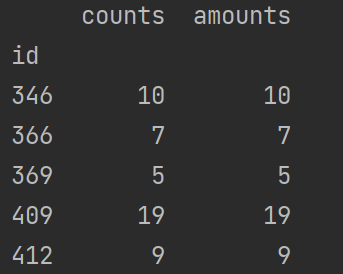
print(datagroup.count()) # 分组的数目,包括缺失值
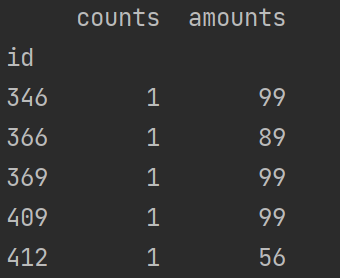
print(datagroup.max()) # 每组最大值
print(datagroup.min()) # 每组最小值
4.4.2 使用agg方法聚合数据
agg,aggregate方法都支持对每个分组应用某函数,包括Python内置函数或自定义函数。同时这两个方法能够也能够直接对DataFrame进行函数应用操作。
DataFrame.agg(func, axis=0, *args, **kwargs)
DataFrame.aggregate(func, axis=0, *args, **kwargs)
agg函数和aggregate函数的参数说明

在正常使用过程中,agg函数和aggregate函数对DataFrame对象操作时功能几乎完全相同,因此只需要掌握其中一个函数即可。
1、使用agg求出当前数据对应的统计量
可以使用agg方法一次求出当前数据中所有菜品销量和售价的总和与均值,如detail[[‘counts’,‘amounts’]].agg([np.sum,np.mean]))。
## 使用agg方法一次求出所有销量和售价的总和与均值
print(data[['counts', 'amounts']].agg([np.sum, np.mean]))
2、使用agg分别求字段的不同统计量
对于某个字段希望只做求均值操作,而对另一个字段则希望只做求和操作,可以使用字典的方式,将两个字段名分别作为key,然后将NumPy库的求和与求均值的函数分别作为value,如detail.agg({‘counts’:np.sum,‘amounts’:np.mean}))。
## 对counts求和,对amounts求均值
print(data.agg({'counts': np.sum, 'amounts': np.mean}))
3、使用agg方法求不同字段的不同数目统计量
在某些时候还希望求出某个字段的多个统计量,某些字段则只需要求一个统计量,此时只需要将字典对应key的value变为列表,列表元素为多个目标的统计量即可,如detail.agg({‘counts’:np.sum,‘amounts’:[np.mean,np.sum]}))
## 求counts的总和,求amounts的均值和总和
print(data.agg({'counts': np.sum, 'amounts': [np.mean, np.sum]}))
4、在agg方法中使用自定义函数
在agg方法可传入自定义的函数。
## 自定义函数求两倍的和
def DoubleSum(data):
s = data.sum() * 2
return s
print(data.agg({'counts': DoubleSum}, axis = 0))
5、agg方法中使用的自定义函数含Numpy中的函数
使用自定义函数需要注意的是NumPy库中的函数np.mean,np.median,np.prod,np.sum,np.std,np.var能够在agg中直接使用,但是在自定义函数中使用NumPy库中的这些函数,如果计算的时候是单个序列则会无法得出想要的结果,如果是多列数据同时计算则不会出现这种问题。
## 自定义函数求两倍的和
def DoubleSum2(data):
s = sum(data) * 2
return s
print(data.agg({'counts': DoubleSum2}, axis = 0))
print(data[['counts', 'amounts']].agg(DoubleSum2)) #销量与售价的和的两倍
6、使用agg方法做简单的聚合
使用agg方法能够实现对每一个字段每一组使用相同的函数。
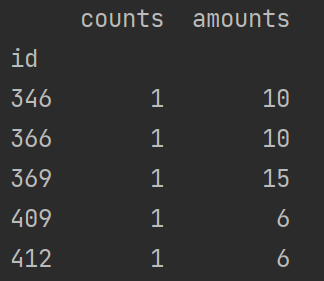
print('均值:', datagroup.agg(np.mean))
print('标准差:', datagroup.agg(np.std))
7、使用agg方法对分组数据使用不同的聚合函数
如果需要对不同的字段应用不同的函数,则可以和Dataframe中使用agg方法相同。
print(datagroup.agg({'counts':np.sum, 'amounts':np.mean}))
4.4.3使用apply方法聚合数据
apply方法类似agg方法能够将函数应用于每一列。不同之处在于apply方法相比agg方法传入的函数只能够作用于整个DataFrame或者Series,而无法像agg一样能够对不同字段,应用不同函数获取不同结果。
使用apply方法对GroupBy对象进行聚合操作其方法和agg方法也相同,只是使用agg方法能够实现对不同的字段进行应用不同的函数,而apply则不行。
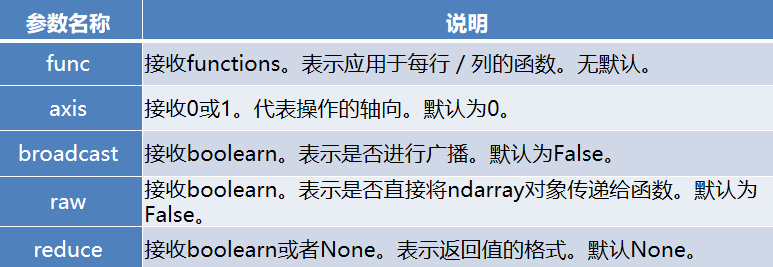
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
apply方法的常用参数及其说明
# 4.4.3使用apply方法聚合数据
### 1、apply方法的基本用法
## counts和amounts的均值
print(data[['counts', 'amounts']].apply(np.mean))
### 2、使用apply方法进行聚合操作
## 订单每组的均值
print(datagroup.apply(np.mean))
## 订单每组的标准差
print(datagroup.apply(np.std))
4.4.4 使用transform方法聚合数据
transform方法能够对整个DataFrame的所有元素进行操作。且transform方法只有一个参数“func”,表示对DataFrame操作的函数。
同时transform方法还能够对DataFrame分组后的对象GroupBy进行操作,可以实现组内离差标准化等操作。
若在计算离差标准化的时候结果中有NaN,这是由于根据离差标准化公式,最大值和最小值相同的情况下分母是0。而分母为0的数在Python中表示为NaN。
# 4.4.4 使用transform方法聚合数据
### 1、使用transform方法将销量和售价翻倍
print(data[['counts', 'amounts']].transform(lambda x: x*2))
### 2、使用transform实现组内离差标准化
print(datagroup.transform(lambda x: (x.mean()-x.min())/(x.max()-x.min())))
4.4.5 任务实现
# 4.4.5 任务实现
### 1、按照时间对菜单详情表进行拆分
detail = pd.read_csv('E:/Input/ptest.csv')
# 订单详情表按照日期分组
detail['time'] = pd.to_datetime(detail['time']) # 转换成日期格式
detail['date'] = [i.date() for i in detail['time']] # 提取日,增加一列date
# detail.to_csv('E:/Output/detail.csv', index=False) # 输出
detailgroup = detail[['date', 'counts', 'amounts']].groupby(by='date')
print(detailgroup.size())
### 2、使用agg方法计算单日菜品销售的平均单价和售价中位数
print(detailgroup[['amounts']].agg([np.mean, np.median])) # 合在一起
print(detailgroup.agg({'amounts': np.mean})) # 分开
print(detailgroup.agg({'amounts': np.median}))
print("-----+++++++++++-----")
### 3、使用apply方法统计单日菜品销售的数目
print(detailgroup['counts'].apply(np.sum))
数据
链接:https://pan.baidu.com/s/1FPQFA8JJHuezxbpQIHiZ4Q
提取码:6666
完整代码
# 4.4 使用分组聚合进行组内计算
## 4.4.1使用groupby方法拆分数据
import pandas as pd
import numpy as np
data = pd.read_csv('E:/Input/ptest.csv')
# print(data.head(3))
datagroup = data[['id', 'counts', 'amounts']].groupby(by='id')
print(datagroup) # 分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。
#<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000020717BF0DF0>
# 可以查看groupby对象常用的描述性统计方法
print(datagroup.count()) # 分组的数目,包括缺失值
print(datagroup.max()) # 每组最大值
print(datagroup.min()) # 每组最小值
print(datagroup.std()) # 每组标准差
print(datagroup.size()) # 每组的大小
print('-----------------')
# 4.4.2 使用agg方法聚合数据
### 1、使用agg求出当前数据对应的统计量
## 使用agg方法一次求出所有销量和售价的总和与均值
print(data[['counts', 'amounts']].agg([np.sum, np.mean]))
### 2、使用agg分别求字段的不同统计量
## 对counts求和,对amounts求均值
print(data.agg({'counts': np.sum, 'amounts': np.mean}))
### 3、使用agg方法求不同字段的不同数目统计量
## 求counts的总和,求amounts的均值和总和
print(data.agg({'counts': np.sum, 'amounts': [np.mean, np.sum]}))
### 4、在agg方法中使用自定义函数
## 自定义函数求两倍的和
def DoubleSum(data):
s = data.sum() * 2
return s
print(data.agg({'counts': DoubleSum}, axis = 0))
### 5、agg方法中使用的自定义函数含Numpy中的函数
## 自定义函数求两倍的和
def DoubleSum2(data):
s = sum(data) * 2
return s
print(data.agg({'counts': DoubleSum2}, axis = 0))
print(data[['counts', 'amounts']].agg(DoubleSum2)) #销量与售价的和的两倍
### 6、使用agg方法做简单的聚合
print('均值:', datagroup.agg(np.mean))
print('标准差:', datagroup.agg(np.std))
### 7、使用agg方法对分组数据使用不同的聚合函数
print(datagroup.agg({'counts':np.sum, 'amounts':np.mean}))
# 4.4.3使用apply方法聚合数据
### 1、apply方法的基本用法
print(data[['counts', 'amounts']].apply(np.mean)) ## counts和amounts的均值
### 2、使用apply方法进行聚合操作
# print(datagroup.apply(np.mean)) ## 订单每组的均值
print(datagroup.apply(np.std)) ## 订单每组的标准差
# 4.4.4 使用transform方法聚合数据
### 1、使用transform方法将销量和售价翻倍
print(data[['counts', 'amounts']].transform(lambda x: x*2))
### 2、使用transform实现组内离差标准化
print(datagroup.transform(lambda x: (x.mean()-x.min())/(x.max()-x.min())))
# 4.4.5 任务实现
### 1、按照时间对菜单详情表进行拆分
detail = pd.read_csv('E:/Input/ptest.csv')
# 订单详情表按照日期分组
detail['time'] = pd.to_datetime(detail['time']) # 转换成日期格式
detail['date'] = [i.date() for i in detail['time']] # 提取日,增加一列date
# detail.to_csv('E:/Output/detail.csv', index=False) # 输出
detailgroup = detail[['date', 'counts', 'amounts']].groupby(by='date')
print(detailgroup.size())
### 2、使用agg方法计算单日菜品销售的平均单价和售价中位数
print(detailgroup[['amounts']].agg([np.mean, np.median])) # 合在一起
print(detailgroup.agg({'amounts': np.mean})) # 分开
print(detailgroup.agg({'amounts': np.median}))
print("-----+++++++++++-----")
### 3、使用apply方法统计单日菜品销售的数目
print(detailgroup['counts'].apply(np.sum))