编写良好的代码和异常处理
作为开发人员,开发中最令人恼火的部分通常是调试。与我共事过的大多数程序员都会赞同这种观点。通常,看到异常的第一反应是烦恼和沮丧的混合。易于调试的异常通常会在调试后的几分钟内产生根本原因。最让我烦恼的是那些在系统在生产中正常运行几天后发生的那些,它们的堆栈跟踪导致死胡同。但是,编写良好的代码可以正确管理异常,不仅可以帮助您更快地调试问题,而且在某些情况下,可以帮助系统自动恢复而无需干预。
幸运的是,您可以使用一些简单有效的工具来减少调试后一种异常所花费的时间。通常,这种技术并不能真正提高您正在开发的软件的可靠性(至少一开始不会),但是从根本上解决问题并提出修复方法变得更加容易。
何时不使用例外?
在深入了解异常处理的详细信息之前,了解何时根本不使用异常至关重要。请考虑以下方案,其中客户端希望通过发送“QUIT”命令来关闭与服务器的会话。
退出命令
由于各种原因,这是对例外的可怕使用。
- 异常在实现和可维护性方面都很难遵循: 既然这是预期的,你的客户如何知道是真的出了问题,还是这只是一个预期的异常?在客户端正常关闭会话的代码将与此服务可能发生的其他异常混合在一起。想象一下,如果您是客户团队的开发人员。遵循异常处理代码中发生的事情不会令人沮丧吗?
- 发出异常情况的信号是困难的:您正在使用异常来处理正常的代码流。发生实际异常时的计划是什么?如果客户端错误捕获了通用异常而不是此特定异常,会发生什么情况?
- 性能:发生异常时,程序控制堆栈将被抛出窗口,并且正常的调用堆栈例程将中断。由于异常预计仅在异常情况下发生,因此这些进程的性能通常不是运行时的最高优先级。
总而言之,请始终记住,只有在“异常”情况下才应引发异常。
Java 中的异常基础知识
错误与异常/捕获可抛出量与异常
错误是 Throwable 的一个子类,它指示合理的应用程序不应尝试捕获的严重问题。大多数此类错误都是异常情况。 ThreadDeath 错误虽然是“正常”情况,但它也是 Error 的一个子类,因为大多数应用程序不应尝试捕获它。捕获可投掷物会捕获所有错误。由于可投掷物是在极端条件下产生的,因此您几乎永远不会从中恢复过来。因此,捕获可抛出物不仅是一种糟糕的设计实践,而且还可能导致意想不到的后果,从而使应用程序更难调试。
选中的异常与未选中的异常
让我们看一下 Java 中异常的层次结构。

选中和未选中的异常都继承自泛型“异常”类(至少是间接继承);但是,它们在使用中具有非常不同的目的。
引发选中的异常会强制调用方考虑他们想要对异常执行的操作。他们不能简单地忽视它。他们要么需要捕获它并对其进行处理,要么将其显式扔回调用方。这是因为 Java 编译器不允许您编译可以接收已检查异常并忽略它的方法调用。

未经检查的异常是纯粹的运行时异常。通常,您不会期望所有调用方都知道可以从应用程序代码引发的每个运行时异常。调用方不需要显式考虑引发运行时异常时要执行的操作。

我经常遵循的一般经验法则是,当您的调用者想要捕获异常并对其进行处理时,使用检查异常。这条规则确实带有一粒盐。如果您在 UI 层并进行服务调用怎么办?您可能希望捕获所有异常,而不是在屏幕上显示 Java 堆栈跟踪。
引发特定异常
你见过多少次看起来像这样的代码?

通常,这是编写代码时最容易错过的错误。您反对截止日期,异常处理可能是您考虑的最后一件事。
引发泛型异常会严重妨碍调用方以不同的方式处理不同异常的能力。在这里,调用方明确需要捕获泛型异常,也许可以执行一些字符串魔术来了解代码的问题是什么,然后适当地处理它。相反,如果您只是抛出更具体的异常,则调用方可以通过捕获不同类型的异常并以不同的方式或按照程序的决定处理每个异常来清楚地了解发生了什么错误。
永不吞咽异常
吞下例外是危险的,在任何地方几乎没有例外。下面是一个简单的示例,用于演示可能发生的问题。

当数据库调用的可靠性为 99.999% 时,假设 0.001% 的调用将值保留在数据库中失败;您最有可能收到需要调试的用户投诉是什么?“即使交易被标记为成功,账户中也没有存入资金。”这似乎是一个从未发生过(或很少发生)的场景,但在我在软件行业工作期间,我遇到了 100 多个实例,在这些实例中,我阅读了与此类似的代码。忘记从异常中恢复;这里的调用者只是不知道是否有异常。作为收到此错误报告的开发人员,您不知道出了什么问题。数据库连接有问题吗?还是您被数据库限制?即使是像异常发生在哪里这样的基本问题也变得无法回答。
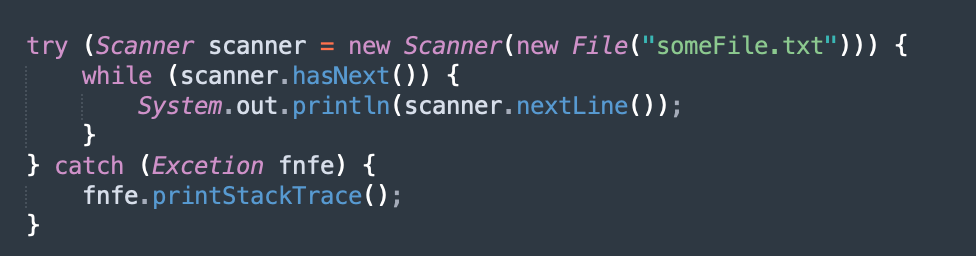
不要丢失堆栈跟踪
我经常观察到的一个常见且简单的错误是看起来像这样的代码。

与前面的示例不同,此处您知道错误发生的位置。当您进行持久函数调用时,它发生了。但是,一旦您知道此时发生了不好的事情,您想如何处理错误?当您查看堆栈跟踪时,除了错误发生的位置之外,它不会告诉您太多。用户 ID 是否不正确?帐号有误吗?数据库保存操作是否失败?确保将堆栈跟踪传播到调用方是回答这些问题的简单方法。
对所有捕获块进行递归审核是发现系统中的任何漏洞的必要条件。
在这里,堆栈跟踪将精确地回答我们上面提出的问题。只需查看堆栈跟踪,您就会知道哪一行引发了异常。对所有捕获块进行递归审核是发现系统中的任何漏洞的必要条件。
快速故障
当我们尝试自动从故障中恢复时,通常会提出一些论点。随着时间的推移,这些方案中会出现更复杂和细微的问题,调试起来令人沮丧。让我们看一个例子。

想象一下,您正在引导一个服务,该服务根据可用的线程池大小运行一堆侦听器。现在假设其中一位开发人员在配置中或在访问配置以获取线程数时引入了拼写错误。没有什么是失败的;您的服务会引导,但延迟开始增加。我可以想象在某些情况下,您必须竭尽全力才能根除此问题的原因。
快速失败的代码完全避免了此问题。您希望使用某个方法,如果出现异常,则立即停止并向调用方返回异常。这种方法可以确保您的服务不会在不完全正确的情况下启动,从而避免后续的问题。
快速失败的代码完全避免了此问题。您希望使用某个配置。如果找不到配置,为什么不立即抛出?这样做不仅可以精确地查明问题,还可以在开发过程中发现问题,从而节省推送紧急修复的麻烦。
快速失败也意味着你在对代码状态做出假设的地方失败。让我们看另一个例子来理解这一点。

此代码可能导致死胡同堆栈跟踪。如果在调用进程方法时抛出 NullPointerException,你怎么知道函数的输入是空的还是“除数”是空的?相反,在除数的构造函数中添加非空断言的代码将立即让调试器知道这里出了什么问题。
清理资源
发生异常时清理任何资源实例对于避免内存泄漏至关重要。内存泄漏是一类棘手的错误,因为症状通常不容易与根本原因相关联。

在上面提到的示例中,如果扫描程序对象已正确实例化,但在从文件中读取数据时引发异常,则扫描程序对象永远不会关闭。相反,使用 Java 中的 try-with-resource 语义根本不担心这个问题。
结论
尽管每个人都讨厌例外,但它们必然会发生。Java 围绕适当的异常处理提供了一个出色的生态系统,这有助于使您的调试工作非常轻松。了解异常处理的基础知识对于良好的软件交付至关重要,我打算捕获一些方法,这些方法可以帮助提高代码的健壮性,并最终帮助减少调试代码所花费的时间









![[附源码]计算机毕业设计基于SSM和UNIAPP的选课APP](https://img-blog.csdnimg.cn/46e7ec135d0d432f842f0bfa4d94af5b.jpeg)