链表的概念与结构
链表与我们通讯录中的顺序表是不同的,顺序表的空间是连续的,像数组一样可以通过下标访问。而链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。即:链表是通过指针将一块块结构体(节点)串起来,前一个节点存放着指向后一个节点的地址。

链表的理解

链表就是像这样的,即将你想要存放的数据分别放在上面的1 2 3 4...中,因为在空间上是不连续的,但是若想要在逻辑上连续则需要使每一个节点中存放指向下一个节点的结构体指针,而链表的另一个特点就是:你要存多少数据就给你开辟多少节点的空间给你使用,不存在浪费空间的情况,即需要我们动态开辟空间(在堆区)
单链表的功能实现
创建节点与链表头
Test* plist = NULL; //链表头
这里的链表头就是指向第一个节点的结构体指针,好一个一个的往后找数据。
typedef struct test
{
int date;
struct test* next;
}Test;变量 data 就是存放我们要添加的数据 (我这里是整型),而 next 指针变量存放的就是下一个节点的地址,因为节点的类型是 struct test,所以我们就要创建同类型的指针接受。
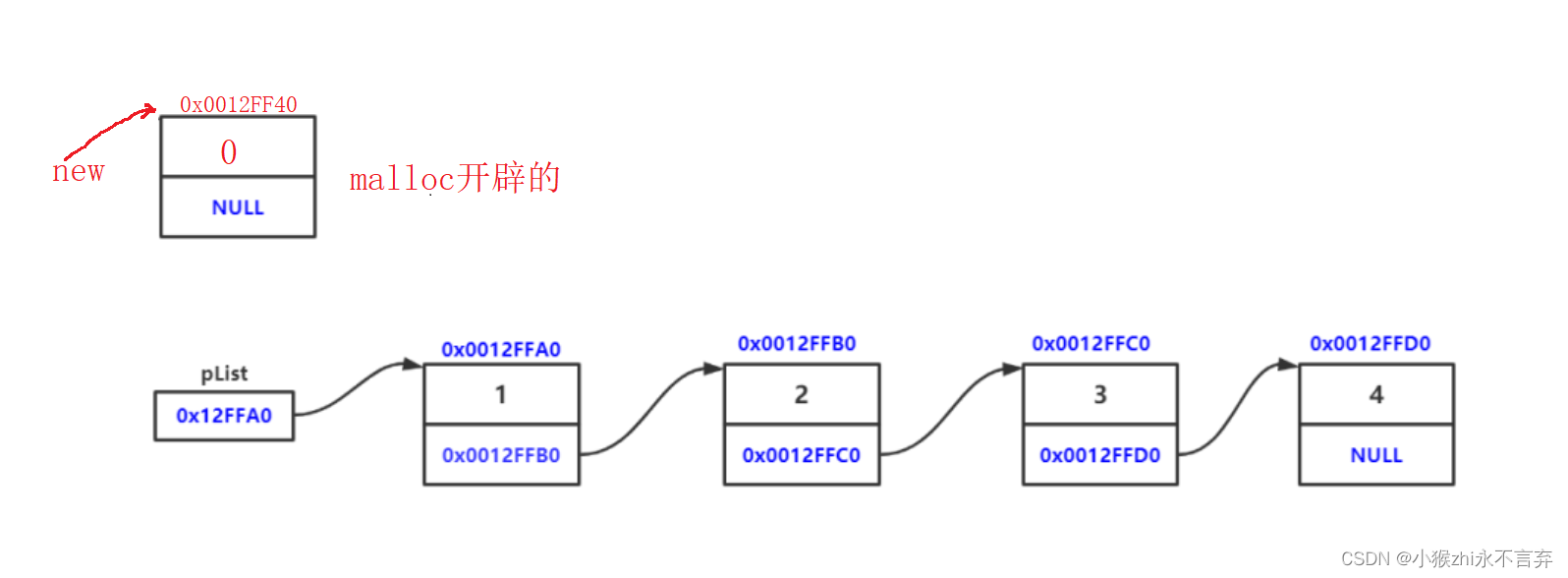
Test* Malloc(int x)//x是要存放的数据
{
Test* new = (Test*)malloc(sizeof(Test));
assert(new);
new->date = x;
new->next = NULL;
return new;
}链表的节点是 malloc 动态开辟出来的,用多少就开辟多少。
打印数据
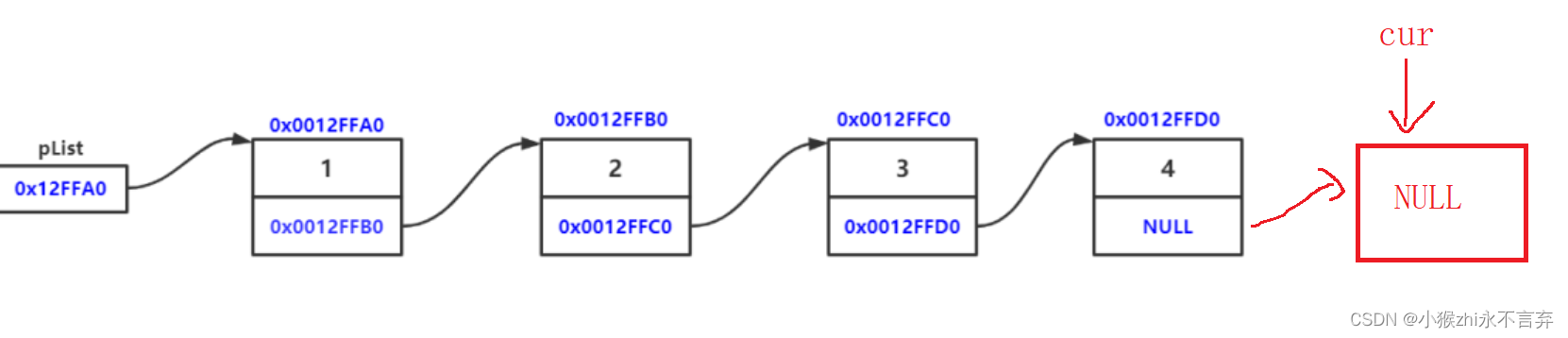
void Print(Test* phead)
{
Test* cur = phead;//指向当前结构体的指针
while (cur != NULL)//最后一个数据指针指向NULL
{
printf("%d->", cur->date);
cur = cur->next;//指向下一个节点
}
printf("NULL");
}链表和顺序表是不同的,顺序表可以通过数组下标去任意的访问数据,因为物理空间连续,链表的物理空间不连续,所以只能通过链表头从前往后的去一个个访问数据。
cur 是我们创建的一个临时变量指向第一个节点,执行完之后就将 cur->next 赋给 cur 即:cur 指向下一个节点的地址...直到 cur 指向 NULL 就停止。
头部插入数据
Test* Malloc(int x)//x是要存放的数据
{
Test* new = (Test*)malloc(sizeof(Test));
assert(new);
new->date = x;
new->next = NULL;
return new;
}void Pushfront(Test** phead,int x)
{
Test* new = Malloc(x);
new->next = *phead;
*phead = new;
}这里是从头部插入数据,所以会将链表头指向的地址发生改变,即改变指针,所以传参就要穿指针的地址,所以我这里用二级指针来接受数据,解引用就相当于直接访问链表头 plist 这个一级指针,改变 *phead 就相当于直接改变 plist。 Malloc(x)是我们开辟的节点地址即一个新的节点。
new->next = *phead; 即使新节点的next指向原来的链表头 *phead = new; “换头”
尾部插入数据
void Pushback(Test** phead, int x)
{
Test* new = Malloc(x);//创建结构体
if (*phead == NULL)//如果一个节点都没有
{
*phead = new;
return;
}
//Test** cur = phead; //有问题,接下*cur也就相当于*phead,是同一块空间
Test* cur = *phead; //临时空间
while (cur->next != NULL)//找到尾部
{
cur = cur->next;
}
cur->next = new;//改变结构体用结构体指针
}
Test** cur = phead; //这个是博主自己犯的一个错误,这样可是行不通的哈,因为如果后续*cur去访问的可就不是临时变量了,解引用就相当于直接访问了 *phead 即:plist,这样进行后续的操作的话,就直接改变了链表头的指向了。所以就有 Test* cur = *phead; 这种写法cur是临时创建的变量改变 cur 并不会造成什么其他的影响,出了作用域也就销毁了。
while (cur->next != NULL) 这里是通过 cur->next找尾结点,可不能用 cur 去直接找
如果直接找就变成上面的样子,而且单链表是从前往后找的(一去不返)所以就有 cur->next 为空指针就停下来了。
指定位置插入数据
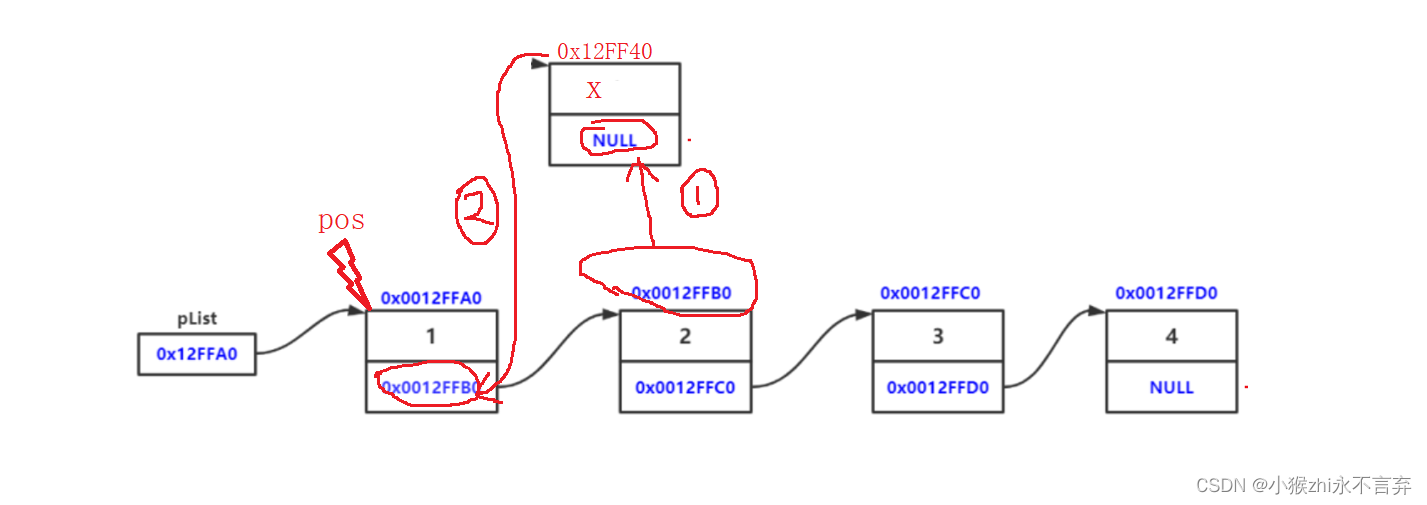
void InsertAfter(Test* pos, int x)//pos就是要插入的节点地址
{
assert(pos);
Test* tail = pos->next;//找到要增数据的下一个节点地址
Test* new = Malloc(x);
pos->next = new;
new->next = tail;
}
我们一般是在指定位置的后面插入节点的,所以就要先将要插入数据后面的一个节点链接起来,防止先插入数据导致后面的数据丢失。
如果我们要在指定位置前面插入数据的话就要在创建一个结构体指针指向要插入数据的前面一个节点的地址,并使 next 指向新开辟的节点地址。具体方法就留个你们试试了!
尾部删除数据
void Popback(Test** phead)
{
assert(*phead);
if ((*phead)->next == NULL)//只有一个节点时
{
free(*phead);
*phead = NULL;
return;
}
Test* cur = *phead; //临时空间1
while (cur->next->next != NULL)//找倒数第二个节点
{
cur = cur->next;
}
free(cur->next);//释放最后一个节点空间
cur->next = NULL;
//或者用两个临时空间寻找最后两个节点
//Test* tail = *phead; //临时空间2
//while (cur->next != NULL)
//{
// tail = cur;
// cur = cur->next;
//}
//free(cur);
//tail->next = NULL;
}想要尾部数据删除就要将最后一个节点的空间释放,倒数第二个节点的 next 指向NULL
所以我们要找最后两个节点的空间。
方法1:直接通过一个结构体指针指向下下个节点
方法2:使用两个结构体指针一前一后
这里如果只有一个节点的话删除数据就要穿 plist 的地址了,因为会将 plist 置空,但如果不止一个节点的话,就不用传地址了,链表头的指向并不会改变。
头部删除数据
void Popfront(Test** phead)
{
assert(*phead);
Test* cur = *phead; //临时空间
*phead = cur->next;
free(cur);
}删除链表的第一个数据就需要传链表头的地址,用二级指针接收,因为删除第一个节点后,链表头就要指向第二个节点的地址,所以解引用是直接对链表头 plist 存的数据进行直接操作。
指定位置删除数据
void EraseAfter(Test* pos)
{
assert(pos);
Test* cur = pos->next;//找到要删数据的下一个节点
assert(cur);
pos->next = cur->next;//将下下个节点串起来
free(cur);//删除
}我们一般也是在指定位置的后面删除节点的,所以就要先将要删除数据后面的一个节点存起来起来,防止先释放空间导致后面的数据丢失。
如果我们要在指定位置前面删除数据的话也要在创建一个结构体指针指向要插入数据的前面一个节点的地址,具体实现就留给你们了。
查链表数据
Test* Find(Test* phead, int x)
{
Test* cur = phead;//指向当前结构体的指针
while (cur->date != x && cur)//找到了或找完了就会退出
{
cur = cur->next;
}
if (cur->date == x)//判断是否找到
return cur;
return NULL;//没找到就返回空
}查找数据直接遍历链表就可以了。但是这种写法,这里会有一个小问题,如果链表为空,则执行到while (cur->date != x && cur) 时就会报错了,cur->date 相当于解引用,为空时就会出错。所以下面这种写法就更安全。
Test* Find(Test* phead, int x)
{
Test* cur = phead;//指向当前结构体的指针
while (cur)
{
if (cur->date == x)//判断是否找到
return cur;
cur = cur->next;
}
return NULL;//没找到就返回空
}空间释放
我们知道堆区开辟的空间要及时释放,否则会造成内存泄漏,十分危险!
void Free(Test* phead)
{
Test* cur = NULL;//指向当前结构体的指针
while (cur)
{
cur = phead;
phead = phead->next;//先将后面的节点记下来
free(cur);
}
}
若有解释不当请留下评论相互学习!