1、一致性 Hash 算法原理
一致性 Hash 算法通过构建环状的 Hash 空间替线性 Hash 空间的方法解决了这个问题,整个 Hash 空间被构建成一个首位相接的环。
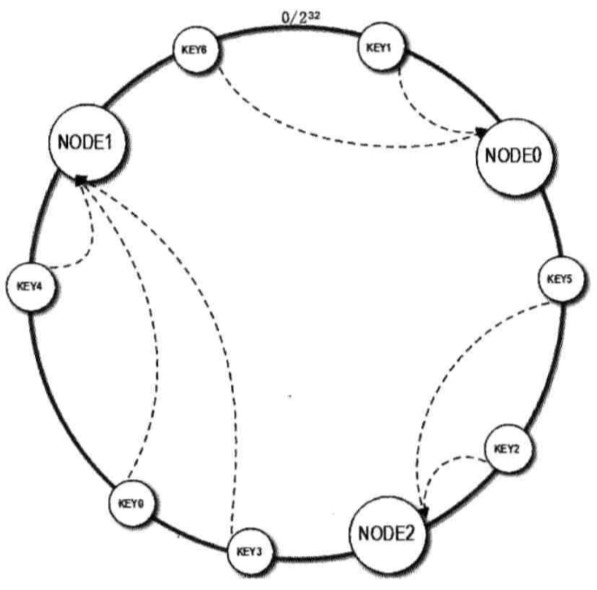
其具体的构造过程为:
- 先构造一个长度为 2^32 的一致性 Hash 环
- 计算每个缓存服务器的 Hash 值,并记录,这就是它们在 Hash 环上的位置
- 对于每个图片,先根据 key 的 hashcode 得到它在 Hash 环上的位置,然后在 Hash 环上顺时针查找距离这个 Key 的 Hash 值最近的缓存服务器节点,这就是该图片所要存储的缓存服务器
当缓存服务器需要扩容的时候,只需要将新加入缓存服务器的 Hash 值放入一致性 Hash 环中,由于 Key 是顺时针查找距离其最近的节点,因此新加入的几点只影响整个环中的一小段。
加入新节点 NODE3 后,原来的 Key 大部分还能继续计算到原来的节点,只有 Key3、Key0 从原来的 NODE1 重新计算到 NODE3,这样就能保证大部分被缓存数据还可以命中。
当节点被删除时,其他节点在环上的映射不会发生改变,只是原来打在对应节点的 key 现在会转移到顺时针方向的下一个节点上。
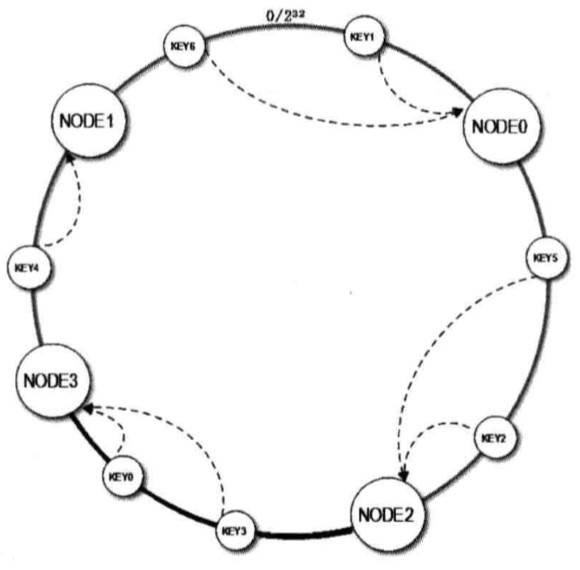
2、解决Hash 环数据倾斜问题
新加入的节点 NODE3 只影响了原来的节点 NODE1,也就是说一部分原来需要访问 NODE1 的缓存数据现在需要访问 NODE3(概率上是 50%)但是原来的节点 NODE0 和 NODE2 不受影响,这就意味着 NODE0 和 NODE2 缓存数据量和负载压力是 NODE1 与 NODE3 的两倍。
(1)引入虚拟节点
为了解决这个问题,最好的办法就是扩展整个环上的节点数量,可以将每台物理缓存服务器虚拟为一组虚拟缓存服务器,使得 Hash 环在空间上的分割更加均匀。
这样只是将虚拟节点的 Hash 值放置在 Hash 环上,在查找时,首先根据 Key 值找到环上的虚拟节点,然后再根据虚拟节点找到真实的缓存服务器。
虚拟节点的数目足够多,就会使得节点在 Hash 环上的分布更加随机化,也就是增加或者删除一台缓存服务器时,都会较为均匀的影响原来集群中已经存在的缓存服务器。
3、一致性 Hash 算法的缺陷
虽然一致性 Hash 算法已经十分完善,但是还是有很多不足的地方
- Hash 环上的节点非常多或者更新频繁时,查询效率比较低下
- 整个 Hash 环需要一个服务路由来做负载均衡,存在单点问题
正因为一致性哈希分区的这些缺点,Redis 在实现自己的分布式集群方案时,采用了基于 P2P 结构的哈希槽算法。
其实本质上虚拟槽中的槽就是大量的虚拟节点的抽象化, 将原来的虚拟节点变成一个槽, redis内置是有16383个槽也就是有16383个虚拟节点。
(1)添加哈希槽解决更新效率
Redis Cluster 通过分片的方式将整个缓存划分为 16384 个槽,每个缓存节点就相当于 Hash 换上的一个节点,接入集群时,所有实例都将均匀占有这些哈希槽,当需要查询一个 Key 是,首先根据 Key 的 hashcode 对 16384 取余来得到 Key 属于哪个槽,并映射到缓存实例上。
(2)去中心化,解决单点负载
每个节点都保存有完整的哈希槽-节点的映射表,也就是说,每个节点都知道自己拥有哪些哈希槽,以及某个确定的哈希槽究竟对应着哪个节点。
无论向哪个节点发出寻找 Key 的请求,该节点都会通过求余计算该 Key 究竟存在于哪个哈希槽,并将请求转发至该哈希槽所在的节点。
4、使用ceilingEntry简易实现
这里使用TreeMap的ceilingEntry(K key) 方法,该方法用来返回与该键至少大于或等于给定键,如果不存在这样的键的键 - 值映射,则返回null相关联。
public class ConsistentHash {
/**
* 假设我们一共初始化有8个节点(可以是ip, 就理解为ip吧);
* 把 1024个虚拟节点跟 8个资源节点相对应
*/
public static Map<Integer, String> realNodeMap = new HashMap<>();
public static int V_NODES = 1024; // 假设我们的环上有1024个虚拟节点
static TreeMap<Integer, String> virtualNodeMap = new TreeMap<>();
private static final Integer REAL_NODE_COUNT = 8;
static {
realNodeMap.put(0, "node_0");
realNodeMap.put(1, "node_1");
realNodeMap.put(2, "node_2");
realNodeMap.put(3, "node_3");
realNodeMap.put(4, "node_4");
realNodeMap.put(5, "node_5");
realNodeMap.put(6, "node_6");
realNodeMap.put(7, "node_7");
for (Integer i = 0; i < V_NODES; i++) {
// 每个虚拟节点跟其取模的余数的 nodeMap 中的key相对应;
// 下面删除虚拟节点的时候, 就可以根据取模规则来删除 TreeMap中的节点了;
virtualNodeMap.put(i, realNodeMap.get(i % REAL_NODE_COUNT));
}
}
/**
* 输入一个id
*
* @param value
* @return
*/
public static String getRealServerNode(String value) {
// 1. 传递来一个字符串, 得到它的hash值
Integer vnode = value.hashCode() % 1024;
// 2.找到对应节点最近的key的节点值
String realNode = virtualNodeMap.ceilingEntry(vnode).getValue();
return realNode;
}
/**
* 模拟删掉一个物理可用资源节点, 其他资源可以返回其他节点
*
* @param nodeName
*/
public static void dropBadNode(String nodeName) {
int nodek = -1;
// 1. 遍历 nodeMap 找到故障节点 nodeName对应的key;
for (Map.Entry<Integer, String> entry : realNodeMap.entrySet()) {
if (nodeName.equalsIgnoreCase(entry.getValue())) {
nodek = entry.getKey();
break;
}
}
if (nodek == -1) {
System.err.println(nodeName + "在真实资源节点中无法找到, 放弃删除虚拟节点!");
return;
}
// 2. 根据故障节点的 key, 对应删除所有 chMap中的虚拟节点
Iterator<Map.Entry<Integer, String>> iter = virtualNodeMap.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<Integer, String> entry = iter.next();
int key = entry.getKey();
String value = entry.getValue();
if (key % REAL_NODE_COUNT == nodek) {
System.out.println("删除节点虚拟节点: [" + key + " = " + value + "]");
iter.remove();
}
}
}
public static void main(String[] args) {
// 1. 一个字符串请求(比如请求字符串存储到8个节点中的某个实际节点);
String requestValue = "hello";
// 2. 打印虚拟节点和真实节点的对应关系;
System.out.println(virtualNodeMap);
// 3. 核心: 传入请求信息, 返回实际调用的节点信息
System.out.println(getRealServerNode(requestValue));
// 4. 删除某个虚拟节点后
System.out.println("==========删除 node_2 之后: ================");
dropBadNode("node_2");
System.out.println("===============删除之后的虚拟节点map: ===========");
System.out.println(virtualNodeMap);
System.out.println("==============删除之后, 获取节点的真正node节点对应者: ");
System.out.println(getRealServerNode(requestValue));
}
}







![C++ [STL-简介]](https://img-blog.csdnimg.cn/84e4fd60d85a42619862f999bd6ec9ea.png#pic_center)