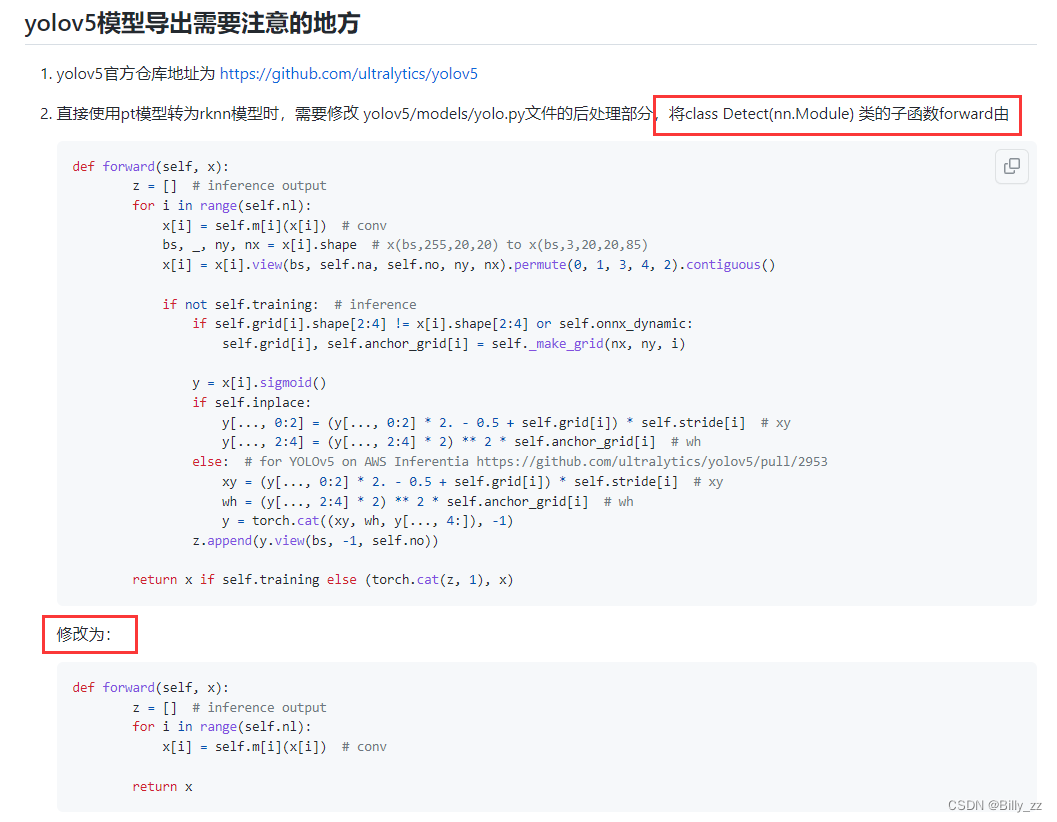
目录
多目标建模总结
推荐系统——多目标优化
网易严选跨域多目标算法演进
背景介绍
多目标建模及优化
1.样本与特征
2. 模型结构迭代
3. 位置偏差与 Debias
4. 多目标 Loss 优化
5. 跨域多目标建模
多目标建模总结
http://t.csdn.cn/H514i
常见的指标有点击率CTR、转化率CVR、GMV、浏览深度和品类丰富度等。
多目标建模的常用方法:
-多模型的融合
-多任务学习
底层共享表示的优化
任务序列依赖关系建模
多目标建模已经成为当前推荐系统中的标配,在多目标建模过程中,需要考虑多个目标之间的相互关系,以选择合适的多目标建模方法,同时,在多目标的损失函数的设计上,也存在很多的优化方案,需要根据具体的应用场景选择合适的损失函数,以达到对具体任务的优化。

推荐系统——多目标优化
http://t.csdn.cn/JNdFF

网易严选跨域多目标算法演进
全文目录:
-
背景介绍
-
多目标建模及演进
-
长期价值探索
-
多场景建模的实践
其中 Part2 围绕严选业务,介绍如何多目标建模,以及进一步演进至跨域多目标建模的具体做法;Part3 主要分享在推荐业务中长期价值的探索;Part4 则集中在多场景建模,并结合某业务场景的实践进行细粒度讲解。
01
背景介绍
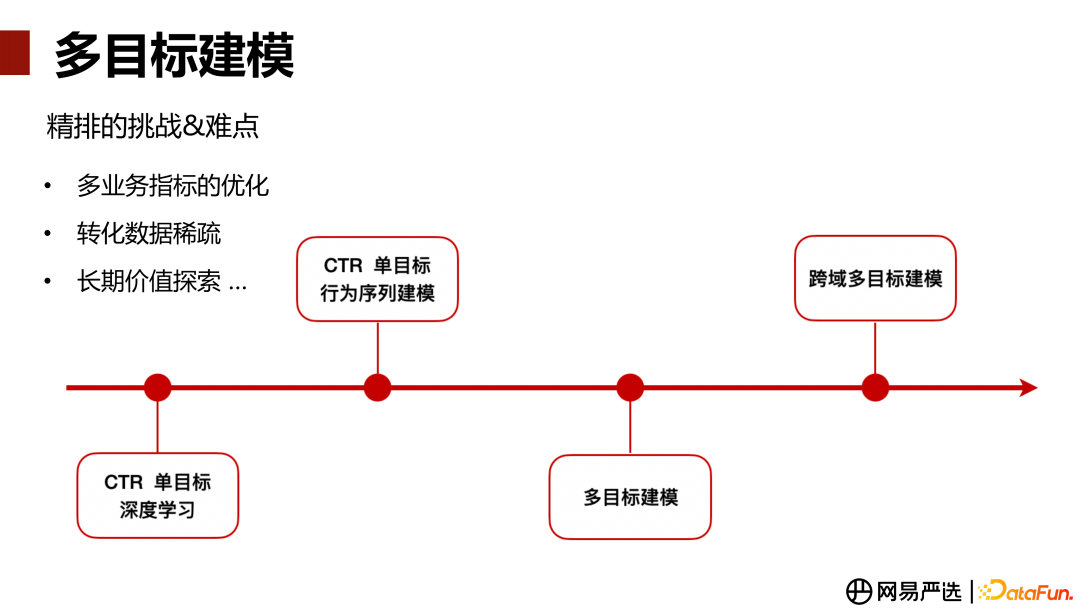
推荐系统的总体流程可以分成四块,主要是召回、粗排、精排、重排。其中精排会承载很多业务模块的业务指标,在不同业务模块,关注的业务指标有所不同。对于某一些业务指标,存在转化数据比较稀疏,以及冷启动的问题。另外,我们在与业务方的交流中发现,他们关注的一些业务指标与算法目标不直接相关,需要我们去做一些长期价值的探索。
严选精排算法演进过程,开始是基于深度学习的 CTR 单目标建模,然后在此基础上增加了基于用户行为序列进行建模,接着衍生到多目标建模,最后是跨域多目标建模。
02
多目标建模及优化
1.样本与特征
近年来,多目标建模是业界排序建模的主流方式,而业务数据和特征工程决定了模型的上限。
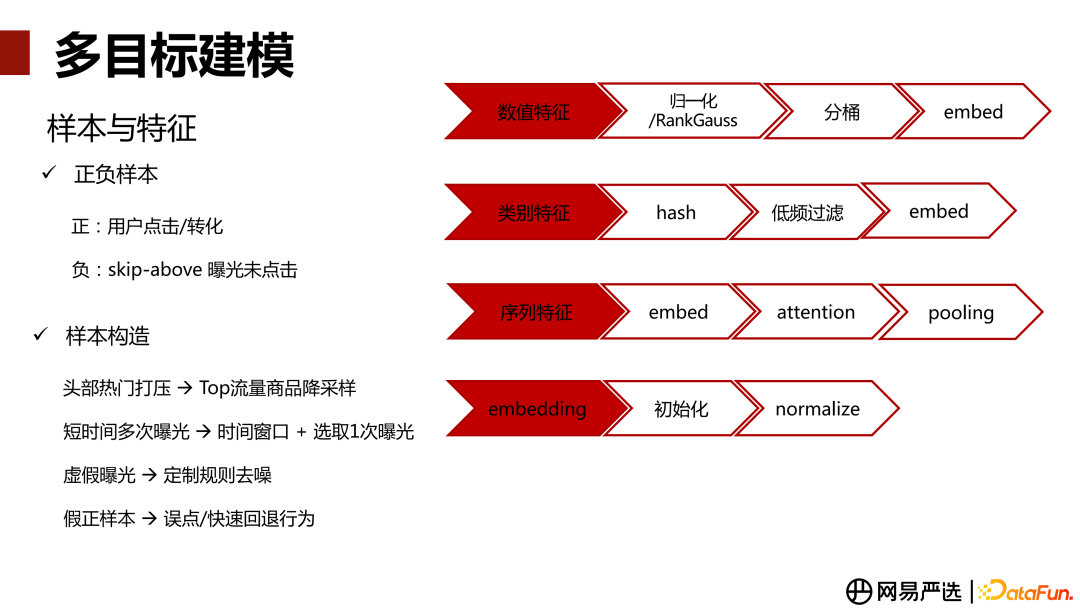
在多目标建模中,我们选取用户的点击与转化行为为正样本,根据 Skip-Above 原则,选取曝光未点击的样本作为负样本。此外,在样本构造中还会注意以下几个优化点:
-
头部的热门商品可能存在过曝光,需要对这种 Top 流量的商品做降采样。
-
-
-
特征工程方面,我们将其分为四类:数值特征、类别特征、序列特征和 Embedding。各类特征处理方式如下:
-
-
-
-
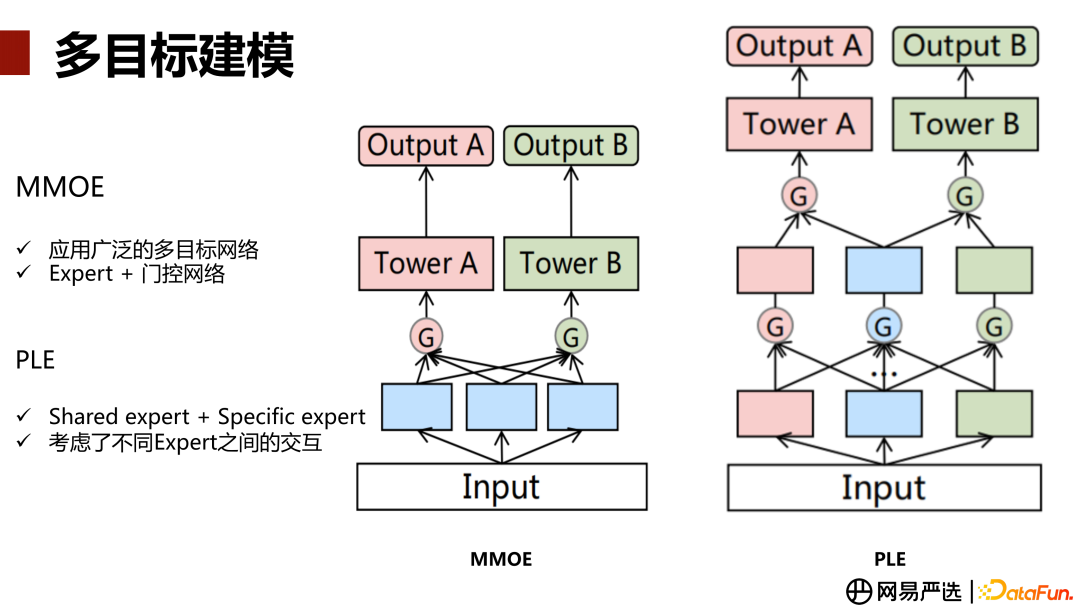
2. 模型结构迭代
3. 位置偏差与 Debias
上面介绍了数据特征处理和使用基础的多目标网络结构进行建模,在此基础上,会根据实际业务场景的问题进行优化。
第一个问题是位置偏差,位置偏差是指推荐 Feed 流场景下用户倾向点击/交互曝光位置靠前的物品,这个信息蕴含在正样本里,可能会导致建模存在偏差。如下图左上角是对某个业务模块做的位置偏差分析,横轴是时间,纵轴是曝光点击率。可以看到随着坑位的逐渐往下,曝光点击率逐渐下降。基于带位置偏差的数据进行模型训练,会形成一个循环反馈,模型去学习这种趋势,然后做预测推荐,会导致位置偏差在不断地放大,从而导致整体的推荐流量生态出现问题,比如部分商品过曝光。
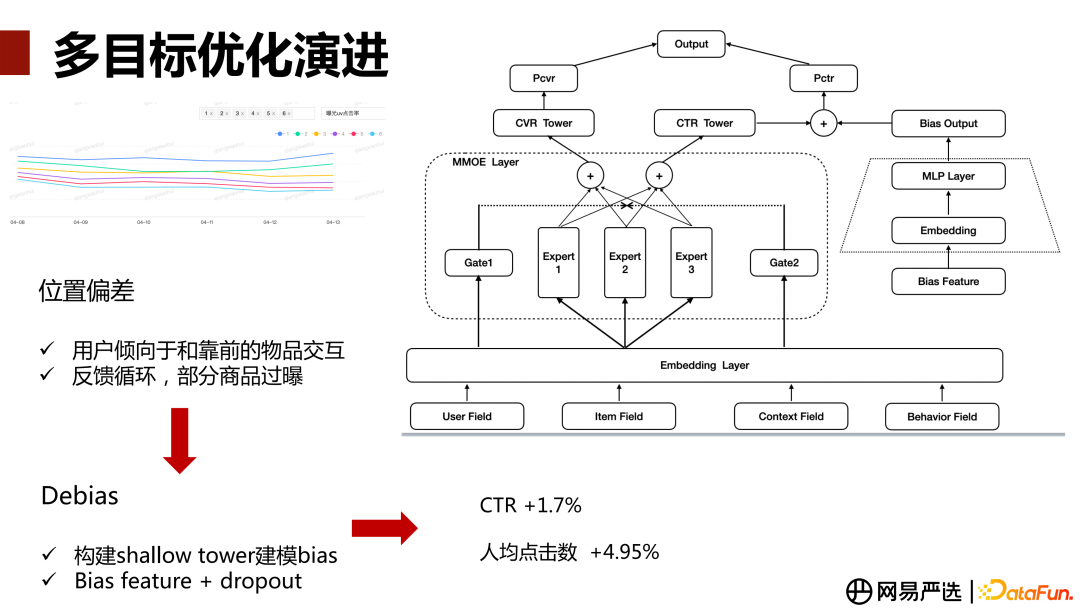
存在的位置偏差需要做 Debias 的操作。我们做 Debias 的方式是在 MMOE 多任务的基础上,加一个消偏模块。整体结构如上图右边部分,输入是常见的几类特征(用户侧、商品侧、情境上下文,行为交互序列特征)。经过特征预处理后,输入到 Embedding 层,然后会进入 MMOE 主网络。同时会构建一个 Debais 辅助网络,输入主要是 Bias 相关的特征(比如商品曝光的坑位、设备的型号、用户的身份等可能影响到展示位置的特征),经过浅层网络后得到bias 的学习表征。然后把这个结果与多任务主网络学出来的 CTR 结果直接相加,再经过一层激活函数得到最终 CTR 预测结果,CVR 网络无任何操作。Debais 辅助网络的浅层部分,会加上 Dropout,主要是为了防止模型学习结果过于依赖浅层网络的特征,保证模型的鲁棒性。
多任务模型 Debias 优化上线 AB 后,人均点击数+4.95%、曝光点击率+1.70%。需要说明的是,Debias 优化需要根据具体业务特点做判断,我们的场景 AB 刚上线前几天,会对某些业务指标产生非正向收益,因为 Debias 会对热门做打压,对长尾的商品进行扶持,这可能会影响销售额。Debias 优化,本质上是从整体业务生态或者长期收益的角度考虑问题,在短期内能承载一部分收益下降的前提下,可以推全放量,它会带动整体推荐流量生态向良性、健康的方向发展。
4. 多目标 Loss 优化
此外,在 CTR 跟 CVR 目的基础上根据业务方的需求增加更多的目标,包括加购、评论商品、查看促销信息、分享、收藏等。有些目标如收藏、分享的转化数据相对会比较稀疏,这些任务与 CTR、CVR 样本比较丰富的任务一起训练时,由于样本过于稀疏,会导致训练不够充分,被带偏。
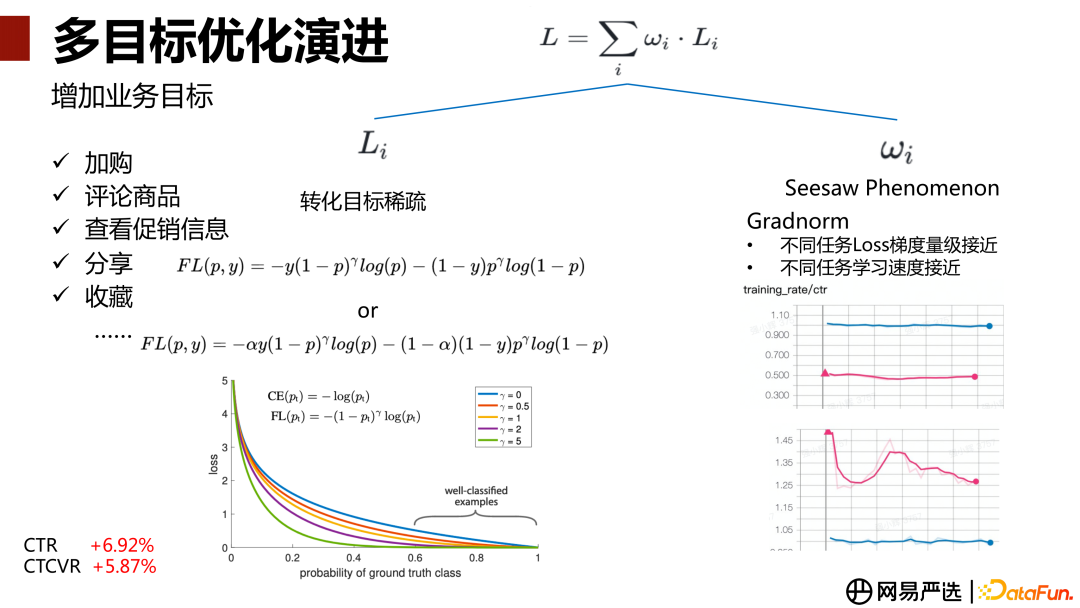
针对转化目标比较稀疏,训练不充分的问题。我们会考虑在损失函数上引入 Focal Loss[4] 替换交叉熵函数。如上图中的 FL(p, y),Focal Loss 在交叉熵基础上,增加了 P 和 Gamma 两个参数,P 就是模型预测样本是否为正样本的概率。看损失函数第一项,对于正样本,P 的预测接近 1 时,1-p 的 Gamma 次方会更加接近于 0,那么很容易区分的那部分正样本,损失会下降非常明显;P 的预测接近 0 时,损失无太大变化。对负样本的处理与正样本同理。Focal Loss 目的是让 Loss 去关注/聚焦比较难以区分样本信息,Gamma 参数是去调节聚集程度。还可以再引入一个类别权重参数A lpha,去解决正负样本不平衡的问题。比如 Alpha 定义为正负样本比,增强正样本的损失影响。
另外,多个子任务一起训练时可能存在某个子任务被带偏的情况,即跷跷板(Seesaw Phenomenon)效应。我们尝试使用 Gradnorm[5] 梯度归一化来控制 WI 的权重。梯度归一的目标是让不同的任务的 Loss 梯度量级更加接近,同时还可以让不同任务的学习速率也更加接近。通过这两个点优化 WI 权重,让各个任务的学些更加平衡。上图右下角两张图是 CTR、CVR 训练速度的展示。红线是它原有的训练速度,蓝线是经过 Gradnorm 调整之后的,可以看到调整之后,训练的速度接近 1 左右,不会出现速度训练过快或过慢的情况。
多目标损失优化,引入 Focal Loss 和 GradNorm 控制损失权重后,整体上线 AB 实验,CTR +6.92%,CTCVR+5.87%,都有显著提升。
5. 跨域多目标建模
在我们的业务中,会涉及到很多场景,比如新客、新品页面,用户的行为数据会比较稀疏,还有新上线的业务模块,刚上线数据非常少,处于冷启状态。那么在这些场景下,如何能够让模型学习得更好呢?那就需要考虑多场景的跨域建模。引入多场景的好处在于,首先让模型先意识到场景之间的差异性,建模拟合映射由 P(y|x) -> P(y|x, d),输入增加了场景信息(Domain)。另外小样本的场景,能够通过对样本更加丰富/比较成熟模块的场景共性的刻画和迁移学习,让模型对小场景也能够取得更好的效果。
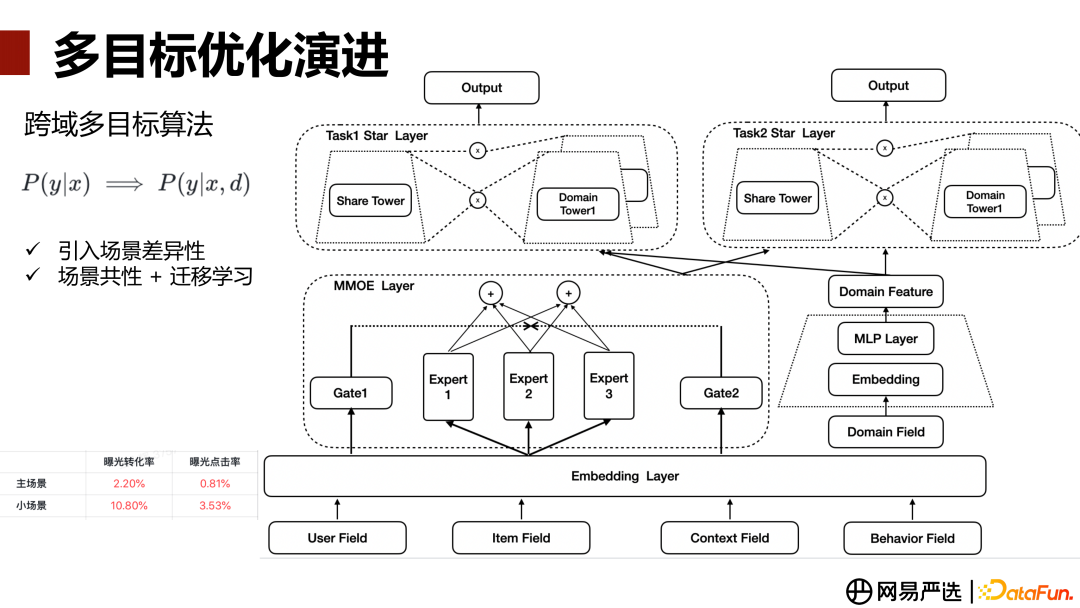
跨域多目标算法的整体网络结构,如上图。
底层输入特征(包括用户侧、商品侧、上下文情境、行为序列特征),经过特征预处理进入 Embedding 层,然后进 MMOE 层进行多任务的信息抽取。网络右边部分是一个辅助网络,把域/不同场景/Domain Field 相关的特征输入,然后经过一个 Domain Tower 得到对应场景的抽象特征。然后将场景的抽象特征与多任务的输出表征共同输入到 STAR 网络层(参考阿里 STAR 文章[6]),STAR 的拓扑结构里包含两种塔:共享 Share塔、表征不同场景的 Domain塔。Share塔主要去学习场景的一些共性信息,Domain 塔去学习各个不同场景对应的独特信息,之后对两边塔的权重进 Element相乘后得到的结果,作为每个场景的权重,最终得到每个场景下不同任务的输出。
这个优化上线后,在主场景和小样本场景上取得的效果有些差异,小样本场景下的提升更加明显,曝光转化率和曝光点击率有 10.8% 和 3.5% 的相对提升。主场景下,本身数据比较丰富,效果提升没有那么显著,曝光转化率和曝光点击率分别有 2.2% 和 0.81% 的提升。
(2023年 4月19日 10:26首次发布)