目录
什么是优先队列
为什么需要优先队列?
优先队列是个啥?
优先队列的工作原理
Python实现一个优先队列
Python内置库中的queue.PriorityQueue的使用
基本操作
多条件优先级实现
Python内置库中的heapq
heapq的常用操作
基于heapq实现一个优先队列类
什么是优先队列
为什么需要优先队列?
有一个小需求:请取出一组数中的最大数,比如该组数为:1,5,2,8,6,4,3,7,9,0
要是你该如何实现该需求呢?
最简单的策略是:将这组数存入列表,然后调用max取列表的最大值

大家可以去网上搜索下max函数的时间复杂度是O(n)。
相当于下面实现:

我们再来变更下需求,我们需要:取出这组数中前三大的值
那么此时max函数就不太适合了。
最简单的策略是:将这组数存入列表,然后对列表进行降序,然后取前三个数:

那么上面这种策略取出前三个最大数的时间复杂度是多少呢?
这个大家可以去网上搜下Python的sorted方法的使用的算法是timsort,时间复杂度最优是O(n),最差是O(nlogn),平均是O(nlogn)。
可以发现,其实max函数的性能要比sorted函数要好。
好的,现在我们再变更下需求:
现在有一组数,初始时为:3,5,1,每次我们取出一个最大值后,都会加入一个新的随机数到该组数中,然后再取出这组数中的最大值,然后再加入一个新的随机数,依次往复。
上面这个需求,在现实中有很多场景,比如:
打印机队列,比如打印机总是打印优先级最高的任务,而在其打印过程中,我们随时会加入新的任务进去,当打印机打印完当前任务后,会从任务队列中取出最高优先级的任务打印,而不是先来后到的顺序打印
那么此时该如何实现上面的需求呢?
可能大部分的人的策略会如下:
由于要取出最大值,因此,将这组数存入列表lst,然后lst升序,lst.pop()
加入一个新的数后,继续:lst升序,lst.pop()

那么上面这个逻辑的时间复杂度是多少呢?
假设这组数初始有N个,然后执行M次:取出最大值后,加入一个随机值。
那么时间复杂度为:M * NlogN
其中列表的pop和append都是尾部操作,可以看成O(1)时间复杂度。
那么上面这种类似于打印机工作原理的案例是否有更高效的算法策略呢?
答案是:有的。那就是基于优先队列数据结构。
优先队列是个啥?
我们要从一组数中取出最大值,使用:
- max函数需要O(n)时间
- sorted函数需要O(nlogn)时间
这两个方法其实都是基于列表工作的,即数组。我们知道数组是一个线性表数据结构,它在内存上是一段连续的空间,可以基于元素大小,和索引值快速找到对应元素的内存空间。即基于索引获取列表中某个元素只需要O(1)的时间。
但是要找列表中的最大值,则至少需要把所有元素遍历一遍,才能找到,即至少O(n)的时间。这是由于列表的底层数据结构决定的。
而优先队列本质是一个堆结构。
什么是堆呢?
堆其实就是一颗完全二叉树。
什么是完全二叉树呢?
一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
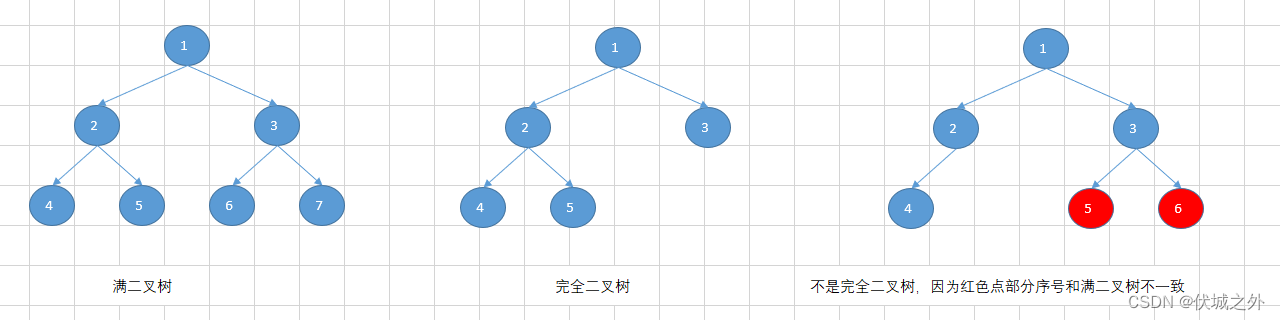
由上图我们可知,完全二叉树的最深的一层如果节点不满的话,则会优先填满左边。
并且完全二叉树中某节点的序号为k的话,则其左孩子节点的序号必然为2k+1,其右孩子节点的序号必然为2k+2。因此上面的完全二叉树可以用数组来进行模拟:
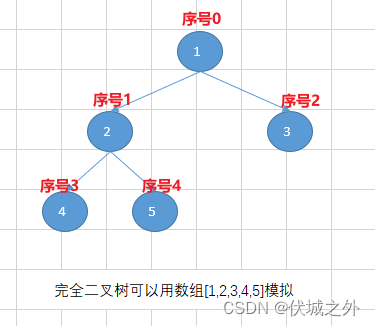
可以发现数组的索引刚好就是完全二叉树节点的序号。
堆结构对应的完全二叉树需要满足以下两个条件之一:
- 父节点要大于或等于其左右孩子节点,此时堆称为最大堆
- 父节点要小于或等于其左右孩子节点,此时堆称为最小堆
这样的话,堆结构才能快速地找到最值节点,即堆结构的顶点。
优先队列的工作原理
优先队列底层其实就是一颗完全二叉树。我们向优先队列中加入新元素,其实就是向完全二叉树中加入新元素。
优先队列中每个元素都具有一个优先级属性,该属性会决定元素在完全二叉树中的位置。
而优先队列总是保证最高优先级的元素,处于树根位置。
那么,优先队列如何实现最高优先级的元素,总是处于树根位置呢?
而这其实有涉及到了优先队列的两个常用操作:
- 出队:取出优先队列的最高优先级元素
- 入队:加入一个新元素
上面两个操作一旦发生,都可能破坏优先队列的底层数据结构的优先级顺序(即树根是否为最高优先级元素)。而为了防止优先队列的优先级顺序被破坏,上面两个操作又有两个缓冲动作:
- 出队:下沉
- 入队:上浮
当我们向优先队列中入队一个新元素,需要先将新元素加入到底层堆结构(实现:数组)的尾部,但是这样的话可能会破坏堆结构的顺序性,因此我们需要通过上浮操作,来调整堆的顺序。
关于上浮操作,请看下面示例:
如下图,是一个最大堆,父节点的值总是大于其左右子孩子节点的值

现在我们需要向堆中新增一个元素29,则先放在尾部,假设此时29的序号为k,则其父节点的序号必然为 Math.floor((k-1)/2)

然后比较29和其父节点值得大小,如果29 > 父节点值,则交换节点的值,完成29的上浮行为
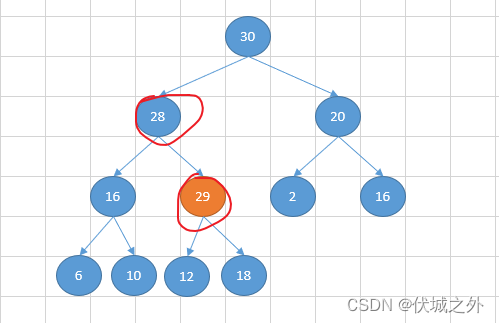
然后继续比较,29和其父节点值的大小, 如果29 > 父节点值,则交换节点的值,完成29的上浮行为

直到,29发现其小于等于父节点值时,停止上浮,或者29已经上浮到k=0序号位置,即顶点位置时,停止上浮。
当我们需要优先队列出队时,相当于堆结构删除树根元素,但是我们不能冒失的直接将堆顶元素删除,这样会让堆结构散架。
好的做法,是将堆顶元素和堆尾元素值交换,然后将堆尾元素弹出(堆结构可以用数组模拟,因此可以使用pop操作) ,但是此时堆顶元素的值其实并非最大值,因此我们需要使用下沉操作来调整堆结构,维护其顺序性。
关于下沉操作,我们可以看如下示例:
下图是一个最大堆,我们现在需要删除堆顶30

则第一步是交换堆顶元素和堆尾元素的值,然后将堆尾元素弹出


此时最大堆的顺序性被破坏,我们开始执行下沉操作,所谓下沉操作,即将破坏顺序性的节点12和max(左孩子值,右孩子值) 比较,若12< max(左孩子值,右孩子值),则交换

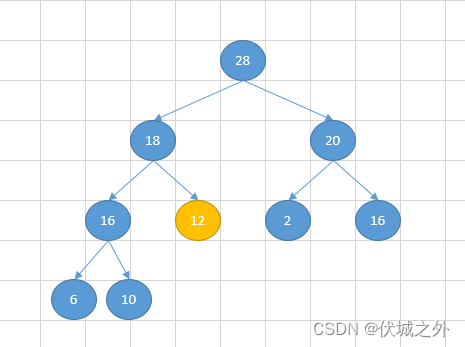
当下沉到没有左右孩子,或者大于等于max(左孩子,右孩子)时,即停止下沉。
我们可以发现,使用堆结构模拟的优先队列,每次入队都会触发上浮操作,每次出队都会触发下沉操作,但是上浮和下沉的次数最多就是完全二叉树的深度,而完全二叉树的深度为logN,也就是说优先队列每次入队和出队的时间复杂度为O(logN)。
Python实现一个优先队列
下面优先队列类的方法设计参考Python的queue.PriorityQueue
# 小顶堆优先队列
class PriorityQueue:
def __init__(self):
self.queue = []
# 交换元素
def swap(self, i, j):
self.queue[i], self.queue[j] = self.queue[j], self.queue[i]
# 获取优先队列中元素个数
def qsize(self):
return len(self.queue)
# 入队
def put(self, ele):
self.queue.append(ele)
self.swim()
# 上浮
def swim(self):
child = len(self.queue) - 1
while child != 0:
father = (child - 1) // 2
# 小顶堆,即小的的上浮
if self.queue[child] < self.queue[father]:
self.swap(child, father)
child = father
else:
break
# 出队
def get(self):
self.swap(0, len(self.queue) - 1)
ans = self.queue.pop()
self.sink()
return ans
# 下沉
def sink(self):
f = 0
while True:
l = 2 * f + 1
r = l + 1
t = None
if len(self.queue) > l >= 0 and len(self.queue) > r >= 0:
t = r if self.queue[l] > self.queue[r] else l
elif 0 <= l < len(self.queue) <= r:
t = l
else:
break
# 小顶堆,即大的下沉
if self.queue[t] < self.queue[f]:
self.swap(t, f)
f = t
else:
break实现是否正确的验证:
1705. 吃苹果的最大数目 - 力扣(LeetCode)
class PriorityQueue:
def __init__(self):
self.queue = []
# 交换元素
def swap(self, i, j):
self.queue[i], self.queue[j] = self.queue[j], self.queue[i]
# 入队
def put(self, ele):
self.queue.append(ele)
self.swim()
# 上浮
def swim(self):
child = len(self.queue) - 1
while child != 0:
father = (child - 1) // 2
if self.queue[child] < self.queue[father]:
self.swap(child, father)
child = father
else:
break
# 出队
def get(self):
self.swap(0, len(self.queue) - 1)
ans = self.queue.pop()
self.sink()
return ans
# 下沉
def sink(self):
f = 0
while True:
l = 2 * f + 1
r = l + 1
t = None
if len(self.queue) > l >= 0 and len(self.queue) > r >= 0:
t = r if self.queue[l] > self.queue[r] else l
elif 0 <= l < len(self.queue) <= r:
t = l
else:
break
if self.queue[t] < self.queue[f]:
self.swap(t, f)
f = t
else:
break
class Apple:
def __init__(self, apple, day):
self.apple = apple
self.day = day
def __lt__(self, other):
return self.day < other.day
class Solution(object):
def eatenApples(self, apples, days):
"""
:type apples: List[int]
:type days: List[int]
:rtype: int
"""
pq = PriorityQueue()
count = 0
i = 0
while i < len(apples) or len(pq.queue) > 0:
if i < len(apples) and apples[i] > 0:
pq.put(Apple(apples[i], i + days[i]))
while True:
if len(pq.queue) == 0:
break
head = pq.queue[0]
if head.day <= i or head.apple == 0:
pq.get()
continue
else:
head.apple -= 1
count += 1
break
i += 1
return countPython内置库中的queue.PriorityQueue的使用
基本操作
queue.PriorityQueue类主要
有方法如下:
- put:入队
- get:出队
- qsize:获取优先队列存储的元素个数
有属性如下:
- queue:获取优先队列底层堆结构对应的数组,常用于获取最值,而不取出
上面几个方法和属性的含义,可以参考前面实现优先队列的代码。
多条件优先级实现
加入优先队列的元素的优先级可能是多条件的,什么意思呢?
比如一个班级若干个学生,然后要从这些学生中选出一个综合素质最好的学生,条件如下:
- 文化课成绩越高,综合素质越高
- 如果文化课成绩相同,则体育成绩越高,综合素质越高
此时我们如何依赖于queue.PriorityQueue来从这些学生中选择最高综合素质的学生呢?

此时我们可以将加入优先队列的元素设计为一个类,然后将该类的对象加入优先队列。
而对象之间的大小比较,可以基于类定义的__lt__魔术方法实现,__lt__魔术方法可以实现同一个类的两个对象基于比较运算符进行大小比较。
此时优先队列中元素的多条件优先级,就变成了单条件优先级,即元素本身就是优先级。
Python内置库中的heapq
heapq的常用操作
- heappush
- heappop

我们可以发现,上面代码中,
- heapq将我们自定义的pq列表当成了容器,类似于queue.PrioirtyQueue的queue属性。
- heapq.heappush操作,类似于queue.PrioirtyQueue的put操作
- heapq.heappop操作,类似于queue.PriorityQueue的get操作
基于heapq实现一个优先队列类
因此,我们完全可以基于heapq来实现一个PriorityQueue,实现如下
import heapq
# 小顶堆优先队列
class PriorityQueue:
def __init__(self):
self.queue = []
# 获取优先队列中元素个数
def qsize(self):
return len(self.queue)
# 入队
def put(self, ele):
heapq.heappush(self.queue, ele)
# 出队
def get(self):
return heapq.heappop(self.queue)