Join关联操作
背景
在实际的数据库应用中,我们经常需要从多个数据表中读取数据,这时就可以使用SQL语句中的连接(JOIN),在两个或者多个数据表中查询数据。在使用MapReduce框架进行数据查询的过程中,也会涉及到从多个数据集中读取数据,进行Join关联操作,只不过此时需要使用Java代码并根据MapReduce的编程规范实现这个业务。
由于MapReduce的分布式设计理念,对于MapReduce实现Join操作具备了一定的特殊性。特殊性主要体现于:==究竟在MapReduce的什么阶段进行数据集的关联操作?==是mapper阶段还是reduce阶段,之间的区别又是什么?
基于此,整个MapReduce的join可以分为两个阶段:Map阶段进行合并(Map Side Join ),Reduce阶段进行合并(Reduce Side Join)
Reduce阶段进行关联操作 Reduce Side Join
reduce side join ,顾名思义,就是在Reduce阶段进行关联操作,这是最容易想到和实现的join方式,因为通过shuffle过程就可以将相关的数据分到相同的分组中,这将为后面的join操作提供了便捷。
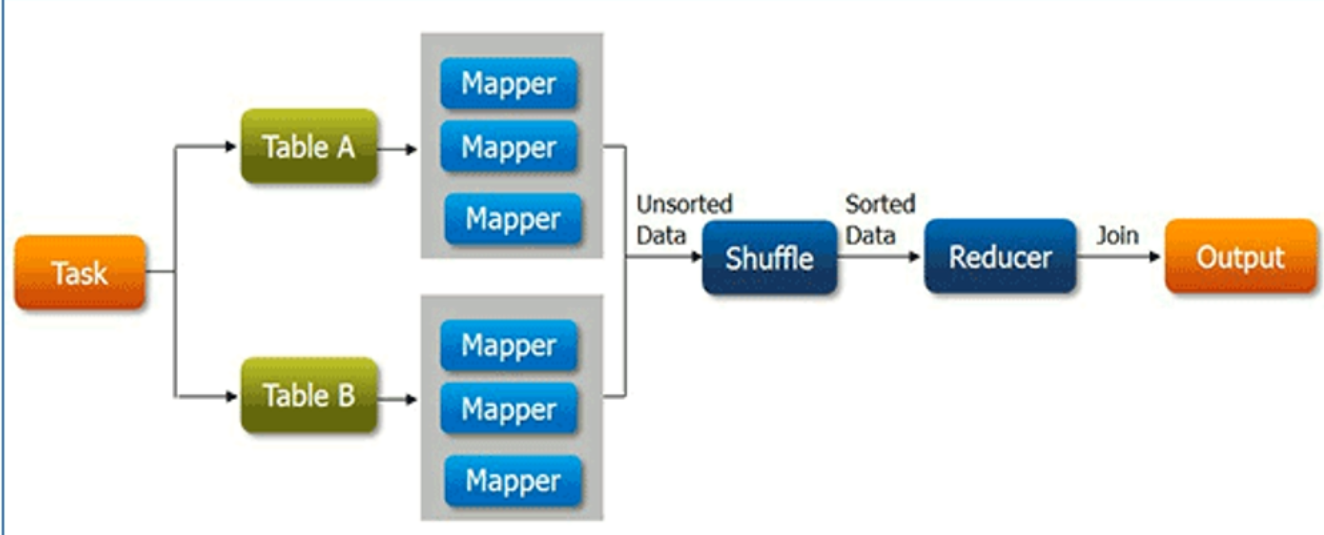
弊端
reduce端join的最大问题就是整个join操作都是在reduce阶段完成的,但是通常情况下,reduce的并行度是极小的(默认是1),这就使得所有的数据都挤压到reduce阶段处理,压力颇大,虽然说可以设置reduce的并行度,但是优惠导致最终结果被分散到多个不同的文件中。并且数据从mapper到reduce的过程中,shuffle阶段十分繁琐,数据集打的时候成本极高
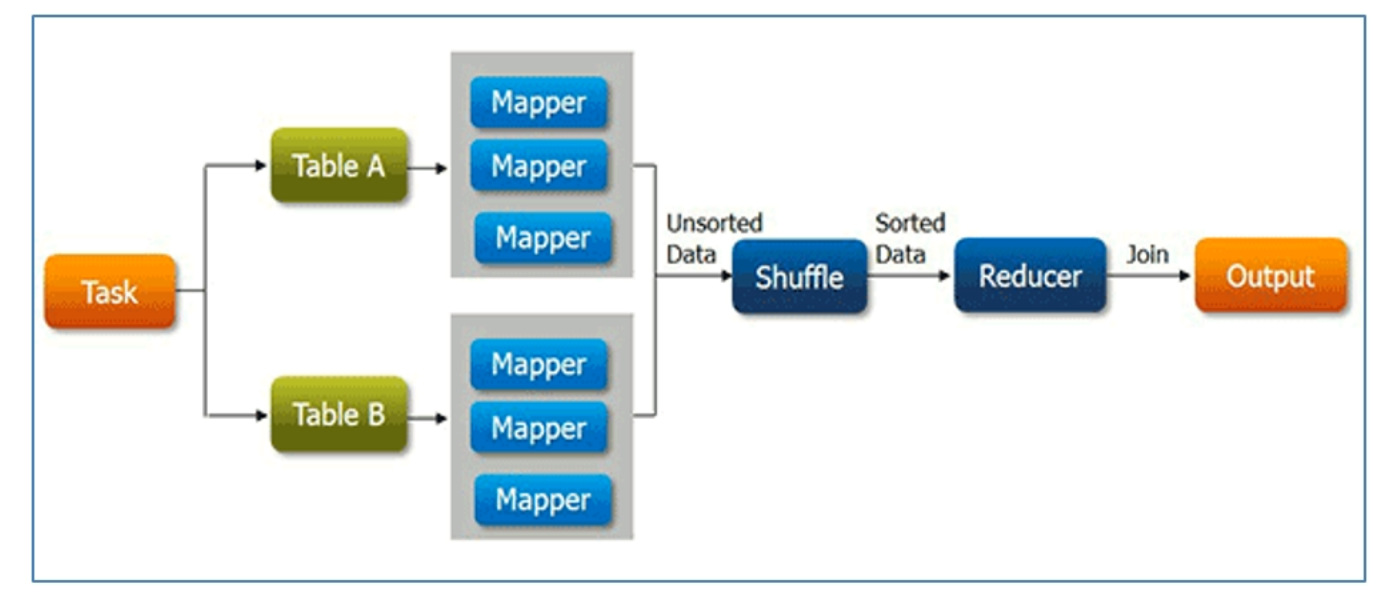
在这里进行一个实验
合并订单数据
数据集阿里云盘分享 (aliyundrive.com)
思路
在这里合并的是两个文本文件,两个文本一个是商品信息,一个是订单信息,二者通过商品编号进行关联,
此外两个文件在同一个文件夹下,那么读取的时候就需要解决一个问题: 如何去问两个文件?两个文件读取后交给Reduce如何解决?
- 读取文件可以通过setup方法来获取文件名,通过文件名进行区分
- 在这里数据量比较小,可以直接使用字符串来进行,在使用字符串的时候可以在前缀添加一个能够区分的字符,在Reduce中先将字符给取出来
Mapper
package MapReduceTest.join.reduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @author wxk
* @date 2023/04/20/8:09
*/
public class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, Text> {
String fileName;
Text outKey = new Text();
Text outValue = new Text();
StringBuilder sb = new StringBuilder();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
//获取文件名
fileName = split.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//清空内容
sb.setLength(0);
String[] split = value.toString().split("\\|");
//订单
if ("orders.txt".equals(fileName)) {
outKey.set(split[1]);
sb.append(split[0]).append("\t").append(split[2]);
//为了更好的分辨,在前缀上加入文件名
outValue.set(sb.insert(0, "orders@").toString());
} else {
outKey.set(split[0]);
sb.append(split[1]).append("\t").append(split[2]);
outValue.set(sb.insert(0, "goods@").toString());
}
context.write(outKey,outValue);
//数据写出
}
}
Reduce
package MapReduceTest.join.reduce;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @author wxk
* @date 2023/04/20/16:37
*/
public class ReduceJoinReduce extends Reducer<Text, Text, Text, Text> {
List<String> goodsList = new ArrayList<>();
List<String> ordersList = new ArrayList<>();
Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
String[] s = value.toString().split("@");
System.out.println("==="+s[1]);
if ("orders".equals(s[0])) {
//是以orders@开头,表明是orders数据
// System.out.println("==="+s[1]);
ordersList.add(s[1]);
} else {
goodsList.add(s[1]);
}
}
int goodS = goodsList.size();
int orderS= ordersList.size();
for( int i = 0;i< goodS;i++){
for( int j = 0;j < orderS;j++){
outValue.set(ordersList.get(j)+ "\t"+goodsList.get(i) );
context.write(key,outValue);
}
}
goodsList.clear();
ordersList.clear();
}
}
Driver
package MapReduceTest.join.reduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author wxk
* @date 2023/04/20/16:50
*/
public class ReduceJoinDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, ReduceJoinDriver.class.getSimpleName());
//设置Mapper驱动
job.setMapperClass(ReduceJoinMapper.class);
//设置驱动
job.setJarByClass(ReduceJoinDriver.class);
//设置Mapper输出Key的类型
job.setMapOutputKeyClass(Text.class);
//设置Mapper输出Value的类型
job.setMapOutputValueClass(Text.class);
//设置Reduce
job.setReducerClass(ReduceJoinReduce.class);
//设置Reduce输出的Key的类型
job.setOutputKeyClass(Text.class);
//设置Reduce输出Value的类型
job.setOutputValueClass(Text.class);
//设置输入路径
FileInputFormat.setInputPaths(job,new Path("E:/MapReduceTest/JoinTest"));
//设置输出格式
FileOutputFormat.setOutputPath(job,new Path("E:/MapReduceTest/JoinTestOut"));
boolean b = job.waitForCompletion(true);
System.out.println(b ? 0: 1);
}
}
运行结果如下:

他这个是根据商品ID进行排序的,但是我们像根据订单编号进行排序
排序
package MapReduceTest.join.reduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author wxk
* @date 2023/04/22/8:51
*/
public class ReduceJoinSort {
public static class ReduceJoinSortMapper extends Mapper<LongWritable,Text,Text, Text>{
Text outKey= new Text();
Text outValue=new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] item = value.toString().split("\t");
//设置订单编号为key
outKey.set(item[1]);
//订单编号 商品ID 商品编码 商品名称
outValue.set(item[1]+ "\t" + item[0]+ "\t"+ item[3] +"\t"+item[4] + "\t" + item[2]);
context.write(outKey,outValue);
}
}
public static class ReduceJoinSortReduce extends Reducer<Text,Text, NullWritable,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for(Text value :values){
context.write(NullWritable.get(),value);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, ReduceJoinDriver.class.getSimpleName());
//设置Mapper驱动
job.setMapperClass(ReduceJoinSortMapper.class);
//设置驱动
job.setJarByClass(ReduceJoinSort.class);
//设置Mapper输出Key的类型
job.setMapOutputKeyClass(Text.class);
//设置Mapper输出Value的类型
job.setMapOutputValueClass(Text.class);
//设置Reduce
job.setReducerClass(ReduceJoinSortReduce.class);
//设置Reduce输出的Key的类型
job.setOutputKeyClass(NullWritable.class);
//设置Reduce输出Value的类型
job.setOutputValueClass(Text.class);
//设置输入路径
FileInputFormat.setInputPaths(job,new Path("E:/MapReduceTest/JoinTestOut"));
//设置输出格式
FileOutputFormat.setOutputPath(job,new Path("E:/MapReduceTest/JoinTestSortOut"));
boolean b = job.waitForCompletion(true);
System.out.println(b ? 0: 1);
}
}
由于逻辑相对比较简单,就将三个合二为一,以下是输出结果,看起来相对有序点。 确信.jpg