目录
前端路由和History API
浏览文境(Browser Context)
会话历史(Session History)
History API
history.go()切换当前会话,并不改变会话栈
history.back() === history.go(-1) & history.forward() === history.go(1)
pushState(state,title,url)
replaceState(state, title, url)
实战服务端路由(做个负载均衡)
实战前端路由(单页面)
前端路由和History API
浏览文境(Browser Context)
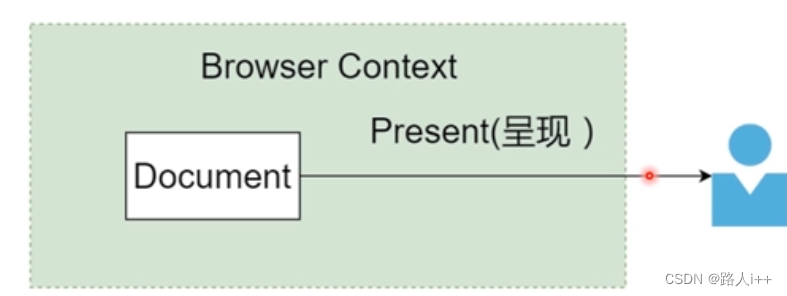
document文档
Browser Context (浏览的网页,网址等---浏览器的上下文)(共享的知识)
程序Present呈现出我们看到的网页效果
会话历史(Session History)
浏览器的会话栈Session Stack
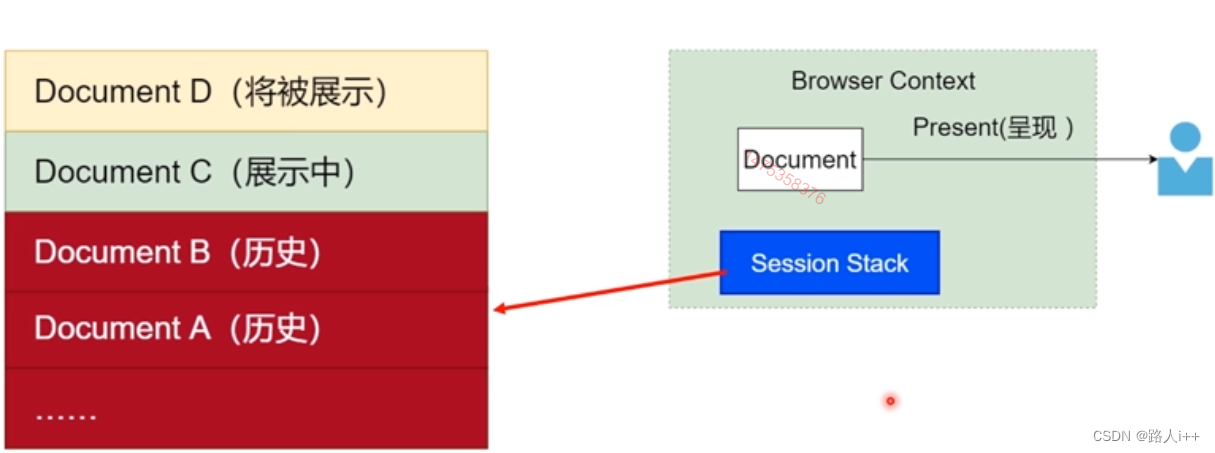
History API
提供操作控制浏览器会话历史,维护会话栈(Session stack)的能力
history.go()切换当前会话,并不改变会话栈
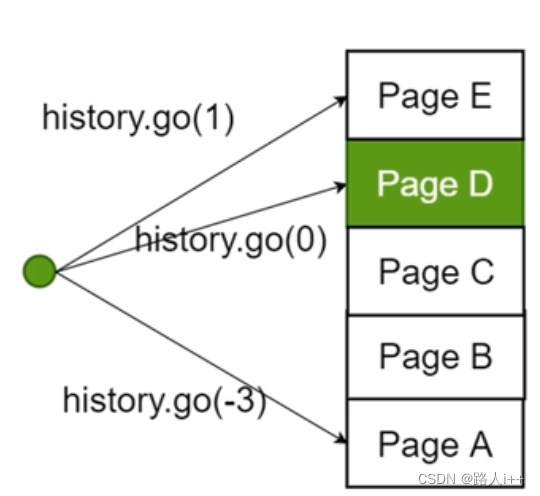
history.back() === history.go(-1) & history.forward() === history.go(1)
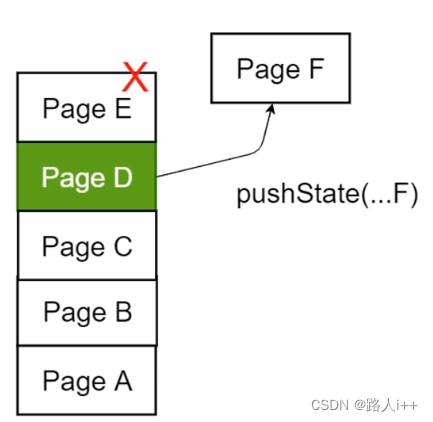
pushState(state,title,url)
压栈,从当前会话栈前往新产生路径
不发生跳转、刷新页面、后退/前进到一个pushState出来的路径也不会渲染,让前端渲染
新增一个状态(State)到会话栈(Session Stack)
- state:状态数据(自定义),可以通过history.state获取
- title:预留字段,多数浏览器不使用
- url:新状态的URL
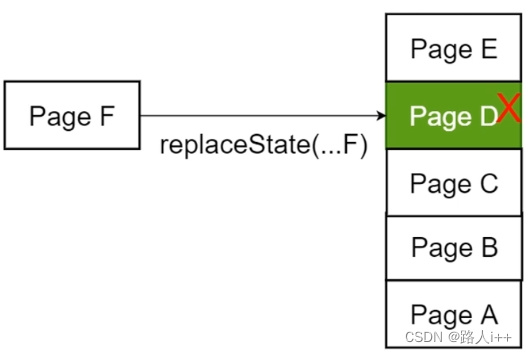
replaceState(state, title, url)
替换当前页面路径
替换会话栈(Session Stack)中当前的状态
- state:状态数据(自定义),可以通过history.state获取
- title:预留字段,多数浏览器不使用
- url:新状态的URL
实战服务端路由(做个负载均衡)
- 观察node.js实现服务端路由
- 观察用Cluster启动多个实例进行负载均衡
const app = require('express')()
const fs = require('fs')
const path = require('path')
const pageDir = path.resolve(__dirname, "pages")//解析绝对路径, __dirname当前文件相对目录,文件夹
const htmls = fs.readdirSync(pageDir)// 读取目录下所有文件s
function displayHtmlFile(name) { // 写一个函数去显示,
return (req, res) => {
const filePath = path.resolve(pageDir, name + ".html") // 找到文件
res.sendFile(filePath)// 返回文件
}
}
htmls.forEach(file => { // 路由架构
const [name, ext] = file.split('.')// 拿到文件名.扩展名
app.get('/' + name, displayHtmlFile(name))
})
app.listen(3000)// 负载均衡
const cluster = require('cluster');// 集群
const numCPUs = require('os').cpus().length; // 我的机器上有多少CPU核心
const express = require('express')
if (cluster.isMaster) {// 判断进程是在主进程
console.log(`Master ${process.pid} is running`);// pid 进程id
// Fork workers.
for (let i = 0; i < numCPUs - 1; i++) {
cluster.fork(); // 再执行一次本文件
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {// 从进程
// Workers can share any TCP connection
// In this case it is an HTTP server
const app = new express()
// 此时express提供负载均衡,是操作系统层面提供的;
// TCP层面开始分流,流量平均打到8080端口上
// 可以加1级缓存,2级缓存,3级缓存
app.listen(8080)
console.log(`Worker ${process.pid} started`);
}
// 父进程和子进程是平等的/平行的,父进程关了不一定会关子进程
// 组织形式上有父子关系,Master父,Worker子,内部有一定的联系实战前端路由(单页面)
前端路由配合服务端路由的使用
- 在node端实现wildcard路由/product/*
- 前端解析/product/:id和/product/list形成单页面应用
// 服务端node
const app = require('express')()
const path = require('path')
const { reset } = require('nodemon')
const htmlFile = path.resolve(__dirname, "pages/spa.html")// 多路由都指向单页面渲染的同一html
// /proucts /product/123 ->
app.get(/\/product(s|\/\d+)/, (req, res) => {// /d+数字
res.sendFile(htmlFile)// 返回文件
})
app.listen(3000)
// html
<!DOCTYPE html>
<html>
<head>
<style>
a {
color: skyblue;
cursor: pointer;
}
</style>
</head>
<body>
<h2>单页面应用示例</h2>
<div id='content'>渲染内容区</div>
<ul>
<li><a onclick='route("/products")'>列表</a></li>
<li><a onclick='route("/product/123")'>详情</a></li>
</ul>
<script>
function pageList() {
const html = `
<ul>
<li>Apple</li>
<li>TicTok</li>
<li>Alibaba</li>
</ul>
`
document.getElementById('content')
.innerHTML = html
}
function pageDetail() {
document.getElementById('content')
.innerHTML = "DETAIL"
}
function route(path) { // 单页面跳转
history.pushState(null, null, path)
matchRoute(pages, window.location.href) // 渲染
}
const pages = [// 路由列表
{
match: /\/products/,// 路由匹配
route: pageList // 调用函数
},
{
match: /\/product\/\d+/,
route: pageDetail
}
]
function matchRoute(pages, href) { // 路由匹配
const page = pages.find(page => page.match.test(href))
page.route()
}
window.onpopstate = function () { // 监听单页面应用浏览器前进后退,增加渲染,和history api是一组的
matchRoute(pages, window.location.href)
}
matchRoute(pages, window.location.href)
</script>
</body>
</html>



![[论文阅读] (29)李沐老师视频学习——2.研究的艺术·找问题和明白问题的重要性](https://img-blog.csdnimg.cn/4d4a9a2edc814a68bfb40eac06927424.png#pic_center)



![[架构之路-171]-《软考-系统分析师》-5-数据库系统-4- 数 据 库 的 控 制 功 能(并发控制、性能优化)](https://img-blog.csdnimg.cn/efa475c85161475a98075dadf5fd54d2.png)