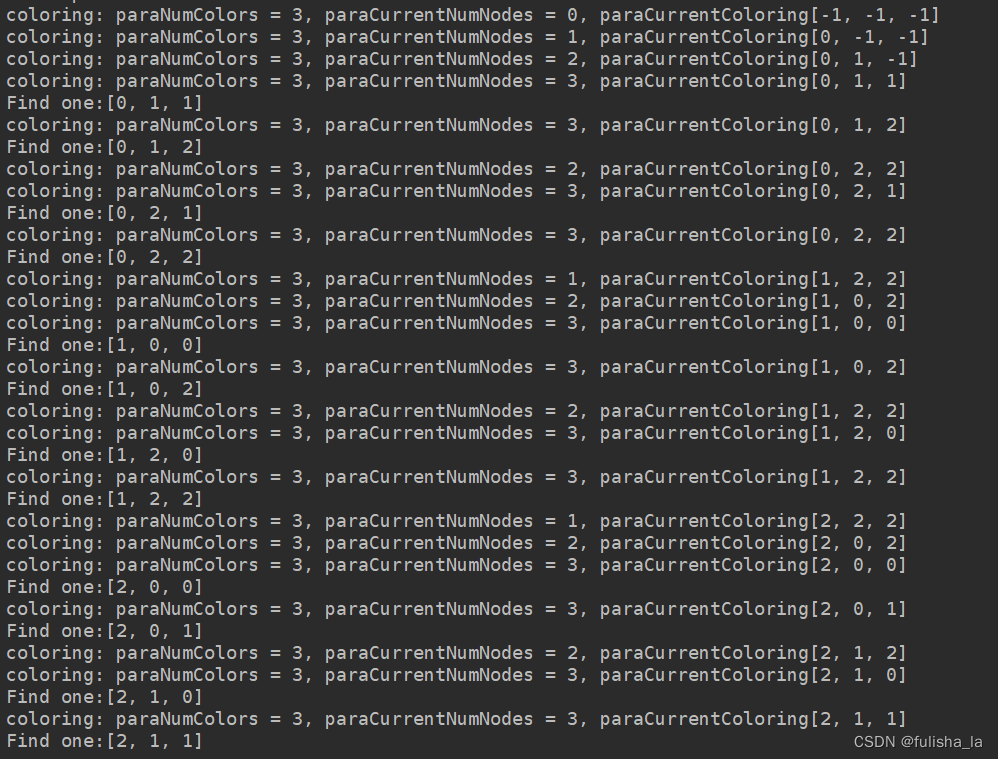
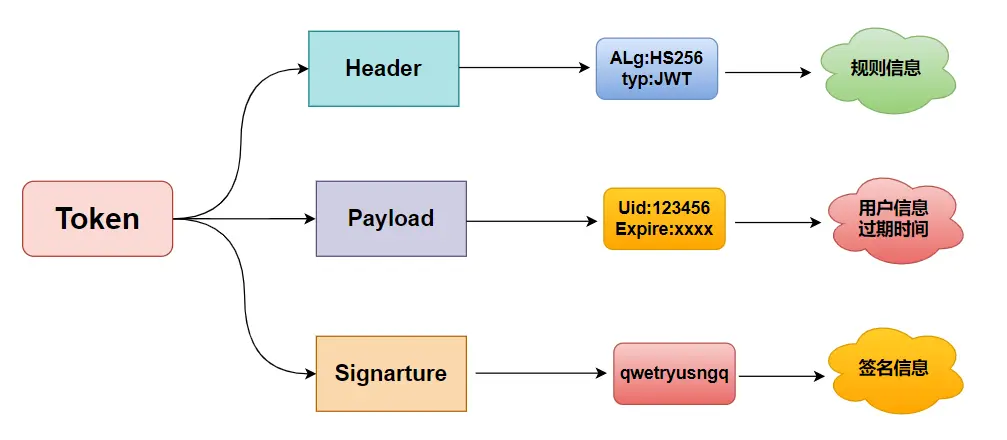
看图识文
- 介绍
- 示例一
- 示例二
- 示例三
- 示例四
- 示例五
- 示例六
介绍
该库用于识别并获取图片上的文字,支持多种语言。对英文识别度非常高,但是对中文的识别度非常一般。需要单独训练对应的中文库。对白纸黑字的合同文识别度还不错,其他的都不太好。
git地址:
https://github.com/naptha/tesseract.js
下面通过6个小例子来看下用法。使用的时候需要开个服务,在vscode上打开Go Live就行。
示例一
demo1.png

demo1.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
p {
width: 300px;
}
</style>
</head>
<body>
<!-- 识别纯英文文字的图片 ok -->
<p id="log"></p>
<!-- v4 -->
<script src='https://unpkg.com/tesseract.js@4.0.2/dist/tesseract.min.js'></script>
<script>
Tesseract.recognize(
'./images/demo1.png', // 被识别的图片
'eng', // 识别图片中文字用到的语言
{ logger: m => console.log(m) }
).then(({ data: { text } }) => {
document.getElementById('log').innerHTML = text;
})
</script>
</body>
</html>
识别结果:

示例二
demo2.png
```demo2.html`
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<!-- 识别一个纯英文截图 ok -->
<p id="log"></p>
<!-- v4 -->
<script src='https://unpkg.com/tesseract.js@4.0.2/dist/tesseract.min.js'></script>
<script>
const { createWorker } = Tesseract;
async function demo2() {
const worker = await createWorker({
logger: m => console.log(m)
});
work();
async function work() {
await worker.loadLanguage('eng'); // 下载语言包
await worker.initialize('eng'); // 使用的语言
const { data: { text } } = await worker.recognize('./images/demo2.png');
document.getElementById('log').innerHTML = text;
await worker.terminate();
}
}
demo2();
</script>
</body>
</html>
识别结果:

示例三
demo3.png

demo3.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<!-- 识别一张打印版中文合同图片 ok -->
<!-- 该图片的截图也ok -->
<!-- v4 -->
<script src='https://unpkg.com/tesseract.js@4.0.2/dist/tesseract.min.js'></script>
<script>
const { createWorker } = Tesseract;
async function demo2() {
const worker = await createWorker({
logger: m => console.log(m)
});
work();
async function work() {
await worker.loadLanguage('chi_sim'); // 下载简体中文语言包
await worker.initialize('chi_sim'); // 使用简体中文
const { data: { text } } = await worker.recognize('./images/demo3.png');
console.log(text);
await worker.terminate();
}
}
demo2();
</script>
</body>
</html>
识别结果:

很棒,识别出来了。
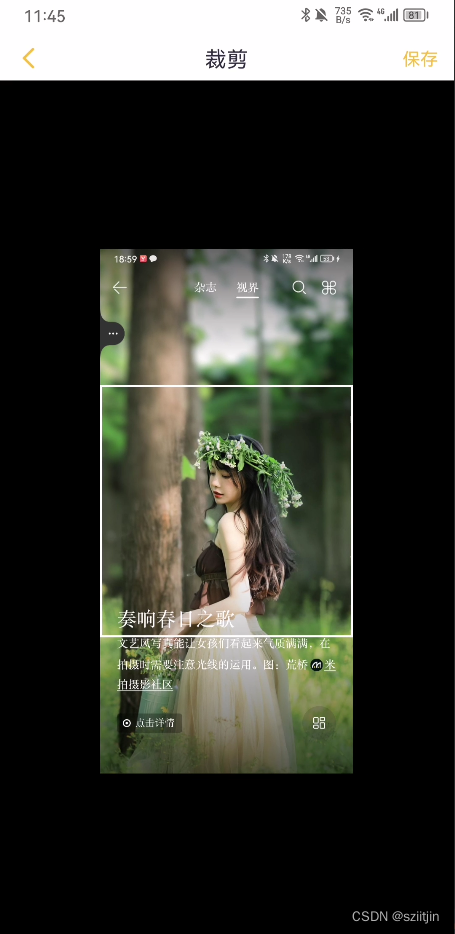
示例四
demo4.png
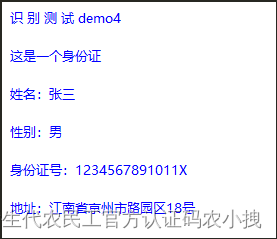
自己写一串文字,然后截图,识别一下试试。
demo.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<!-- 浏览器字体 no -->
<p id="log"></p>
<!-- v4 -->
<script src='https://unpkg.com/tesseract.js@4.0.2/dist/tesseract.min.js'></script>
<script>
const { createWorker } = Tesseract;
async function demo2() {
const worker = await createWorker({
logger: m => console.log(m)
});
work();
async function work() {
await worker.loadLanguage('chi_sim');
await worker.initialize('chi_sim');
const { data: { text } } = await worker.recognize('./images/demo4.png');
console.log(text);
document.getElementById('log').innerHTML = text;
await worker.terminate();
}
}
demo2();
</script>
</body>
</html>
识别结果:
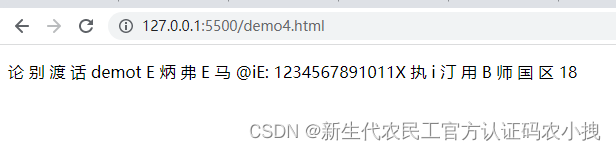
很拉跨,基本没识别出来。。。
示例五
demo5.png

试试识别身份证,这么大的字,这么清晰的像素
demo5.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<p id="log"></p>
<!-- v4 -->
<script src='https://unpkg.com/tesseract.js@4.0.2/dist/tesseract.min.js'></script>
<script>
const { createWorker } = Tesseract;
async function demo2() {
const worker = await createWorker({
logger: m => console.log(m)
});
work();
async function work() {
await worker.loadLanguage('chi_sim');
await worker.initialize('chi_sim');
const { data: { text } } = await worker.recognize('./images/demo5.png');
document.getElementById('log').innerHTML = text;
await worker.terminate();
}
}
demo2();
</script>
</body>
</html>
识别结果:
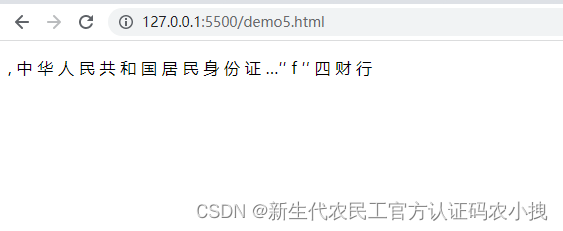
识别出来了,但是会受到其他因素的干扰。
示例六
demo6.png

识别几个艺术字试试
demo6.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<p id="log"></p>
<!-- v4 -->
<script src='https://unpkg.com/tesseract.js@4.0.2/dist/tesseract.min.js'></script>
<script>
const { createWorker } = Tesseract;
async function demo2() {
const worker = await createWorker({
logger: m => console.log(m)
});
work();
async function work() {
await worker.loadLanguage('chi_sim');
await worker.initialize('chi_sim');
const { data: { text } } = await worker.recognize('./images/demo6.png');
document.getElementById('log').innerHTML = text;
await worker.terminate();
}
}
demo2();
</script>
</body>
</html>
识别结果:
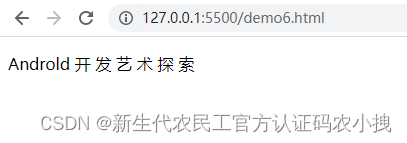
哎哟,不错哦,就是不那么完美,英文字母的拼写有一丢丢小问题。
实际开发中需要对使用过程进行优化,以及字库的训练。或者使用阿里或百度提供的付费版服务。