Twitter近期开源了其推荐系统源码[1,2,3],截止现在已经接近36k star。但网上公开的文章都是blog[1]直译,很拗口,因此特地开个系列系统分享下。系列涵盖:
Twitter整体推荐系统架构:涵盖图数据挖掘、召回、精排、规则多样性重排、混排等。参考材料见[1,2]。
Twitter精排模型(Heavy Ranker):包含模型结构、特征工程、多目标建模、多目标融合等,看了下居然是出自新浪微博DLP-KDD 2021的工作,很强。参考材料见[3]。
Twitter图模型预训练表征(TwHIN embeddings):基于社交异构图对用户、推文做预训练,Twiiter自研TwHIN KDD 2022的工作。参考材料见[3]。
本篇文章主要先分享Twitter整体的推荐系统架构。
引言
Twitter场景下推荐系统问题定义:
输入:Twitter network,由推文、用户、交互行为等构成的超大规模异构图。
输出:预测你和推文或其他用户交互的概率,进行推文或用户的推荐。
整体问题和常见的推荐系统差别不大。特色的地方在于Twitter比较关注social graph的挖掘,包括图特征、图预训练、图召回模型等。
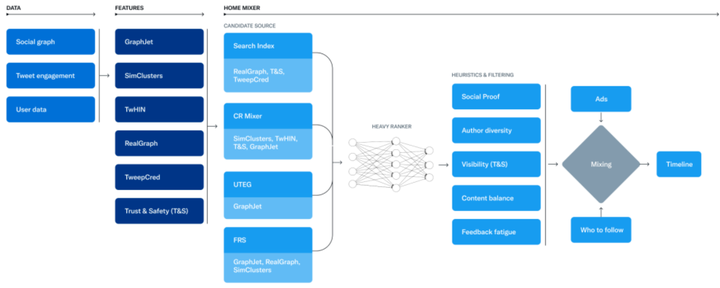
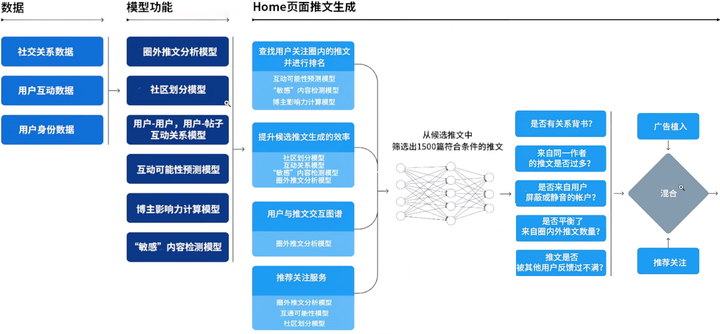
整体架构如下图,包括数据、特征工程和推荐系统服务。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑切换为居中
添加图片注释,不超过 140 字(可选)
最终Feed流还会以时间线的形式由早先到最近呈现给用户推文
数据:涵盖了社交图、用户的交互行为、用户画像数据等。数据这块是Twitter 的核心资产,由用户、推文和互动构成的超大规模异构社交图。
特征工程:Twitter主要关注社交图的预训练、聚类、社区发现等,这也是Twitter的特色所在。图预训练得到的向量可以用于向量召回、精排特征等。此外,还包括一小部分安全相关的工作。
推荐系统核心服务:Home Mixer,Twitter定制的Scala框架。可以认为是算法工程。类比国内大厂用的Java、Go、C++等。由三大部分构成:
召回:Candidate Sources,从不同的推荐源获取最好的推文,类似推荐系统的召回阶段。Candidate Retrival。核心召回路是图召回。
"Candidate Sources" 提供了候选项,而 "Candidate Retrieval" 则是从这些候选项中选出最符合需求的候选项的过程。因此,选择适当的 "Candidate Sources" 对于 "Candidate Retrieval" 的效果至关重要,因为这可以影响候选项的质量和准确性。
"Candidate Retrieval" 的意思是候选项检索。这个术语通常用于搜索和推荐系统,指的是从大量数据中检索出符合特定要求的候选项,以供进一步评估和选择。例如,在推荐系统中,候选项检索可以指从用户的浏览历史、兴趣和偏好中选出候选内容,以供推荐。
粗精排:使用机器学习模型对推文进行打分排序,Twitter分为Light Ranker和Heavy Ranker。分别类比推荐系统的粗排和精排阶段。
重排/混排:应用启发式规则,例如过滤自已屏蔽用户的推文、NSFW内容和已看到的推文;保证作者多样性等;以及负责广告、推文和作者混排等。
下面会围绕召回、粗排、精排、混排展开介绍。特征部分不单独设章节,会在召回和粗排中用到的地方介绍。
召回
Twitter有很多召回数据源,为用户召回最新、最感兴趣的相关推文。
输入:推文候选池大小,hundreds of millions 亿万级别。
输出:两类召回通道:你关注的用户圈(in-network)、你未关注的用户圈(out-of-network),整体上,二者比例是55开,即召回一半你关注用户的推文、一半你未关注的用户的推文。当然,不同用户召回的配比会不一样。
In-Network召回
主召回路,也是最大的候选推文来源,目标是从你关注的作者推文中,检索出最新、你最可能感兴趣的推文给你,能贡献 50% 的推文来源。使用自研搜索引擎Earlybird[6],检索你关注的人的推文,本质是个倒排索引。只不过索引里检索到的推文要过一个Light ranker海选粗排模型进行该召回路的截断,放在下文的粗排章节中介绍。
Out-of-Network 召回
在用户关注圈子之外寻找相关的推文推荐给用户。Twitter采取了两类召回方法:
UserTweetEntityGraph (UTEG):协同过滤。通过分析你关注的人或有相似兴趣的人的行为,来预测你感兴趣的相关推文,比如,二跳关系U2U2I,为了实现高效动态图构造和游走,内部自研了GraphJet[5]图引擎,发表在VLDB 2016上。GraphJet能够高效、动态地维护一个实时交互图(real-time interaction graph),结点为用户和推文,边为实时交互行为,并实现高效地图游走。该方法大概能涵盖 15% 的推文来源。该方法得到的召回结果也要过一个Light Ranker进行海选粗排。
"二跳关系U2U2I"是指一种用户-用户-项目(User-User-Item)的关系,用于描述推荐系统中的协同过滤过程。在这个过程中,根据你关注的人或有相似兴趣的人的行为,预测你可能感兴趣的相关推文。二跳关系是指从一个用户(User)通过关注的用户(User)找到相关的推文(Item)。这种关系可以帮助推荐系统发现更加相关和有趣的内容。
例如,假设你是用户A,你关注了用户B,而用户B关注了用户C。用户C发布了一条推文,而根据用户B和C的关系,可以预测这条推文可能对你(用户A)感兴趣。这就是一个典型的用户-用户-项目(U2U2I)的二跳关系。
Embedding Spaces:嵌入表征学习。建模更加通用的问题:你对哪些推文以及哪些作者感兴趣。表征学习目标是训练得到用户表征向量和推文表征向量,再通过计算user-user、user-tweet表征之间的相似性来预测用户兴趣。主要分为稀疏嵌入和稠密嵌入两种,前者通过聚类来做表征、后者基于图学习做预训练。
表征学习(Representation Learning),有时也称为特征学习(Feature Learning),是指通过机器学习算法自动学习和提取数据的有用特征或表示。这种学习方法的目的是将原始数据转化为更易于处理和理解的形式,从而提高机器学习模型的性能。在推荐系统中,表征学习的目标是学习用户和推文的表征向量,这些向量可以捕捉用户的兴趣和推文的相关性。
表征学习可以用于预测用户对推文和作者的兴趣。通过训练得到用户表征向量和推文表征向量,然后计算这些向量之间的相似性,从而预测用户对某个推文或作者的兴趣。
表征学习主要分为稀疏嵌入和稠密嵌入两种:
稀疏嵌入(Sparse Embedding):这种方法通常使用聚类(Clustering)技术来学习数据的表征。在这种方法中,每个用户或推文可以用一个高维、稀疏的向量来表示,其中每个维度对应一个聚类。
稠密嵌入(Dense Embedding):这种方法通常基于图学习(Graph Learning)来进行预训练。在这种方法中,每个用户或推文可以用一个低维、稠密的向量来表示。图学习算法可以捕捉用户和推文之间的复杂关系,并将这些关系嵌入到向量中。
稀疏嵌入和稠密嵌入是两种不同的数据表征方法,用于将非结构化数据(如用户或推文)转换为能被机器学习算法处理的向量形式。这两种方法在表示数据时,采用了不同的维度和密度。
稀疏嵌入(Sparse Embedding):顾名思义,稀疏嵌入是一种将数据表示为高维但稀疏的向量。稀疏向量中的大部分元素都是0,只有少数元素是非零值。这种方法通常使用聚类技术来学习数据的表征。例如,假设我们有一组用户,我们可以根据用户的兴趣、年龄、地域等特征对他们进行聚类。然后,每个用户可以用一个高维向量表示,向量中的每个维度对应一个聚类。如果用户属于某个聚类,则该维度的值为1,否则为0。这样,大部分维度的值都是0,形成稀疏向量。
稠密嵌入(Dense Embedding):与稀疏嵌入相反,稠密嵌入将数据表示为低维但稠密的向量。这意味着向量中的大部分元素都是非零值。这种方法通常基于图学习来进行预训练。例如,我们可以将用户和推文之间的关系构建成一个图,然后通过图学习算法来学习这个图的表征。图学习算法可以捕捉用户和推文之间的复杂关系,并将这些关系嵌入到向量中。这样,每个用户或推文都可以用一个低维、稠密的向量来表示。
稀疏嵌入:优点:
可解释性强:稀疏嵌入中的每个维度对应一个聚类,这使得结果更容易理解和解释,有助于分析数据和挖掘有用的信息。
压缩性:由于向量中的大部分元素为零,可以使用压缩技术(如稀疏矩阵存储)来减少存储空间和计算资源的需求。
缺点:
计算效率低:由于向量的高维性,稀疏嵌入在计算时可能会比较耗时。
泛化能力较差:稀疏嵌入容易受到离群点的影响,可能导致泛化能力较差,无法在未知数据上获得良好的性能。
稠密嵌入:优点:
计算效率高:由于向量的低维性,稠密嵌入在计算时具有较高的效率。
泛化能力强:稠密嵌入能够捕捉数据之间的复杂关系,具有较好的泛化能力,能在未知数据上获得较好的性能。
缺点:
可解释性差:稠密嵌入的维度不直接对应具体的特征或类别,这使得结果较难理解和解释。
存储空间需求大:由于向量中的大部分元素都是非零值,稠密嵌入需要更多的存储空间来存储向量。
SimClusters是一种基于社区发现的稀疏嵌入方法,它被提出并发表在2020年的KDD会议上。这种方法主要用于异构表征模型,通过矩阵分解算法,根据社交图谱(social graph)中有影响力的用户进行社区发现。社区发现是一种寻找社交网络中具有相似特征或行为的用户群体的过程。
SimClusters方法首先根据用户的流行度和行为将推文和用户划分到不同的空间中。在该模型中,共有约14.5万个社区,每3周更新一次。这些社区有的较大,有的较小,一个用户可以同时属于多个社区。
此外,每个推文都可以通过社区进行嵌入,用推文在每个社区的流行度作为表征值。通过这种方式,可以计算用户和推文之间的相似性,并将其用于召回推荐。
简而言之,SimClusters是一种利用社区发现对用户和推文进行嵌入的方法,便于计算相似性并提高推荐系统的性能。
稀疏嵌入:最有用的表征模型是SimClusters[7],发表在KDD 2020上,基于社区发现的异构表征模型,利用矩阵分解算法,基于social graph中有影响力的用户进行社区发现,并根据流行度和用户行为将推文和用户划分到不同空间中。一共有14.5W个社区,每3周更新一次,社区有的很大,有的很小,一个用户可以属于多个社区;每个推文也可以用社区来做嵌入,用推文在每个社区的流行度作为表征值。这样就能够计算用户和推文的相似性并用于召回,社区形如:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
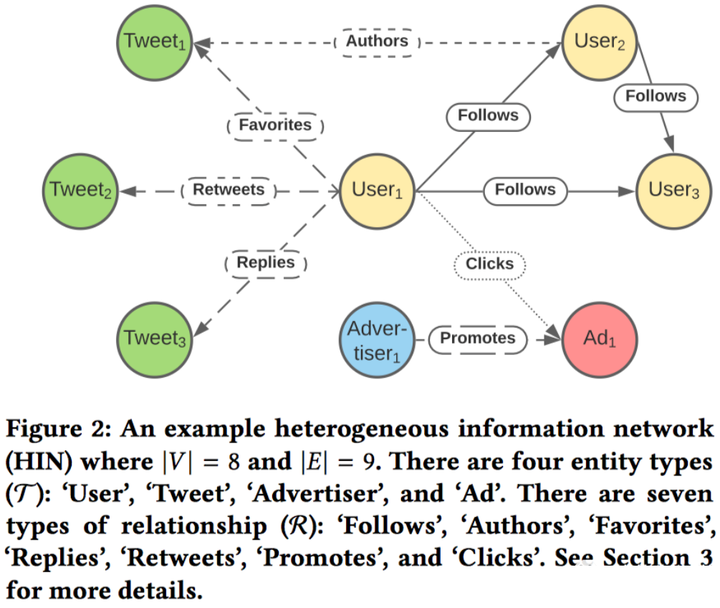
稠密嵌入:使用TwHIN[8]做user、twitter的稠密嵌入表征。异构图如下图所示,得到的稠密表征计算相似度就可以用于图召回。这个部分源码开源在the-algorithm-ml中,参见[3]。下次会在系列3中进行分享。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图2:一个异构信息网络(HIN)的例子,其中V = 8,E = 9。
有四种实体类型(T):用户,推文,广告主和广告。
有七种关系类型(R):关注,作者,收藏,回复,转发,推广和点击。更多细节请参见第3节。
源信号抽取(Source Signal Extraction,SSE)是一种信号处理技术,主要用于从混合信号中分离出原始信号。
在实际应用中,我们常常会遇到来自不同源的信号混合在一起的情况,这种混合信号可能包含了噪声或其他干扰成分。
源信号抽取的目标是从这些混合信号中恢复出原始信号,以便于后续的分析、处理或应用。
源信号抽取的方法有很多,其中最著名的一种是独立成分分析(Independent Component Analysis,ICA)。ICA是一种线性代数方法,通过将混合信号表示为源信号和混合矩阵的乘积,然后寻找一个逆矩阵来分离出原始信号。除了ICA之外,还有其他方法如主成分分析(Principal Component Analysis,PCA)、盲源分离(Blind Source Separation,BSS)等。
源信号抽取在许多领域都有广泛的应用,例如语音处理、生物医学信号处理、通信信号处理、图像处理等。通过源信号抽取技术,我们可以提高信号质量、消除噪声和干扰,从而更好地利用这些信号。
除此之外,还提到了CR-Mixer,是个协调层,代理执行Out-of-Network多路召回,调用底层的计算服务,包括:源信号抽取(source signal extraction), 召回结果生成(candidate generation), 过滤(filtering)和粗排(light ranker)。个人理解这个服务是在多路召回后、精排前,主要用于调用多种召回服务、多路合并和粗排。
除了推文的推荐, 还介绍了推人服务(following-recommendation-service(FRS),用于推荐作者,也是一个小的推荐系统,流程基本同主推荐系统,包括召回,排序,过滤,推荐理由,排序主要预测关注概率以及关注后进作者主页正向交互的概率,二者加权融合。
Twitter召回的核心组件:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
粗排
本质是个引擎侧召回通道的海选粗排。包括2个,1个是Early Bird的in-network召回后海选粗排模型、1个是UTEG召回(GraphJet图游走)后的海选粗排模型,二者差异不大,只是特征不一样。
Twitter的海选粗排是个很老的LR模型,预测用户会交互twitter的概率,这个模型内部正准备重构。整体架构如下所示:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
LR的特征涵盖了用户侧特征(tweepcred: pagerank做声誉预估,粉丝数等)、tweet特征(包括静态文本质量、实时转发、回复、关注等)以及上下文特征(用户语言)。
对交互正样本会做加权损失训练,比如:点击的权重为1,点赞的权重为2等。
INDEX_BY_LABEL = {
"is_clicked": 1,
"is_favorited": 2,
"is_open_linked": 3,
"is_photo_expanded": 4,
"is_profile_clicked": 5,
"is_replied": 6,
"is_retweeted": 7,
"is_video_playback_50": 8
}
事件标签 点击、收藏、打开链接、展开照片、点击个人资料、回复、转发、视频播放50%
在blog[1]中提到in-network召回的粗排模型用到了RealGraph,出自Twitter在KDD 2014自研的工作:RealGraph: User Interaction Prediction at Twitter[4],本质是个LR逻辑回归模型,但预测是用户和用户的交互概率:
输入:RealGraph是一个有向带权同构graph,节点是Twitter的用户、边是用户与用户的交互关系。由历史行为构成。
输出:目标是预测用户和用户交互的概率,本质是个链接预测的任务。
模型:会基于RealGraph以及边的特征,使用逻辑回归模型来训练,并预测交互概率。
用法:基于预测得到的交互概率,交互概率越高的用户,其推文就会更多地推荐给你。
这个地方和github的代码里的real-graph对应不起来,有点出路。个人感觉可能real-graph得到的user-user probability一方面可以用于推人服务的粗排,另一方面也可以作为user-author of twitter的交叉特征,作为LR粗排模型的输入。
这块特征工程可以研究下,可能有一些实践经验收获。
看起来Twitter没有专门建设多路召回合并后的粗排模型。推测Twitter的架构中,核心召回路in-network、out-network过海选粗排模型,各挑选750个结果,一共1500个结果进精排。
精排
parallel masknet,出自新浪微博(tql)发表在DLP-KDD 2021上的:MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask[10]。该模型也是新浪微博在FiBiNet、GateNet、MaskNet、ContextNet等一系列精排模型中表现较好的。
Parallel MaskNet模型的主要特点是并行处理和掩码网络结构,这种结构在处理大规模稀疏数据时具有优势。下面我们详细介绍一下Parallel MaskNet模型的构成和在CTR预估场景下的应用。
模型结构:
Parallel MaskNet模型主要由以下几个部分组成:
-
Embedding Layer:模型首先将稀疏的特征数据进行embedding,将高维稀疏特征转换为低维稠密特征。这可以减少计算量,同时保留原始特征中的信息。
-
Parallel Masking:在此阶段,模型使用一种并行化的方法来处理不同的特征组。每个特征组都有一个掩码网络,通过独立并行处理,可以更高效地学习不同特征之间的关系。
-
Mask Network:掩码网络用于学习特征之间的交互关系。对于每个特征组,掩码网络通过对输入特征进行掩码操作,学习不同特征组合的重要性。 这有助于模型捕获更复杂的特征交互,从而提高预测性能。
-
Output Layer:模型将经过掩码网络处理的特征进行汇总,然后通过一个全连接层和sigmoid激活函数输出预测结果。这里的输出结果表示用户点击广告的概率。
Parallel MaskNet在CTR预估场景中的应用:
-
广告推荐:模型可以预测用户对各种广告的点击概率,从而帮助广告商为用户推荐最合适的广告内容。
-
个性化推荐:通过学习用户的行为和兴趣,模型可以预测用户对不同内容的点击概率,为用户提供更个性化的推荐。
-
优化广告投放:广告商可以根据模型预测的CTR,调整广告投放策略,以提高广告效果和投放效率。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
精排打分候选集数量1500,是个多目标模型。48M参数的神经网络实现的(有点小),该网络在推特交互数据训练,优化如点赞、转发和回复等目标,考虑了数千个特征,并输出十个Label,为每条推文打分,代表交互的概率,根据这些分数对推文进行融合排序。一共10个目标,下次会细致分享Twitter的精排模型以及源码。
"recap.engagement.is_favorited":用户喜欢推文的概率
"recap.engagement.is_good_clicked_convo_desc_favorited_or_replied":用户点击进入此推文对话并回复或点赞推文的概率
"recap.engagement.is_good_clicked_convo_desc_v2":用户点击进入此推文对话并在那里停留至少 2 分钟的概率
"recap.engagement.is_negative_feedback_v2":用户做出负面反应的概率(要求在推文或作者上“显示较少”,屏蔽或静音推文作者)
"recap.engagement.is_profile_clicked_and_profile_engaged":用户打开推文作者的概率并在作者资料进行交互
"recap.engagement.is_replied":用户回复推文的概率
"recap.engagement.is_replied_reply_engaged_by_author":用户回复推文并且该回复被推文作者参与的概率
"recap.engagement.is_report_tweet_clicked":用户点击举报推文的概率
"recap.engagement.is_retweeted":用户转发推文的概率
"recap.engagement.is_shared":用户分享推文的概率
"recap.engagement.is_tweet_detail_dwelled_15_sec":用户在推文详情页停留超过15s的概率
"recap.engagement.is_video_playback_50":用户观看至少一半视频长度的概率
预测时使用简单加权求和融合排序,看起来是手拍的。
"recap.engagement.is_favorited": 0.5
"recap.engagement.is_good_clicked_convo_desc_favorited_or_replied": 11* (the maximum prediction from these two "good click" features is used and weighted by 11, the other prediction is ignored). (从这两个“好点击”功能中选择最大预测值并乘以11进行加权,忽略另一个预测值)
"recap.engagement.is_good_clicked_convo_desc_v2": 11*
"recap.engagement.is_negative_feedback_v2": -74
"recap.engagement.is_profile_clicked_and_profile_engaged": 12
"recap.engagement.is_replied": 27
"recap.engagement.is_replied_reply_engaged_by_author": 75
"recap.engagement.is_report_tweet_clicked": -369
"recap.engagement.is_retweeted": 1
"recap.engagement.is_video_playback_50": 0.005
到此可以一览Twitter Ranking的核心组件:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
重排
主要目的是做过滤以及支持一些产品Feature,启发式规则导向:
可见性:屏蔽的推文、作者等。
作者多样性:保证作者多样性。
内容平衡:In-Network推文和Out-of-Network推文的控比。
基于反馈的疲劳内容:用户有负反馈的时候,做些干预策略。
二跳人脉过滤:排除与推文没有二级关联的out-of-network推文。不会推荐跳数过多的无关用户。专业术语是social proof。
推文以及回复:推文以及推文的回复上下文展示。
更新检测:确定当前设备上的推文是否过时,并发送指令以将其替换为编辑后的版本。
混排
负责主页混排(Homepage Mixer),包括:推文、广告、关注作者、Onboarding prompts等。

编辑
添加图片注释,不超过 140 字(可选)
上面的流程每天运行大约 50 亿次,平均完成时间不到 1.5 秒。单个管道执行需要 220 秒的 CPU 时间,几乎是在应用程序上看到的延迟的 150 倍。
到此可以一览Twitter 混排/重排的核心组件:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
基建
模型serving服务:Navi,High performance, machine learning model serving written in Rust.
Feeds信息流推荐框架:Product-mixer,Software framework for building feeds of content.
机器学习训练框架:twml,基于TF-1,即将废弃的机器学习框架,目前用于训练粗排Earlybird light ranker。
可以一览下核心基建:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
Twitter 2.0 透明新时代:A new era of transparency for Twitter
不得不说开源是个很大胆的举措,很佩服。最后我们来一睹马斯克对于twitter 2.0的愿景[11],全新篇章开启。
在 Twitter 2.0,我们相信作为互联网的城市广场,我们有责任让我们的平台透明化。因此,今天我们迈出了迈向透明新时代的第一步,并向全球社区开放了我们的大部分源代码。
在 GitHub 上,您会发现两个新的代码库(main repo、ml repo),包含了 Twitter 的许多源代码,包括我们的推荐算法,它负责分发您在 For You 时间轴上看到的推文。对于此版本,我们的目标是尽可能提高透明度,同时去掉了一些可能被不法分子利用的代码:这些代码主要用于保护用户安全和隐私、保护我们的平台免受不良行为者侵害,防止我们打击儿童性剥削和性操纵的努力被破坏。也去掉了一些广告推荐的算法。我们还采取了额外措施来确保用户安全和隐私得到保护,因此不发布与 Twitter 算法相关的训练数据或模型权重。
这是我们以这种方式变得更加透明的第一步,我们计划继续共享更多不会对 Twitter 或我们平台上的人构成重大风险的代码。
我们邀请社区提交 GitHub 问题和PR,以获取有关改进推荐算法的建议。我们正在开发工具来管理这些建议并将同步到我们内部代码库。任何安全问题或问题都可通过 HackerOne 提交给我们的官方漏洞赏金计划。我们希望受益于全球社区的集体智慧和专业知识,帮助我们发现问题并提出改进建议,最终打造更好的 Twitter。
作为互联网的城市广场,我们最终这样做是为了提高透明度并与我们的用户、客户和公众建立信任。随着我们在这一领域取得进展,我们将继续分享更新。
总结
从技术角度,Twitter开源代码提供了一个典型大型推荐系统的案例,不管是个人还是公司都能从中学习到不少东西。
从Twitter开源角度,也挺期待开源社区会如何玩转Twitter源码,能提供哪些有意思的建议和思路,能给Twitter推荐系统带来哪些变化,能否引领一种新的技术发展路线:通过开源来迭代产品,从而提高平台的用户体验。
References
[1] Twitter's Recommendation Algorithm:https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
[2] https://github.com/twitter/the-algorithm
[3] https://github.com/twitter/the-algorithm-ml
[4] KDD 2014:RealGraph: User Interaction Prediction at TwitterKDD 2014:RealGraph:Twitter 用户交互预测
[5] VLDB 2016:GraphJet: Real-Time Content Recommendations at TwitterVLDB 2016:GraphJet:Twitter 实时内容推荐
[6] EarlyBird:https://github.com/twitter/the-algorithm/blob/main/src/java/com/twitter/search/README.md
[7] KDD 2020:SimClusters: Community-Based Representations for Heterogeneous Recommendations at TwitterKDD 2020:SimClusters:Twitter 异构推荐的社区基础表示
[8] KDD 2022:TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized RecommendationKDD 2022:TwHIN:个性化推荐的 Twitter 异构信息网络嵌入
[9] CR-Mixer:https://github.com/twitter/the-algorithm/blob/main/cr-mixer/README.md
[10] DLP-KDD 2021:MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask
[11] A new era of transparency for Twitter:https://blog.twitter.com/en_us/topics/company/2023/a-new-era-of-transparency-for-twitter