本章内容
- 文章概况
- 模型结构
- 实验结果
- 长期预测
- 表征学习
- 消融实验
- 分块和通道独立性
- 不同的回顾窗口
- 总结
文章概况
《A Time Series is Worth 64 Words: Long-term Forecasting with Transformers》是2023年发表于ICLR的一篇文章。该文章借鉴了计算机视觉领域的Vision Transformer(ViT)的方法,提出了一种时序分块方法。
文章代码链接:
论文链接
代码链接
模型结构
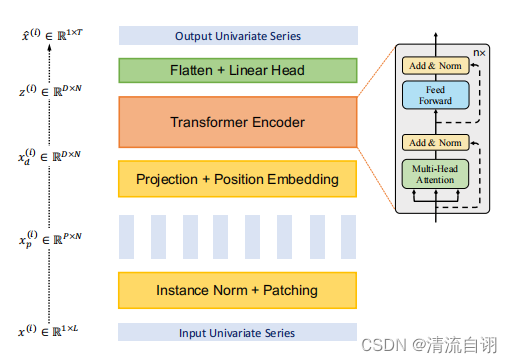
文章的标题就很眼熟,翻阅至模型结构,确认参考了ViT,两张图片对比确实很像,不同的是所解决的问题。如下面表格所示,左侧为ViT模型结构,右侧为PatchTST的Transformer主干。
| ViT | PatchTST |
|---|---|
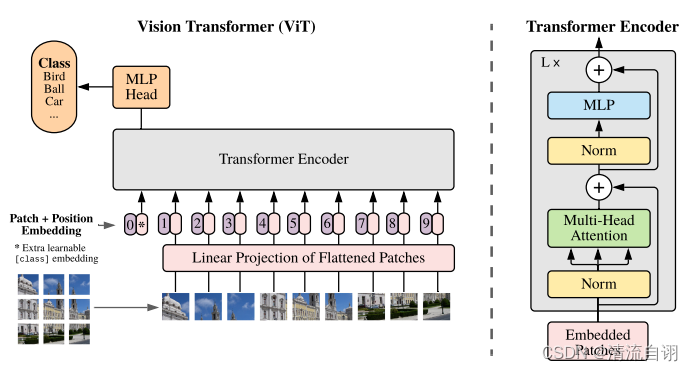 |  |
ViT的细节不做赘述,详细内容可见论文。
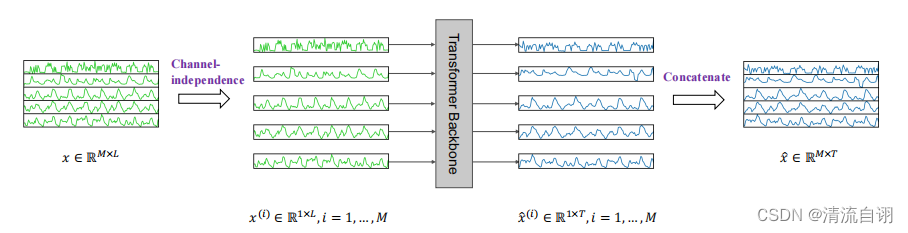
上图为PatchTST的整体结构,大致步骤如下:
1.输入多因子时序数据
2.多因子通道独立化
3.经过若干个Transformer主干后输出多因子独立通道的预测结果
4.通道拼接并输出预测数据
其中每一个Transformer主干(表格右侧)又包含如下步骤:
1.归一化(Norm)
2.分块(Patch Division)
3.语义编码(Projection)和位置编码(Position Embedding)
4.Transformer Encoder(和ViT一样,常规Transformer)
5.扁平化(Flatten)和全连接(Linear)
总体而言,和VIT相比有以下相同和不同:
相同
1.对数据进行分块
2.使用常规Transformer结构
不同
1.PatchTST对多通道数据采取的独立化操作,而包括ViT在内的多数模型通畅采用通道混合的方法
2.PatchTST在每一个Transformer主干网络处均进行了分块操作,而ViT仅在模型输入数据后采用了一次
3.在分块操作中,PatchTST借鉴ViT及其衍生模型,采用了无重合分块和有重合分块的两种方式,其中需要注意的是在数据mask重建的实验中,为避免数据泄露,只采用了无重合分块的方式。
实验结果
长期预测
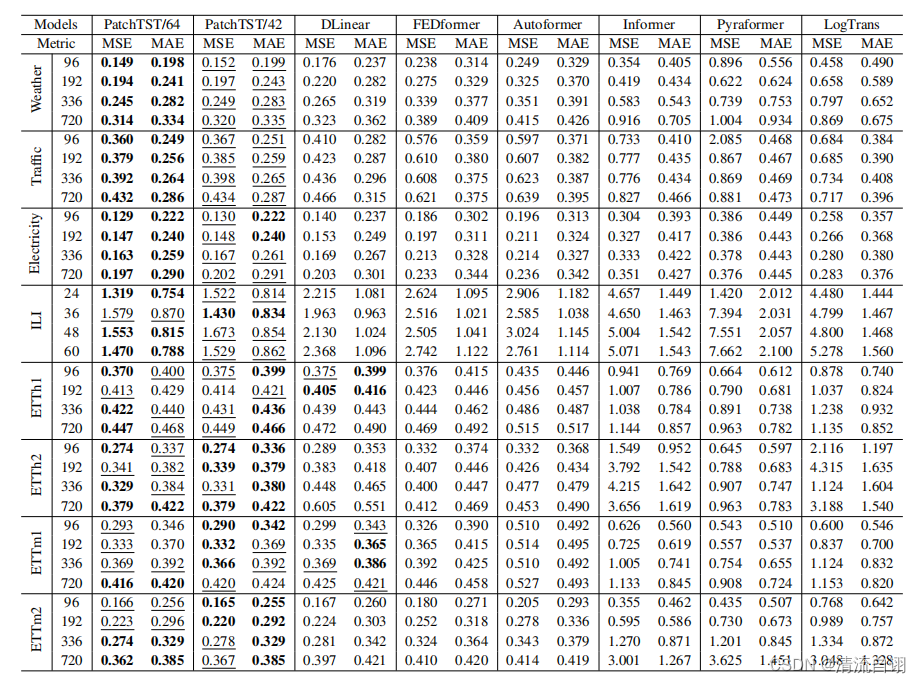
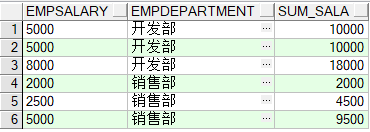
在该部分,作者以监督学习的方式对长期预测进行试验。如上图所示,第一列为8种常用公开数据集;使用以24, 36, 48, 60为输入长度预测以96, 192, 336, 720为输出长度的时序数据;PatchTST/64 、PatchTST/42的64和42表示分块数目。由表中加粗字体,可以看出本文所提方法占了较多的最优情况,总体而言效果更好一些。
表征学习
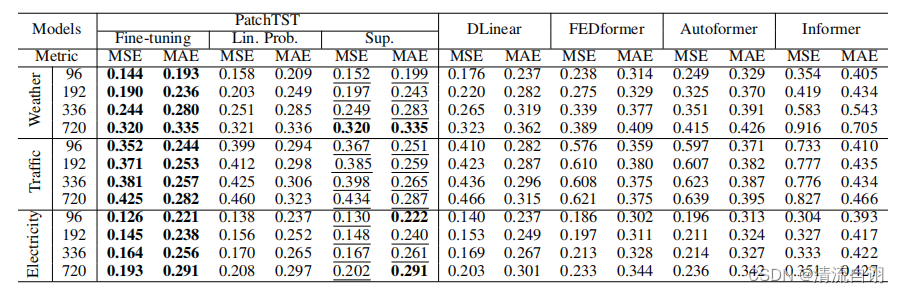
在该部分,作者先使用掩码自监督学习进行试验,对输入的分块给予了百分之四十的遮挡(设值为0),进行了100轮学习。然后在此基础上再进行上文的监督学习,通过对监督学习后的预测结果进行评估来判断表征学习的效果。在这边,作者的监督学习使用了两种方案,一种是线性微调(仅训练最后的线性层,其他参数冻结),另一种是端到端微调(先线性微调,再整个网络的参数一起训练)。实验结果表明微调方法确实起到了一定的效果,其中端到端微调方式效果显著。种种实验结果(包括附录部分的)共同论证了本文所提模型在表征学习方面有着优于其他模型的表现,同时也说明了PatchTST具有着优异的迁移学习的能力。
(更多实验结果见论文附录)
消融实验
分块和通道独立性
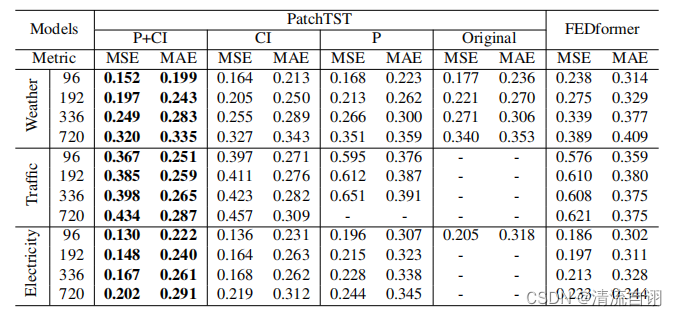
该文章对时序数据分块方法和多因子数据独立化训练方法进行了讨论。实验结果如下表。
其中,P+CI为同时具备分块和通道独立方法(即本文方法),CI表示只有通道独立法,P表示只有分块法,Original则是最原始的两种方法均不具备的实验结果。作者将他们和FDEformer进行对比,实验结果表明分块和通道独立性在提高模型的预测性能上确实具有一定的积极作用。
不同的回顾窗口
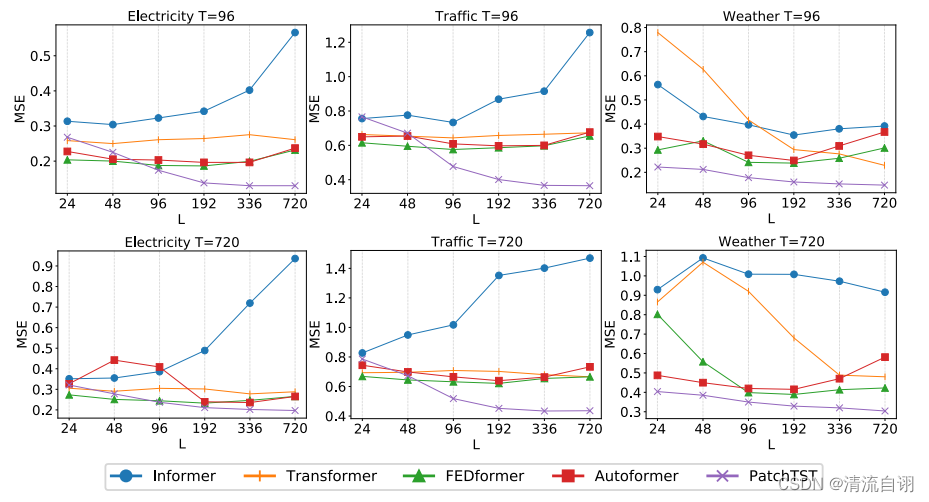
回顾窗口即输入模型的时序数据长度。按照常规思路来说,输入数据越多,时序特征越多,预测结果应该越好,然而事实并非如此。针对这一点,作者进行了讨论,使用不同长度的输入数据,验证相同预测目标的实验效果。横坐标表示输入数据长度,子图顶端T表示预测目标。从图中可以看出,对于多种预测模型而言并非都是输入数据越长预测结果越好,这表明不少模型并未从更长的输入数据中受益,相反,在增加了时间和空间的开销后,还降低了模型的预测性能。而本文所提模型则与之不同,表现出输入数据越多,预测结果越优异的情况,这说明PatchTST具备更优秀的长输入窗口学习能力。
总结
在附录部分,作者还进行了若干组实验,其中消融实验还包括分块长度、预测长度、分块和通道独立、归一化等等。主要讨论的是模型中各个参数和模块(方法)对整个实验效果的影响,在实验的充实性方面可谓是充足。
最让我感兴趣的还是通道独立方法的论述。在文章的附录部分,作者花大篇幅对此进行讨论分享和分析,以实验为支撑的前提下提出了许多观点。就我看来,事无绝对,混合通道和独立通道的效果需以数据为基础以实验为导向来讨论,空谈方法的优劣实属耍流氓。在我做的时序实验中,更倾向于将传统领域研究已具有明确关系的因子进行通道混合,以求通过模型学习的方法学习到他们之前的关系。但又有理论表示,两者存在关系则存在一者即可,过多的关系因子会造成特征的冗余和重复,甚至会干扰单因子的实验效果。我感觉都对,看数据,看实验,结果是啥,自圆其说。至于根因分析、深度学习最深层的原理,能挖就挖,不能就等大佬挖。