目录
栈
队列
栈
栈(Stack)是一种常见的数据结构,它是一种线性数据结构,具有后进先出(Last In First Out, LIFO)的特点。栈可以看作是一个容器,只能在容器的一端进行插入和删除操作,这一端被称为栈顶(Top),另一端被称为栈底(Bottom)。
栈的基本操作有入栈(Push)、出栈(Pop)、获取栈顶元素(Top)和判断栈是否为空(Empty)。入栈操作将一个元素插入到栈顶,出栈操作将栈顶元素删除并返回,获取栈顶元素操作返回栈顶元素但不删除,判断栈是否为空操作返回一个布尔值。
栈的应用非常广泛,例如在计算机程序中,函数调用时会将函数的返回地址和局部变量等信息压入栈中,当函数返回时再将这些信息弹出栈。在表达式求值、括号匹配、迷宫求解等问题中,栈也是非常常用的数据结构。
栈可以使用数组或链表来实现,数组实现的栈叫做顺序栈,链表实现的栈叫做链式栈。顺序栈的优点是实现简单,但是容量固定,当栈满时需要重新分配空间,比较浪费内存。链式栈的优点是可以动态扩展,但是每个节点需要额外的指针空间,比较浪费存储空间。
以下是链式栈的实现:
头文件中:
typedef int StDataType;
typedef struct STNode
{
StDataType data;
struct STNode* next;
};
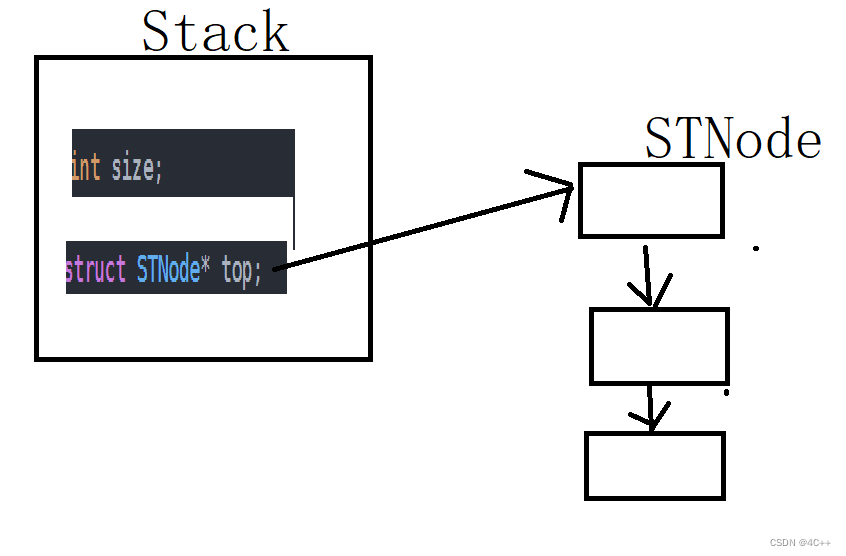
typedef struct Stack
{
int size;
struct STNode* top;
}Stack;
//栈初始化
void StackInit(Stack* pst);
//入栈
void StackPush(Stack* pst, StDataType x);
//出栈
void StackPop(Stack* pst);
//获取栈顶元素
StDataType StackTop(Stack* pst);
//判断栈是否为空
bool StackEmpty(Stack* pst);
//销毁栈
void StackDestroy(Stack* pst);
源文件代码,接口实现:
//栈初始化
void StackInit(Stack* pst)
{
assert(pst);
pst->top = NULL;
pst->size = 0;
}
//入栈
void StackPush(Stack* pst, StDataType x)
{
assert(pst);
STNode* newnode = (STNode*)malloc(sizeof(STNode));
if (newnode == NULL)
{
perror("StackPush error");
return;
}
newnode->data = x;
newnode->next = NULL;
if(pst->top == NULL)
pst->top = newnode;
else
{
newnode->next = pst->top;
pst->top = newnode;
}
pst->size++;
}
//出栈
void StackPop(Stack* pst)
{
assert(pst);
assert(pst->size);
STNode* del = pst->top;
pst->top = del->next;
free(del);
pst->size--;
}
//获取栈顶元素
StDataType StackTop(Stack* pst)
{
assert(pst);
assert(pst->size);
StDataType ret = pst->top->data;
return ret;
}
//判断栈是否为空
bool StackEmpty(Stack* pst)
{
return pst->top == NULL;
}
//销毁栈
void StackDestroy(Stack* pst)
{
assert(pst);
STNode* cur = pst->top;
while (cur)
{
STNode* del = cur;
cur = cur->next;
free(del);
}
}
关于内存中的结构,即栈的结构体中有一个指向STNode结点的指针,指向这个链表的头节点
入栈就是这个链表的头插,出栈就是这个链表的头删
这个链表存放在动态开辟的内存--堆中,不使用后需要程序员自己销毁
如果栈是动态开辟的,那么销毁时要先销毁栈中指向的链表,再销毁栈
如果栈不是动态开辟的,那么只需要销毁栈中指向的链表即可
队列
队列(Queue)是一种常见的数据结构,它是一种线性数据结构,具有先进先出(First In First Out, FIFO)的特点。队列可以看作是一个容器,只能在容器的一端进行插入操作,另一端进行删除操作,这一端被称为队尾(Rear),另一端被称为队头(Front)。
队列的基本操作有入队(Enqueue)、出队(Dequeue)、获取队头元素(Front)和获取队列长度(Size)。入队操作将一个元素插入到队尾,出队操作将队头元素删除并返回,获取队头元素操作返回队头元素但不删除,获取队列长度操作返回队列中元素的个数。
队列的应用也非常广泛,例如在操作系统中,进程调度时会使用队列来存储等待执行的进程,网络通信中,数据包也是通过队列来进行传输的。
队列可以使用数组或链表来实现,数组实现的队列叫做顺序队列,链表实现的队列叫做链式队列。顺序队列的优点是实现简单,但是容量固定,当队列满时需要重新分配空间,比较浪费内存。链式队列的优点是可以动态扩展,但是每个节点需要额外的指针空间,比较浪费存储空间。此外,还有循环队列的实现方式,可以避免顺序队列需要频繁的重新分配空间的问题。
以下是链式队列的实现:
头文件中:
typedef int QDataType;
typedef struct QNode//队列节点
{
QDataType data;
struct QNode* next;
}QNode;
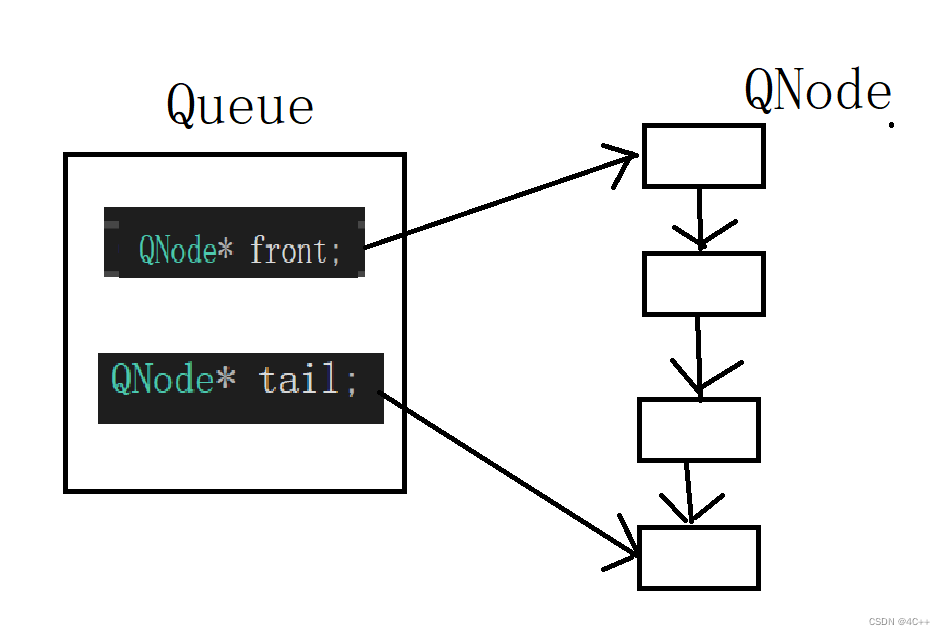
typedef struct Queue//队列
{
QNode* front;
QNode* tail;
}Queue;
//初始化
void QueueInit(Queue* queue);
//队列是否为空
bool QueueEmpty(Queue* queue);
//进队
void QueuePush(Queue* queue, QDataType x);
//出队
void QueuePop(Queue* queue);
//队列头部元素
int QueueTop(Queue* queue);
//队列尾部元素
int QueueBack(Queue* queue);
//队列有效元素个数
int QueueSize(Queue* queue);
//销毁队列
void QueueDestroy(Queue* queue);源代码中,接口实现:
//初始化
void QueueInit(Queue* queue)
{
assert(queue);
queue->front = NULL;
queue->tail = NULL;
}
//队列是否为空
bool QueueEmpty(Queue* queue)
{
assert(queue);
return queue->tail == NULL;
}
//进队
void QueuePush(Queue* queue, QDataType x)
{
assert(queue);
QNode* node = (QNode*)malloc(sizeof(QNode));
node->data = x;
node->next = NULL;
if (queue->tail == NULL)
{
queue->front = queue->tail = node;
}
else
{
queue->tail->next = node;
queue->tail = node;
}
}
//出队
void QueuePop(Queue* queue)
{
assert(queue);
QNode* next = queue->front->next;
free(queue->front);
queue->front = next;
if (queue->front == NULL)
{
queue->tail = NULL;
}
}
//队列头部元素
int QueueTop(Queue* queue)
{
assert(queue);
int ret = queue->front->data;
return ret;
}
//队列尾部元素
int QueueBack(Queue* queue)
{
assert(queue);
int ret = queue->tail->data;
return ret;
}
//队列有效元素个数
int QueueSize(Queue* queue)
{
assert(queue);
QNode* cur = queue->front;
int size = 0;
while (cur)
{
size++;
cur = cur->next;
}
return size;
}
//销毁队列
void QueueDestroy(Queue* queue)
{
assert(queue);
QNode* cur = queue->front;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
queue->tail = NULL;
}
内存结构上,队列的结构体变量内有两个指针:front、tail,分别指向动态内存空间中一条链表中的头节点和尾节点
如果队列是动态开辟的,销毁时应该先销毁队列中指向的链表,再销毁队列这个结构体变量
如果队列不是动态开辟的,那么只需要销毁队列指向的单链表即可