Flink从入门到精通之-06Flink 中的时间和窗口
我们已经了解了基本 API 的用法,熟悉了 DataStream 进行简单转换、聚合的一些操作。除此之外,Flink 还提供了丰富的转换算子,可以用于更加复杂的处理场景。
在流数据处理应用中,一个很重要、也很常见的操作就是窗口计算。所谓的“窗口”,一般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的窗口计算。所以窗口和时间往往是分不开的。接下来我们就深入了解一下 Flink 中的时间语义和窗口的应用。
文章目录
- Flink从入门到精通之-06Flink 中的时间和窗口
- 6.1 时间语义
- 6.1.1 Flink 中的时间语义
- 6.1.2 哪种时间语义更重要
- 6.2 水位线(Watermark)
- 6.2.1 事件时间和窗口
- 6.2.2 什么是水位线
- 6.2.3 如何生成水位线
- 6.2.4 水位线的传递
- 6.2.5 水位线的总结
- 6.3 窗口(Window)
- 6.3.1 窗口的概念
- 6.3.3 窗口 API 概览
- 6.3.4 窗口分配器(Window Assigners)
- 6.3.5 窗口函数(Window Functions)
- 6.3.6 测试水位线和窗口的使用
- 6.3.7 其他 API
- 6.3.8 窗口的生命周期
- 6.4 迟到数据的处理
- 6.4.1 设置水位线延迟时间
- 6.4.2 允许窗口处理迟到数据
- 6.4.3 将迟到数据放入窗口侧输出流
- 6.5 本章总结
6.1 时间语义
“时间”,从理论物理和哲学的角度解释,可能有些玄妙;但对于我们来说,它其实是生活中再熟悉不过的一个概念。一年 365 天,每天 24 小时,时间就像缓缓流淌的河,不疾不徐、无休无止地前进着,它是我们衡量事件发生和进展的标准尺度。如果想写抒情散文或是科幻小说,时间无疑是个绝好的题材。但这跟数据处理有什么关系呢?
其实从上面的描述中已经可以发现,时间本身就有着“流”的特性,它可以用来判断事件发生的先后以及间隔;所以如果我们想要划定窗口来收集数据,一般就需要基于时间。对于批处理来说,这似乎没什么讨论的必要,因为数据都收集好了,想怎么划分窗口都可以;而对于流处理来说,如果想处理更加实时,就必须对时间有更加精细的控制。那怎样对时间进行“精细的控制”呢?在我们的认知里,时间的流逝是一个客观的事实,只要有一个足够精确的表就可以告诉我们准确的时间了。在计算机系统里,这不就是系统时间吗?那所谓的“时间语义”又是什么意思呢?
6.1.1 Flink 中的时间语义
对于一台机器而言,“时间”自然就是指系统时间。但我们知道,Flink 是一个分布式处理系统。分布式架构最大的特点,就是节点彼此独立、互不影响,这带来了更高的吞吐量和容错性;但有利必有弊,最大的问题也来源于此。在分布式系统中,节点“各自为政”,是没有统一时钟的,数据和控制信息都通过网络进行传输。比如现在有一个任务是窗口聚合,我们希望将每个小时的数据收集起来进行统计处理。而对于并行的窗口子任务,它们所在节点不同,系统时间也会有差异;当我们希望统计 8 点~9 点的数据时,对并行任务来说其实并不是“同时”的,收集到的数据也会有误差。
那既然一个集群中有 JobManager 作为管理者,是不是让它统一向所有 TaskManager 发送同步时钟信号就行了呢?这也是不行的。因为网络传输会有延迟,而且这延迟是不确定的,所以 JobManager 发出的同步信号无法同时到达所有节点;想要拥有一个全局统一的时钟,在分布式系统里是做不到的。
另一个麻烦的问题是,在流式处理的过程中,数据是在不同的节点间不停流动的,这同样也会有网络传输的延迟。这样一来,当上下游任务需要跨节点传输数据时,它们对于“时间”的理解也会有所不同。例如,上游任务在 8 点 59 分 59 秒发出一条数据,到下游要做窗口计算时已经是 9 点零 1 秒了,那这条数据到底该不该被收到 8 点~9 点的窗口呢?所以,当我们希望对数据按照时间窗口来进行收集计算时,“时间”到底以谁为标准就非常重要了。
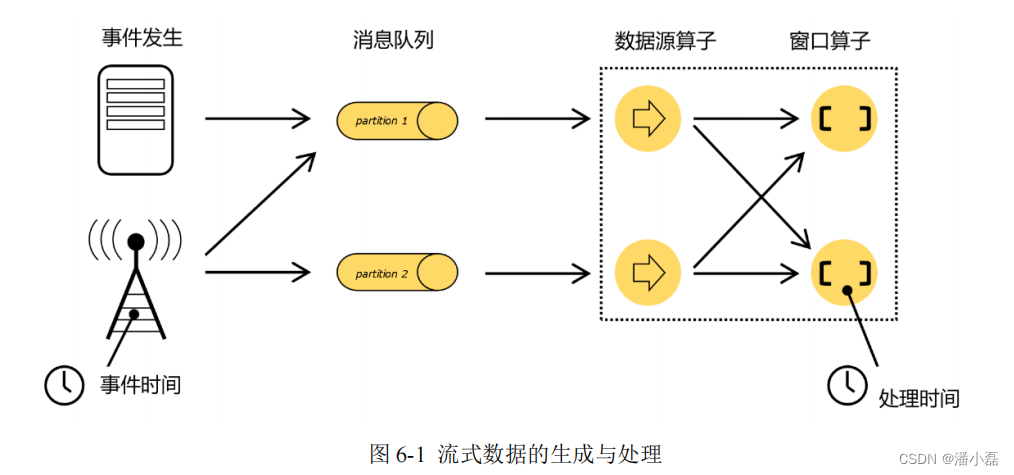
我们重新梳理一下流式数据处理的过程。如图 6-1 所示,在事件发生之后,生成的数据被收集起来,首先进入分布式消息队列,然后被 Flink 系统中的 Source 算子读取消费,进而向下游的转换算子(窗口算子)传递,最终由窗口算子进行计算处理。
很明显,这里有两个非常重要的时间点:一个是数据产生的时间,我们把它叫作“事件时间”(Event Time);另一个是数据真正被处理的时刻,叫作“处理时间”(Processing Time)。
我们所定义的窗口操作,到底是以那种时间作为衡量标准,就是所谓的“时间语义”(Notions of Time)。由于分布式系统中网络传输的延迟和时钟漂移,处理时间相对事件发生的时间会有所滞后。
1. 处理时间(Processing Time)
处理时间的概念非常简单,就是指执行处理操作的机器的系统时间。如果我们以它作为衡量标准,那么数据属于哪个窗口就很明显了:只看窗口任务处理这条数据时,当前的系统时间。比如之前举的例子,数据 8 点 59 分 59 秒产生,而窗口计算时的时间是 9 点零 1 秒,那么这条数据就属于 9 点—10 点的窗口;如果数据传输非常快,9 点之前就到了窗口任务,那么它就属于 8 点—9 点的窗口了。每个并行的窗口子任务,就只按照自己的系统时钟划分窗口。假如我们在早上 8 点 10 分启动运行程序,那么接下来一直到 9 点以前处理的所有数据,都属于第一个窗口;9 点之后、10 点之前的所有数据就将属于第二个窗口。这种方法非常简单粗暴,不需要各个节点之间进行协调同步,也不需要考虑数据在流中的位置,简单来说就是“我的地盘听我的”。所以处理时间是最简单的时间语义。
2. 事件时间(Event Time)
事件时间,是指每个事件在对应的设备上发生的时间,也就是数据生成的时间。
数据一旦产生,这个时间自然就确定了,所以它可以作为一个属性嵌入到数据中。这其实就是这条数据记录的“时间戳”(Timestamp)。在事件时间语义下,我们对于时间的衡量,就不看任何机器的系统时间了,而是依赖于数据本身。打个比方,这相当于任务处理的时候自己本身是没有时钟的,所以只好来一个数据就问一下“现在几点了”;而数据本身也没有表,只有一个自带的“出厂时间”,于是任务就基于这个时间来确定自己的时钟。由于流处理中数据是源源不断产生的,一般来说,先产生的数据也会先被处理,所以当任务不停地接到数据时,它们的时间戳也基本上是不断增长的,就可以代表时间的推进。
当然我们会发现,这里有个前提,就是“先产生的数据先被处理”,这要求我们可以保证数据到达的顺序。但是由于分布式系统中网络传输延迟的不确定性,实际应用中我们要面对的数据流往往是乱序的。在这种情况下,就不能简单地把数据自带的时间戳当作时钟了,而需要用另外的标志来表示事件时间进展,在 Flink 中把它叫作事件时间的“水位线”(Watermarks)。关于水位线的概念和用法,我们会稍后介绍。
6.1.2 哪种时间语义更重要
我们已经了解了 Flink 中两种不同的时间语义,那实际应用的时候,到底应该用哪个呢?
1. 从《星球大战》说起
为了更加清晰地说明两种语义的区别,我们来举一个非常经典的例子:电影《星球大战》。
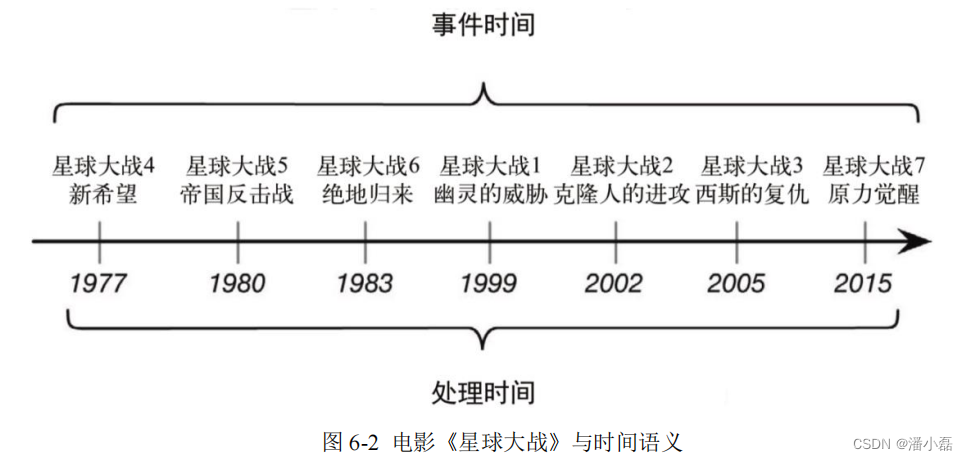
《星球大战》是一部经典的科幻电影,在 1977 拍摄上映之后就引起了巨大的反响,票房爆棚好评如潮。我们知道,但凡一部商业电影叫好又叫座,那十有八九都是要拍续集的——于是6 年内又上映了两部续集,这就是当时轰动一时的星战三部曲。好 IP 总是要反复拿来用,所以十几年后又有了星战前传三部曲,到了 2015 年之后又以每年一部的频率继续拍摄后传和外传。而星战系列的命名也很有趣,是按照故事时间线的发展来的:经典三部曲是系列的四、五、六部,之后是前传一、二、三,2015 年开始的后传就从第七部算起了。如图 6-2 所示,我们会发现,看电影其实就是处理影片中数据的过程,所以影片的上映时间就相当于“处理时间”;而影片的数据就是所描述的故事,它所发生的背景时间就相当于“事件时间”。
现在我们考虑一下,作为没有看过星战的新影迷,如果想要入坑一览,该选择什么样的观影顺序呢?这就要看我们具体的需求了:如果你是剧情党,重点想看一个完整的故事,那最好的选择无疑就是按照系列的编号,沿着故事发展的时间线来看;而如果你是特效党,更想体验炫目的视觉效果和时代技术的发展,那就按照电影的拍摄顺序来观看,不过剧情可能就需要多脑补一下了。所以,两种时间语义都有各自的用途,适用于不同的场景。
2. 数据处理系统中的时间语义
在计算机系统中,考虑数据处理的“时代变化”是没什么意义的,我们更关心的,显然是数据本身产生的时间。比如我们计算网站的 PV、UV 等指标,要统计每天的访问量。如果某个用户在 23 点 59分 59 秒有一次访问,但我们的任务处理这条数据的时间已经是第二天 0 点 0 分 01 秒了;那么这条数据,是应该算作当天的访问,还是第二天的访问呢?很明显,统计用户行为,需要考虑行为本身发生的时间,所以我们应该把这条数据统计入当天的访问量。这时我们用到的窗口,就是以事件时间作为划分标准的,跟处理时间无关。
所以在实际应用中,事件时间语义会更为常见。一般情况下,业务日志数据中都会记录数据生成的时间戳(timestamp),它就可以作为事件时间的判断基础。
3. 两种时间语义的对比
实际应用中,数据产生的时间和处理的时间可能是完全不同的。很长时间收集起来的数据,处理或许只要一瞬间;也有可能数据量过大、处理能力不足,短时间堆了大量数据处理不完,产生“背压”(back pressure)。
通常来说,处理时间是我们计算效率的衡量标准,而事件时间会更符合我们的业务计算逻辑。所以更多时候我们使用事件时间;不过处理时间也不是一无是处。对于处理时间而言,由于没有任何附加考虑,数据一来就直接处理,因此这种方式可以让我们的流处理延迟降到最低,效率达到最高。
但是我们前面提到过,在分布式环境中,处理时间其实是不确定的,各个并行任务时钟不统一;而且由于网络延迟,导致数据到达各个算子任务的时间有快有慢,对于窗口操作就可能收集不到正确的数据了,数据处理的顺序也会被打乱。这就会影响到计算结果的正确性。所以处理时间语义,一般用在对实时性要求极高、而对计算准确性要求不太高的场景。
而在事件时间语义下,水位线成为了时钟,可以统一控制时间的进度。这就保证了我们总可以将数据划分到正确的窗口中,比如 8 点 59 分 59 秒产生的数据,无论网络传输的延迟是多少,它永远属于 8 点~9 点的窗口,不会错分。但我们知道数据还可能是乱序的,要想让窗口正确地收集到所有数据,就必须等这些错乱的数据都到齐,这就需要一定的等待时间。所以整体上看,事件时间语义是以一定延迟为代价,换来了处理结果的正确性。由于网络延迟一般只有毫秒级,所以即使是事件时间语义,同样可以完成低延迟实时流处理的任务。另外,除了事件时间和处理时间,Flink 还有一个“摄入时间”(Ingestion Time)的概念,
它是指数据进入 Flink 数据流的时间,也就是 Source 算子读入数据的时间。摄入时间相当于是事件时间和处理时间的一个中和,它是把 Source 任务的处理时间,当作了数据的产生时间添加到数据里。这样一来,水位线(watermark)也就基于这个时间直接生成,不需要单独指定了。这种时间语义可以保证比较好的正确性,同时又不会引入太大的延迟。它的具体行为跟事件时间非常像,可以当作特殊的事件时间来处理。
在 Flink 中,由于处理时间比较简单,早期版本默认的时间语义是处理时间;而考虑到事件时间在实际应用中更为广泛,从 1.12 版本开始,Flink 已经将事件时间作为了默认的时间语义。
6.2 水位线(Watermark)
在介绍事件时间语义时,我们提到了“水位线”的概念,已经知道了它其实就是用来度量事件时间的。那么水位线具体有什么含义,又跟数据的时间戳有什么关系呢?接下来我们就来深入探讨一下这个流处理中的核心概念。
6.2.1 事件时间和窗口
在实际应用中,一般会采用事件时间语义。而水位线,就是基于事件时间提出的概念。所以在介绍水位线之前,我们首先来梳理一下事件时间和窗口的关系。
一个数据产生的时刻,就是流处理中事件触发的时间点,这就是“事件时间”,一般都会以时间戳的形式作为一个字段记录在数据里。这个时间就像商品的“生产日期”一样,一旦产生就是固定的,印在包装袋上,不会因为运输辗转而变化。如果我们想要统计一段时间内的数据,需要划分时间窗口,这时只要判断一下时间戳就可以知道数据属于哪个窗口了。
明确了一个数据的所属窗口,还不能直接进行计算。因为窗口处理的是有界数据,我们需要等窗口的数据都到齐了,才能计算出最终的统计结果。那什么时候数据就都到齐了呢?对于时间窗口来说这很明显:到了窗口的结束时间,自然就应该收集到了所有数据,就可以触发计算输出结果了。比如我们想统计 8 点~9 点的用户点击量,那就是从 8 点开始收集数据,到 9点截止,将收集的数据做处理计算。这有点类似于班车,如图 6-3 所示,每小时发一班,那么8 点之后来的人都会上同一班车,到 9 点钟准时发车;9 点之后来的人,就只好等下一班 10点发的车了。
当然,我们现在处理的数据本身是有时间戳的。所以为了更清楚地解释,我们将“赶班车”这个例子中的人,换成带着生产日期的商品。所以现在我们班车的主要任务是运送货物,一辆车就只装载 1 小时内生产出的所有商品,货到齐了就发车。比如某辆车要装的是 8 点到 9 点的所有商品,那货什么时候到齐呢?自然可以想到,到 9 点钟的时候商品就到齐了,可以发车了。
这里的关键问题是,“9 点钟发车”,到底是看谁的表来定时间?在处理时间语义下,都是以当前任务所在节点的系统时间为准的。这就相当于每辆车里都挂了一个钟,司机看到到了 9 点就直接发车。这种方式简单粗暴容易实现,但因为车上的钟是独立运行的,以它为标准就不能准确地判断商品的生产时间。在分布式环境下,这样会因为网络传输延迟的不确定而导致误差。比如有些商品在 8 点 59 分 59 秒生产出来,可是从下生产线到运至车上又要花费几秒,那就赶不上 9 点钟这班车了。而且现在分布式系统中有很多辆 9点发的班车,所以同时生产出的一批商品,需要平均分配到不同班车上,可这些班车距离有近有远、上面挂的钟有快有慢,这就可能导致有些商品上车了、有些却被漏掉;先后生产出的商品,到达车上的顺序也可能乱掉:统计结果的正确性受到了影响。所以在实际中我们往往需要以事件时间为准。如果考虑事件时间,情况就复杂起来了。现在不能直接用每辆车上挂的钟(系统时间),又没有统一的时钟,那该怎么确定发车时间呢?现在能利用的,就只有商品的生产时间(数据的时间戳)了。我们可以这样思考:一般情况下,商品生产出来之后,就会立即传送到车上;所以商品到达车上的时间(系统时间)应该稍稍滞后于商品的生产时间(数据时间戳)。如果不考虑传输过程的一点点延迟,我们就可以直接用商品生产时间来表示当前车上的时间了。如图 6-4 所示,到达车上的商品,生产时间是8 点 05 分,那么当前车上的时间就是 8 点 05 分;又来了一个 8 点 10 分生产的商品,现在车上的时间就是 8 点 10 分。我们直接用数据的时间戳来指示当前的时间进展,窗口的关闭自然也是以数据的时间戳等于窗口结束时间为准,这就相当于可以不受网络传输延迟的影响了。像之前所说 8 点 59 分 59 秒生产出来的商品,到车上的时候不管实际时间(系统时间)是几点,我们就认为当前是 8 点 59 分 59 秒,所以它总是能赶上车的;而 9 点这班车,要等到 9 点整生产的商品到来,才认为时间到了 9 点,这时才正式发车。这样就可以得到正确的统计结果了。
在这个处理过程中,我们其实是基于数据的时间戳,自定义了一个“逻辑时钟”。这个时钟的时间不会自动流逝;它的时间进展,就是靠着新到数据的时间戳来推动的。这样的好处在于,计算的过程可以完全不依赖处理时间(系统时间),不论什么时候进行统计处理,得到的结果都是正确的。比如双十一的时候系统处理压力大,我们可能会把大量数据缓存在 Kafka中;过了高峰时段之后再读取出来,在几秒之内就可以处理完几个小时甚至几天的数据,而且依然可以按照数据产生的时间段进行统计,所有窗口都能收集到正确的数据。而一般实时流处理的场景中,事件时间可以基本与处理时间保持同步,只是略微有一点延迟,同时保证了窗口计算的正确性。
6.2.2 什么是水位线
在事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟,用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数据的时间戳来驱动的。
但在分布式系统中,这种驱动方式又会有一些问题。因为数据本身在处理转换的过程中会变化,如果遇到窗口聚合这样的操作,其实是要攒一批数据才会输出一个结果,那么下游的数据就会变少,时间进度的控制就不够精细了。另外,数据向下游任务传递时,一般只能传输给一个子任务(除广播外),这样其他的并行子任务的时钟就无法推进了。例如一个时间戳为 9点整的数据到来,当前任务的时钟就已经是 9 点了;处理完当前数据要发送到下游,如果下游任务是一个窗口计算,并行度为 3,那么接收到这个数据的子任务,时钟也会进展到 9 点,9点结束的窗口就可以关闭进行计算了;而另外两个并行子任务则时间没有变化,不能进行窗口计算。所以我们应该把时钟也以数据的形式传递出去,告诉下游任务当前时间的进展;而且这个时钟的传递不会因为窗口聚合之类的运算而停滞。一种简单的想法是,在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。由于类似于水流中用来做标志的记号,在 Flink 中,这种用来衡量事件时间(Event Time)进展的标记,就被称作“水位线”(Watermark)。具体实现上,水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点,主要内容就是一个时间戳,用来指示当前的事件时间。而它插入流中的位置,就应该是在某个数据到来之后;这样就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。
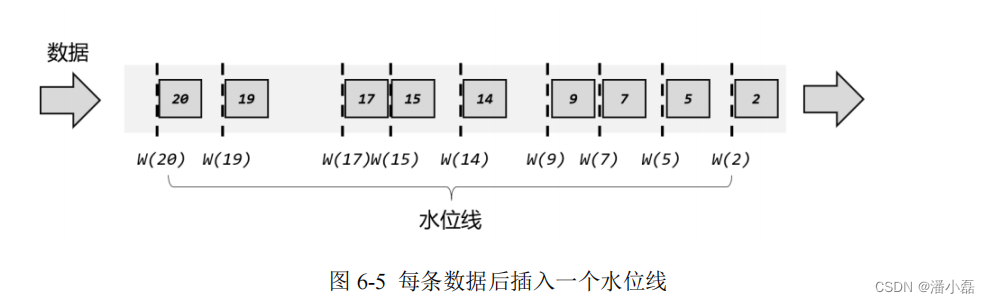
如图 6-5 所示,每个事件产生的数据,都包含了一个时间戳,我们直接用一个整数表示。这里没有指定单位,可以理解为秒或者毫秒(方便起见,下面讲述统一认为是秒)。当产生于2 秒的数据到来之后,当前的事件时间就是 2 秒;在后面插入一个时间戳也为 2 秒的水位线,随着数据一起向下游流动。而当 5 秒产生的数据到来之后,同样在后面插入一个水位线,时间戳也为 5,当前的时钟就推进到了 5 秒。这样,如果出现下游有多个并行子任务的情形,我们只要将水位线广播出去,就可以通知到所有下游任务当前的时间进度了。
水位线就像它的名字所表达的,是数据流中的一部分,随着数据一起流动,在不同任务之间传输。这看起来非常简单;接下来我们就进一步探讨一些复杂的状况。
1. 有序流中的水位线
在理想状态下,数据应该按照它们生成的先后顺序、排好队进入流中;也就是说,它们处理的过程会保持原先的顺序不变,遵守先来后到的原则。这样的话我们从每个数据中提取时间戳,就可以保证总是从小到大增长的,从而插入的水位线也会不断增长、事件时钟不断向前推进。
实际应用中,如果当前数据量非常大,可能会有很多数据的时间戳是相同的,这时每来一条数据就提取时间戳、插入水位线就做了大量的无用功。而且即使时间戳不同,同时涌来的数据时间差会非常小(比如几毫秒),往往对处理计算也没什么影响。所以为了提高效率,一般会每隔一段时间生成一个水位线,这个水位线的时间戳,就是当前最新数据的时间戳,如图6-6 所示。所以这时的水位线,其实就是有序流中的一个周期性出现的时间标记。
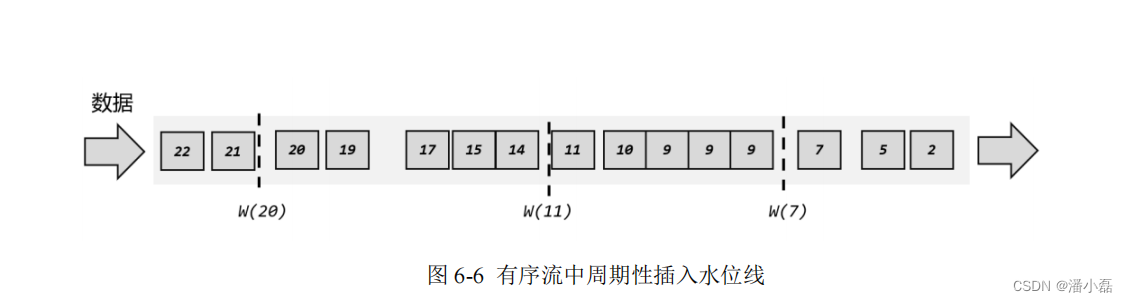
这里需要注意的是,水位线插入的“周期”,本身也是一个时间概念。在当前事件时间语义下,假如我们设定了每隔 100ms 生成一次水位线,那就是要等事件时钟推进 100ms 才能插入;但是事件时钟本身的进展,本身就是靠水位线来表示的——现在要插入一个水位线,可前提又是水位线要向前推进 100ms,这就陷入了死循环。所以对于水位线的周期性生成,周期时间是指处理时间(系统时间),而不是事件时间。
2. 乱序流中的水位线
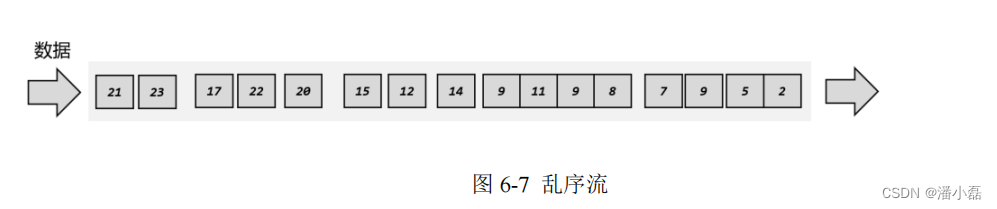
有序流的处理非常简单,看起来水位线也并没有起到太大的作用。但这种情况只存在于理想状态下。我们知道在分布式系统中,数据在节点间传输,会因为网络传输延迟的不确定性,导致顺序发生改变,这就是所谓的“乱序数据”。这里所说的“乱序”(out-of-order),是指数据的先后顺序不一致,主要就是基于数据的产生时间而言的。如图 6-7 所示,一个 7 秒时产生的数据,生成时间自然要比 9 秒的数据早;但是经过数据缓存和传输之后,处理任务可能先收到了 9 秒的数据,之后 7 秒的数据才姗姗来迟。这时如果我们希望插入水位线,来指示当前的事件时间进展,又该怎么做呢?
最直观的想法自然是跟之前一样,我们还是靠数据来驱动,每来一个数据就提取它的时间戳、插入一个水位线。不过现在的情况是数据乱序,所以有可能新的时间戳比之前的还小,如果直接将这个时间的水位线再插入,我们的“时钟”就回退了——水位线就代表了时钟,时光不能倒流,所以水位线的时间戳也不能减小。
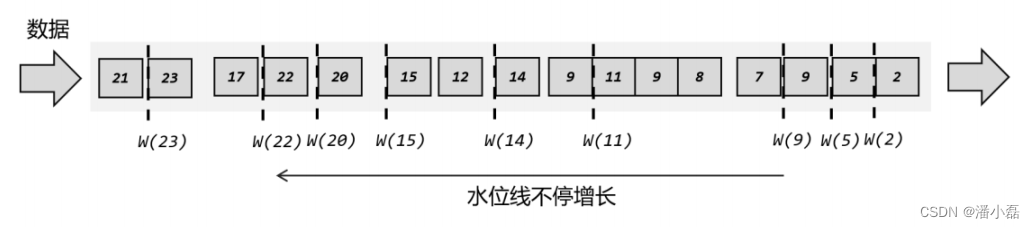
解决思路也很简单:我们插入新的水位线时,要先判断一下时间戳是否比之前的大,否则就不再生成新的水位线,如图 6-8 所示。也就是说,只有数据的时间戳比当前时钟大,才能推动时钟前进,这时才插入水位线。
如果考虑到大量数据同时到来的处理效率,我们同样可以周期性地生成水位线。这时只需要保存一下之前所有数据中的最大时间戳,需要插入水位线时,就直接以它作为时间戳生成新的水位线,如图 6-9 所示。
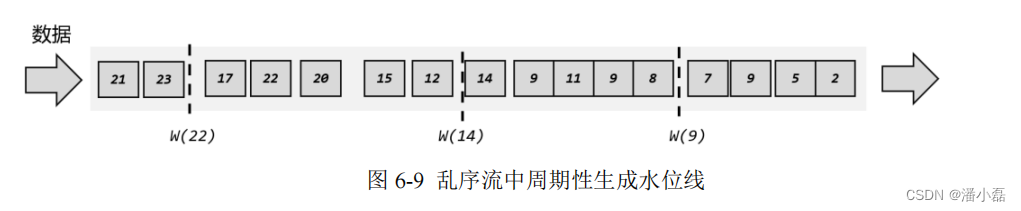
这样做尽管可以定义出一个事件时钟,却也会带来一个非常大的问题:我们无法正确处理“迟到”的数据。在上面的例子中,当 9 秒产生的数据到来之后,我们就直接将时钟推进到了9 秒;如果有一个窗口结束时间就是 9 秒(比如,要统计 0-9 秒的所有数据),那么这时窗口就应该关闭、将收集到的所有数据计算输出结果了。但事实上,由于数据是乱序的,还可能有时间戳为 7 秒、8 秒的数据在 9 秒的数据之后才到来,这就是“迟到数据”(late data)。它们本来也应该属于 0~9 秒这个窗口,但此时窗口已经关闭,于是这些数据就被遗漏了,这会导致统计结果不正确。
如果用之前我们类比班车的例子,现在的状况就是商品不是按照生产时间顺序到来的,所以有可能出现这种情况:9 点生产的商品已经到了,我们认为已经到了 9 点,所以直接发车;但是可能还会有8 点59分59 秒生产的商品迟到了,没有赶上这班车。那怎么解决这个问题呢?其实我们有很多生活中的经验。假如是一个团队出去团建,那肯定希望每个人都不能落下;如果有人因为堵车没能准时到车上,我们可以稍微等一会儿。9 点发车,我们可以等到 9 点 10分,等人都到齐了再出发。当然,实际应用的网络环境不可能跟北京的交通一样堵,所以不需要等那么久,或许只要等一两秒钟就可以了。具体在商品班车的例子里,我们可以多等 2 秒钟,也就是当生产时间为 9 点零 2 秒的商品到达,时钟推进到 9 点零 2 秒,这时就认为所有 8 点到9 点生产的商品都到齐了,可以正式发车。不过这样相当于更改了发车时间,属于“违规操作”。
为了做到形式上仍然是 9 点发车,我们可以更改一下时钟推进的逻辑:当一个商品到达时,不要直接用它的生产时间作为当前时间,而是减上两秒,这就相当于把车上的逻辑时钟调慢了。这样一来,当 9 点生产的商品到达时,我们当前车上的时间是 8 点 59 分 58 秒,还没到发车时间;当 9 点零 2 秒生产的商品到达时,车上时间刚好是 9 点,这时该到的商品都到齐了,准时发车就没问题了。回到上面的例子,为了让窗口能够正确收集到迟到的数据,我们也可以等上 2 秒;也就是用当前已有数据的最大时间戳减去 2 秒,就是要插入的水位线的时间戳,如图 6-10 所示。这样的话,9 秒的数据到来之后,事件时钟不会直接推进到 9 秒,而是进展到了 7 秒;必须等到11 秒的数据到来之后,事件时钟才会进展到 9 秒,这时迟到数据也都已收集齐,0~9 秒的窗口就可以正确计算结果了。
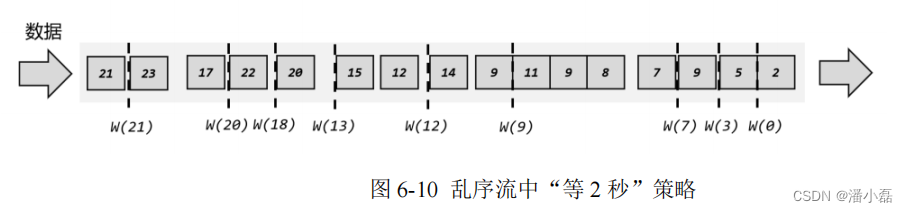
如果仔细观察就会看到,这种“等 2 秒”的策略其实并不能处理所有的乱序数据。比如22 秒的数据到来之后,插入的水位线时间戳为 20,也就是当前时钟已经推进到了 20 秒;对于10~20 秒的窗口,这时就该关闭了。但是之后又会有 17 秒的迟到数据到来,它本来应该属于10-20 秒窗口,现在却被遗漏丢弃了。那又该怎么办呢?既然现在等 2 秒还是等不到 17 秒产生的迟到数据,那自然我们可以试着多等几秒,也就是把时钟调得更慢一些。最终的目的,就是要让窗口能够把所有迟到数据都收进来,得到正确的计算结果。对应到水位线上,其实就是要保证,当前时间已经进展到了这个时间戳,在这之后不可能再有迟到数据来了。
下面是一个示例,我们可以使用周期性的方式生成正确的水位线。
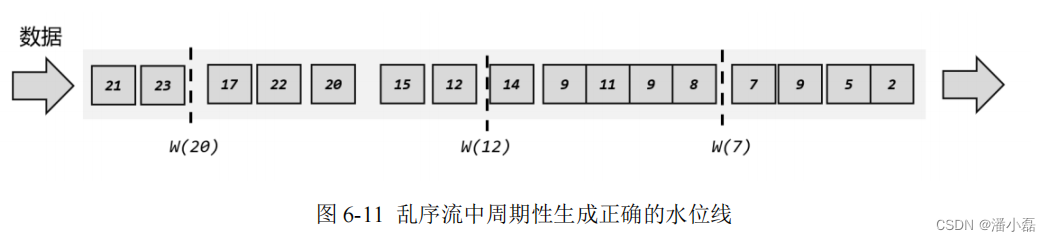
如图 6-11 所示,第一个水位线时间戳为 7,它表示当前事件时间是 7 秒,7 秒之前的数据都已经到齐,之后再也不会有了;同样,第二个、第三个水位线时间戳分别为 12 和 20,表示11 秒、20 秒之前的数据都已经到齐,如果有对应的窗口就可以直接关闭了,统计的结果一定是正确的。这里由于水位线是周期性生成的,所以插入的位置不一定是在时间戳最大的数据后面。
另外需要注意的是,这里一个窗口所收集的数据,并不是之前所有已经到达的数据。因为数据属于哪个窗口,是由数据本身的时间戳决定的,一个窗口只会收集真正属于它的那些数据。也就是说,上图中尽管水位线 W(20)之前有时间戳为 22 的数据到来,10~20 秒的窗口中也不会收集这个数据,进行计算依然可以得到正确的结果。关于窗口的原理,我们会在后面继续展开讲解。
3. 水位线的特性
现在我们可以知道,水位线就代表了当前的事件时间时钟,而且可以在数据的时间戳基础上加一些延迟来保证不丢数据,这一点对于乱序流的正确处理非常重要。
我们可以总结一下水位线的特性:
⚫ 水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
⚫ 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
⚫ 水位线是基于数据的时间戳生成的
⚫ 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
⚫ 水位线可以通过设置延迟,来保证正确处理乱序数据
⚫ 一个水位线 Watermark(t),表示在当前流中事件时间已经达到了时间戳 t, 这代表 t 之前的所有数据都到齐了,之后流中不会出现时间戳 t’ ≤ t 的数据水位线是 Flink 流处理中保证结果正确性的核心机制,它往往会跟窗口一起配合,完成对乱序数据的正确处理。关于这部分内容,我们会稍后进一步展开讲解。
6.2.3 如何生成水位线
上一节中我们讲到,水位线是用来保证窗口处理结果的正确性的,如果不能正确处理所有乱序数据,可以尝试调大延迟的时间。那在实际应用中,到底应该怎样生成水位线呢?本节我们就来讨论这个问题。
1. 生成水位线的总体原则
我们知道,完美的水位线是“绝对正确”的,也就是一个水位线一旦出现,就表示这个时间之前的数据已经全部到齐、之后再也不会出现了。而完美的东西总是可望不可即,我们只能尽量去保证水位线的正确。如果对结果正确性要求很高、想要让窗口收集到所有数据,我们该怎么做呢?
一个字,等。由于网络传输的延迟不确定,为了获取所有迟到数据,我们只能等待更长的时间。作为筹划全局的程序员,我们当然不会傻傻地一直等下去。那到底等多久呢?这就需要对相关领域有一定的了解了。比如,如果我们知道当前业务中事件的迟到时间不会超过 5 秒,那就可以将水位线的时间戳设为当前已有数据的最大时间戳减去 5 秒,相当于设置了 5 秒的延迟等待。更多的情况下,我们或许没那么大把握。毕竟未来是没有人能说得准的,我们怎么能确信未来不会出现一个超级迟到数据呢?所以另一种做法是,可以单独创建一个 Flink 作业来监控事件流,建立概率分布或者机器学习模型,学习事件的迟到规律。得到分布规律之后,就可以选择置信区间来确定延迟,作为水位线的生成策略了。例如,如果得到数据的迟到时间服从μ=1,σ=1 的正态分布,那么设置水位线延迟为 3 秒,就可以保证至少 97.7%的数据可以正确处理。
如果我们希望计算结果能更加准确,那可以将水位线的延迟设置得更高一些,等待的时间越长,自然也就越不容易漏掉数据。不过这样做的代价是处理的实时性降低了,我们可能为极少数的迟到数据增加了很多不必要的延迟。如果我们希望处理得更快、实时性更强,那么可以将水位线延迟设得低一些。这种情况下,可能很多迟到数据会在水位线之后才到达,就会导致窗口遗漏数据,计算结果不准确。对于这些 “漏网之鱼”,Flink 另外提供了窗口处理迟到数据的方法,我们会在后面介绍。当然,如果我们对准确性完全不考虑、一味地追求处理速度,可以直接使用处理时间语义,这在理论上可以得到最低的延迟。所以 Flink 中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把控制的权力交给了程序员,我们可以在代码中定义水位线的生成策略。接下来我们就具体了解一下水位线在代码中的使用。
2. 水位线生成策略(Watermark Strategies)
在 Flink 的 DataStream API 中 , 有 一 个 单 独 用 于 生 成 水 位 线 的 方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间:
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks( WatermarkStrategy<T> watermarkStrategy)
具体使用时,直接用 DataStream 调用该方法即可,与普通的 transform 方法完全一样。
DataStream<Event> stream = env.addSource(new ClickSource());
DataStream<Event> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(<watermark strategy>);
这里读者可能有疑惑:不是说数据里已经有时间戳了吗,为什么这里还要“分配”呢?这是因为原始的时间戳只是写入日志数据的一个字段,如果不提取出来并明确把它分配给数据,Flink 是无法知道数据真正产生的时间的。当然,有些时候数据源本身就提供了时间戳信息,比如读取 Kafka 时,我们就可以从 Kafka 数据中直接获取时间戳,而不需要单独提取字段分配了。.assignTimestampsAndWatermarks()方法需要传入一个 WatermarkStrategy 作为参数,这就是 所 谓 的 “ 水 位 线 生 成 策 略 ” 。 WatermarkStrategy 中 包 含 了 一 个 “ 时 间 戳 分 配器”TimestampAssigner 和一个“水位线生成器”WatermarkGenerator。
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>,
WatermarkGeneratorSupplier<T>{
@Override
TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);
@Override
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
⚫ TimestampAssigner:主要负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础。
⚫ WatermarkGenerator:主要负责按照既定的方式,基于时间戳生成水位线。在WatermarkGenerator 接口中,主要又有两个方法:onEvent()和 onPeriodicEmit()。
⚫ onEvent:每个事件(数据)到来都会调用的方法,它的参数有当前事件、时间戳,以及允许发出水位线的一个 WatermarkOutput,可以基于事件做各种操作
⚫ onPeriodicEmit:周期性调用的方法,可以由 WatermarkOutput 发出水位线。周期时间为处理时间,可以调用环境配置的.setAutoWatermarkInterval()方法来设置,默认为200ms。
env.getConfig().setAutoWatermarkInterval(60 * 1000L);
3. Flink 内置水位线生成器
WatermarkStrategy 这个接口是一个生成水位线策略的抽象,让我们可以灵活地实现自己的需求;但看起来有些复杂,如果想要自己实现应该还是比较麻烦的。好在 Flink 充分考虑到了我们的痛苦,提供了内置的水位线生成器(WatermarkGenerator),不仅开箱即用简化了编程,而且也为我们自定义水位线策略提供了模板。这两个生成器可以通过调用 WatermarkStrategy 的静态辅助方法来创建。它们都是周期性生成水位线的,分别对应着处理有序流和乱序流的场景。
(1)有序流
对于有序流,主要特点就是时间戳单调增长(Monotonously Increasing Timestamps),所以永远不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景,直接调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。简单来说,就是直接拿当前最大的时间戳作为水位线就可以了。
stream.assignTimestampsAndWatermarks( WatermarkStrategy.<Event>forMonotonousTimestamps() .withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
上面代码中我们调用.withTimestampAssigner()方法,将数据中的 timestamp 字段提取出来,作为时间戳分配给数据元素;然后用内置的有序流水位线生成器构造出了生成策略。这样,提取出的数据时间戳,就是我们处理计算的事件时间。这里需要注意的是,时间戳和水位线的单位,必须都是毫秒。
(2)乱序流
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间(Fixed Amount of Lateness)。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用 WatermarkStrategy. forBoundedOutOfOrderness()方法就可以实现。这个方法需要传入一个 maxOutOfOrderness 参数,表示“最大乱序程度”,它表示数据流中乱序数据时间戳的最大差值;如果我们能确定乱序程度,那么设置对应时间长度的延迟,就可以等到所有的乱序数据了。
代码示例如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import java.time.Duration;
public class WatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSource())
// 插入水位线的逻辑
.assignTimestampsAndWatermarks(
// 针对乱序流插入水位线,延迟时间设置为 5s
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
// 抽取时间戳的逻辑
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
) .print();
env.execute();
}
}
上面代码中,我们同样提取了 timestamp 字段作为时间戳,并且以 5 秒的延迟时间创建了处理乱序流的水位线生成器。
事实上,有序流的水位线生成器本质上和乱序流是一样的,相当于延迟设为 0 的乱序流水位线生成器,两者完全等同:
WatermarkStrategy.forMonotonousTimestamps()
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(0))
这里需要注意的是,乱序流中生成的水位线真正的时间戳,其实是当前最大时间戳 – 延迟时间 – 1,这里的单位是毫秒。为什么要减 1 毫秒呢?我们可以回想一下水位线的特点:时间戳为 t 的水位线,表示时间戳≤t 的数据全部到齐,不会再来了。如果考虑有序流,也就是延迟时间为 0 的情况,那么时间戳为 7 秒的数据到来时,之后其实是还有可能继续来 7 秒的数据的;所以生成的水位线不是 7 秒,而是 6 秒 999 毫秒,7 秒的数据还可以继续来。这一点可以在 BoundedOutOfOrdernessWatermarks 的源码中明显地看到:
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
4. 自定义水位线策略
一般来说,Flink 内置的水位线生成器就可以满足应用需求了。不过有时我们的业务逻辑可能非常复杂,这时对水位线生成的逻辑也有更高的要求,我们就必须自定义实现水位线策略WatermarkStrategy 了。
在 WatermarkStrategy 中,时间戳分配器 TimestampAssigner 都是大同小异的,指定字段提取时间戳就可以了;而不同策略的关键就在于 WatermarkGenerator 的实现。整体说来,Flink有两种不同的生成水位线的方式:一种是周期性的(Periodic),另一种是断点式的(Punctuated)。还记得 WatermarkGenerator 接口中的两个方法吗?——onEvent()和 onPeriodicEmit(),前者是在每个事件到来时调用,而后者由框架周期性调用。周期性调用的方法中发出水位线,自然就是周期性生成水位线;而在事件触发的方法中发出水位线,自然就是断点式生成了。两种方式的不同就集中体现在这两个方法的实现上。
(1)周期性水位线生成器(Periodic Generator)
周期性生成器一般是通过 onEvent()观察判断输入的事件,而在 onPeriodicEmit()里发出水位线。
下面是一段自定义周期性生成水位线的代码:
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// 自定义水位线的产生
public class CustomWatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSource()).assignTimestampsAndWatermarks(new CustomWatermarkStrategy()) .print();
env.execute();
}
public static class CustomWatermarkStrategy implements WatermarkStrategy<Event> {
@Override
public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp; // 告诉程序数据源里的时间戳是哪一个字段
}
};
}
@Override
public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CustomPeriodicGenerator();
}
}
public static class CustomPeriodicGenerator implements WatermarkGenerator<Event> {
private Long delayTime = 5000L; // 延迟时间
private Long maxTs = Long.MIN_VALUE + delayTime + 1L; // 观察到的最大时间戳
@Override
public void onEvent(Event event, long eventTimestamp, WatermarkOutput output) {
// 每来一条数据就调用一次
maxTs = Math.max(event.timestamp, maxTs); // 更新最大时间戳
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发射水位线,默认 200ms 调用一次
output.emitWatermark(new Watermark(maxTs - delayTime - 1L));
}
}
}
我们在 onPeriodicEmit()里调用 output.emitWatermark(),就可以发出水位线了;这个方法由系统框架周期性地调用,默认 200ms 一次。所以水位线的时间戳是依赖当前已有数据的最大时间戳的(这里的实现与内置生成器类似,也是减去延迟时间再减 1),但具体什么时候生成与数据无关。
(2)断点式水位线生成器(Punctuated Generator)
断点式生成器会不停地检测 onEvent()中的事件,当发现带有水位线信息的特殊事件时,就立即发出水位线。一般来说,断点式生成器不会通过 onPeriodicEmit()发出水位线。
自定义的断点式水位线生成器代码如下:
public class CustomPunctuatedGenerator implements WatermarkGenerator<Event> {
@Override
public void onEvent(Event r, long eventTimestamp, WatermarkOutput output) {
// 只有在遇到特定的 itemId 时,才发出水位线
if (r.user.equals("Mary")) {
output.emitWatermark(new Watermark(r.timestamp - 1));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 不需要做任何事情,因为我们在 onEvent 方法中发射了水位线
}
}
我们在 onEvent()中判断当前事件的 user 字段,只有遇到“Mary”这个特殊的值时,才调用output.emitWatermark()发出水位线。这个过程是完全依靠事件来触发的,所以水位线的生成一定在某个数据到来之后。
5. 在自定义数据源中发送水位线
我们也可以在自定义的数据源中抽取事件时间,然后发送水位线。这里要注意的是,在自定义数据源中发送了水位线以后,就不能再在程序中使用 assignTimestampsAndWatermarks 方法 来 生 成 水 位 线 了 。 在 自 定 义 数 据 源 中 生 成 水 位 线 和 在 程 序 中 使 用assignTimestampsAndWatermarks 方法生成水位线二者只能取其一。示例程序如下:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import java.util.Calendar;
import java.util.Random;
public class EmitWatermarkInSourceFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSourceWithWatermark()).print();
env.execute();
}
// 泛型是数据源中的类型
public static class ClickSourceWithWatermark implements SourceFunction<Event>
{
private boolean running = true;
@Override
public void run(SourceContext<Event> sourceContext) throws Exception {
Random random = new Random();
String[] userArr = {"Mary", "Bob", "Alice"};
String[] urlArr = {"./home", "./cart", "./prod?id=1"};
while (running) {
long currTs = Calendar.getInstance().getTimeInMillis(); // 毫秒时间戳
String username = userArr[random.nextInt(userArr.length)];
String url = urlArr[random.nextInt(urlArr.length)];
Event event = new Event(username, url, currTs);
// 使用 collectWithTimestamp 方法将数据发送出去,并指明数据中的时间戳的字段
sourceContext.collectWithTimestamp(event, event.timestamp);
// 发送水位线
sourceContext.emitWatermark(new Watermark(event.timestamp - 1L));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running = false;
}
}
}
在自定义水位线中生成水位线相比 assignTimestampsAndWatermarks 方法更加灵活,可以任意的产生周期性的、非周期性的水位线,以及水位线的大小也完全由我们自定义。所以非常适合用来编写 Flink 的测试程序,测试 Flink 的各种各样的特性。
6.2.4 水位线的传递
我们知道水位线是数据流中插入的一个标记,用来表示事件时间的进展,它会随着数据一起在任务间传递。如果只是直通式(forward)的传输,那很简单,数据和水位线都是按照本身的顺序依次传递、依次处理的;一旦水位线到达了算子任务, 那么这个任务就会将它内部的时钟设为这个水位线的时间戳。
在这里,“任务的时钟”其实仍然是各自为政的,并没有统一的时钟。实际应用中往往上下游都有多个并行子任务,为了统一推进事件时间的进展,我们要求上游任务处理完水位线、时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。这样,后续任务就不需要依赖原始数据中的时间戳(经过转化处理后,数据可能已经改变了),也可以知道当前事件时间了。
可是还有另外一个问题,那就是在“重分区”(redistributing)的传输模式下,一个任务有可能会收到来自不同分区上游子任务的数据。而不同分区的子任务时钟并不同步,所以同一时刻发给下游任务的水位线可能并不相同。这时下游任务又该听谁的呢?
这就要回到水位线定义的本质了:它表示的是“当前时间之前的数据,都已经到齐了”。这是一种保证,告诉下游任务“只要你接到这个水位线,就代表之后我不会再给你发更早的数据了,你可以放心做统计计算而不会遗漏数据”。所以如果一个任务收到了来自上游并行任务的不同的水位线,说明上游各个分区处理得有快有慢,进度各不相同比如上游有两个并行子任务都发来了水位线,一个是 5 秒,一个是 7 秒;这代表第一个并行任务已经处理完 5 秒之前的所有数据,而第二个并行任务处理到了 7 秒。那这时自己的时钟怎么确定呢?当然也要以“这之前的数据全部到齐”为标准。如果我们以较大的水位线 7 秒作为当前时间,那就表示“7 秒前的数据都已经处理完”,这显然不是事实——第一个上游分区才处理到 5 秒,5~7 秒的数据还会不停地发来;而如果以最小的水位线 5 秒作为当前时钟就不会有这个问题了,因为确实所有上游分区都已经处理完,不会再发 5 秒前的数据了。这让我们想到“木桶原理”:所有的上游并行任务就像围成木桶的一块块木板,它们中最短的那一块,决定了我们桶中的水位。
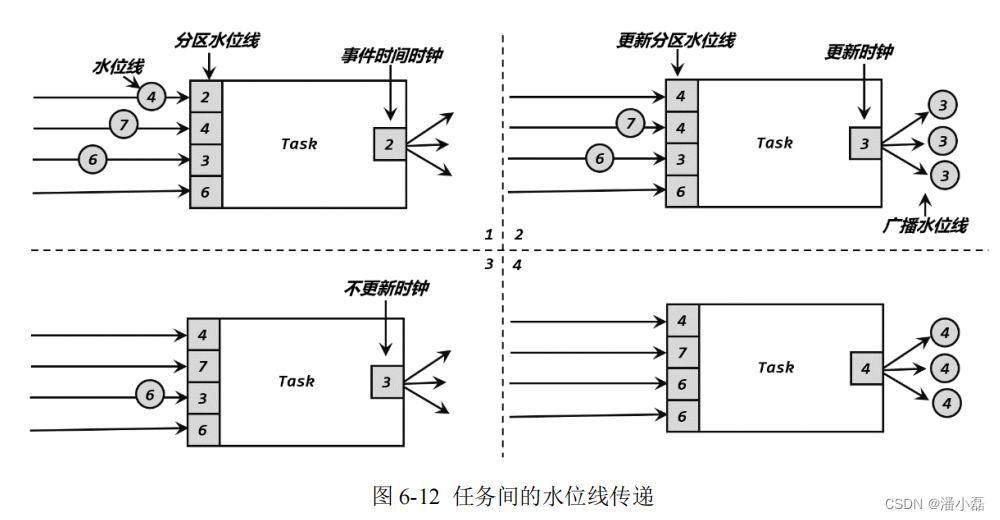
我们可以用一个具体的例子,将水位线在任务间传递的过程完整梳理一遍。如图 6-12 所示,当前任务的上游,有四个并行子任务,所以会接收到来自四个分区的水位线;而下游有三个并行子任务,所以会向三个分区发出水位线。具体过程如下:
(1)上游并行子任务发来不同的水位线,当前任务会为每一个分区设置一个“分区水位线”(Partition Watermark),这是一个分区时钟;而当前任务自己的时钟,就是所有分区时钟里最小的那个。
(2)当有一个新的水位线(第一分区的 4)从上游传来时,当前任务会首先更新对应的分区时钟;然后再次判断所有分区时钟中的最小值,如果比之前大,说明事件时间有了进展,当前任务的时钟也就可以更新了。这里要注意,更新后的任务时钟,并不一定是新来的那个分区水位线,比如这里改变的是第一分区的时钟,但最小的分区时钟是第三分区的 3,于是当前任务时钟就推进到了 3。当时钟有进展时,当前任务就会将自己的时钟以水位线的形式,广播给下游所有子任务。
(3)再次收到新的水位线(第二分区的 7)后,执行同样的处理流程。首先将第二个分区时钟更新为 7,然后比较所有分区时钟;发现最值没有变化,那么当前任务的时钟也不变,也不会向下游任务发出水位线。
(4)同样道理,当又一次收到新的水位线(第三分区的 6)之后,第三个分区时钟更新为6,同时所有分区时钟最小值变成了第一分区的4,所以当前任务的时钟推进到 4,并发出时间戳为 4 的水位线,广播到下游各个分区任务。
水位线在上下游任务之间的传递,非常巧妙地避免了分布式系统中没有统一时钟的问题,每个任务都以“处理完之前所有数据”为标准来确定自己的时钟,就可以保证窗口处理的结果总是正确的。对于有多条流合并之后进行处理的场景,水位线传递的规则是类似的。关于 Flink中的多流转换,我们会在后续章节中介绍。
6.2.5 水位线的总结
水位线在事件时间的世界里面,承担了时钟的角色。也就是说在事件时间的流中,水位线是唯一的时间尺度。如果想要知道现在几点,就要看水位线的大小。后面讲到的窗口的闭合,以及定时器的触发都要通过判断水位线的大小来决定是否触发。
水位线是一种特殊的事件,由程序员通过编程插入的数据流里面,然后跟随数据流向下游流动。水位线的默认计算公式:水位线 = 观察到的最大事件时间 – 最大延迟时间 – 1 毫秒。所以这里涉及到一个问题,就是不同的算子看到的水位线的大小可能是不一样的。因为下游的算子可能并未接收到来自上游算子的水位线,导致下游算子的时钟要落后于上游算子的时钟。比如 map->reduce 这样的操作,如果在 map 中编写了非常耗时间的代码,将会阻塞水位线的向下传播,因为水位线也是数据流中的一个事件,位于水位线前面的数据如果没有处理完毕,那么水位线不可能弯道超车绕过前面的数据向下游传播,也就是说会被前面的数据阻塞。这样就会影响到下游算子的聚合计算,因为下游算子中无论由窗口聚合还是定时器的操作,都需要水位线才能触发执行。这也就告诉了我们,在编写 Flink 程序时,一定要谨慎的编写每一个算子的计算逻辑,尽量避免大量计算或者是大量的 IO 操作,这样才不会阻塞水位线的向下传递。在数据流开始之前,Flink 会插入一个大小是负无穷大(在 Java 中是-Long.MAX_VALUE)的水位线,而在数据流结束时,Flink 会插入一个正无穷大(Long.MAX_VALUE)的水位线,保证所有的窗口闭合以及所有的定时器都被触发。
对于离线数据集,Flink 也会将其作为流读入,也就是一条数据一条数据的读取。在这种情况下,Flink 对于离线数据集,只会插入两次水位线,也就是在最开始处插入负无穷大的水位线,在结束位置插入一个正无穷大的水位线。因为只需要插入两次水位线,就可以保证计算的正确,无需在数据流的中间插入水位线了。
水位线的重要性在于它的逻辑时钟特性,而逻辑时钟这个概念可以说是分布式系统里面最为重要的概念之一了,理解透彻了对理解各种分布式系统非常有帮助。具体可以参考 LeslieLamport 的论文。
6.3 窗口(Window)
我们已经了解了 Flink 中事件时间和水位线的概念,那它们有什么具体应用呢?当然是做基于时间的处理计算了。其中最常见的场景,就是窗口聚合计算。之前我们已经了解了 Flink 中基本的聚合操作。在流处理中,我们往往需要面对的是连续不断、无休无止的无界流,不可能等到所有所有数据都到齐了才开始处理。所以聚合计算其实只能针对当前已有的数据——之后再有数据到来,就需要继续叠加、再次输出结果。这样似乎很“实时”,但现实中大量数据一般会同时到来,需要并行处理,这样频繁地更新结果就会给系统带来很大负担了。更加高效的做法是,把无界流进行切分,每一段数据分别进行聚合,结果只输出一次。这就相当于将无界流的聚合转化为了有界数据集的聚合,这就是所谓的“窗口”(Window)聚合操作。窗口聚合其实是对实时性和处理效率的一个权衡。在实际应用中,我们往往更关心一段时间内数据的统计结果,比如在过去的 1 分钟内有多少用户点击了网页。在这种情况下,我们就可以定义一个窗口,收集最近一分钟内的所有用户点击数据,然后进行聚合统计,最终输出一个结果就可以了。在 Flink 中,提供了非常丰富的窗口操作,下面我们就来详细介绍。
6.3.1 窗口的概念
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
在 Flink 中, 窗口就是用来处理无界流的核心。我们很容易把窗口想象成一个固定位置的“框”,数据源源不断地流过来,到某个时间点窗口该关闭了,就停止收集数据、触发计算并输出结果。例如,我们定义一个时间窗口,每 10 秒统计一次数据,那么就相当于把窗口放在那里,从 0 秒开始收集数据;到 10 秒时,处理当前窗口内所有数据,输出一个结果,然后清空窗口继续收集数据;到 20 秒时,再对窗口内所有数据进行计算处理,输出结果;依次类推,如图 6-13 所示。
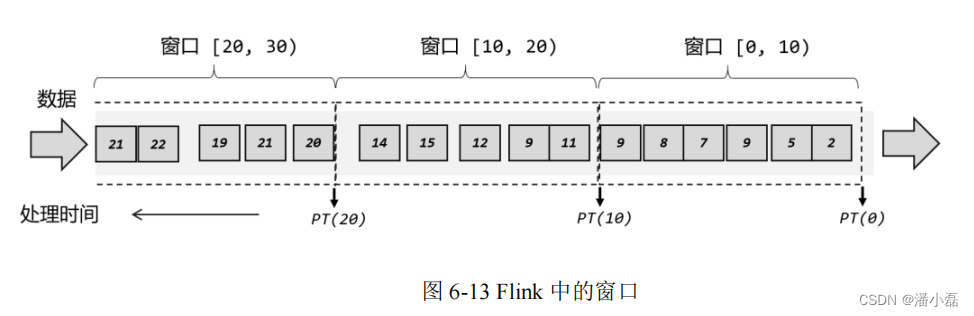
这里注意为了明确数据划分到哪一个窗口,定义窗口都是包含起始时间、不包含结束时间的,用数学符号表示就是一个左闭右开的区间,例如 0~10 秒的窗口可以表示为[0, 10),这里单位为秒。
对于处理时间下的窗口而言,这样理解似乎没什么问题。因为窗口的关闭是基于系统时间的,赶不上这班车的数据,就只能坐下一班车了——正如上图中,0~10 秒的窗口关闭后,可能还有时间戳为 9 的数据会来,它就只能进入 10-20 秒的窗口了。这样会造成窗口处理结果的不准确。然而如果我们采用事件时间语义,就会有些费解了。由于有乱序数据,我们需要设置一个延迟时间来等所有数据到齐。比如上面的例子中,我们可以设置延迟时间为 2 秒,如图 6-14所示,这样 0-10 秒的窗口会在时间戳为 12 的数据到来之后,才真正关闭计算输出结果,这样就可以正常包含迟到的 9 秒数据了。
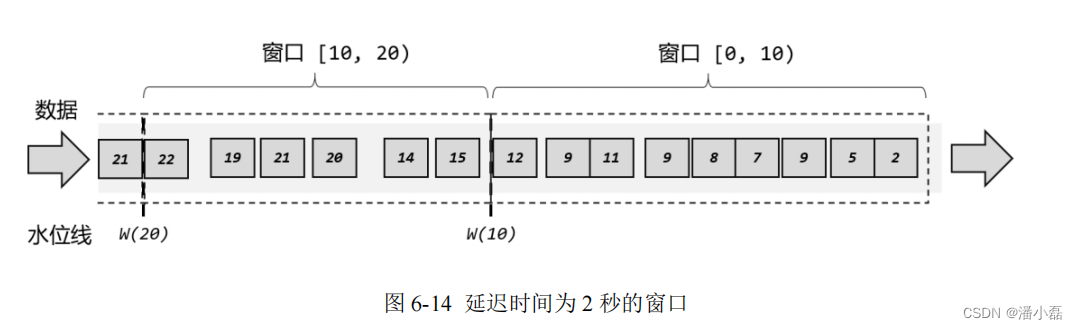
但是这样一来,0~10 秒的窗口不光包含了迟到的 9 秒数据,连 11 秒和 12 秒的数据也包含进去了。我们为了正确处理迟到数据,结果把早到的数据划分到了错误的窗口——最终结果都是错误的。
所以在 Flink 中,窗口其实并不是一个“框”,流进来的数据被框住了就只能进这一个窗口。相比之下,我们应该把窗口理解成一个“桶”,如图 6-15 所示。在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
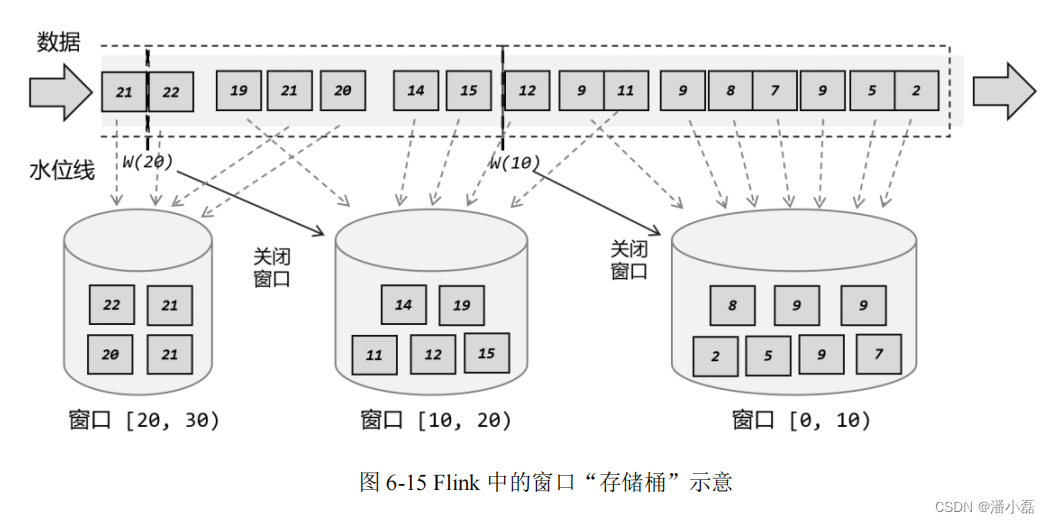
我们可以梳理一下事件时间语义下,之前例子中窗口的处理过程:
(1)第一个数据时间戳为 2,判断之后创建第一个窗口[0, 10),并将 2 秒数据保存进去;
(2)后续数据依次到来,时间戳均在 [0, 10)范围内,所以全部保存进第一个窗口;
(3)11 秒数据到来,判断它不属于[0, 10)窗口,所以创建第二个窗口[10, 20),并将 11秒的数据保存进去。由于水位线设置延迟时间为 2 秒,所以现在的时钟是 9 秒,第一个窗口也没有到关闭时间;
(4)之后又有 9 秒数据到来,同样进入[0, 10)窗口中;
(5)12 秒数据到来,判断属于[10, 20)窗口,保存进去。这时产生的水位线推进到了 10秒,所以 [0, 10)窗口应该关闭了。第一个窗口收集到了所有的 7 个数据,进行处理计算后输出结果,并将窗口关闭销毁;
(6)同样的,之后的数据依次进入第二个窗口,遇到 20 秒的数据时会创建第三个窗口[20, 30)并将数据保存进去;遇到 22 秒数据时,水位线达到了 20 秒,第二个窗口触发计算,输出结果并关闭。
这里需要注意的是,Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭,事实上“触发计算”和“窗口关闭”两个行为也可以分开,这部分内容我们会在后面详述。
(1)时间窗口(Time Window)
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。
用结束时间减去开始时间,得到这段时间的长度,就是窗口的大小(window size)。这里的时间可以是不同的语义,所以我们可以定义处理时间窗口和事件时间窗口。Flink 中有一个专门的类来表示时间窗口,名称就叫作 TimeWindow。这个类只有两个私有属性:start 和 end,表示窗口的开始和结束的时间戳,单位为毫秒。
private final long start;
private final long end;
我们可以调用公有的 getStart()和 getEnd()方法直接获取这两个时间戳。另外,TimeWindow还提供了一个 maxTimestamp()方法,用来获取窗口中能够包含数据的最大时间戳。
public long maxTimestamp() {
return end - 1;
}
很明显,窗口中的数据,最大允许的时间戳就是 end - 1,这也就代表了我们定义的窗口时间范围都是左闭右开的区间[start,end)。或许有较真的读者会问,为什么不把窗口区间定义成左开右闭、包含上结束时间呢?这样maxTimestamp 跟 end 一致,不就可以省去一个方法的定义吗?这主要是为了方便判断窗口什么时候关闭。对于事件时间语义,窗口的关闭需要水位线推进到窗口的结束时间;而我们知道,水位线 Watermark(t)代表的含义是“时间戳小于等于 t 的数据都已到齐,不会再来了”。为了简化分析,我们先不考虑乱序流设置的延迟时间。那么当新到一个时间戳为 t 的数据时,当前水位线的时间推进到了 t – 1(还记得乱序流里生成水位线的减一操作吗?)。所以当时间戳为 end 的数据到来时,水位线推进到了 end - 1;如果我们把窗口定义为不包含 end,那么当前的水位线刚好就是 maxTimestamp,表示窗口能够包含的数据都已经到齐,我们就可以直接关闭窗口了。所以有了这样的定义,我们就不需要再去考虑那烦人的“减一”了,直接看到时间戳为 end 的数据,就关闭对应的窗口。如果为乱序流设置了水位线延迟时间 delay,也只需要等到时间戳为 end + delay 的数据,就可以关窗了。为了更容易理解,本书中我们对水位线的分析,统一不再考虑“减一”的问题。
(2)计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。这相当于座位有限、“人满就发车”,是否发车与时间无关。每个窗口截取数据的个数,就是窗口的大小。计数窗口相比时间窗口就更加简单,我们只需指定窗口大小,就可以把数据分配到对应的窗口中了。在 Flink 内部也并没有对应的类来表示计数窗口,底层是通过“全局窗口”(Global Window)来实现的。关于全局窗口,我们稍后讲解。
2. 按照窗口分配数据的规则分类
时间窗口和计数窗口,只是对窗口的一个大致划分;在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以有不同的功能应用。
根据分配数据的规则,窗口的具体实现可以分为 4 类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。
下面我们来做具体介绍。
(1)滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动,那就好像它在不停地向前“翻滚”一样。这是最简单的窗口形式,我们之前所举的例子都是滚动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。
滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)。比如我们可以定义一个长度为 1 小时的滚动时间窗口,那么每个小时就会进行一次统计;或者定义一个长度为 10 的滚动计数窗口,就会每 10 个数进行一次统计。
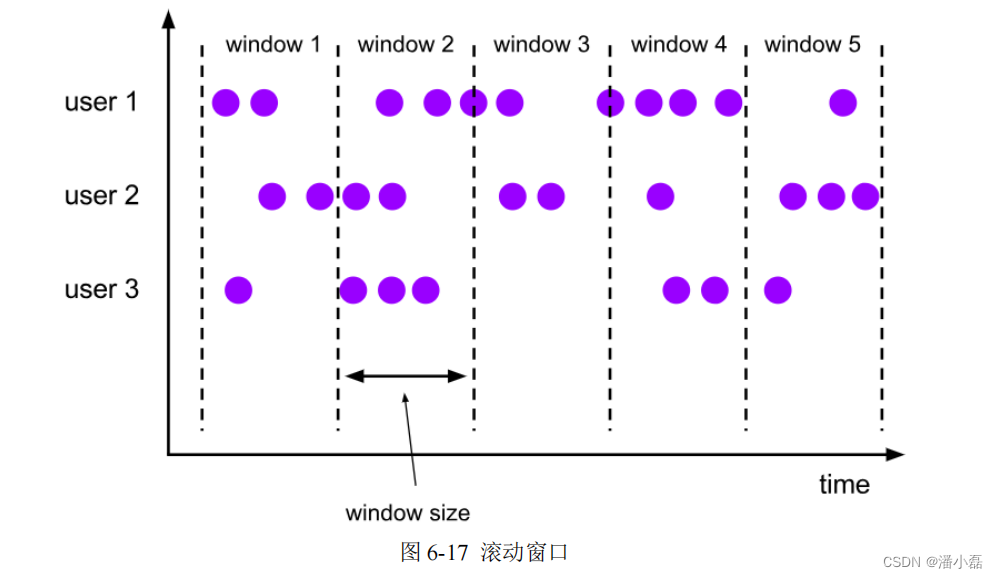
如图 6-17 所示,小圆点表示流中的数据,我们对数据按照 userId 做了分区。当固定了窗口大小之后,所有分区的窗口划分都是一致的;窗口没有重叠,每个数据只属于一个窗口。滚动窗口应用非常广泛,它可以对每个时间段做聚合统计,很多 BI 分析指标都可以用它来实现。
(2)滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。既然是向前滑动,那么每一步滑多远,就也是可以控制的。所以定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个“滑动步长”(window slide),它其实就代表了窗口计算的频率。滑动的距离代表了下个窗口开始的时间间隔,而窗口大小是固定的,所以也就是两个窗口结束时间的间隔;窗口在结束时间触发计算输出结果,那么滑动步长就代表了计算频率。例如,我们定义一个长度为 1 小时、滑动步长为 5 分钟的滑动窗口,那么就会统计 1 小时内的数据,每 5 分钟统计一次。同样,滑动窗口可以基于时间定义,也可以基于数据个数定义。
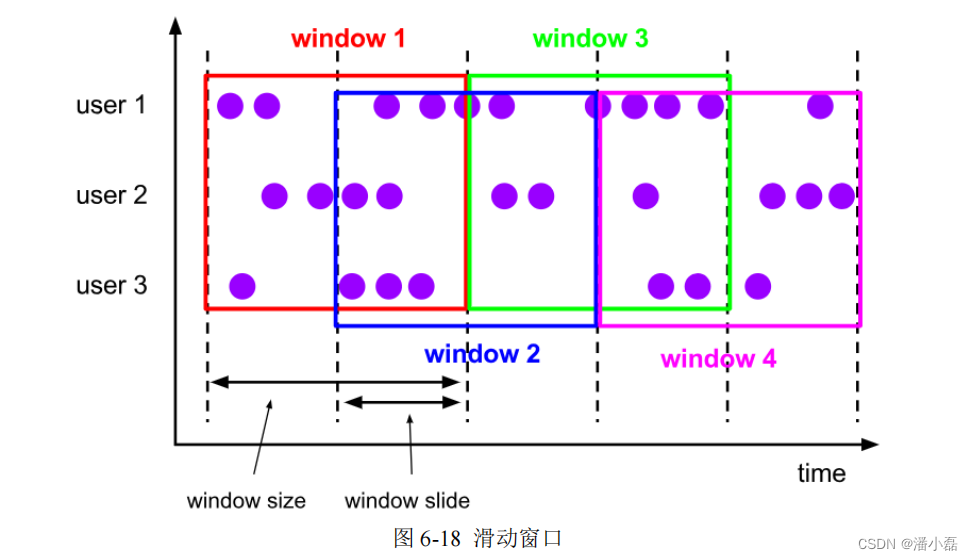
我们可以看到,当滑动步长小于窗口大小时,滑动窗口就会出现重叠,这时数据也可能会被同时分配到多个窗口中。而具体的个数,就由窗口大小和滑动步长的比值(size/slide)来决定。如图 6-18 所示,滑动步长刚好是窗口大小的一半,那么每个数据都会被分配到 2 个窗口里。比如我们定义的窗口长度为 1 小时、滑动步长为 30 分钟,那么对于 8 点 55 分的数据,应该同时属于[8 点, 9 点)和[8 点半, 9 点半)两个窗口;而对于 8 点 10 分的数据,则同时属于[8点, 9 点)和[7 点半, 8 点半)两个窗口。所以,滑动窗口其实是固定大小窗口的更广义的一种形式;换句话说,滚动窗口也可以看作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide)。当然,我们也可以定义滑动步长大于窗口大小,这样的话就会出现窗口不重叠、但会有间隔的情况;这时有些数据不属于任何一个窗口,就会出现遗漏统计。所以一般情况下,我们会让滑动步长小于窗口大小,并尽量设置为整数倍的关系。
在一些场景中,可能需要统计最近一段时间内的指标,而结果的输出频率要求又很高,甚至要求实时更新,比如股票价格的 24 小时涨跌幅统计,或者基于一段时间内行为检测的异常报警。这时滑动窗口无疑就是很好的实现方式。
(3)会话窗口(Session Windows)
会话窗口顾名思义,是基于“会话”(session)来来对数据进行分组的。这里的会话类似Web 应用中 session 的概念,不过并不表示两端的通讯过程,而是借用会话超时失效的机制来描述窗口。简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。这就好像我们打电话一样,如果时不时总能说点什么,那说明还没聊完;如果陷入了尴尬的沉默,半天都没话说,那自然就可以挂电话了。
与滑动窗口和滚动窗口不同,会话窗口只能基于时间来定义,而没有“会话计数窗口”的概念。这很好理解,“会话”终止的标志就是“隔一段时间没有数据来”,如果不依赖时间而改成个数,就成了“隔几个数据没有数据来”,这完全是自相矛盾的说法。而同样是基于这个判断标准,这“一段时间”到底是多少就很重要了,必须明确指定。对于会话窗口而言,最重要的参数就是这段时间的长度(size),它表示会话的超时时间,也就是两个会话窗口之间的最小距离。如果相邻两个数据到来的时间间隔(Gap)小于指定的大小(size),那说明还在保持会话,它们就属于同一个窗口;如果 gap 大于 size,那么新来的数据就应该属于新的会话窗口,而前一个窗口就应该关闭了。在具体实现上,我们可以设置静态固定的大小(size),也可以通过一个自定义的提取器(gap extractor)动态提取最小间隔 gap 的值。
考虑到事件时间语义下的乱序流,这里又会有一些麻烦。相邻两个数据的时间间隔 gap大于指定的 size,我们认为它们属于两个会话窗口,前一个窗口就关闭;可在数据乱序的情况下,可能会有迟到数据,它的时间戳刚好是在之前的两个数据之间的。这样一来,之前我们判断的间隔中就不是“一直没有数据”,而缩小后的间隔有可能会比 size 还要小——这代表三个数据本来应该属于同一个会话窗口。
所以在 Flink 底层,对会话窗口的处理会比较特殊:每来一个新的数据,都会创建一个新的会话窗口;然后判断已有窗口之间的距离,如果小于给定的 size,就对它们进行合并(merge)操作。在 Window 算子中,对会话窗口会有单独的处理逻辑。
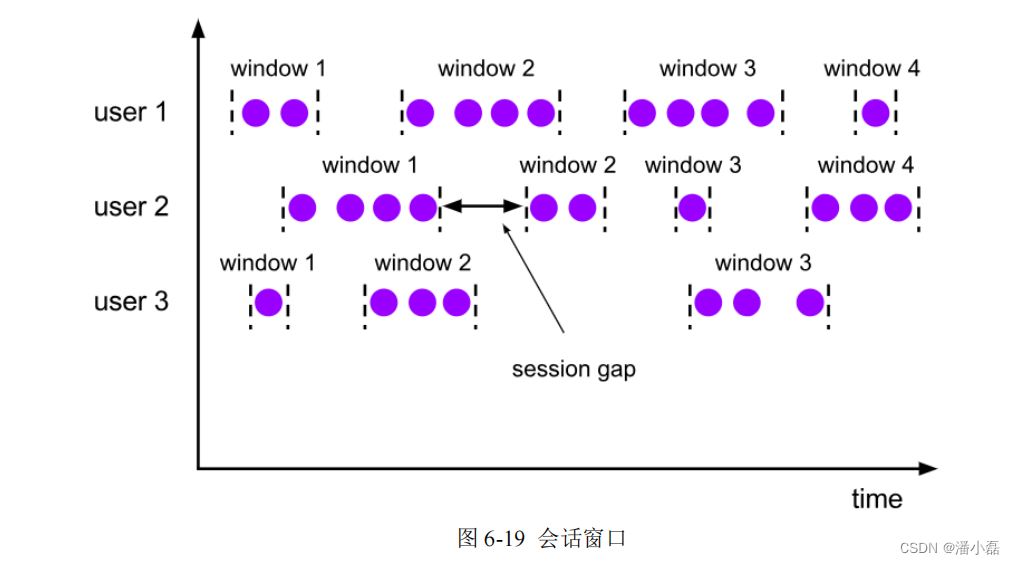
我们可以看到,与前两种窗口不同,会话窗口的长度不固定,起始和结束时间也是不确定的,各个分区之间窗口没有任何关联。如图 6-19 所示,会话窗口之间一定是不会重叠的,而且会留有至少为 size 的间隔(session gap)。在一些类似保持会话的场景下,往往可以使用会话窗口来进行数据的处理统计。
(4)全局窗口(Global Windows)
还有一类比较通用的窗口,就是“全局窗口”。这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中;说直白一点,就跟没分窗口一样。无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”(Trigger)。关于触发器,我们会在后面的 6.3.6 小节进行讲解。
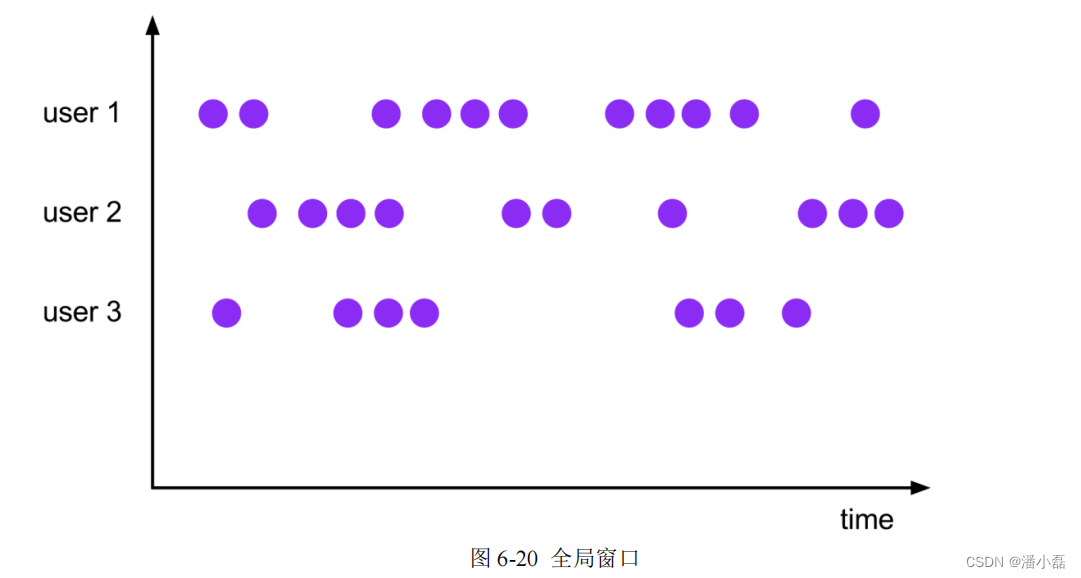
如图 6-20 所示,可以看到,全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink 中的计数窗口(Count Window),底层就是用全局窗口实现的。
6.3.3 窗口 API 概览
已经了解了 Flink 中窗口的概念和分类,接下来我们就要看看在代码中怎样使用了。这一小节我们先对 Window API 有一个整体认识,了解一下基本的调用方法。
1. 按键分区(Keyed)和非按键分区(Non-Keyed)
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流 KeyedStream来开窗,还是直接在没有按键分区的 DataStream 上开窗。也就是说,在调用窗口算子之前,是否有 keyBy 操作。
(1)按键分区窗口(Keyed Windows)
经过按键分区 keyBy 操作后,数据流会按照 key 被分为多条逻辑流(logical streams),这就是 KeyedStream。基于 KeyedStream 进行窗口操作时, 窗口计算会在多个并行子任务上同时执行。相同 key 的数据会被发送到同一个并行子任务,而窗口操作会基于每个 key 进行单独的处理。所以可以认为,每个 key 上都定义了一组窗口,各自独立地进行统计计算。在代码实现上,我们需要先对 DataStream 调用.keyBy()进行按键分区,然后再调用.window()定义窗口。
stream.keyBy(...).window(...)
(2)非按键分区(Non-Keyed Windows)
如果没有进行 keyBy,那么原始的 DataStream 就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了 1。所以在实际应用中一般不推荐使用这种方式。
在代码中,直接基于 DataStream 调用.windowAll()定义窗口。
stream.windowAll(...)
这里需要注意的是,对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的,windowAll 本身就是一个非并行的操作。
2. 代码中窗口 API 的调用
有了前置的基础,接下来我们就可以真正在代码中实现一个窗口操作了。简单来说,窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
stream.keyBy(<key selector>).window(<window assigner>).aggregate(<window function>)
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,而窗口函数的调用方法也不只.aggregate()一种,我们接下来就详细展开讲解。另外,在实际应用中,一般都需要并行执行任务,非按键分区很少用到,所以我们之后都以按键分区窗口为例;如果想要实现非按键分区窗口,只要前面不做 keyBy,后面调用.window()时直接换成.windowAll()就可以了。
6.3.4 窗口分配器(Window Assigners)
定义窗口分配器(Window Assigners)是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。从 6.3.2 节的介绍中我们知道,窗口分配数据的规则,其实就对应着不同的窗口类型。所以可以说,窗口分配器其实就是在指定窗口的类型。窗口分配器最通用的定义方式,就是调用.window()方法。这个方法需要传入一个WindowAssigner 作为参数,返回 WindowedStream。如果是非按键分区窗口,那么直接调用.windowAll()方法,同样传入一个 WindowAssigner,返回的是 AllWindowedStream。窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型 Flink中都给出了内置的分配器实现,我们可以方便地调用实现各种需求。
1. 时间窗口
时间窗口是最常用的窗口类型,又可以细分为滚动、滑动和会话三种。在较早的版本中,可以直接调用.timeWindow()来定义时间窗口;这种方式非常简洁,但使用事件时间语义时需要另外声明,程序员往往因为忘记这点而导致运行结果错误。所以在1.12 版本之后,这种方式已经被弃用了,标准的声明方式就是直接调用.window(),在里面传入对应时间语义下的窗口分配器。这样一来,我们不需要专门定义时间语义,默认就是事件时间;如果想用处理时间,那么在这里传入处理时间的窗口分配器就可以了。
下面我们列出了每种情况的代码实现。
(1)滚动处理时间窗口
窗口分配器由类 TumblingProcessingTimeWindows 提供,需要调用它的静态方法.of()。
stream.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
这里.of()方法需要传入一个 Time 类型的参数 size,表示滚动窗口的大小,我们这里创建了一个长度为 5 秒的滚动窗口。另外,.of()还有一个重载方法,可以传入两个 Time 类型的参数:size 和 offset。第一个参数当然还是窗口大小,第二个参数则表示窗口起始点的偏移量。这里需要多做一些解释:对于我们之前的定义,滚动窗口其实只有一个 size 是不能唯一确定的。比如我们定义 1 天的滚动窗口,从每天的 0 点开始计时是可以的,统计的就是一个自然日的所有数据;而如果从每天的凌晨 2 点开始计时其实也完全没问题,只不过统计的数据变成了每天 2 点到第二天 2 点。这个起始点的选取,其实对窗口本身的类型没有影响;而为了方便应用,默认的起始点时间戳是窗口大小的整倍数。也就是说,如果我们定义 1 天的窗口,默认就从 0 点开始;如果定义 1 小时的窗口,默认就从整点开始。而如果我们非要不从这个默认值开始,那就可以通过设置偏移量offset 来调整。
这里读者可能会觉得奇怪:这个功能好像没什么用,非要弄个偏移量不是给自己找别扭吗?这其实是有实际用途的。我们知道,不同国家分布在不同的时区。标准时间戳其实就是1970 年 1 月 1 日 0 时 0 分 0 秒 0 毫秒开始计算的一个毫秒数,而这个时间是以 UTC 时间,也就是 0 时区(伦敦时间)为标准的。我们所在的时区是东八区,也就是 UTC+8,跟 UTC 有 8小时的时差。我们定义 1 天滚动窗口时,如果用默认的起始点,那么得到就是伦敦时间每天 0点开启窗口,这时是北京时间早上 8 点。那怎样得到北京时间每天 0 点开启的滚动窗口呢?只要设置-8 小时的偏移量就可以了:
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))
(2)滑动处理时间窗口
窗口分配器由类 SlidingProcessingTimeWindows 提供,同样需要调用它的静态方法.of()。
stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
这里.of()方法需要传入两个 Time 类型的参数:size 和 slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长。我们这里创建了一个长度为 10 秒、滑动步长为 5 秒的滑动窗口。
滑动窗口同样可以追加第三个参数,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
(3)处理时间会话窗口
窗口分配器由类 ProcessingTimeSessionWindows 提供,需要调用它的静态方法.withGap()或者.withDynamicGap()。
stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
这里.withGap()方法需要传入一个 Time 类型的参数 size,表示会话的超时时间,也就是最小间隔 session gap。我们这里创建了静态会话超时时间为 10 秒的会话窗口。
.window(ProcessingTimeSessionWindows.withDynamicGap(new
SessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
@Override
public long extract(Tuple2<String, Long> element) {
// 提取 session gap 值返回, 单位毫秒
return element.f0.length() * 1000;
}
}))
这里.withDynamicGap()方法需要传入一个 SessionWindowTimeGapExtractor 作为参数,用来定义 session gap 的动态提取逻辑。在这里,我们提取了数据元素的第一个字段,用它的长度乘以 1000 作为会话超时的间隔。
(4)滚动事件时间窗口
窗口分配器由类 TumblingEventTimeWindows 提供,用法与滚动处理事件窗口完全一致。
stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)
这里.of()方法也可以传入第二个参数 offset,用于设置窗口起始点的偏移量。
(5)滑动事件时间窗口
窗口分配器由类 SlidingEventTimeWindows 提供,用法与滑动处理事件窗口完全一致。
stream.keyBy(...).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
(6)事件时间会话窗口
窗口分配器由类 EventTimeSessionWindows 提供,用法与处理事件会话窗口完全一致。
stream.keyBy(...).window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
2. 计数窗口
计数窗口概念非常简单,本身底层是基于全局窗口(Global Window)实现的。Flink 为我们提供了非常方便的接口:直接调用.countWindow()方法。根据分配规则的不同,又可以分为滚动计数窗口和滑动计数窗口两类,下面我们就来看它们的具体实现。
(1)滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数 size,表示窗口的大小。
stream.keyBy(...)
.countWindow(10)
我们定义了一个长度为 10 的滚动计数窗口,当窗口中元素数量达到 10 的时候,就会触发计算执行并关闭窗口。
(2)滑动计数窗口
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数:size 和 slide,前者表示窗口大小,后者表示滑动步长。
stream.keyBy(...).countWindow(10,3)
我们定义了一个长度为 10、滑动步长为 3 的滑动计数窗口。每个窗口统计 10 个数据,每隔 3 个数据就统计输出一次结果。
3. 全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由 GlobalWindows 类提供。
stream.keyBy(...).window(GlobalWindows.create());
需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
6.3.5 窗口函数(Window Functions)
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪。所以在窗口分配器之后,必须再接上一个定义窗口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。
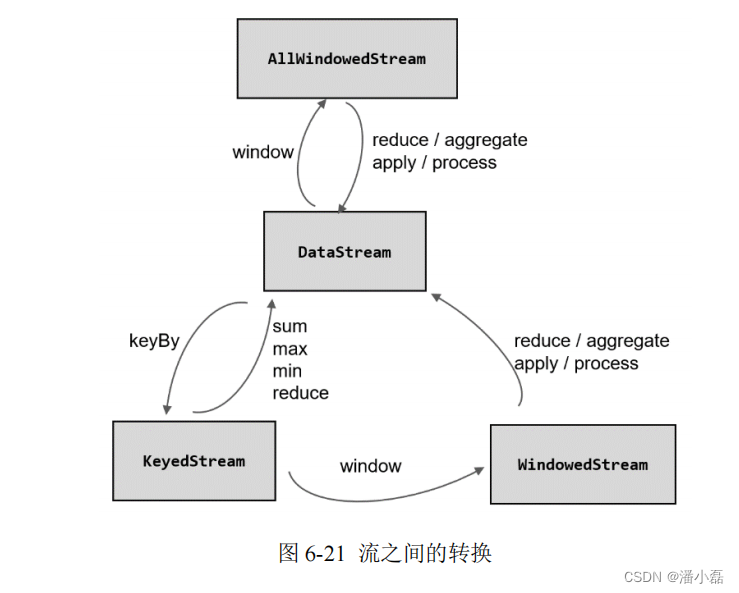
经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream,如图 6-21 所示。
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。下面我们来进行分别讲解。
1. 增量聚合函数(incremental aggregation functions)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。窗口对无限流的切分,可以看作得到了一个有界数据集。如果我们等到所有数据都收集齐,在窗口到了结束时间要输出结果的一瞬间再去进行聚合,显然就不够高效了——这相当于真的在用批处理的思路来做实时流处理。
为了提高实时性,我们可以再次将流处理的思路发扬光大:就像 DataStream 的简单聚合一样,每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了;区别只是在于不立即输出结果,而是要等到窗口结束时间。等到窗口到了结束时间需要输出计算结果的时候,我们只需要拿出之前聚合的状态直接输出,这无疑就大大提高了程序运行的效率和实时性。
典型的增量聚合函数有两个:ReduceFunction 和 AggregateFunction。
(1)归约函数(ReduceFunction)
最基本的聚合方式就是归约(reduce)。我们在基本转换的聚合算子中介绍过 reduce 的用法,窗口的归约聚合也非常类似,就是将窗口中收集到的数据两两进行归约。当我们进行流处理时,就是要保存一个状态;每来一个新的数据,就和之前的聚合状态做归约,这样就实现了增量式的聚合。
窗口函数中也提供了 ReduceFunction:只要基于 WindowedStream 调用.reduce()方法,然后传入 ReduceFunction 作为参数,就可以指定以归约两个元素的方式去对窗口中数据进行聚合了。这里的 ReduceFunction 其实与简单聚合时用到的 ReduceFunction 是同一个函数类接口,所以使用方式也是完全一样的。
我们回忆一下,ReduceFunction 中需要重写一个 reduce 方法,它的两个参数代表输入的两个元素,而归约最终输出结果的数据类型,与输入的数据类型必须保持一致。也就是说,中间聚合的状态和输出的结果,都和输入的数据类型是一样的。
下面是使用 ReduceFunction 进行增量聚合的代码示例。
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import
org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindo
ws;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
public class WindowReduceExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO) .withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
stream.map(new MapFunction<Event, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Event value) throws Exception {
// 将数据转换成二元组,方便计算
return Tuple2.of(value.user, 1L);
}
})
.keyBy(r -> r.f0)
// 设置滚动事件时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
// 定义累加规则,窗口闭合时,向下游发送累加结果
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
})
.print();
env.execute();
}
}
运行结果形式如下:
(Bob,1)
(Alice,2)
(Mary,2)
...
代码中我们对每个用户的行为数据进行了开窗统计。与 word count 逻辑类似,首先将数据转换成(user, count)的二元组形式(类型为 Tuple2<String, Long>),每条数据对应的初始 count值都是 1;然后按照用户 id 分组,在处理时间下开滚动窗口,统计每 5 秒内的用户行为数量。对于窗口的计算,我们用 ReduceFunction 对 count 值做了增量聚合:窗口中会将当前的总 count值保存成一个归约状态,每来一条数据,就会调用内部的 reduce 方法,将新数据中的 count值叠加到状态上,并得到新的状态保存起来。等到了 5 秒窗口的结束时间,就把归约好的状态直接输出。
这里需要注意,我们经过窗口聚合转换输出的数据,数据类型依然是二元组 Tuple2<String, Long>。
(2)聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。这就迫使我们必须在聚合前,先将数据转换(map)成预期结果类型;而在有些情况下,还需要对状态进行进一步处理才能得到输出结果,这时它们的类型可能不同,使用 ReduceFunction 就会非常麻烦。
例如,如果我们希望计算一组数据的平均值,应该怎样做聚合呢?很明显,这时我们需要计算两个状态量:数据的总和(sum),以及数据的个数(count),而最终输出结果是两者的商(sum/count)。如果用 ReduceFunction,那么我们应该先把数据转换成二元组(sum, count)的形式,然后进行归约聚合,最后再将元组的两个元素相除转换得到最后的平均值。本来应该只是一个任务,可我们却需要 map-reduce-map 三步操作,这显然不够高效。于是自然可以想到,如果取消类型一致的限制,让输入数据、中间状态、输出结果三者类型都可以不同,不就可以一步直接搞定了吗?
Flink 的 Window API 中的 aggregate 就提供了这样的操作。直接基于 WindowedStream 调用.aggregate()方法,就可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction 的实现类作为参数。AggregateFunction 在源码中的定义如下:
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable
{
ACC createAccumulator();
ACC add(IN value, ACC accumulator);
OUT getResult(ACC accumulator);
ACC merge(ACC a, ACC b);
}
AggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型 IN 就是输入流中元素的数据类型;
累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
接口中有四个方法:
⚫ createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
⚫ add():将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。
⚫ getResult():从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态,然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均值,就可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。
⚫ merge():合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
所以可以看到,AggregateFunction 的工作原理是:首先调用 createAccumulator()为任务初始化一个状态(累加器);而后每来一个数据就调用一次 add()方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用 getResult()方法得到计算结果。很明显,与 ReduceFunction 相同,AggregateFunction 也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
下面来看一个具体例子。我们知道,在电商网站中,PV(页面浏览量)和 UV(独立访客数)是非常重要的两个流量指标。一般来说,PV 统计的是所有的点击量;而对用户 id 进行去重之后,得到的就是 UV。所以有时我们会用 PV/UV 这个比值,来表示“人均重复访问量”,也就是平均每个用户会访问多少次页面,这在一定程度上代表了用户的粘度。代码实现如下:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.util.HashSet;
public class WindowAggregateFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 所有数据设置相同的 key,发送到同一个分区统计 PV 和 UV,再相除
stream.keyBy(data -> true).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(2)))
.aggregate(new AvgPv())
.print();
env.execute();
}
public static class AvgPv implements AggregateFunction<Event, Tuple2<HashSet<String>, Long>, Double> {
@Override
public Tuple2<HashSet<String>, Long> createAccumulator() {
// 创建累加器
return Tuple2.of(new HashSet<String>(), 0L);
}
@Override
public Tuple2<HashSet<String>, Long> add(Event value, Tuple2<HashSet<String>, Long> accumulator) {
// 属于本窗口的数据来一条累加一次,并返回累加器
accumulator.f0.add(value.user);
return Tuple2.of(accumulator.f0, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<HashSet<String>, Long> accumulator) {
// 窗口闭合时,增量聚合结束,将计算结果发送到下游
return (double) accumulator.f1 / accumulator.f0.size();
}
@Override
public Tuple2<HashSet<String>, Long> merge(Tuple2<HashSet<String>, Long> a, Tuple2<HashSet<String>, Long> b) {
return null;
}
}
}
输出结果形式如下:
1.0
1.6666666666666667
...
代码中我们创建了事件时间滑动窗口,统计 10 秒钟的“人均 PV”,每 2 秒统计一次。由于聚合的状态还需要做处理计算,因此窗口聚合时使用了更加灵活的 AggregateFunction。为了统计 UV,我们用一个 HashSet 保存所有出现过的用户 id,实现自动去重;而 PV 的统计则类似一个计数器,每来一个数据加一就可以了。所以这里的状态,定义为包含一个 HashSet 和一个 count 值的二元组(Tuple2<HashSet, Long>),每来一条数据,就将 user 存入 HashSet,同时 count 加 1。这里的 count 就是 PV,而 HashSet 中元素的个数(size)就是 UV;所以最终窗口的输出结果,就是它们的比值。
这里没有涉及会话窗口,所以 merge()方法可以不做任何操作。
另外,Flink 也为窗口的聚合提供了一系列预定义的简单聚合方法,可以直接基于WindowedStream 调用。主要包括.sum()/max()/maxBy()/min()/minBy(),与 KeyedStream 的简单聚合非常相似。它们的底层,其实都是通过 AggregateFunction 来实现的。通过 ReduceFunction 和 AggregateFunction 我们可以发现,增量聚合函数其实就是在用流处理的思路来处理有界数据集,核心是保持一个聚合状态,当数据到来时不停地更新状态。这就是 Flink 所谓的“有状态的流处理”,通过这种方式可以极大地提高程序运行的效率,所以在实际应用中最为常见。
2. 全窗口函数(full window functions)
窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。很明显,这就是典型的批处理思路了——先攒数据,等一批都到齐了再正式启动处理流程。
这样做毫无疑问是低效的:因为窗口全部的计算任务都积压在了要输出结果的那一瞬间,而在之前收集数据的漫长过程中却无所事事。这就好比平时不用功,到考试之前通宵抱佛脚,肯定不如把工夫花在日常积累上。
那为什么还需要有全窗口函数呢?这是因为有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意义了;另外,输出的结果有可能要包含上下文中的一些信息(比如窗口的起始时间),这是增量聚合函数做不到的。所以,我们还需要有更丰富的窗口计算方式,这就可以用全窗口函数来实现。
在 Flink 中,全窗口函数也有两种:WindowFunction 和 ProcessWindowFunction。
(1)窗口函数(WindowFunction)
WindowFunction 字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于 WindowedStream 调用.apply()方法,传入一个 WindowFunction 的实现类。
stream .keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
这个类中可以获取到包含窗口所有数据的可迭代集合(Iterable),还可以拿到窗口(Window)本身的信息。WindowFunction 接口在源码中实现如下:
public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function, Serializable {
void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) throws Exception;
}
当窗口到达结束时间需要触发计算时,就会调用这里的 apply 方法。我们可以从 input 集合中取出窗口收集的数据,结合 key 和 window 信息,通过收集器(Collector)输出结果。这里 Collector 的用法,与 FlatMapFunction 中相同。不过我们也看到了,WindowFunction 能提供的上下文信息较少,也没有更高级的功能。事实上,它的作用可以被 ProcessWindowFunction 全覆盖,所以之后可能会逐渐弃用。一般在实际应用,直接使用 ProcessWindowFunction 就可以了。
(2)处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction 还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。事实上,ProcessWindowFunction 是 Flink 底层 API——处理函数(process function)中的一员,关于处理函数我们会在后续章节展开讲解。
当 然 , 这 些 好 处 是 以 牺 牲 性 能 和 资 源 为 代 价 的 。 作 为 一 个 全 窗 口 函 数 ,ProcessWindowFunction 同样需要将所有数据缓存下来、等到窗口触发计算时才使用。它其实就是一个增强版的 WindowFunction。
具体使用跟 WindowFunction 非常类似,我们可以基于 WindowedStream 调用.process()方法,传入一个 ProcessWindowFunction 的实现类。下面是一个电商网站统计每小时 UV 的例子:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
importorg.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.util.HashSet;
public class UvCountByWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 将数据全部发往同一分区,按窗口统计 UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
// 自定义窗口处理函数
public static class UvCountByWindow extends ProcessWindowFunction<Event, String, Boolean, TimeWindow>{
@Override
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
HashSet<String> userSet = new HashSet<>();
// 遍历所有数据,放到 Set 里去重
for (Event event: elements){
userSet.add(event.user);
}
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(" 窗 口 : " + new Timestamp(start) + " ~ " + new Timestamp(end) + " 的独立访客数量是:" + userSet.size());
}
}
}
输出结果形式如下:
窗口:...~...的独立访客数量是:2
窗口:...~...的独立访客数量是:3
...
这里我们使用的是事件时间语义。定义 10 秒钟的滚动事件窗口后,直接使用ProcessWindowFunction 来定义处理的逻辑。我们可以创建一个 HashSet,将窗口所有数据的userId 写入实现去重,最终得到 HashSet 的元素个数就是 UV 值。
当 然 , 这 里 我 们 并 没 有 用 到 上 下 文 中 其 他 信 息 , 所 以 其 实 没 有 必 要 使 用ProcessWindowFunction。全窗口函数因为运行效率较低,很少直接单独使用,往往会和增量聚合函数结合在一起,共同实现窗口的处理计算。
3. 增量聚合和全窗口函数的结合使用
我们已经了解了 Window API 中两类窗口函数的用法,下面我们先来做个简单的总结。增量聚合函数处理计算会更高效。举一个最简单的例子,对一组数据求和。大量的数据连续不断到来,全窗口函数只是把它们收集缓存起来,并没有处理;到了窗口要关闭、输出结果的时候,再遍历所有数据依次叠加,得到最终结果。而如果我们采用增量聚合的方式,那么只需要保存一个当前和的状态,每个数据到来时就会做一次加法,更新状态;到了要输出结果的时候,只要将当前状态直接拿出来就可以了。增量聚合相当于把计算量“均摊”到了窗口收集数据的过程中,自然就会比全窗口聚合更加高效、输出更加实时。
而全窗口函数的优势在于提供了更多的信息,可以认为是更加“通用”的窗口操作。它只负责收集数据、提供上下文相关信息,把所有的原材料都准备好,至于拿来做什么我们完全可以任意发挥。这就使得窗口计算更加灵活,功能更加强大。
所以在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink 的Window API 就给我们实现了这样的用法。
我们之前在调用 WindowedStream 的.reduce()和.aggregate()方法时,只是简单地直接传入了一个 ReduceFunction 或 AggregateFunction 进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是 WindowFunction 或者 ProcessWindowFunction。
// ReduceFunction 与 WindowFunction 结合
public <R> SingleOutputStreamOperator<R> reduce( ReduceFunction<T> reduceFunction, WindowFunction<T, R, K, W> function)
// ReduceFunction 与 ProcessWindowFunction 结合
public <R> SingleOutputStreamOperator<R> reduce( ReduceFunction<T> reduceFunction, ProcessWindowFunction<T, R, K, W> function)
// AggregateFunction 与 WindowFunction 结合
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate( AggregateFunction<T, ACC, V> aggFunction, WindowFunction<V, R, K, W> windowFunction)
// AggregateFunction 与 ProcessWindowFunction 结合
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate( AggregateFunction<T, ACC, V> aggFunction, ProcessWindowFunction<V, R, K, W> windowFunction)
这样调用的处理机制是:基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了 Iterable 类型的输入。一般情况下,这时的可迭代集合中就只有一个元素了。下面我们举一个具体的实例来说明。在网站的各种统计指标中,一个很重要的统计指标就是热门的链接;想要得到热门的 url,前提是得到每个链接的“热门度”。一般情况下,可以用url 的浏览量(点击量)表示热门度。我们这里统计 10 秒钟的 url 浏览量,每 5 秒钟更新一次;
另外为了更加清晰地展示,还应该把窗口的起始结束时间一起输出。我们可以定义滑动窗口,并结合增量聚合函数和全窗口函数来得到统计结果。
具体实现代码如下:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class UrlViewCountExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 需要按照 url 分组,开滑动窗口统计
stream.keyBy(data -> data.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
// 同时传入增量聚合函数和全窗口函数
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
.print();
env.execute();
}
// 自定义增量聚合函数,来一条数据就加一
public static class UrlViewCountAgg implements AggregateFunction<Event, Long, Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
// 自定义窗口处理函数,只需要包装窗口信息
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throwsException{
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
// 迭代器中只有一个元素,就是增量聚合函数的计算结果
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}
}
这里我们为了方便处理,单独定义了一个 POJO 类 UrlViewCount 来表示聚合输出结果的数据类型,包含了 url、浏览量以及窗口的起始结束时间。
import java.sql.Timestamp;
public class UrlViewCount {
public String url;
public Long count;
public Long windowStart;
public Long windowEnd;
public UrlViewCount() {
}
public UrlViewCount(String url, Long count, Long windowStart, Long windowEnd)
{
this.url = url;
this.count = count;
this.windowStart = windowStart;
this.windowEnd = windowEnd;
}
@Override
public String toString() {
return "UrlViewCount{" +
"url='" + url + '\'' +
", count=" + count +
", windowStart=" + new Timestamp(windowStart) +
", windowEnd=" + new Timestamp(windowEnd) +
'}';
}
}
代码中用一个 AggregateFunction 来实现增量聚合,每来一个数据就计数加一;得到的结果交给 ProcessWindowFunction,结合窗口信息包装成我们想要的 UrlViewCount,最终输出统计结果。
注:ProcessWindowFunction 是处理函数中的一种,后面我们会详细讲解。这里只用它来将增量聚合函数的输出结果包裹一层窗口信息。
窗口处理的主体还是增量聚合,而引入全窗口函数又可以获取到更多的信息包装输出,这样的结合兼具了两种窗口函数的优势,在保证处理性能和实时性的同时支持了更加丰富的应用场景。
6.3.6 测试水位线和窗口的使用
之前讲过,当水位线到达窗口结束时间时,窗口就会闭合不再接收迟到的数据,因为根据水位线的定义,所有小于等于水位线的数据都已经到达,所以显然 Flink 会认为窗口中的数据都到达了(尽管可能存在迟到数据,也就是时间戳小于当前水位线的数据)。我们可以在之前生成水位线代码 WatermarkTest 的基础上,增加窗口应用做一下测试:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class WatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 将数据源改为 socket 文本流,并转换成 Event 类型
env.socketTextStream("localhost", 7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception { String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim()));
}
})
// 插入水位线的逻辑
.assignTimestampsAndWatermarks(
// 针对乱序流插入水位线,延迟时间设置为 5s
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
// 抽取时间戳的逻辑
@Override
public long extractTimestamp(Event element, long
recordTimestamp) {
return element.timestamp;
}
})
)
// 根据 user 分组,开窗统计
.keyBy(data -> data.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new WatermarkTestResult())
.print();
env.execute();
}
// 自定义处理窗口函数,输出当前的水位线和窗口信息
public static class WatermarkTestResult extends ProcessWindowFunction<Event, String, String, TimeWindow>{
@Override
public void process(String s, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long currentWatermark = context.currentWatermark();
Long count = elements.spliterator().getExactSizeIfKnown();
out.collect("窗口" + start + " ~ " + end + "中共有" + count + "个元素,窗口闭合计算时,水位线处于:" + currentWatermark);
}
}
}
我们这里设置的最大延迟时间是 5 秒,所以当我们在终端启动 nc 程序,也就是 nc –lk 7777然后输入如下数据时:
Alice, ./home, 1000
Alice, ./cart, 2000
Alice, ./prod?id=100, 10000
Alice, ./prod?id=200, 8000
Alice, ./prod?id=300, 15000
我们会看到如下结果:
窗口 0 ~ 10000 中共有 3 个元素,窗口闭合计算时,水位线处于:9999
我们就会发现,当最后输入[Alice, ./prod?id=300, 15000]时,流中会周期性地(默认 200毫秒)插入一个时间戳为 15000L – 5 * 1000L – 1L = 9999 毫秒的水位线,已经到达了窗口[0,10000)的结束时间,所以会触发窗口的闭合计算。而后面再输入一条[Alice, ./prod?id=200, 9000]时,将不会有任何结果;因为这是一条迟到数据,它所属于的窗口已经触发计算然后销毁了(窗口默认被销毁),所以无法再进入到窗口中,自然也就无法更新计算结果了。窗口中的迟到数据默认会被丢弃,这会导致计算结果不够准确。Flink 提供了有效处理迟到数据的手段,我们会在稍后的 6.4 节详细介绍。
6.3.7 其他 API
对于一个窗口算子而言,窗口分配器和窗口函数是必不可少的。除此之外,Flink 还提供了其他一些可选的 API,让我们可以更加灵活地控制窗口行为。
1. 触发器(Trigger)
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗口函数,所以可以认为是计算得到结果并输出的过程。
基于 WindowedStream 调用.trigger()方法,就可以传入一个自定义的窗口触发器(Trigger)。
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())
Trigger 是窗口算子的内部属性,每个窗口分配器(WindowAssigner)都会对应一个默认的触发器;对于 Flink 内置的窗口类型,它们的触发器都已经做了实现。例如,所有事件时间窗口,默认的触发器都是 EventTimeTrigger;类似还有 ProcessingTimeTrigger 和 CountTrigger。所以一般情况下是不需要自定义触发器的,不过我们依然有必要了解它的原理。
Trigger 是一个抽象类,自定义时必须实现下面四个抽象方法:
⚫ onElement():窗口中每到来一个元素,都会调用这个方法。
⚫ onEventTime():当注册的事件时间定时器触发时,将调用这个方法。
⚫ onProcessingTime ():当注册的处理时间定时器触发时,将调用这个方法。
⚫ clear():当窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态。
可以看到,除了 clear()比较像生命周期方法,其他三个方法其实都是对某种事件的响应。onElement()是对流中数据元素到来的响应;而另两个则是对时间的响应。这几个方法的参数中都有一个“触发器上下文”(TriggerContext)对象,可以用来注册定时器回调(callback)。这里提到的“定时器”(Timer),其实就是我们设定的一个“闹钟”,代表未来某个时间点会执行的事件;当时间进展到设定的值时,就会执行定义好的操作。很明显,对于时间窗口(TimeWindow)而言,就应该是在窗口的结束时间设定了一个定时器,这样到时间就可以触发窗口的计算输出了。关于定时器的内容,我们在后面讲解处理函数(process function)时还会提到。
上面的前三个方法可以响应事件,那它们又是怎样跟窗口操作联系起来的呢?这就需要了解一下它们的返回值。这三个方法返回类型都是 TriggerResult,这是一个枚举类型(enum),
其中定义了对窗口进行操作的四种类型。
⚫ CONTINUE(继续):什么都不做
⚫ FIRE(触发):触发计算,输出结果
⚫ PURGE(清除):清空窗口中的所有数据,销毁窗口
⚫ FIRE_AND_PURGE(触发并清除):触发计算输出结果,并清除窗口
我们可以看到,Trigger 除了可以控制触发计算,还可以定义窗口什么时候关闭(销毁)。上面的四种类型,其实也就是这两个操作交叉配对产生的结果。一般我们会认为,到了窗口的结束时间,那么就会触发计算输出结果,然后关闭窗口——似乎这两个操作应该是同时发生的;但 TriggerResult 的定义告诉我们,两者可以分开。稍后我们就会看到它们分开操作的场景。
下面我们举一个例子。在日常业务场景中,我们经常会开比较大的窗口来计算每个窗口的pv 或者 uv 等数据。但窗口开的太大,会使我们看到计算结果的时间间隔变长。所以我们可以使用触发器,来隔一段时间触发一次窗口计算。我们在代码中计算了每个 url 在 10 秒滚动窗口的 pv 指标,然后设置了触发器,每隔 1 秒钟触发一次窗口的计算。
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import
org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import
org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.Trigger;
170
import org.apache.flink.streaming.api.windowing.triggers.TriggerResult;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class TriggerExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env .addSource(new ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps() .withTimestampAssigner(new
SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
)
.keyBy(r -> r.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.trigger(new MyTrigger())
.process(new WindowResult())
.print();
env.execute();
}
public static class WindowResult extends ProcessWindowFunction<Event, UrlViewCount, String, TimeWindow> {
@Override
public void process(String s, Context context, Iterable<Event> iterable, Collector<UrlViewCount> collector) throws Exception {
collector.collect( new UrlViewCount( s,
// 获取迭代器中的元素个数
iterable.spliterator().getExactSizeIfKnown(),
context.window().getStart(),
context.window().getEnd()
)
);
}
}
public static class MyTrigger extends Trigger<Event, TimeWindow> {
@Override
public TriggerResult onElement(Event event, long l, TimeWindow timeWindow, TriggerContext triggerContext) throws Exception {
ValueState<Boolean> isFirstEvent = triggerContext.getPartitionedState(
new ValueStateDescriptor<Boolean>("first-event", Types.BOOLEAN)
);
if (isFirstEvent.value() == null) {
for (long i = timeWindow.getStart(); i < timeWindow.getEnd(); i = i + 1000L) {
triggerContext.registerEventTimeTimer(i);
}
isFirstEvent.update(true);
}
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onEventTime(long l, TimeWindow timeWindow, TriggerContext triggerContext) throws Exception {
return TriggerResult.FIRE;
}
@Override
public TriggerResult onProcessingTime(long l, TimeWindow timeWindow, TriggerContext triggerContext) throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public void clear(TimeWindow timeWindow, TriggerContext triggerContext) throws Exception {
ValueState<Boolean> isFirstEvent = triggerContext.getPartitionedState(
new ValueStateDescriptor<Boolean>("first-event", Types.BOOLEAN)
);
isFirstEvent.clear();
}
}
}
输出结果如下:
UrlViewCount{url='./prod?id=1', count=1, windowStart=2021-07-01 14:44:10.0,
windowEnd=2021-07-01 14:44:20.0}
UrlViewCount{url='./prod?id=1', count=1, windowStart=2021-07-01 14:44:10.0,
windowEnd=2021-07-01 14:44:20.0}
UrlViewCount{url='./prod?id=1', count=1, windowStart=2021-07-01 14:44:10.0,
windowEnd=2021-07-01 14:44:20.0}
UrlViewCount{url='./prod?id=1', count=1, windowStart=2021-07-01 14:44:10.0,
windowEnd=2021-07-01 14:44:20.0}
2. 移除器(Evictor)
移除器主要用来定义移除某些数据的逻辑。基于 WindowedStream 调用.evictor()方法,就可以传入一个自定义的移除器(Evictor)。Evictor 是一个接口,不同的窗口类型都有各自预实现的移除器。
stream.keyBy(…)
.window(…)
.evictor(new MyEvictor())
Evictor 接口定义了两个方法:
⚫ evictBefore():定义执行窗口函数之前的移除数据操作
⚫ evictAfter():定义执行窗口函数之后的以处数据操作
默认情况下,预实现的移除器都是在执行窗口函数(window fucntions)之前移除数据的。
3. 允许延迟(Allowed Lateness)
在事件时间语义下,窗口中可能会出现数据迟到的情况。这是因为在乱序流中,水位线(watermark)并不一定能保证时间戳更早的所有数据不会再来。当水位线已经到达窗口结束时间时,窗口会触发计算并输出结果,这时一般也就要销毁窗口了;如果窗口关闭之后,又有本属于窗口内的数据姗姗来迟,默认情况下就会被丢弃。这也很好理解:窗口触发计算就像发车,如果要赶的车已经开走了,又不能坐其他的车(保证分配窗口的正确性),那就只好放弃坐班车了。
不过在多数情况下,直接丢弃数据也会导致统计结果不准确,我们还是希望该上车的人都能上来。为了解决迟到数据的问题,Flink 提供了一个特殊的接口,可以为窗口算子设置一个“允许的最大延迟”(Allowed Lateness)。也就是说,我们可以设定允许延迟一段时间,在这段时间内,窗口不会销毁,继续到来的数据依然可以进入窗口中并触发计算。直到水位线推进到了 窗口结束时间 + 延迟时间,才真正将窗口的内容清空,正式关闭窗口。
基于 WindowedStream 调用.allowedLateness()方法,传入一个 Time 类型的延迟时间,就可以表示允许这段时间内的延迟数据。
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.allowedLateness(Time.minutes(1))
比如上面的代码中,我们定义了 1 小时的滚动窗口,并设置了允许 1 分钟的延迟数据。也就是说,在不考虑水位线延迟的情况下,对于 8 点~9 点的窗口,本来应该是水位线到达 9 点整就触发计算并关闭窗口;现在允许延迟 1 分钟,那么 9 点整就只是触发一次计算并输出结果,并不会关窗。后续到达的数据,只要属于 8 点-9 点窗口,依然可以在之前统计的基础上继续叠加,并且再次输出一个更新后的结果。直到水位线到达了 9 点零 1 分,这时就真正清空状态、关闭窗口,之后再来的迟到数据就会被丢弃了。
从这里我们就可以看到,窗口的触发计算(Fire)和清除(Purge)操作确实可以分开。不过在默认情况下,允许的延迟是 0,这样一旦水位线到达了窗口结束时间就会触发计算并清除窗口,两个操作看起来就是同时发生了。当窗口被清除(关闭)之后,再来的数据就会被丢弃。
4. 将迟到的数据放入侧输出流
我们自然会想到,即使可以设置窗口的延迟时间,终归还是有限的,后续的数据还是会被丢弃。如果不想丢弃任何一个数据,又该怎么做呢?Flink 还提供了另外一种方式处理迟到数据。我们可以将未收入窗口的迟到数据,放入“侧输出流”(side output)进行另外的处理。所谓的侧输出流,相当于是数据流的一个“分支”,这个流中单独放置那些错过了该上的车、本该被丢弃的数据。
基于 WindowedStream 调用.sideOutputLateData() 方法,就可以实现这个功能。方法需要传入一个“输出标签”(OutputTag),用来标记分支的迟到数据流。因为保存的就是流中的原始数据,所以 OutputTag 的类型与流中数据类型相同。
DataStream<Event> stream = env.addSource(...);
OutputTag<Event> outputTag = new OutputTag<Event>("late") {};
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
将迟到数据放入侧输出流之后,还应该可以将它提取出来。基于窗口处理完成之后的DataStream,调用.getSideOutput()方法,传入对应的输出标签,就可以获取到迟到数据所在的流了。
SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
.aggregate(new MyAggregateFunction())
DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);
这里注意,getSideOutput()是 SingleOutputStreamOperator 的方法,获取到的侧输出流数据类型应该和 OutputTag 指定的类型一致,与窗口聚合之后流中的数据类型可以不同。
6.3.8 窗口的生命周期
熟悉了窗口 API 的使用,我们再回头梳理一下窗口本身的生命周期,这也是对窗口所有操作的一个总结。
1. 窗口的创建
窗口的类型和基本信息由窗口分配器(window assigners)指定,但窗口不会预先创建好,而是由数据驱动创建。当第一个应该属于这个窗口的数据元素到达时,就会创建对应的窗口。
2. 窗口计算的触发
除了窗口分配器,每个窗口还会有自己的窗口函数(window functions)和触发器(trigger)。窗口函数可以分为增量聚合函数和全窗口函数,主要定义了窗口中计算的逻辑;而触发器则是指定调用窗口函数的条件。
对于不同的窗口类型,触发计算的条件也会不同。例如,一个滚动事件时间窗口,应该在水位线到达窗口结束时间的时候触发计算,属于“定点发车”;而一个计数窗口,会在窗口中元素数量达到定义大小时触发计算,属于“人满就发车”。所以 Flink 预定义的窗口类型都有对应内置的触发器。
对于事件时间窗口而言,除去到达结束时间的“定点发车”,还有另一种情形。当我们设置了允许延迟,那么如果水位线超过了窗口结束时间、但还没有到达设定的最大延迟时间,这期间内到达的迟到数据也会触发窗口计算。这类似于没有准时赶上班车的人又追上了车,这时车要再次停靠、开门,将新的数据整合统计进来。
3. 窗口的销毁
一般情况下,当时间达到了结束点,就会直接触发计算输出结果、进而清除状态销毁窗口。
这时窗口的销毁可以认为和触发计算是同一时刻。这里需要注意,Flink 中只对时间窗口(TimeWindow)有销毁机制;由于计数窗口(CountWindow)是基于全局窗口(GlobalWindw)实现的,而全局窗口不会清除状态,所以就不会被销毁。在特殊的场景下,窗口的销毁和触发计算会有所不同。事件时间语义下,如果设置了允许延迟,那么在水位线到达窗口结束时间时,仍然不会销毁窗口;窗口真正被完全删除的时间点,是窗口的结束时间加上用户指定的允许延迟时间。
4. 窗口 API 调用总结
到目前为止,我们已经彻底明白了 Flink 中窗口的概念和 Window API 的调用,我们再用一张图做一个完整总结,如图 6-22 所示。

Window API 首先按照时候按键分区分成两类。keyBy 之后的 KeyedStream,可以用.window()方法声明按键分区窗口(Keyed Windows);而如果不做 keyBy,DataStream 也可以直接调用.windowAll()声明非按键分区窗口。之后的方法调用就完全一样了。
接下来首先是通过.window()/.windowAll()方法定义窗口分配器,得到 WindowedStream;然 后 通 过 各 种 转 换 方 法 ( reduce/aggregate/apply/process ) 给 出 窗 口 函 数(ReduceFunction/AggregateFunction/ProcessWindowFunction),定义窗口的具体计算处理逻辑,转换之后重新得到 DataStream。这两者必不可少,是窗口算子(WindowOperator)最重要的组成部分。
此外,在这两者之间,还可以基于 WindowedStream 调用.trigger()自定义触发器、调用.evictor()定义移除器、调用.allowedLateness()指允许延迟时间、调用.sideOutputLateData()将迟到数据写入侧输出流,这些都是可选的 API,一般不需要实现。而如果定义了侧输出流,可以基于窗口聚合之后的 DataStream 调用.getSideOutput()获取侧输出流。
6.4 迟到数据的处理
有了事件时间、水位线和窗口的相关知识,现在就可以系统性地讨论一下怎样处理迟到数据了。我们知道,所谓的“迟到数据”(late data),是指某个水位线之后到来的数据,它的时间戳其实是在水位线之前的。所以只有在事件时间语义下,讨论迟到数据的处理才是有意义的。事件时间里用来表示时钟进展的就是水位线(watermark)。对于乱序流,水位线本身就可以设置一个延迟时间;而做窗口计算时,我们又可以设置窗口的允许延迟时间;另外窗口还有将迟到数据输出到测输出流的用法。所有的这些方法,它们之间有什么关系,我们又该怎样合理利用呢?这一节我们就来讨论这个问题。
6.4.1 设置水位线延迟时间
水位线是事件时间的进展,它是我们整个应用的全局逻辑时钟。水位线生成之后,会随着数据在任务间流动,从而给每个任务指明当前的事件时间。所以从这个意义上讲,水位线是一个覆盖万物的存在,它并不只针对事件时间窗口有效。
之前我们讲到触发器时曾提到过“定时器”,时间窗口的操作底层就是靠定时器来控制触发的。既然是底层机制,定时器自然就不可能是窗口的专利了;事实上它是 Flink 底层 API——处理函数(process function)的重要部分。
所以水位线其实是所有事件时间定时器触发的判断标准。那么水位线的延迟,当然也就是全局时钟的滞后,相当于是上帝拨动了琴弦,所有人的表都变慢了。
既然水位线这么重要,那一般情况就不应该把它的延迟设置得太大,否则流处理的实时性就会大大降低。因为水位线的延迟主要是用来对付分布式网络传输导致的数据乱序,而网络传输的乱序程度一般并不会很大,大多集中在几毫秒至几百毫秒。所以实际应用中,我们往往会给水位线设置一个“能够处理大多数乱序数据的小延迟”,视需求一般设在毫秒~秒级。
当我们设置了水位线延迟时间后,所有定时器就都会按照延迟后的水位线来触发。如果一个数据所包含的时间戳,小于当前的水位线,那么它就是所谓的“迟到数据”。
6.4.2 允许窗口处理迟到数据
水位线延迟设置的比较小,那之后如果仍有数据迟到该怎么办?对于窗口计算而言,如果水位线已经到了窗口结束时间,默认窗口就会关闭,那么之后再来的数据就要被丢弃了。自然想到,Flink 的窗口也是可以设置延迟时间,允许继续处理迟到数据的。这种情况下,由于大部分乱序数据已经被水位线的延迟等到了,所以往往迟到的数据不会太多。这样,我们会在水位线到达窗口结束时间时,先快速地输出一个近似正确的计算结果;然后保持窗口继续等到延迟数据,每来一条数据,窗口就会再次计算,并将更新后的结果输出。这样就可以逐步修正计算结果,最终得到准确的统计值了。
类比班车的例子,我们可以这样理解:大多数人是在发车时刻前后到达的,所以我们只要把表调慢,稍微等一会儿,绝大部分人就都上车了,这个把表调慢的时间就是水位线的延迟;到点之后,班车就准时出发了,不过可能还有该来的人没赶上。于是我们就先慢慢往前开,这段时间内,如果迟到的人抓点紧还是可以追上的;如果有人追上来了,就停车开门让他上来,然后车继续向前开。当然我们的车不能一直慢慢开,需要有一个时间限制,这就是窗口的允许延迟时间。一旦超过了这个时间,班车就不再停留,开上高速疾驰而去了。
所以我们将水位线的延迟和窗口的允许延迟数据结合起来,最后的效果就是先快速实时地输出一个近似的结果,而后再不断调整,最终得到正确的计算结果。回想流处理的发展过程,这不就是著名的 Lambda 架构吗?原先需要两套独立的系统来同时保证实时性和结果的最终正确性,如今 Flink 一套系统就全部搞定了。
6.4.3 将迟到数据放入窗口侧输出流
即使我们有了前面的双重保证,可窗口不能一直等下去,最后总要真正关闭。窗口一旦关闭,后续的数据就都要被丢弃了。那如果真的还有漏网之鱼又该怎么办呢?那就要用到最后一招了:用窗口的侧输出流来收集关窗以后的迟到数据。这种方式是最后“兜底”的方法,只能保证数据不丢失;因为窗口已经真正关闭,所以是无法基于之前窗口的结果直接做更新的。我们只能将之前的窗口计算结果保存下来,然后获取侧输出流中的迟到数据,判断数据所属的窗口,手动对结果进行合并更新。尽管有些烦琐,实时性也不够强,但能够保证最终结果一定是正确的。
如果还用赶班车来类比,那就是车已经上高速开走了,这班车是肯定赶不上了。不过我们还留下了行进路线和联系方式,迟到的人如果想办法辗转到了目的地,还是可以和大部队会合的。最终,所有该到的人都会在目的地出现。所以总结起来,Flink 处理迟到数据,对于结果的正确性有三重保障:水位线的延迟,窗口允许迟到数据,以及将迟到数据放入窗口侧输出流。我们可以回忆一下之前 6.3.5 小节统计每个 url 浏览次数的代码 UrlViewCountExample,稍作改进,增加处理迟到数据的功能。具体代码如下。
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
public class ProcessLateDataExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取 socket 文本流
SingleOutputStreamOperator<Event> stream = env.socketTextStream("localhost", 7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception {
String[] fields = value.split(" ");
return new Event(fields[0].trim(), fields[1].trim(),Long.valueOf(fields[2].trim()));
}
})
// 方式一:设置 watermark 延迟时间,2 秒钟
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 定义侧输出流标签
OutputTag<Event> outputTag = new OutputTag<Event>("late"){};
SingleOutputStreamOperator<UrlViewCount> result = stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 方式二:允许窗口处理迟到数据,设置 1 分钟的等待时间
.allowedLateness(Time.minutes(1))
// 方式三:将最后的迟到数据输出到侧输出流
.sideOutputLateData(outputTag)
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult());
result.print("result");
result.getSideOutput(outputTag).print("late");
// 为方便观察,可以将原始数据也输出
stream.print("input");
env.execute();
}
public static class UrlViewCountAgg implements AggregateFunction<Event, Long,
Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}
}
我们还是先启动 nc –lk 7777,然后依次输入以下数据:
Alice, ./home, 1000
Alice, ./home, 2000
Alice, ./home, 10000
Alice, ./home, 9000
Alice, ./cart, 12000
Alice, ./prod?id=100, 15000
Alice, ./home, 9000
Alice, ./home, 8000
Alice, ./prod?id=200, 70000
Alice, ./home, 8000
Alice, ./prod?id=300, 72000
Alice, ./home, 8000
下面我们来分析一下程序的运行过程。当输入数据[Alice, ./home, 10000]时,时间戳为10000,由于设置了 2 秒钟的水位线延迟时间,所以此时水位线到达了 8 秒(事实上是 7999毫秒,这里不再追究减 1 的细节),并没有触发 [0, 10s) 窗口的计算;所以接下来时间戳为 9000的数据到来,同样可以直接进入窗口做增量聚合。当时间戳为 12000 的数据到来时(无所谓url 是什么,所有数据都可以推动水位线前进),水位线到达了 12000 – 2 * 1000 = 10000,所以触发了[0, 10s) 窗口的计算,第一次输出了窗口统计结果,如下所示:
result> UrlViewCount{url='./home,', count=3, windowStart=1970-01-01 08:00:00.0, windowEnd=1970-01-01 08:00:10.0}
这里 count 值为 3,就包括了之前输入的时间戳为 1000、2000、9000 的三条数据。不过窗口触发计算之后并没有关闭销毁,而是继续等待迟到数据。之后时间戳为 15000的数据继续推进水位线,此时时钟已经进展到了 13000ms;此时再来一条时间戳为 9000 的数据,我们会发现立即输出了一条统计结果:
result> UrlViewCount{url='./home,', count=4, windowStart=1970-01-01 08:00:00.0, windowEnd=1970-01-01 08:00:10.0}
很明显,这仍然是[0, 10s) 的窗口,在之前计数值 3 的基础上继续叠加,更新统计结果为4。所以允许窗口处理迟到数据之后,相当于窗口有了一段等待时间,在这期间所有的迟到数据都会立即触发窗口计算,更新之前的结果。因此,之后时间戳为 8000 的数据到来,同样会立即输出:
result> UrlViewCount{url='./home,', count=5, windowStart=1970-01-01 08:00:00.0, windowEnd=1970-01-01 08:00:10.0}
我们设置窗口等待的时间为 1 分钟,所以当时间推进到 10000 + 60 * 1000 = 70000 时,窗口就会真正被销毁。此前的所有迟到数据可以直接更新窗口的计算结果,而之后的迟到数据已经无法整合进窗口,就只能用侧输出流来捕获了。需要注意的是,这里的“时间”依然是由水位线来指示的,所以时间戳为 70000 的数据到来,并不会触发窗口的销毁;当时间戳为 72000的数据到来,水位线推进到了 72000 – 2 * 1000 = 70000,此时窗口真正销毁关闭,之后再来的迟到数据就会输出到侧输出流了:
late> Event{user='Alice,', url='./home,', timestamp=1970-01-01 08:00:08.0}
6.5 本章总结
在流处理中,由于对实时性的要求非常高,同时又要求能够保证窗口操作结果的正确,所以必须引入水位线来描述事件时间。而窗口正是时间相关的最佳应用场景,所以 Flink 为我们提供了丰富的窗口类型和处理操作;与此同时,在实际应用中很难对乱序流给出一个最佳延迟时间,单独依赖水位线去保证结果正确性是不够的,所以需要结合窗口(Window)处理迟到数据的相关 API。本章我们详细了解了 Flink 中时间语义和水位线的概念、窗口 API 的用法以及处理迟到数据的相关知识,这些内容对于实时流处理来说非常重要。
Flink 的时间语义和窗口,主要就是为了处理大规模的乱序数据流时,同时保证低延迟、高吞吐和结果的正确性。这部分设计基本上是对谷歌(Google)著名论文《数据流模型:一种在大规模、无界、无序数据处理中平衡正确性、延迟和性能的实用方法》(The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing)的具体实现,如果读者有兴趣可以读一下原始论文,会对流处理有更加深刻的理解。