没有一种机器学习算法可以解决所有类型的机器学习问题。机器学习任务可能千差万别,算法的选择将取决于数据的大小、维数和稀疏性等因素。目标变量、数据的质量以及特征内部以及特征与目标变量之间存在的相互作用和统计关系。
在本文中,我将提供机器学习的五种最常用算法的快速参考指南。这将介绍算法的内部工作原理以及使每个算法更适合特定任务的注意事项。
这将包括对线性回归、逻辑回归、随机森林、XGBoost 和 K-means 的简要介绍。对于每种算法,我将介绍以下内容:
- 基本原理。
- 示例代码。
- 应该什么时候使用。
- 优点和缺点。
文章目录
- 一、线性回归
- 1.1 基本原理
- 1.2 示例代码
- 1.3 应该什么时候使用
- 1.4 优缺点
- 二、逻辑回归
- 2.1 基本原理
- 2.2 示例代码
- 2.3应该什么时候使用
- 2.4优缺点
- 三、随机森林
- 3.1 基本原理
- 3.2 示例代码
- 3.3 应该什么时候使用
- 3.4 优缺点
- 四、XGBoost
- 4.1 基本原理
- 4.2 示例代码
- 4.3 应该什么时候使用
- 4.4 优缺点
- 五、K 均值
- 5.1 基本原理
- 5.2 示例代码
- 5.3 应该什么时候使用
- 5.4 优缺点
- 六、总结对比
一、线性回归
1.1 基本原理
线性回归是一种有监督的机器学习算法,用于预测连续的目标变量。对于简单的线性回归,其中有一个自变量(特征)和一个因变量(目标),算法可以用以下等式表示。
y=a+bx
其中y是因变量,X是特征变量,b是直线的斜率,a是截距。
简单线性回归可以可视化为散点图,其中 x 轴包含因变量,y 轴包含自变量。线性回归算法通过数据点绘制一条最佳拟合线,最大限度地减少预测输出和实际输出之间的变化。
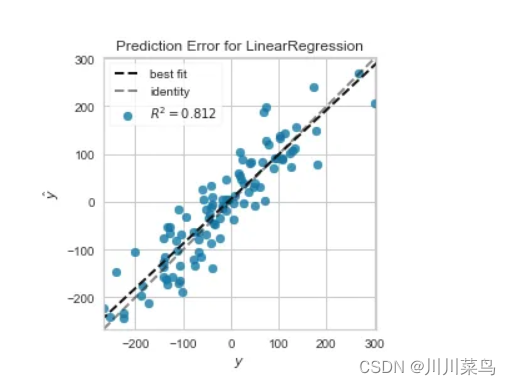
1.2 示例代码
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from yellowbrick.regressor import PredictionError
X, y = make_regression(
n_samples=500, n_features=5, noise=50, coef=False
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
visualizer = PredictionError(model)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
1.3 应该什么时候使用
- 线性回归只能用于解决基于回归的问题。
- 因变量和自变量之间必须存在线性关系。
- 残差必须服从正态分布。
- 特征之间必须没有相关性。
- 该算法假设训练数据是随机采样的。
- 最适合基于回归的问题,其中数据中的关系既是线性的又是简单的。
1.4 优缺点
优点:
- 高度可解释和快速训练。
- 在线性可分数据上表现非常好。
缺点:
- 对异常值不稳健。
- 非常简单,因此它不能很好地模拟现实世界数据中的复杂性。
- 该算法也容易过拟合。
二、逻辑回归
2.1 基本原理
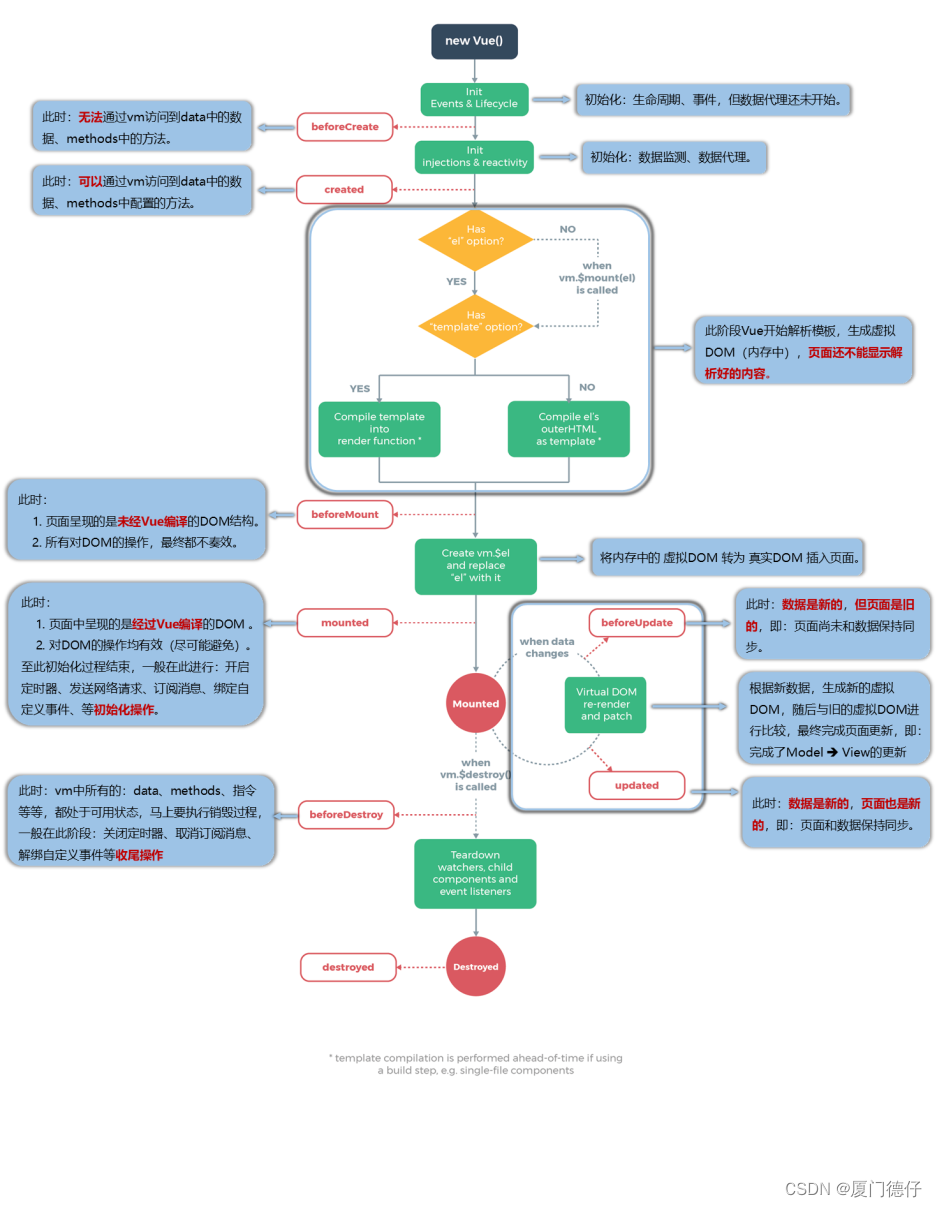
逻辑回归本质上是线性回归模型,以适应分类问题。逻辑回归不是拟合直线,而是应用逻辑函数将线性方程的输出压缩在 0 和 1 之间。结果是 S 形曲线而不是穿过数据点的直线,如下图所示。
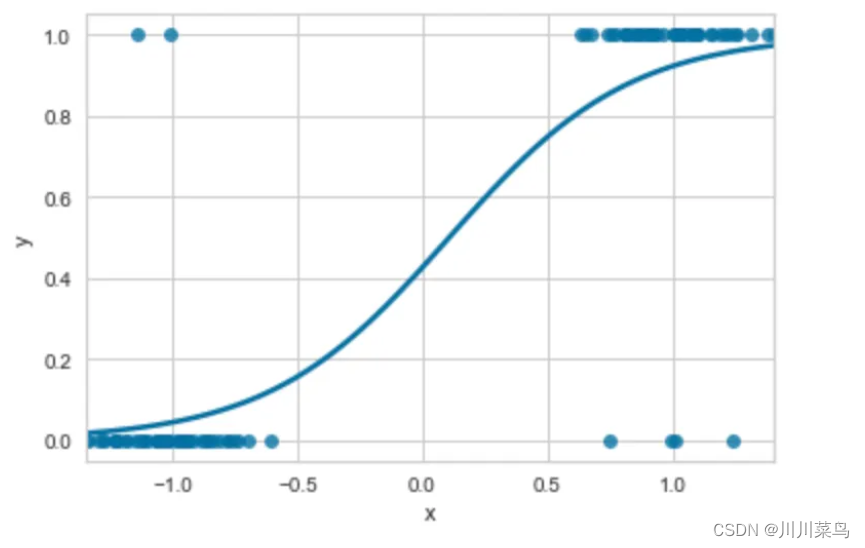
选择 0 和 1 之间的阈值来分隔类,通常为 0.5。本质上,我们在 0.5 处绘制一条穿过 S 曲线的水平线。这条线上方的任何数据点都属于 1 类,低于该线的任何数据点都属于 0 类。
2.2 示例代码
import seaborn as sns
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
X, y = make_classification(n_features=1,
n_informative=1,
n_redundant=0,
n_classes=2,
n_clusters_per_class=1,
flip_y=0.2,
random_state=0)
df = pd.DataFrame(X, columns=['x'])
df['y'] = y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lr = LogisticRegression(C=1e5)
model = lr.fit(X_train, y_train)
y_pred = model.predict(X_test)
sns.regplot(x='x', y='y', data=df, logistic=True, ci=None)
2.3应该什么时候使用
- 该算法只能用于解决分类问题。
- 特征和目标变量之间必须存在线性关系。
- 观测值的数量必须大于特征的数量。
- 最适合数据中的关系既是线性又简单的分类问题。
2.4优缺点
优点:
- 与线性回归一样,该算法可解释性强且训练速度快。
- 它在线性可分数据上表现非常好。
缺点:
- 容易过度拟合。
- 与线性回归一样,它不能很好地模拟复杂关系。
三、随机森林
3.1 基本原理
随机森林算法构建决策树的“森林” 。森林中的每棵树都会根据给定的一组特征生成预测。一旦生成了所有预测,就会进行多数表决,并且最常预测的类别形成最终预测。
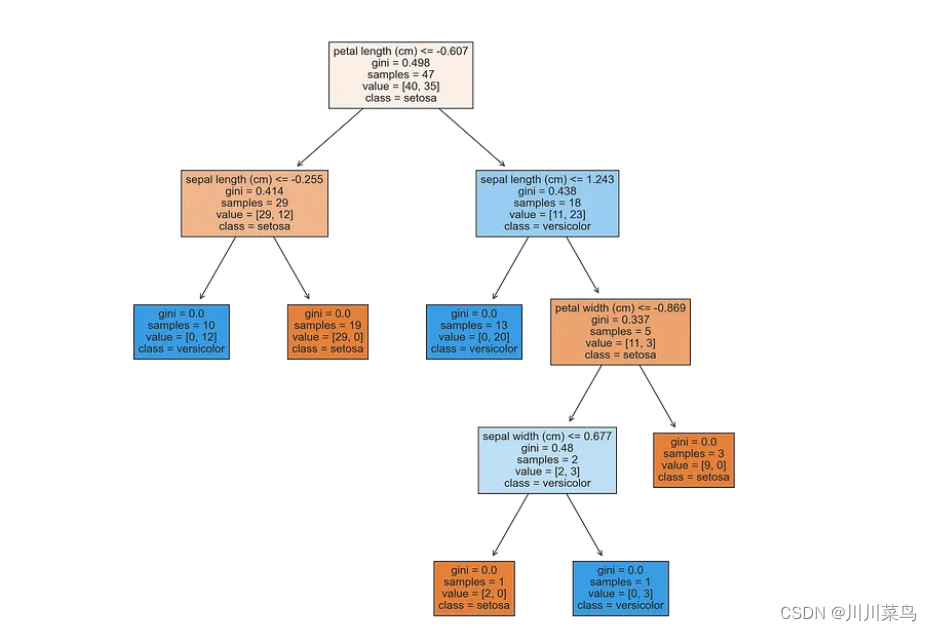
决策树是一种非常直观的算法。它具有类似流程图的结构,其中包含代表测试的一系列节点。每个测试的结果都会产生分裂,并创建一个或多个叶节点,直到实现最终预测。超参数决定树的生长深度和使用的节点分裂函数。
随机森林算法遵循以下步骤序列:
- 训练数据集根据森林中树木的数量随机分成多个样本。树的数量是通过超参数设置的。
- 使用其中一个数据子集并行训练决策树。
- 评估所有树的输出,并将最常出现的预测作为最终结果。
3.2 示例代码
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
X, y = make_classification(random_state=0)
X_train, X_test, Y_train, Y_test = train_test_split(X, y, random_state=0)
rf = RandomForestClassifier(n_estimators=100,
random_state=0)
rf.fit(X_train, Y_train)
3.3 应该什么时候使用
- 该算法可用于解决基于分类和回归的问题。
- 它特别适合具有高维度的大型数据集,因为该算法本身就执行特征选择。
3.4 优缺点
优点:
- 它可以模拟线性和非线性关系。
- 它对异常值不敏感。
- 随机森林能够在包含缺失数据的数据集上表现良好。
缺点:
- 随机森林可能容易过度拟合,尽管这可以通过修剪在一定程度上减轻。
- 尽管可以提取特征重要性以提供一定程度的可解释性,但它不像线性回归和逻辑回归那样可解释。
四、XGBoost
4.1 基本原理
XGBoost 是一种基于梯度提升决策树的算法。它类似于随机森林,因为它构建决策树的集合,但 XGBoost 不是并行训练模型,而是顺序训练模型。每个决策树都从先前模型产生的错误中学习。这种按顺序训练模型的技术称为提升。
XGBoost 中的梯度是指使用弱学习器的特定类型的提升。弱学习器是非常简单的模型,仅比随机机会表现更好。该算法从初始的弱学习器开始。每个后续模型都针对先前决策树产生的错误。这一直持续到无法做出进一步的改进并产生最终的强大学习者模型。
4.2 示例代码
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
X, y = make_classification(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = XGBClassifier()
model.fit(X_train, y_train)
4.3 应该什么时候使用
- 它可用于解决基于分类和回归的问题。
- XGBoost 通常被认为是用于结构化数据监督学习的最佳和最灵活的算法之一,因此适用于范围广泛的数据集和问题类型。
4.4 优缺点
优点:
- XGboost 非常灵活,因为它在小型和大型数据集上都能同样出色地工作。
- 与其他复杂算法相比,它具有计算效率,因此可以更快地训练模型。
缺点:
- 它不适用于非常稀疏或非结构化的数据。
- 它被认为是一个黑盒模型,比其他一些算法更难解释。
- 由于模型从其前一个模型的错误中学习的机制,XGBoost 可能对异常值敏感。
五、K 均值
5.1 基本原理
K-means 是最流行的聚类算法之一,它是一种无监督机器学习形式,旨在在训练数据集中找到相似示例的组。
该算法通过首先初始化随机簇质心来工作。然后对于每个数据点,通常使用欧几里德距离或余弦相似度的距离度量将其分配给最近的质心。一旦分配了所有数据点,质心就会移动到已分配数据点的平均值。重复这些步骤,直到质心分配停止改变。
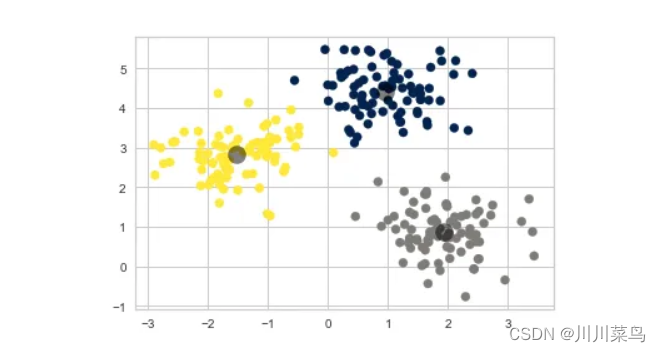
5.2 示例代码
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X, y_true = make_blobs(n_samples=250, centers=3,
cluster_std=0.60, random_state=0)
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
5.3 应该什么时候使用
- K-means 仅适用于无监督聚类。
- 对于这些类型的问题,它通常被认为是一种很好的全能算法。
5.4 优缺点
优点:
- 这是一个实现起来相对简单的算法。
- 它可以用于大型数据集。
- 由此产生的簇很容易解释。
缺点:
- K-means 对异常值很敏感。
- 该算法未找到最佳簇数。这必须在实施之前由其他技术确定。
- 聚类结果不一致。如果 K-means 在数据集上多次运行,它每次都会产生不同的结果。
六、总结对比
- 线性回归:最适合解决存在线性关系且关系相对简单的数据集的基于回归的问题。
- 逻辑回归:最适合解决数据线性可分且数据集维数较低的分类问题。
- 随机森林:最适合具有复杂关系的大型高维数据集。
- XGBoost:适用于范围广泛的结构化数据集和问题。与随机森林相比,计算效率更高。
- K-means:最适合解决无监督聚类问题。