数据库开发系列
文章目录
- 数据库开发系列
- 前言
- 一、MongoDB存储引擎
- 二、MongoDB 复制(副本集)
- 三、为什么需要分片集群架构
- 四、高可用分片集群架构(+复制集)
- 总结
前言
数据库的演进
随着计算机的发展,越来越多的数据需要被处理,数据库是为处理数据而产生。从概念上来说,数据库是指以一定的方式存储到一起,能为多个用户共享,具有更可能小的冗余,与应用程序彼此独立的数据集合。从功能上来说,就是数据管理软件。
到了2000年随着互联网的发展,数据量呈现爆发式增长。海量数据的诞生,传统的关系型数据库在应对大规模,超大流量的时候就显得力不从心。借此,NoSQL数据库跟NewSQLl数据库就此登场。
NoSQL 全称 “not only sql”,所有非关系型的数据库都统称为NoSQL数据库,NoSQL数据库主要有四种类型,文档数据库(MongoDB为代表),键值数据库(Redis为代表),宽列存储(Hbase为代表)和图形数据库(Neo4J为代表)。
NewSQL数据库,提供了与NoSQL相同的扩展性,但仍属于关系型模型,还保留SQL作为查询语言,保证了ACID事务性。代表数据库有Spanner,CockroachDB。
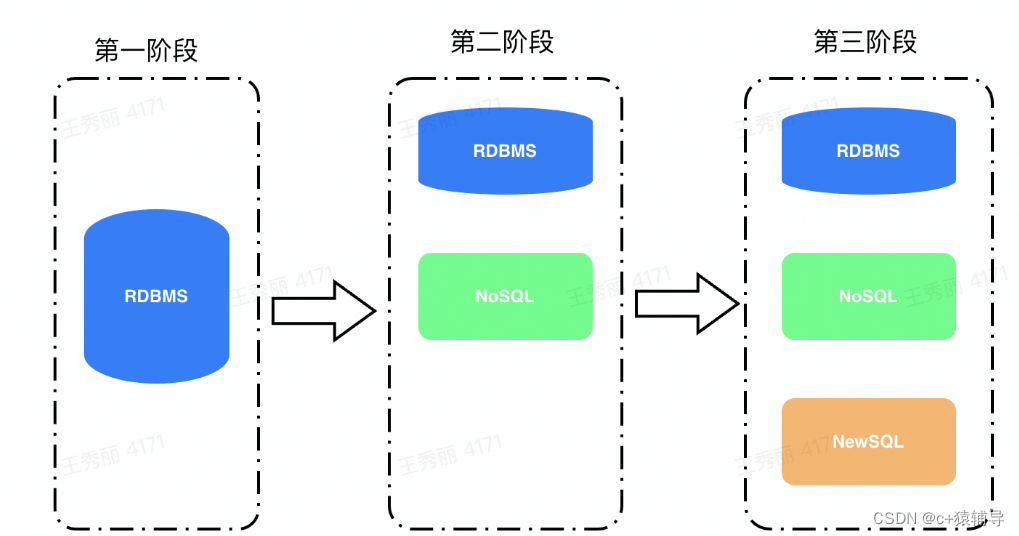
数据库发展到今天,可以说是百花齐放,随着2020年阿里云数据库进入全球魔力四象限的Leader象限,这也是中国数据库40年来首次进入全球顶级数据库行列,标志着国产数据库开始崛起。
数据库索引技术
数据库是用来处理数据的,那高效的存储、检索数据,是数据库管理系统必备的技能。数据库中用于提高检索效率很重要的一项技术就是索引。
数据结构指的是“一组数据的存储结构”,算法指的是“操作数据的一组方法”。数据结构是为算法服务的,算法是要作用在特定的数据结构上的。数据库提高检索效率使用的是索引,数据库索引是一种树形数据结构,如MongoDB使用的是B-tree、MySQL使用的是B+tree。
参考https://blog.csdn.net/dbaxiaosa/article/details/127750957
MongoDB介绍
本文重点介绍MongoDB,它虽然诞生于NoSQL,但4.0版本之后,已经不仅仅是NoSQL了,可以与上文中任何一位NewSQL的代表PK。MongoDB是一个开源、高性能、无模式的文档数据库,旨在简化开发和扩展。
一、MongoDB存储引擎
WiredTiger是在MongoDB3.0版本引入的,并且在MongoDB3.2版本开始成为MongoDB默认的存储引擎。相比较MMAPv1,WiredTiger功能更强大,而且具有更高的性能。3.0版本之前是采用的 MongoDB的MMAPv1存储引擎。
文件空间分配方式改进
MMAPv1存储引擎是在数据库级别分配文件的,将每个数据库中所有的集合和索引都混合存储在数据库文件中,即使删除了某个集合或索引,其占用的磁盘空间也很难及时自动回收。WiredTIger则在集合和索引级别分配文件,将每个数据库中所有的集合和索引都存储在单独的文件中,集合或索引删除后,其对应文件即可删除,磁盘空间回收方便。
WiredTiger的一些数据文件:
mongod.lock:用于防止多个进程连接同一个WiredTiger数据库
.wt文件:存储各个集合的数据,每个文件100MB
WiredTiger.wt:用于存储所有集合的元数据信息
WiredTiger.turtle:用于存储WiredTiger.wt的元数据信息
journal文件夹:用于存储日志文件(Write ahead log)
WiredTiger对内存的使用情况
wiredTiger对内存使用会分为两大部分,一部分是内部内存,另外一部分是文件系统的缓存。内部内存默认值有一个计算公式{ 50% of(RAM-1GB) ,or256MB },索引和集合的内存都被加载到内部内存,索引是被压缩的放在内部内存,集合则没有压缩。wiredTiger会通过文件系统缓存,自动使用其他所有的空闲内存,放在文件系统缓存里面的数据,与磁盘上的数据格式一致,可以有效减少磁盘I/O。
你需要分析是否对默认的内存做调优。一条比较好的原则就是wt的缓存足够大,能够缓存整个应用的工作集。
查看wt的缓存统计信息:
db.serverStatus().wiredTiger.cache
文档级别的并发控制
WiredTiger存储引擎使用文档级别锁,同一时刻多个写操作可以修改同一个集合中不同的文档,但不能修改同一个文档。这使得WiredTiger存储引擎的并发处理能力比MMAPv1更好。
通过检查点和预写日志实现数据持久化
按照MongoDB默认的配置,WiredTiger的写操作会先写入Cache(BTree结构),当Cache大小达到128KB时便将其持久化到预写日志文件(Write ahead log)。WiredTiger每60s或日志文件大小达到2GB时会做一次检查点Checkpoint,产生指定时间点的数据库快照(内存中数据的一致性视图),将快照中的所有数据以一致性方式持久化到数据文件中,保证数据文件和内存数据是一致的。Wiredtiger连接初始化时,首先将数据恢复至最新的快照状态,然后根据预写日志文件恢复数据,以保证存储可靠性。
内存使用上限可配置
使用WiredTiger存储引擎时,MongoDB数据缓存分两部分:内部缓存和文件系统缓存。内部缓存大小可以使用–wiredTigerCacheSizeGB参数来设置,默认值为:1GB或RAM的60%到1GB之间,取两值中较大者。文件系统缓存大小则不固定,MongoDB自动使用系统空闲的内存,且数据在文件系统缓存中是压缩存储的。
数据压缩
使用WiredTiger存储引擎时,数据库的集合与索引、日志文件都是压缩存储的,节省了磁盘空间。WiredTiger默认情况下,集合数据使用块压缩算法,索引数据则使用前缀压缩算法。这使得数据占用磁盘空间少,读写速度快,花费I/O时间少。
集合中数据比较少时,压缩和无压缩的写性能相单,无压缩读性能反而比压缩读性能好。当集合数据很多时,压缩的读写性能则都要比无压缩的读写性能好。
二、MongoDB 复制(副本集)
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
复制还允许您从硬件故障和服务中断中恢复数据。
注:MongoDB复制是异步的,若配置了从Secondary读取数据,则需要业务接受数据延迟。
为什么需要复制?
保障数据的安全性
数据高可用性 (24*7)
灾难恢复
无需停机维护(如备份,重建索引,压缩)
分布式读取数据
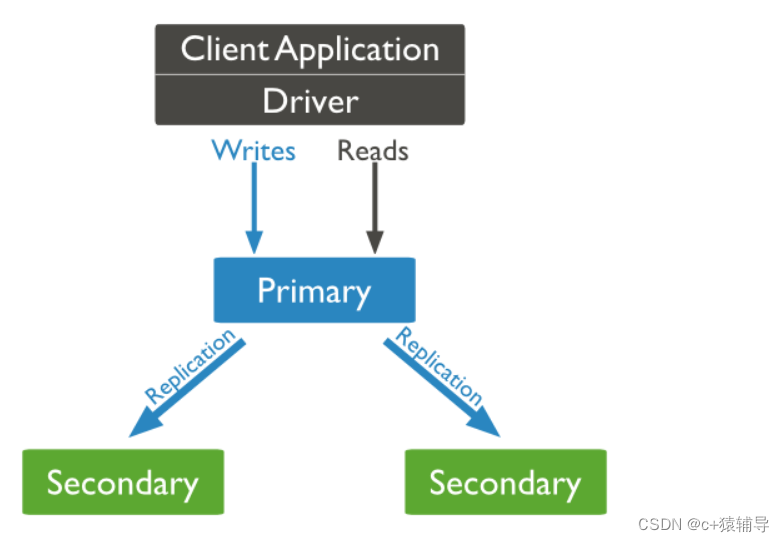
MongoDB复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
副本集特征:
N 个节点的集群
任何节点可作为主节点
所有写入操作都在主节点上
自动故障转移
自动恢复
创建分片语法
//创建mongo实例
mongod --bind_ip "0.0.0.0" --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --logpath "YOUR_LOG_PATH" --replSet "REPLICA_SET_INSTANCE_NAME" --logappend --fork
//启动一个新的副本集
rs.initiate()
//添加副本集
rs.add(HOST_NAME:PORT)
//查看副本集状态使用
rs.status()
//查看副本集的配置
rs.conf()
参数解析
--oplogSize 日志操作文件的大(默认磁盘剩余空间的5%)
--dbpath 数据文件路径
--logpath 日志文件路径
--port 端口号,默认是27017
--replSet 复制集的名字,一个replica sets中的每个节点的这个参数都要用一个复制集名字,这里是test.
--replSet test/ 这个后面跟的是其他standard节点的ip和端口
--maxConns 最大连接数
--fork 后台运行
--logappend 日志文件循环使用,如果日志文件已满,那么新日志覆盖最久日志。
三、为什么需要分片集群架构
当业务遇到如下问题时,可以使用分片集群解决:
1、存储容量受单机限制,即磁盘资源遭遇瓶颈。
2、读写能力受单机限制,可能是CPU、内存或者网卡等资源遭遇瓶颈,导致读写能力无法扩展。
关于负载均衡
MongoDB分片集群的自动负载均衡目前是由mongos的后台线程来做,并且每个集合同一时刻只能有一个迁移任务。负载均衡主要根据集合在各个shard上chunk的数量来决定的,相差超过一定阈值(和chunk总数量相关)就会触发chunk迁移。
负载均衡默认是开启的,为了避免chunk迁移影响到线上业务,可以通过设置迁移执行窗口,例如只允许凌晨02:00~06:00期间进行迁移。
use config
db.settings.update(
{ _id: "balancer" },
{ $set: { activeWindow : { start : "02:00", stop : "06:00" } } },
{ upsert: true }
)
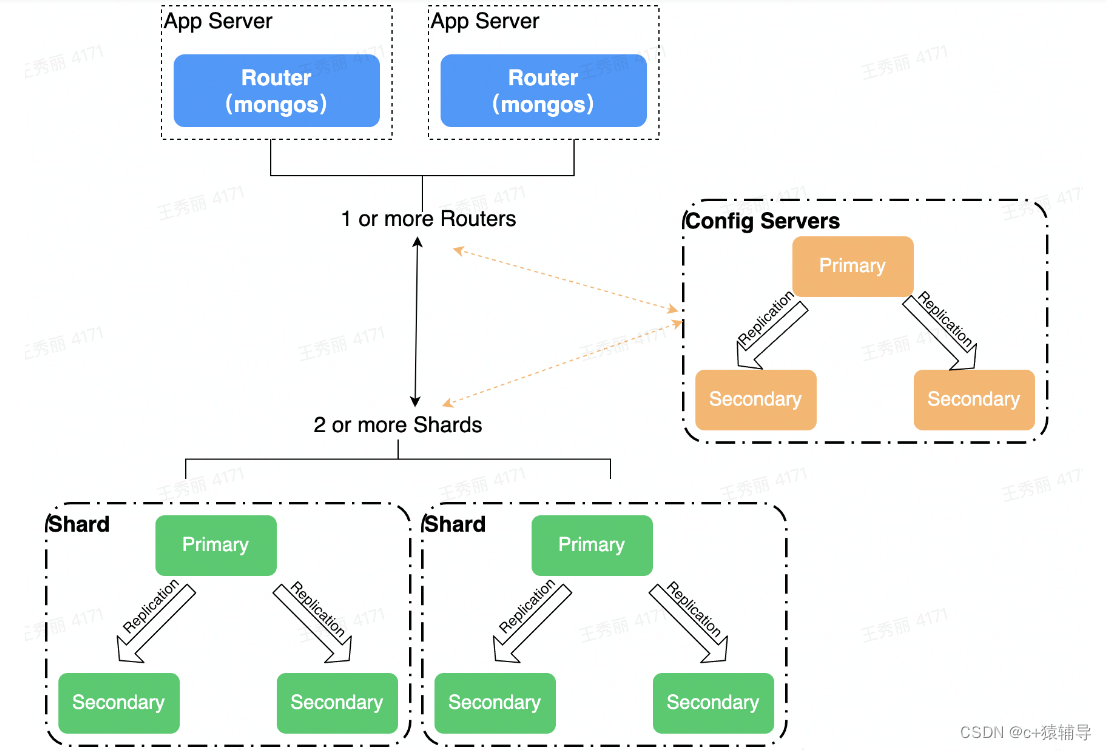
四、高可用分片集群架构(+复制集)
一个 MongoDB分片集群由以下组件组成:
1、shard:每个分片包含分片数据的一个子集。每个分片都可以部署为副本集。
2、mongos:mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。
3、config servers:配置服务器存储集群的元数据和配置设置。从 MongoDB 3.4 开始,配置服务器必须部署为副本集 (CSRS)。
总之:shard、config servers组建部署副本集保障高可用,mongos是单点架构,可以部署多个节点保障高可用。
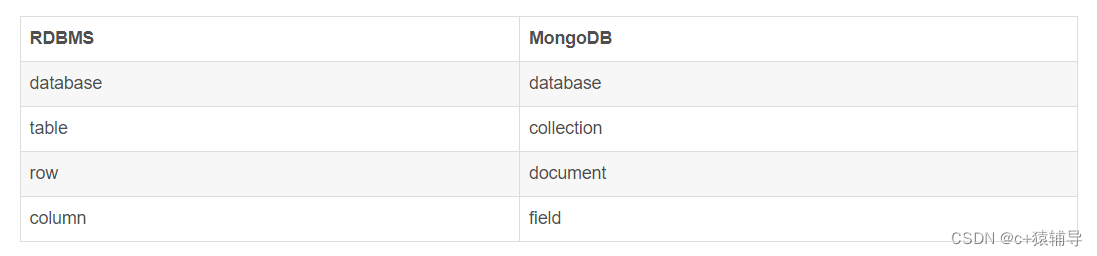
参照关系型数据库,我们来看看MongoDB中的对象。
部署测试(待完成):
总结
通过本文的学习,应该对mongodb的分布式架构有了深刻了理解