1. 损失函数
具有深度学习理论基础的同学对损失函数和反向传播一定不陌生,在此不详细展开理论介绍。损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离向量,绝对值向量等。使用损失函数的流程概括如下:
- 计算实际输出和目标之间的差距。
- 为我们更新输出提供一定的依据(反向传播)。
损失函数的官方文档:Loss Functions。
(1)nn.L1Loss:平均绝对误差(MAE,Mean Absolute Error),计算方法很简单,取预测值和真实值的绝对误差的平均数即可,公式为:
l
o
s
s
=
∣
x
1
−
t
1
∣
+
∣
x
2
−
t
2
∣
+
⋯
+
∣
x
n
−
t
n
∣
n
loss=\frac{|x_1-t_1|+|x_2-t_2|+\dots +|x_n-t_n|}{n}
loss=n∣x1−t1∣+∣x2−t2∣+⋯+∣xn−tn∣。
PyTorch1.13中 nn.L1Loss 数据形状规定如下:
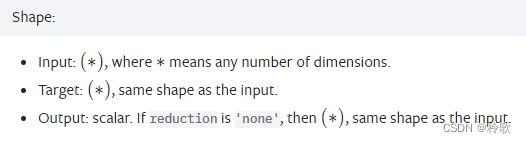
早先的版本需要指定 batch_size 大小,现在不需要了。可以设置参数 reduction,默认为 mean,即取平均值,也可以设置为 sum,顾名思义就是取和。
测试代码如下:
import torch.nn as nn
import torch
input = torch.tensor([1.0, 2.0, 3.0])
target = torch.tensor([4.0, -2.0, 5.0])
loss = nn.L1Loss()
result = loss(input, target)
print(result) # tensor(3.)
loss = nn.L1Loss(reduction='sum')
result = loss(input, target)
print(result) # tensor(9.)
(2)nn.MSELoss:均方误差(MSE,Mean Squared Error),即预测值和真实值之间的平方和的平均数,公式为:
l
o
s
s
=
(
x
1
−
t
1
)
2
+
(
x
2
−
t
2
)
2
+
⋯
+
(
x
n
−
t
n
)
2
n
loss=\frac{(x_1-t_1)^2+(x_2-t_2)^2+\dots +(x_n-t_n)^2}{n}
loss=n(x1−t1)2+(x2−t2)2+⋯+(xn−tn)2。
该损失函数的用法与 nn.L1Loss 相似,代码如下:
import torch.nn as nn
import torch
input = torch.tensor([1.0, 2.0, 3.0])
target = torch.tensor([4.0, -2.0, 5.0])
loss = nn.MSELoss()
result = loss(input, target)
print(result) # tensor(9.6667)
loss = nn.MSELoss(reduction='sum')
result = loss(input, target)
print(result) # tensor(29.)
(3)nn.CrossEntropyLoss:交叉熵误差,训练分类
C
C
C 个类别的模型的时候较常用这个损失函数,一般用在 Softmax 层后面,假设
x
x
x 为某次三分类预测(
C
=
3
C=3
C=3)输出的结果:
[
0.1
,
0.7
,
0.2
]
[0.1,0.7,0.2]
[0.1,0.7,0.2],
t
a
r
g
e
t
=
1
target=1
target=1 为正确解的标签(下标从0开始),则损失函数的计算公式为:
l
o
s
s
(
x
,
t
a
r
g
e
t
)
=
−
w
t
a
r
g
e
t
l
o
g
e
x
p
(
x
t
a
r
g
e
t
)
Σ
i
=
0
C
−
1
e
x
p
(
x
c
)
=
w
t
a
r
g
e
t
(
−
x
t
a
r
g
e
t
+
l
o
g
Σ
i
=
0
C
−
1
e
x
p
(
x
i
)
)
loss(x, target)=-w_{target}log\frac{exp(x_{target})}{\Sigma _{i=0}^{C-1}exp(x_c)}=w_{target}(-x_{target}+log\Sigma _{i=0}^{C-1}exp(x_i))
loss(x,target)=−wtargetlogΣi=0C−1exp(xc)exp(xtarget)=wtarget(−xtarget+logΣi=0C−1exp(xi))。
PyTorch1.13中 nn.CrossEntropyLoss 数据形状规定如下:
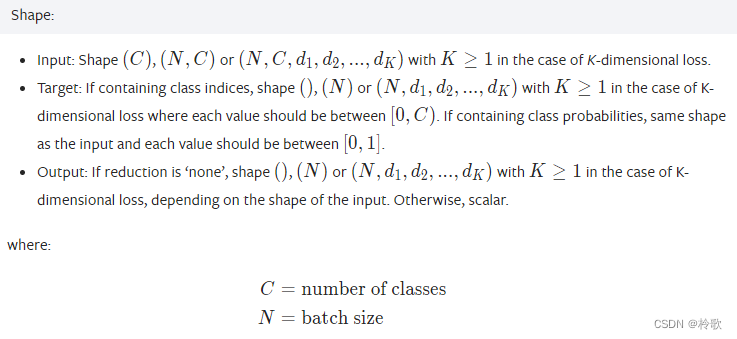
测试代码如下:
import torch.nn as nn
import torch
input = torch.tensor([0.1, 0.7, 0.2])
target = torch.tensor(1)
loss = nn.CrossEntropyLoss()
result = loss(input, target)
print(result) # tensor(0.7679)
input = torch.tensor([0.8, 0.1, 0.1])
result = loss(input, target)
print(result) # tensor(1.3897)
2. 反向传播
接下来以 CIFAR10 数据集为例,用上一节(PyTorch学习笔记-神经网络模型搭建小实战)搭建的神经网络先设置 batch_size 为1,看一下输出结果:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.nn as nn
class CIFAR10_Network(nn.Module):
def __init__(self):
super(CIFAR10_Network, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), # [32, 32, 32]
nn.MaxPool2d(kernel_size=2), # [32, 16, 16]
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), # [32, 16, 16]
nn.MaxPool2d(kernel_size=2), # [32, 8, 8]
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), # [64, 8, 8]
nn.MaxPool2d(kernel_size=2), # [64, 4, 4]
nn.Flatten(), # [1024]
nn.Linear(in_features=1024, out_features=64), # [64]
nn.Linear(in_features=64, out_features=10) # [10]
)
def forward(self, input):
output = self.model(input)
return output
network = CIFAR10_Network()
test_set = datasets.CIFAR10('dataset/CIFAR10', train=False, transform=transforms.ToTensor())
data_loader = DataLoader(test_set, batch_size=1)
loss = nn.CrossEntropyLoss()
for step, data in enumerate(data_loader):
imgs, targets = data
output = network(imgs)
output_loss = loss(output, targets)
print(output)
print(targets)
print(output_loss)
# tensor([[ 0.1252, -0.1069, -0.0747, 0.0232, 0.0852, 0.1019, 0.0688, -0.1068,
# 0.0854, -0.0740]], grad_fn=<AddmmBackward0>)
# tensor([3])
# tensor(2.2960, grad_fn=<NllLossBackward0>)
现在我们来尝试解决第二个问题,即损失函数如何为我们更新输出提供一定的依据(反向传播)。
例如对于卷积层来说,其中卷积核中的每个参数就是我们需要调整的,每个参数具有一个属性 grad 表示梯度,反向传播时每一个要更新的参数都会求出对应的梯度,在优化的过程中就可以根据这个梯度对参数进行优化,最终达到降低损失函数值的目的。
PyTorch 中对损失函数计算出的结果使用 backward 函数即可计算出梯度:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.nn as nn
class CIFAR10_Network(nn.Module):
def __init__(self):
super(CIFAR10_Network, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), # [32, 32, 32]
nn.MaxPool2d(kernel_size=2), # [32, 16, 16]
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), # [32, 16, 16]
nn.MaxPool2d(kernel_size=2), # [32, 8, 8]
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), # [64, 8, 8]
nn.MaxPool2d(kernel_size=2), # [64, 4, 4]
nn.Flatten(), # [1024]
nn.Linear(in_features=1024, out_features=64), # [64]
nn.Linear(in_features=64, out_features=10) # [10]
)
def forward(self, input):
output = self.model(input)
return output
network = CIFAR10_Network()
test_set = datasets.CIFAR10('dataset/CIFAR10', train=False, transform=transforms.ToTensor())
data_loader = DataLoader(test_set, batch_size=1)
loss = nn.CrossEntropyLoss()
for step, data in enumerate(data_loader):
imgs, targets = data
output = network(imgs)
output_loss = loss(output, targets)
output_loss.backward() # 反向传播
我们在计算反向传播之前设置断点,然后可以通过一下目录查看到某一层参数的梯度,在反向传播之前为 None:
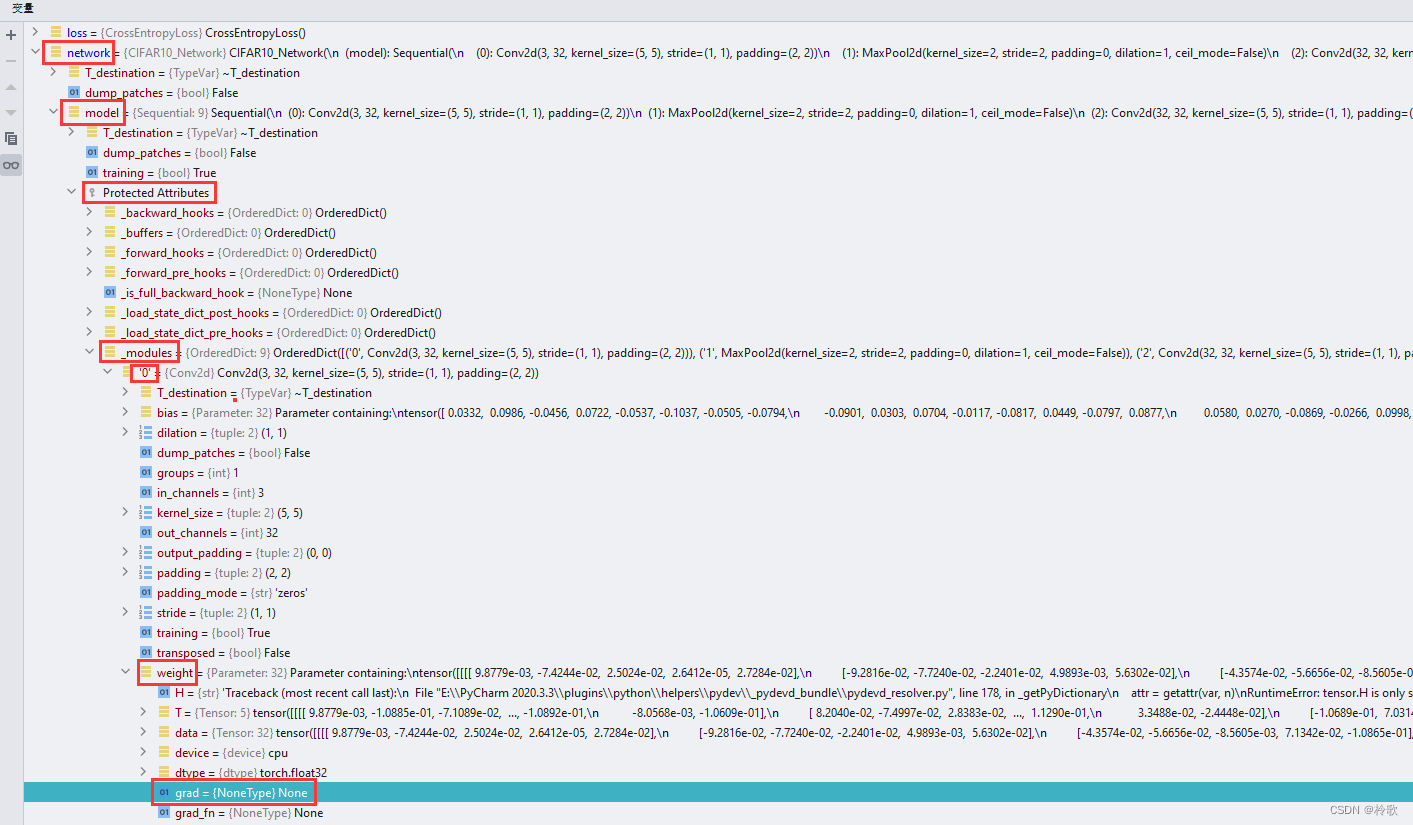
执行反向传播的代码后可以看到 grad 处有数值了:
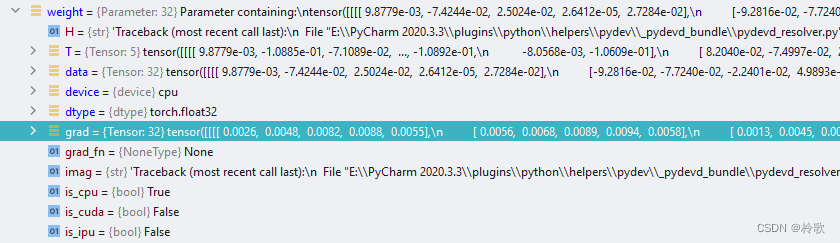
我们有了各个节点参数的梯度,接下来就可以选用一个合适的优化器,来对这些参数进行优化。
3. 优化器
优化器 torch.optim 的官方文档:TORCH.OPTIM。
优化器主要是在模型训练阶段对模型的可学习参数进行更新,常用优化器有:SGD、RMSprop、Adam等。优化器初始化时传入传入模型的可学习参数,以及其他超参数如 lr、momentum 等,例如:
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
在训练过程中先调用 optimizer.zero_grad() 清空梯度,再调用 loss.backward() 反向传播,最后调用 optimizer.step() 更新模型参数,例如:
for step, data in enumerate(data_loader):
imgs, targets = data
output = network(imgs)
output_loss = loss(output, targets)
optimizer.zero_grad()
output_loss.backward()
optimizer.step()
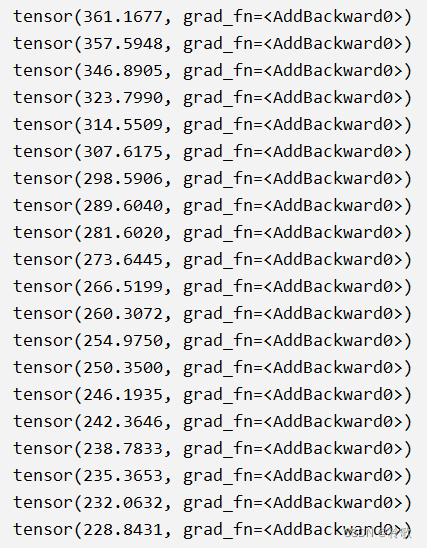
接下来我们来训练20轮神经网络,看看损失函数值的变化:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
class CIFAR10_Network(nn.Module):
def __init__(self):
super(CIFAR10_Network, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), # [32, 32, 32]
nn.MaxPool2d(kernel_size=2), # [32, 16, 16]
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), # [32, 16, 16]
nn.MaxPool2d(kernel_size=2), # [32, 8, 8]
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), # [64, 8, 8]
nn.MaxPool2d(kernel_size=2), # [64, 4, 4]
nn.Flatten(), # [1024]
nn.Linear(in_features=1024, out_features=64), # [64]
nn.Linear(in_features=64, out_features=10) # [10]
)
def forward(self, input):
output = self.model(input)
return output
network = CIFAR10_Network()
test_set = datasets.CIFAR10('dataset/CIFAR10', train=False, transform=transforms.ToTensor())
data_loader = DataLoader(test_set, batch_size=64)
loss = nn.CrossEntropyLoss()
optimizer = optim.SGD(network.parameters(), lr=0.01)
for epoch in range(20): # 学习20轮
total_loss = 0.0
for step, data in enumerate(data_loader):
imgs, targets = data
output = network(imgs)
output_loss = loss(output, targets)
total_loss += output_loss
optimizer.zero_grad()
output_loss.backward()
optimizer.step()
print(total_loss)
训练结果如下图所示,可以看到每一轮所有 batch 的损失函数值的总和确实在不断降低了: