一、APEX
英伟达开发的,压缩数据的框架

(一)安装bug
直接安装
https://blog.csdn.net/weixin_47658790/article/details/115055505
(二)运行bug
然后运行又出现了bug-----------------------
IndexError: tuple index out of range ----- Python
https://github.com/NVIDIA/apex/pull/1282
上面的好像不太管用,改utils.py源码
# if cached_x.grad_fn.next_functions[1][0].variable is not x:
if cached_x.grad_fn.next_functions[0][0].variable is not x:
二、RAGA代码
(一)OOM
报错
Tried to allocate 364.00 MiB (GPU 0; 4.00 GiB total capacity; 2.71 GiB already allocated; 0 bytes free; 3.16 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
看一下报错的含义
https://blog.csdn.net/weixin_57234928/article/details/123556441
如此看来,2.71G的内存+一些缓存,导致没有空间(0 free),然后开始清理缓存,最后留下来了总共3.16G的内容。之前还有364没load,感觉还有希望
改batch实在改不动了
只好把隐藏层dim改一下,从100改成10
可以跑动了,但是在每次打分时,又爆了,emm所以试一下
with torch.no_grad()
每次都是test的时候爆内存,后来发现,test是train的2倍了,改小一点

test改成100个试一下
成功!

(二)torch基础
探索了一下[]的使用
a[0]代表tensor a第1维的第0个;
a[1]代表tensor a第1维的第1个;
a[0][2]代表tensor a第1维的第0个的第2维的第2个;

想不明白为什么1维tensor
[]ha
还是一维的,后来突然想到,如果[]中也是tensor会怎样?
emm做实验不成功,先不看了我哭
三、RAGA pre
我真的觉得我这页GCN的ppt做的好好啊

四、DP pre
(一)defaultdict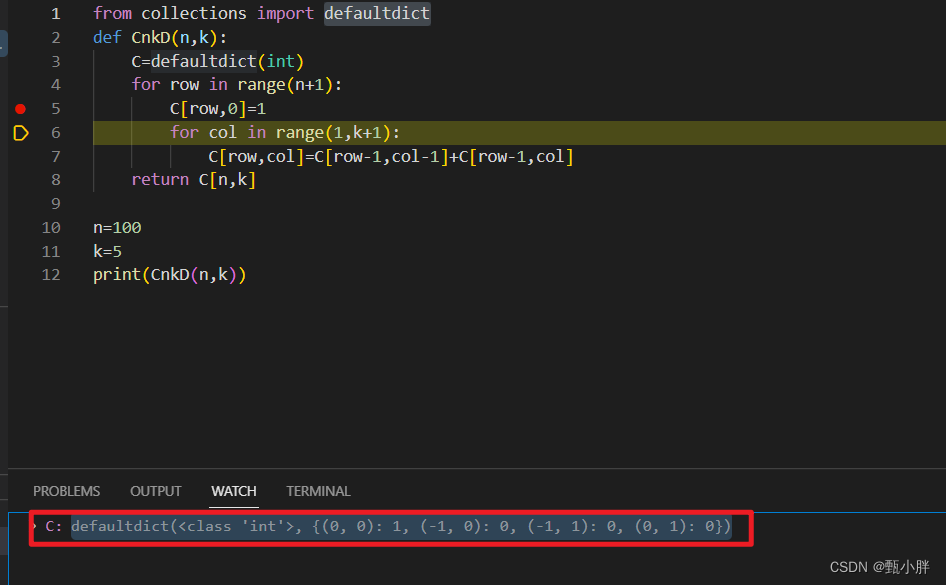
这个东西好神奇呀。
直接可以用字典表示二维数组的形式
芜湖
第一次可以熬夜~
快12点啦~睡啦睡啦