大家好,我是微学AI,今天给大家带来自然语言处理实战项目3-利用CNN做语义分析任务,深度学习在自然语言处理领域中的应用越来越广泛,其中语义分析是其中一个重要的应用。本文将为读者介绍语义分析的任务以及如何用深度学习方法实现该任务。同时,我们也将提供代码示例来帮助读者更好地理解和实践。
一、语义分析任务
语义分析,又称为情感分析或观点挖掘,是指对文本的情感、观点等主观性信息进行分析和判断的任务。通常情况下,语义分析任务可以分为两类:
情感分类任务:将文本划分为正面、负面或中性三个类别中的一个,也称为极性分类任务。
观点提取任务:从文本中提取出与某一主题相关的观点和意见。
语义分析在社交媒体监控、产品评论分析、品牌声誉管理等领域中具有重要的应用。下面,我们将介绍如何用深度学习方法实现情感分类任务。
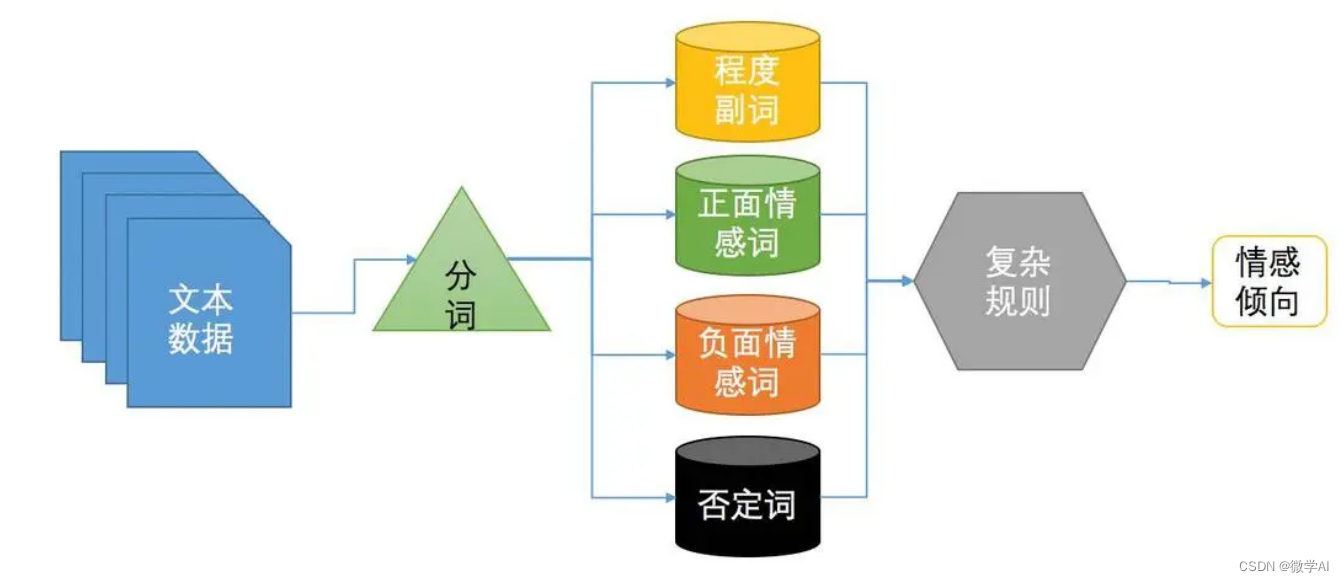
传统的情感分析是利用专家系统,规则定义,甚至是人为定义复杂的规则进行情感分析,提炼程度副词、正面词,否定词等信息规则,这样做的弊端是需要穷举大量的规则,对于新的语句适应性较差。
二、基于深度学习的情感分类
情感分类任务是将文本划分为正面、负面或中性三个类别中的一个。其核心是将文本转化为向量表示,并使用分类器将其划分到对应的类别中。本文将介绍如何使用卷积神经网络(Convolutional Neural Networks,CNN)实现情感分类任务。
数据集
我们将使用IMDB电影评论数据集来进行情感分类任务。该数据集包含50,000条电影评论,其中25,000条用于训练,25,000条用于测试。每条评论已经被标注为正面或负面两种情感之一。
数据预处理
在进行情感分类任务之前,我们需要对文本进行预处理。具体来说,我们需要将文本转化为数字向量的形式,以便于神经网络对其进行处理。在本文中,我们将使用词袋模型(Bag of Words,BoW)来将文本转化为向量表示。
首先,我们需要对文本进行分词,并去除停用词等无用信息。然后,我们将对所有评论中出现的单词进行统计,并将其编号。最后,我们将每条评论表示为一个向量,其中每个元素表示对应单词在该评论中出现的次数。
模型设计
本文将使用卷积神经网络来实现情感分类任务。具体来说,我们将使用一个由卷积层、池化层和全连接层组成的神经网络。其中,卷积层和池化层用于从文本中提取特征,全连接层用于将提取出的特征映射到不同的情感类别中。
卷积层是卷积神经网络的核心组件,用于从输入数据中提取特征。在本文中,我们将使用多个不同大小的卷积核来提取文本中的不同特征。具体来说,我们将使用大小为3、4和5的三个卷积核。每个卷积核的深度为128。
池化层用于对卷积层输出的特征图进行降维。在本文中,我们将使用最大池化(Max Pooling)来实现。具体来说,我们将对每个特征图取最大值,然后将这些最大值拼接在一起作为全连接层的输入。
全连接层用于将提取出的特征映射到不同的情感类别中。具体来说,我们将使用一个包含两个输出节点的全连接层,分别对应正面和负面两种情感。
模型训练
在模型训练之前,我们需要将数据集分为训练集和验证集。在本文中,我们将使用80%的数据用于训练,20%的数据用于验证。
在训练过程中,我们将使用交叉熵损失函数和随机梯度下降(Stochastic Gradient Descent,SGD)优化器。训练过程中,我们将使用批量梯度下降(Batch Gradient Descent)来更新模型参数。
三、代码实现
下面我用Keras框架实现情感分类任务:
import numpy as np
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Conv1D, MaxPooling1D, GlobalMaxPooling1D, Embedding
from tensorflow.keras.preprocessing import sequence
# 设定参数
max_features = 5000
maxlen = 400
batch_size = 32
embedding_dims = 50
filters = 250
kernel_size = 3
hidden_dims = 250
epochs = 10
# 加载数据集
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
# 将序列填充或截断为固定长度
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
# 构建模型
model = Sequential()
# 嵌入层
model.add(Embedding(max_features, embedding_dims, input_length=maxlen))
# 一维卷积层
model.add(Conv1D(filters,
kernel_size,
padding='valid',
activation='relu',
strides=1))
# 最大池化层
model.add(GlobalMaxPooling1D())
# 全连接层
model.add(Dense(hidden_dims))
model.add(Dropout(0.2))
model.add(Activation('relu'))
# 输出层
model.add(Dense(1))
model.add(Activation('sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test))
# 评估模型
score, acc = model.evaluate(x_test, y_test, batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc)运行结果:
Epoch 1/10
782/782 [==============================] - 14s 12ms/step - loss: 0.3867 - accuracy: 0.8082 - val_loss: 0.2688 - val_accuracy: 0.8882
Epoch 2/10
782/782 [==============================] - 9s 12ms/step - loss: 0.1998 - accuracy: 0.9224 - val_loss: 0.2710 - val_accuracy: 0.8870
Epoch 3/10
782/782 [==============================] - 9s 12ms/step - loss: 0.1088 - accuracy: 0.9620 - val_loss: 0.3278 - val_accuracy: 0.8772
Epoch 4/10
782/782 [==============================] - 9s 12ms/step - loss: 0.0453 - accuracy: 0.9856 - val_loss: 0.3632 - val_accuracy: 0.8859
Epoch 5/10
782/782 [==============================] - 9s 12ms/step - loss: 0.0190 - accuracy: 0.9939 - val_loss: 0.5028 - val_accuracy: 0.8844
Epoch 6/10
782/782 [==============================] - 9s 12ms/step - loss: 0.0159 - accuracy: 0.9949 - val_loss: 0.5761 - val_accuracy: 0.8767
Epoch 7/10
782/782 [==============================] - 9s 12ms/step - loss: 0.0248 - accuracy: 0.9905 - val_loss: 0.6028 - val_accuracy: 0.8718
Epoch 8/10
782/782 [==============================] - 9s 12ms/step - loss: 0.0200 - accuracy: 0.9924 - val_loss: 0.5844 - val_accuracy: 0.8788
Epoch 9/10
782/782 [==============================] - 10s 12ms/step - loss: 0.0129 - accuracy: 0.9957 - val_loss: 0.7424 - val_accuracy: 0.8718
Epoch 10/10
782/782 [==============================] - 10s 12ms/step - loss: 0.0130 - accuracy: 0.9952 - val_loss: 0.6867 - val_accuracy: 0.8797
782/782 [==============================] - 3s 3ms/step - loss: 0.6867 - accuracy: 0.8797
Test score: 0.6867138147354126
Test accuracy: 0.8796799778938293
Process finished with exit code 0
本文利用卷积神经网络对IMDB电影评论进行二元分类的示例代码。过程是从Keras中导入了相关库和模块,然后设定了一些超参数,包括最大特征数、序列最大长度、批次大小、嵌入层维度、过滤器数量、卷积核大小、隐藏层维度和训练时的迭代次数等。用了IMDB数据集并将数据集划分为训练集和测试集。然后,它使用pad_sequences()函数将序列填充或截断为固定长度,并且构建了一个序列模型。该模型包含一个嵌入层、一个一维卷积层、一个最大池化层、一个全连接层和一个输出层。模型使用ReLU激活函数和Sigmoid激活函数来实现非线性转换,并使用binary_crossentropy损失函数和adam优化器来进行训练和评估。希望大家一看就懂哦,过程清晰明了。