海量数据的交互式分析工具Dremel
- 产生背景
- 数据模型
- 两方面的技术支撑
- 面向记录和面向列的存储
- 嵌套模型的形式化定义
- 嵌套式的列存储
- 数据的无损表示
- 重复深度的定义
- 定义深度的定义
- 高效的数据编码(了解)
- 数据重组
- 查询语言与执行(了解)
- 性能分析(了解)
- 小结
产生背景
- MapReduce处理大量数据需要等待几小时甚至更长时间才能出结果,重新修改代码再次运行耗时严重。
- 期望实时的数据交互,在一个相对可以接受的合理时间内系统就会返回结果,而不是像MapReduce一样需要耗费很长时间。
故Google团队结合其自身的实际需求,借鉴搜索引擎和并行数据库的一些技术,开发出了实时的交互式查询系统Dremel。
数据模型
两方面的技术支撑
Google的数据平台需要满足通用性,不同平台之间能够很好地实现数据的交互处理。
一方面:统一的存储平台
实现高效的数据存储,Dremel使用的是底层数据存储平台是GFS。
另一方面:统一的数据存储格式
存储的数据才可以被不同的平台所使用。
面向记录和面向列的存储
在关系数据库中,数据的存储方式一般有两种,较早期基本使用的都是行[关系数据库中也称其为元组(tuple)]存储,或者说是面向记录的存储。这种存储方式以行为单位,一行一行地存储数据。
列存储则是以属性为单位,每次存储一个属性,在应用时再将需要的属性重新组装成原始的记录。
Google的Dremel是第一个在嵌套数据模型基础上实现列存储的系统。
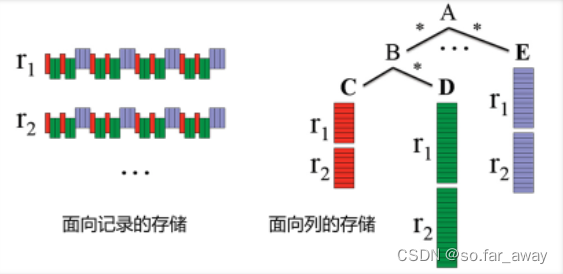
- 好处一:处理时只需要使用涉及的列数据。
- 好处二:列存储更利于数据的压缩。
嵌套模型的形式化定义
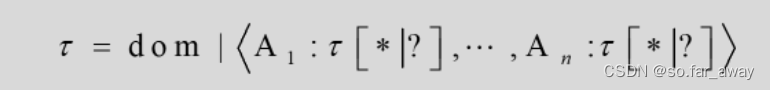
字符τ是一个数据类型的定义,可以是原子类型,也可以是记录类型。
Ai代表该τ的命名,即Ai就是某个τ类型的变量。
原子类型
原子类型允许的取值类型包括整型、浮点型、字符串等。
记录类型
①记录类型可以包括多个域,是使用递归方式定义的,即τ能够由其余以前定义好的τ组成。
②记录型数据包括三种类型:必须的(Required)、可重复的(Repeated)、可选的(Optional),其中Required类型必须出现且仅能出现一次。
这种嵌套式数据模型的定义方式跟具体的语言和处理平台无关,这种跨平台的优良特性正是Google所需要的。
嵌套式的列存储
关系数据库中采用列存储有其便利之处,因为在不同列中相同位置的数据必然属于原数据库中的同一行,因此我们可以直接将每一类的值按顺序排列下来,不用引入其他的概念,也不会丢失数据信息。
(注意空白部分)
嵌套式数据结构的列存储,数据本身之间的关系很复杂。存储后的数据本身反映不出任何结构上的信息,因此存储中除了记录值,还要记录结构。另外,所有的列存储在应用时往往要涉及多个列,如何按照正确的顺序快速进行数据重组也是列存储需要解决的。
Dremel从数据结构的表示等方面解决了上述问题。
数据的无损表示
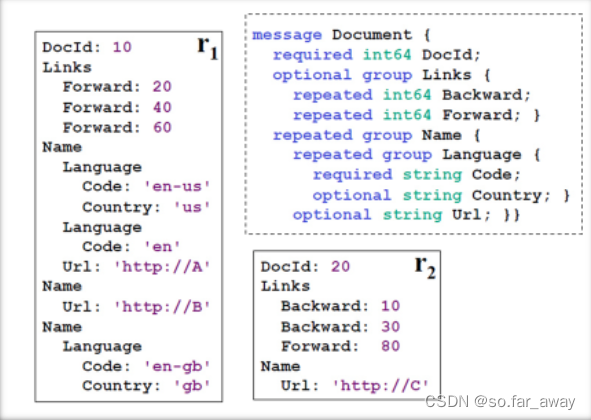
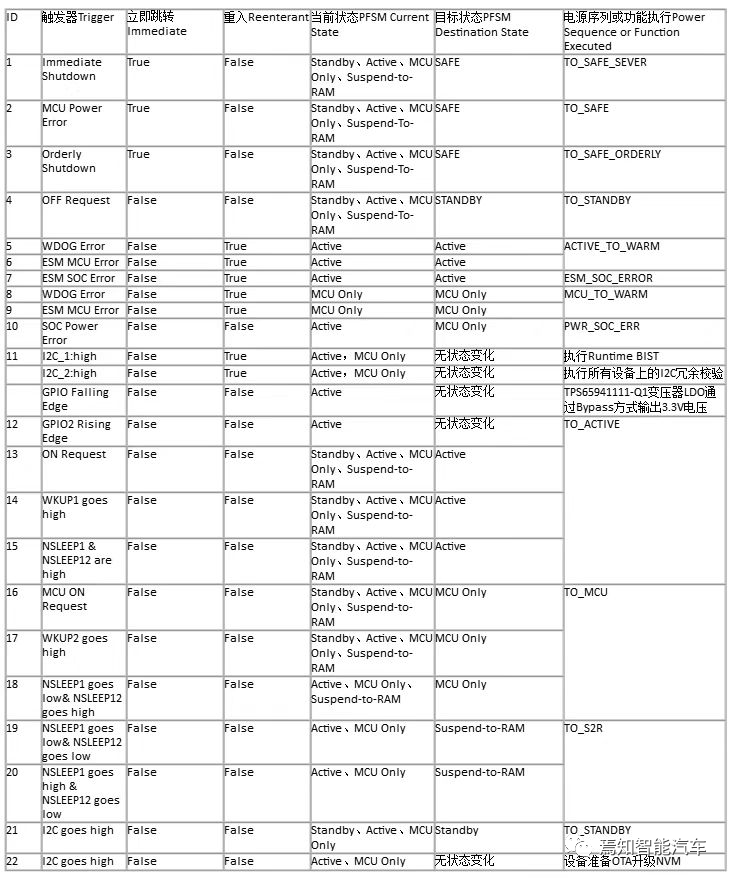
上图是一个记录类型文档的实例。其中,右上角的虚线框内是该文档的模式(Schema)定义。而r1和r2则是符合该模式的两条记录。r1和r2中的属性是通过完整的路径来表示的,比如Name.Language.Code。
在嵌套式的数据模型中,对于某个值,如上图中r1中的’en-us’和’en’,如果仅仅是单纯地记录下来,根本无法判断这两个值对应的是r1中哪个位置,因为它们的路径都是Name.Language.Code,Name.Language.Code在r1中出现了三次。
为了准确地在存储中反映出嵌套的数据,Dremel定义了两个变量:r(Repetition Level,重复深度)、d(Definition Level,定义深度)。
重复深度的定义
从r1中可以发现,Name.Language.Code一共出现了三次,值分别为’en-us’、‘en’和’en-gb’。对照模式定义,不难发现在Name.Language.Code中,可重复的(repeated)字段有Name和Language,因此Code的可重复深度的取值只可能为0、1、2。
0:一个新纪录的开始,也就是没有重复。
1:Name重复
2:Language重复
注:重复深度skip掉所有非repeated类型的字段,即只有repeated类型才算作一级深度。
沿着r1的记录从上到下读取,当我们第一个读取到’en-us’时,我们尚没有看见Name和Language重复出现(这两个字段都是第一次出现),所以’en-us’的r值取0。
接着往下读取,'en’出现的时候,Language出现了第二次,也就是说重复了,因为Language在Name.Language.Code路径中的位置排在第二,所以’en’的r值取2.
当读取到’en-gb’时,Name重复(此Name后Language只出现过一次,没有重复,所以是否重复取决于当前路径),Name在Name.Language.Code中排第一位,所以重复深度是1。
因此r1中Code的值的重复深度分别是0、2、1,简单来说,重复深度记录的是该列的值在哪一个级别上重复的。
要注意第二个Name在r1中没有包含任何Code值,为确定’en-gb’出现在第三个Name而不是第二个,系统会添加一个NULL值在’en’和’en-gb’之间。由于在模式定义中,Language字段中的Code字段是必需的(required),所以它的缺失意味着Language也没有定义。
注:当计算Dremel中的查询路径的重复深度(repeated depth)时,只需要考虑出现的[Repeated]字段,这是因为前者定义为“沿着从根到任意元素的路径中重复的最大次数”,而optional字段只会在其中某些路径中出现一次或不出现,因此对于整个结构体的重复次数没有影响,不需要计入重复深度的计算,以及required字段一定会出现,但只会出现一次,也不需要计入重复深度的计算。
总结:
Dremel中重复深度的定义并不考虑非repeated类型的字段,因为required(必须出现且只能出现一次)和optional类型的值不可能重复,所以只考虑repeated类型字段出现的情况就可以完整表达出嵌套结构中字段的重复情况。
可见,重复深度主要关注的是可重复类型。
定义深度的定义
以Name.Language.Country路径为例,按照模式定义,Name、Language和Country三个字段均属于可有可无型。
Name.Language.Country在r1中一共有4个定义,值分别为’us’、NULL、NULL和’gb’,Name、Language、Country都是有定义的,所以’us’的d值为3。同理,第一个NULL的d值为2,第二个NULL的d值为1,'gb’的d值为3。
也就是说值的d值是该路径上定义的字段的个数。
总结:
定义深度同时关注可重复类型和可选类型。
定义深度表示“值的路径中有多少可以不被定义(因为是可重复类型或可选类型)的字段实际是有意义的”。
如下是带有重复深度和定义深度的r1和r2的列存储:
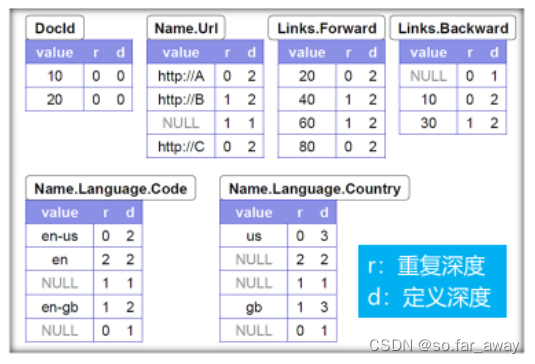
每一列最终会被存储为块(Block)的集合,每个块包含重复深度和定义深度且包含字段值。
NULLs没有明确存储因为它们可以根据定义深度确定:任何定义深度小于可重复和可选字段数量之和就意味着这是一个NULL。必需字段的值不需要存储定义深度。
类似地,重复深度只在必要时存储;比如,定义深度0意味着重复深度0,所以后者可省略。
高效的数据编码(了解)
在Google,经常会出现模式包含成千上万的字段,却仅有几百个在记录中被使用的情况。因此需要尽可能廉价地处理确实字段。

数据重组
无论何种模型,只要采用列存储,在使用时都需要考虑数据重组问题。
数据重组:将查询涉及的列取出,然后将其按照原始记录的顺序组装起来,让用户感觉好像数据库中仅存在这些查询设计的列一样。
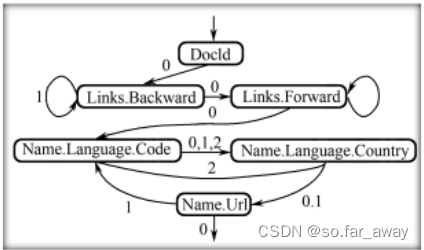
Dremel数据重组方法的核心思想是为每个字段创建一个有限状态机(FSM),读取字段值和重复深度,然后顺序地将值添加到输出结果上。
下图是r1的有限状态机:
下图是r1的完整重组过程:
重复深度驱动状态变迁,一旦一个reader获取了一个值,就去查看下一个值的重复深度来决定状态如何变化、跳转到哪个reader。
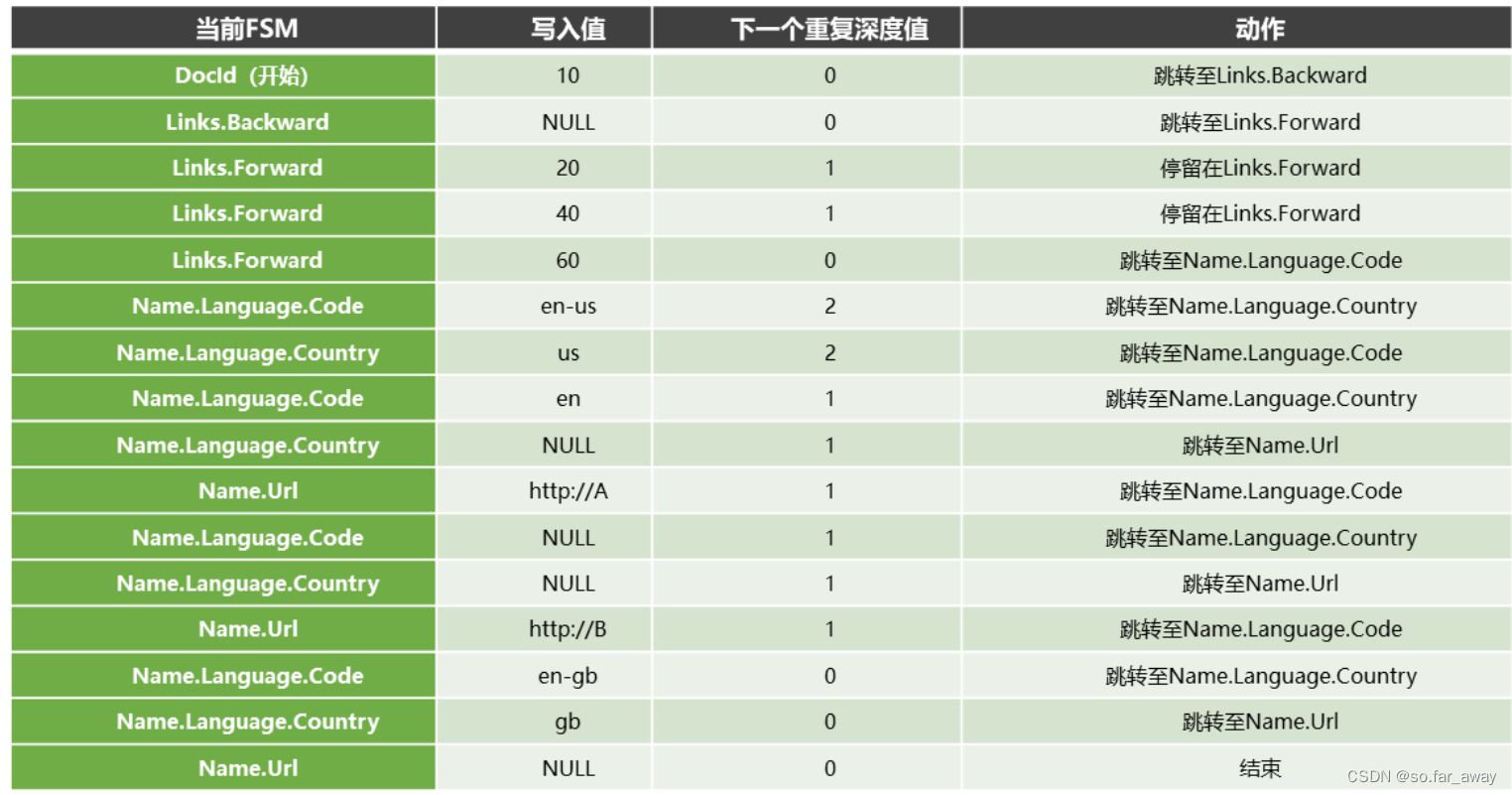
数据重组未完待续~~
查询语言与执行(了解)
Dremel的SQL查询输入的是一个或多个嵌套结构的表以及相应的模式,而输出的结果是一个嵌套结构的表以及相应的模式。
Dremel利用多层级服务树的概念来执行查询操作。
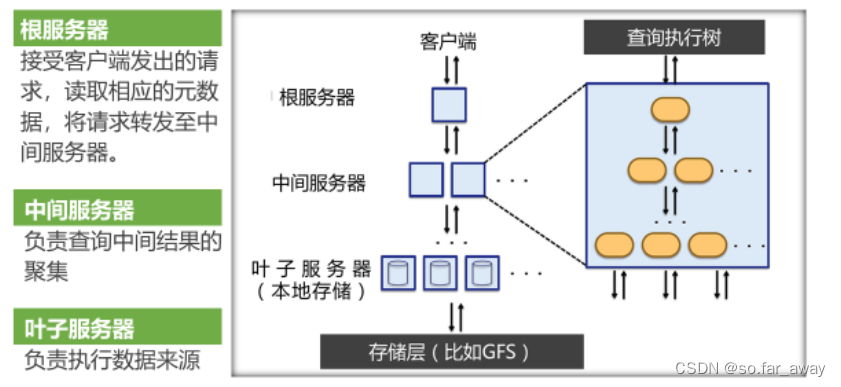
Dremel中的数据都是分布式存储的,因此每一层查询涉及的数据实际都被水平划分后存储在多个服务器上。
Dremel是一个多用户系统,因此同一时刻往往会有多个用户进行查询。
查询分发器有一个很重要参数,它表示在返回结果之前一定要扫描百分之多少的tablet。
性能分析(了解)
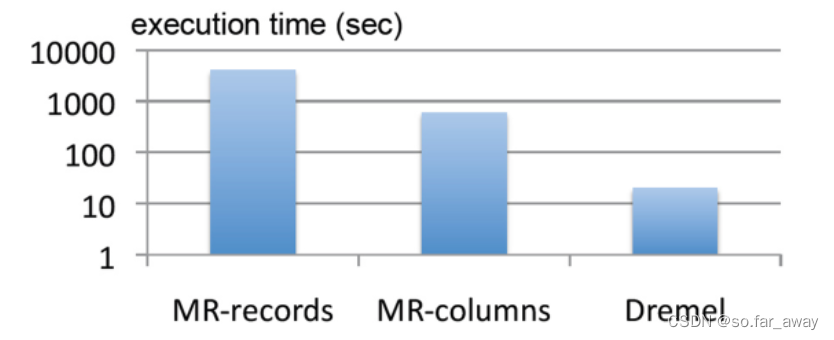
MapReduce从面向记录转换到列状存储后性能提升了一个数量级(从小时到分钟),而使用Dremel则又提升了一个数量级(从分钟到秒)。
小结
- Dremel和MapReduce并不是相互替代,而是相互补充的技术。在不同的应用场景下各有其用武之地。
- Drill的设计目标就是复制一个开源的Dremel,但是从目前来看,该项目无论是进展还是影响力都达不到Hadoop的高度。
- 希望未来能出现一个真正有影响力的开源项目实现Dremel的主要功能并被广泛采用。