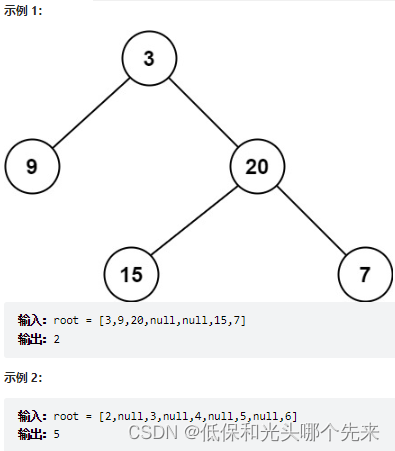
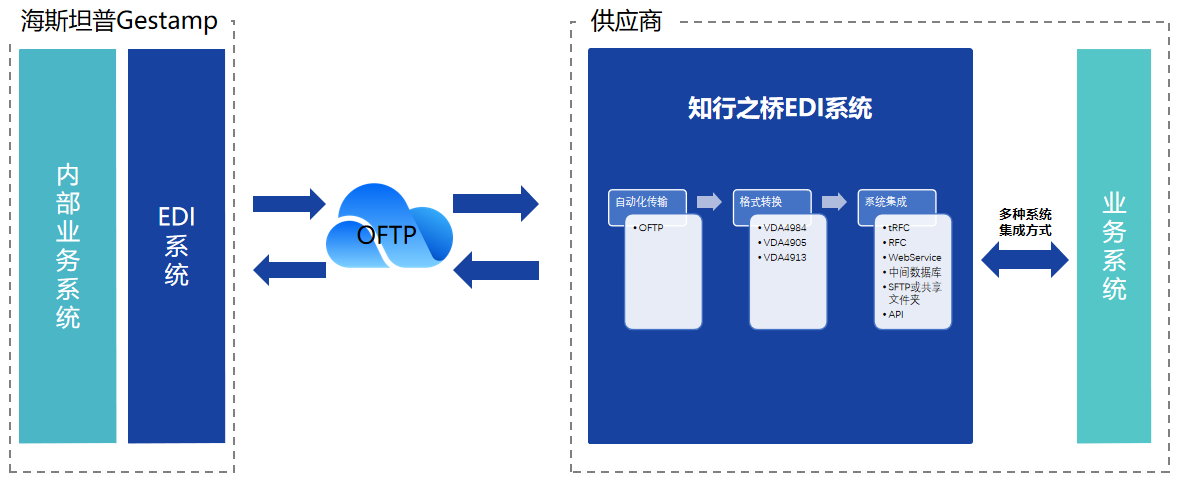
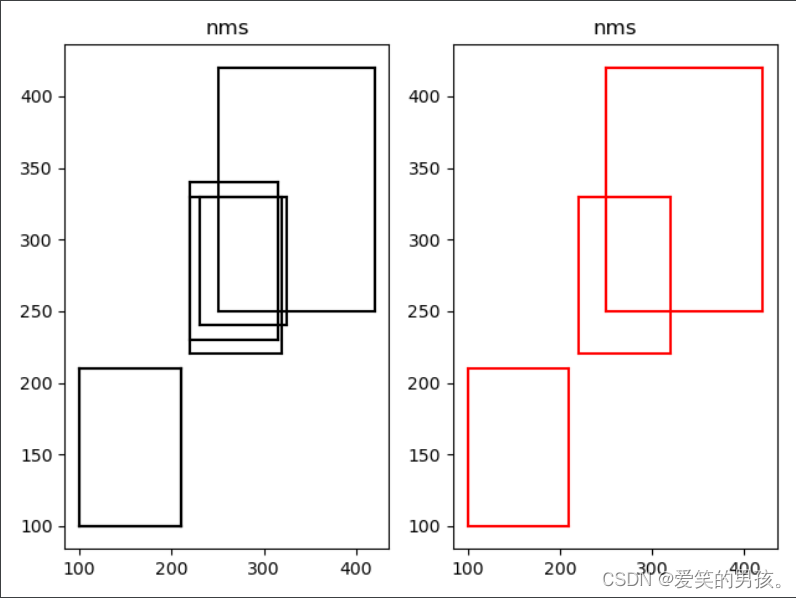
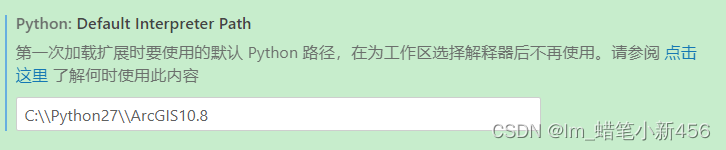
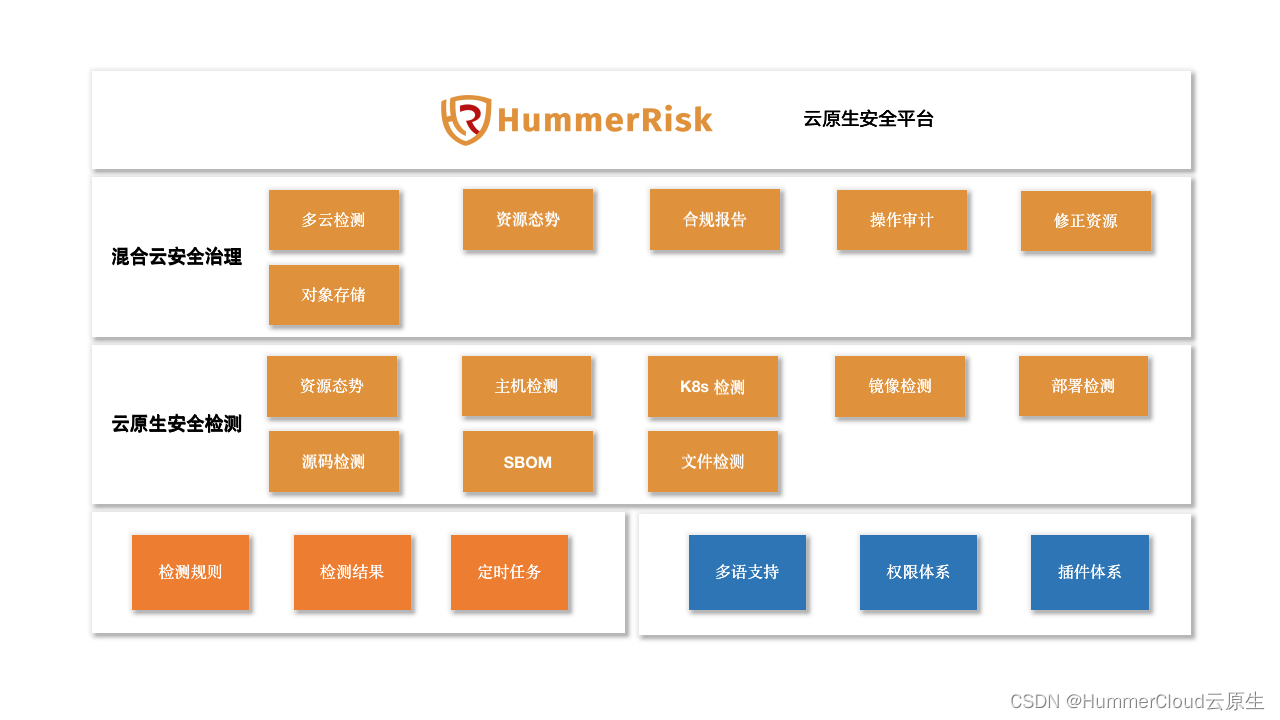
ps.实际生产环境中并不会使用mapReduce,而是spark和flink,但是它可以建立分布式的思想。
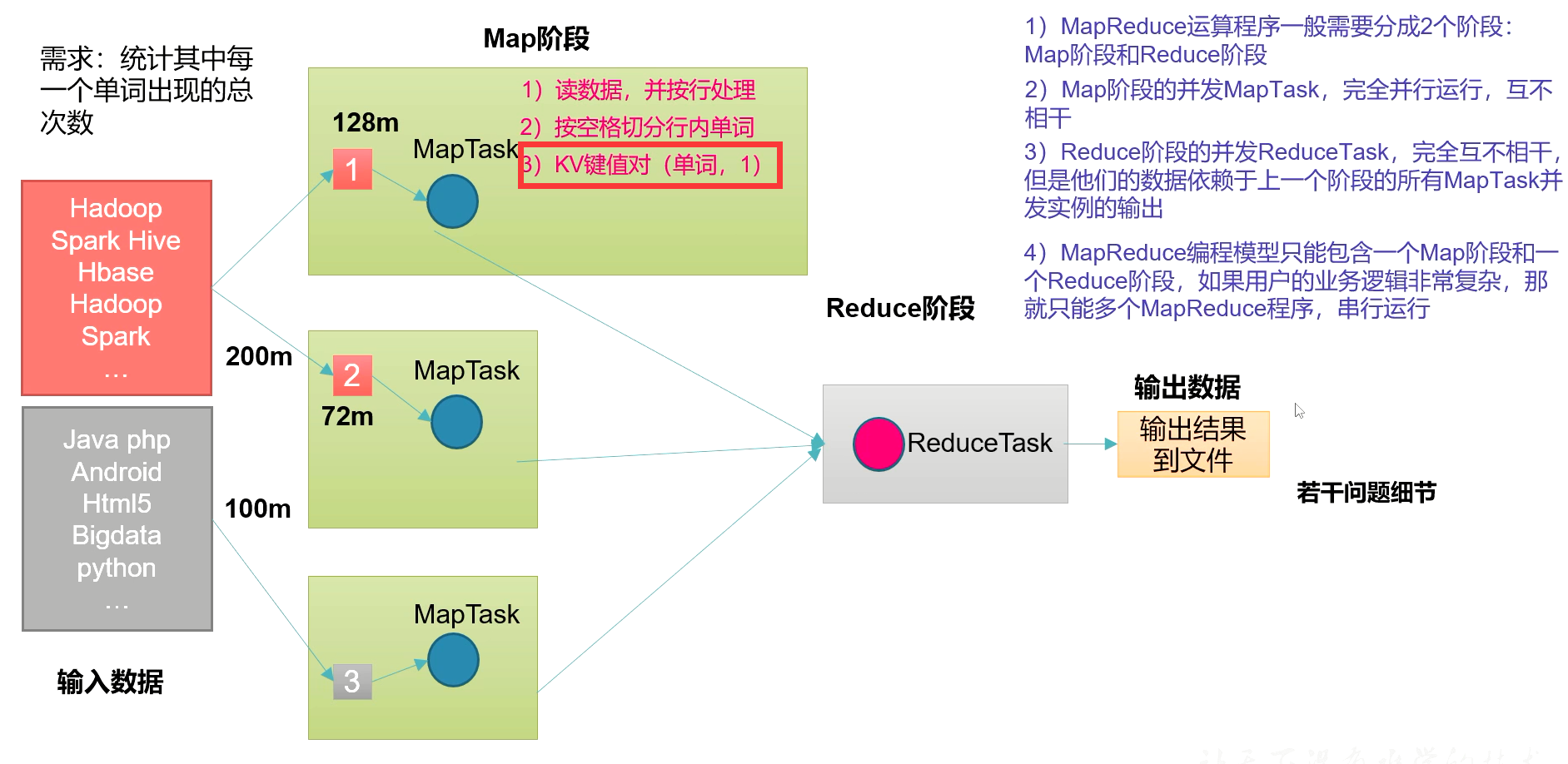
1.MapReduce框架
2.mapReduce小项目练习
ps.基本流程:一般都是在代码层面引入hadoop依赖,然后在windows环境下进行代码编写测试,没有问题的话,把代码打包成jar包,然后拖入xShell,利用liunx执行测试.
(1) 数据序列化的类型:
| Java类型 | Hadoop Writable类型 |
| Boolean |
BooleanWritable |
ps.实际生产环境中并不会使用mapReduce,而是spark和flink,但是它可以建立分布式的思想。
ps.基本流程:一般都是在代码层面引入hadoop依赖,然后在windows环境下进行代码编写测试,没有问题的话,把代码打包成jar包,然后拖入xShell,利用liunx执行测试.
(1) 数据序列化的类型:
| Java类型 | Hadoop Writable类型 |
| Boolean |
BooleanWritable |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/442336.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!