🐱作者:一只大喵咪1201
🐱专栏:《Linux学习》
🔥格言:你只管努力,剩下的交给时间!

信号
- 🔔信号
- 🎵预备知识
- 🎵信号处理方法的注册
- 🔔信号的产生
- 🎵通过终端按键产生信号
- 🎵调用系统调用向进程发信号
- 🎵硬件异常产生信号
- 🎵由软件条件产生信号
- 🔔核心转储
🔔信号
从生活中入手,例如发令枪,闹钟,红绿灯等等,这些都是信号。信号必须都是动态的,像路标就不能称之为信号。
以红绿灯为例,一看到红绿灯我们就知道红灯行,绿灯停,我们不仅能认识它是一个红绿灯,而且还知道应该产生什么样的行为,这样才算是能够识别红绿灯。
- 识别 = 认识 + 行为产生
对于红绿等这个信号,我们需要有如下几个共识:
- 我们之所以能识别红绿灯,是因为我们受到过教育(手段),让我们在大脑中记住了不同颜色对应的行为(属性)。
- 当绿灯亮了以后,不一定要立刻过马路,比如有其他的车闯红灯,需要进行避让,所以说我们不一定要立刻产生相应的行为。
- 红灯亮了以后,正好来了一个电话,在接电话这个期间我们会记住此时是红灯,不会将这个状态忘记。
- 红绿灯默认的行为是红灯行,绿灯停,但是也可以产生其他行为,还可以忽略。
现在将生活中红绿灯的例子迁移到进程中:
- 共识:信号是发给进程的。
- 进程之所以能够识别信号,是因为程序员将对应的信号种类和逻辑已经写好了的。
- 当信号发给进程后,进程不一定要立刻去处理,可能有更加紧急的任务,会在合适的时候去处理。
- 进程收到信号到处理信号之前会有一个窗口期,这个期间要将收到的信号进行保存。
- 处理信号的方式有三种:默认动作,自定义动作,忽略。
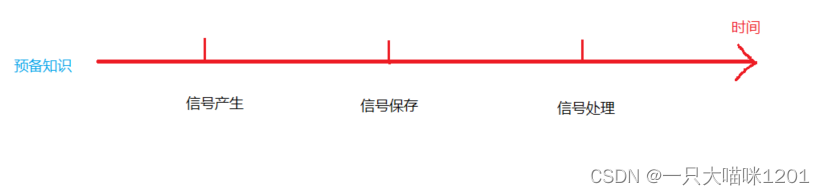
我们学习信号是学习它的整个生命周期,按照时间轴,分为信号产生,信号保存,信号处理。但是在这之前先需要学习一些预备知识。
🎵预备知识
进程能够识别的信号是已经写好的,它有62个:
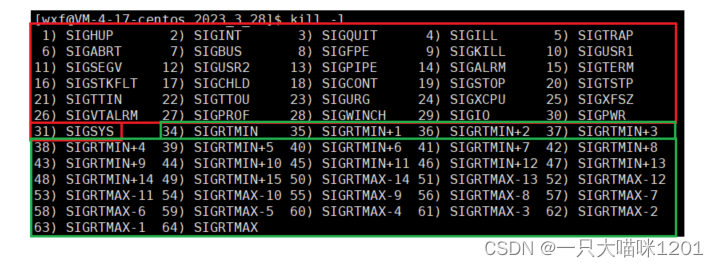
- 红色框中的是普通信号,编号从1-31。
- 绿色框中的是实时信号,编号从34-64。
这其中没有32号和33号信号,所以一共有62个信号。而且这里我们只学习普通信号,对实时信号暂不做研究。
- 在使用这些信号时,可以用信号名,也可以用信号编号,它是一样的,都是宏定义后的结果。
根据我们对Linux的了解,信号存放在哪里呢?既然信号是给进程的,而进程是通过内核数据结构来管理的,所以我们可以推断出,信号放在进程的task_struct结构体中。
既然它是在PCB中,而且数量是31个,task_struct中必定不会设置31个变量来存放信号,数组还有可能,但是信号的状态只分为有和没有两种,所以再次推断,31个信号放在一个32位的整形变量中,每个比特位代表一个信号。
本喵写一段伪代码来示意一下:
struct task_struct
{
//进程属性
unsigned int signal;
//.......
}
就像在学习基础IO和进程间通信的时候,那些flags标志中的不同的比特位代表着不同的意义,这31个信号量也是这种方式:

具体的保存细节后面本喵再详细讲解。
问题来了,内核数据结构的修改,这个工作是由谁来完成的?毫无疑问是操作系统,因为task_struct就是它维护的,而且是存在于内存中的,只有操作系统才有权力去修改它,用户是无法直接操作的,因为操作系统不相信任何人。
所以说,无论哪个信号,最后的本质都是由操作系统发生给进程的,这里的发送本质就是在修改task_struct中存放信号那个变量的比特位。
- 信号发送的本质就是在修改PCB中的信号位图。
无论未来我们学习了多少中发送信号的方式,本质都是通过操作系统向目标进程发送信号。
所以操作系统一定会提供相关的系统调用,比如我们之前使用过的各自信号:
kill -9 pid值 //停止某个进程
kill -19 pid值 //暂停某个进程
kill -18 pid值 //继续某个进程
它们的底层一定是在调用相关的系统调用,来让操作系统修改PCB中的信号位图。
🎵信号处理方法的注册
- 所谓的注册,就是告诉操作系统,当某个进程接收到某个信号后的处理方式。
既然是告诉操作系统,那么肯定会用到系统调用,该系统调用的名字是signal():
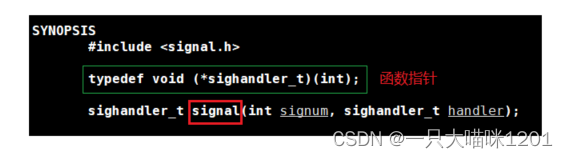
- int signal:要注册的信号编号
- sighandler_t handler:自定义的函数指针
可以将信号的处理方式写成一个函数,然后将函数名传递个signal,此时当进程接收到signum指定的信号编号时,就会执行我们定义的函数。
void handler(int signo)
{
cout<<"进程接收到的一个信号,编号:"<<signo<<endl;
}
函数的返回类型必须是void类型,形参必须是signo类型,名字可以随意。
补充:
我们之前,在shell的命令行中,会按crtl + c 来结束正在运行的进程。这种键我们称为热键。
ctrl + c本质是上一个组合键,操作系统识别到这种组合键后,会将它解释为2号信号SIGINT。

现在将我们自己写的函数注册为2号信号的处理方式。
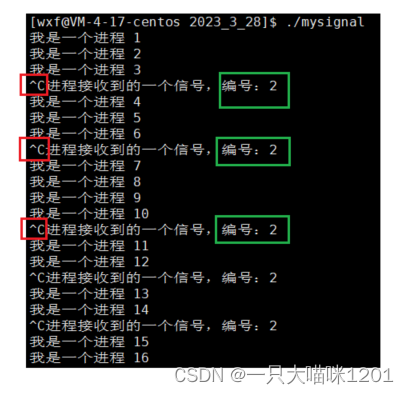
运行起来后发现,按上ctrl+c后,进程不会结束了。
- 2号信号SIGINT的默认处理方式就是结束进程。
- 我们自定义的处理方式中并没有结束进程,所以进程在收到2号进程后打印了一句话。
- 所有信号的默认处理方式都是结束进程,只是不同的信号代表的意义不一样。
小实验:
我们将31个信号都自定义处理方式,并且不退出进程,那么这个进程是不是就无法退出了?
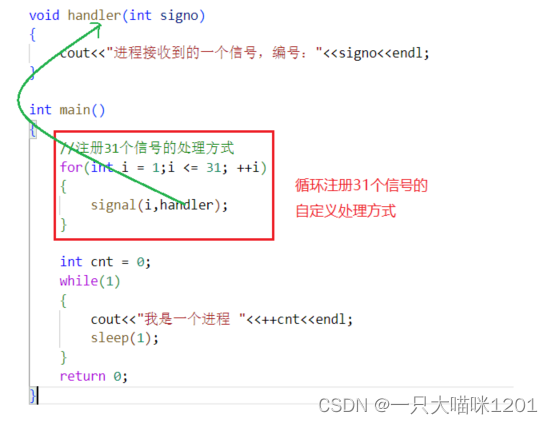
此时31个信号的自定义处理方式中都没有进程退出。
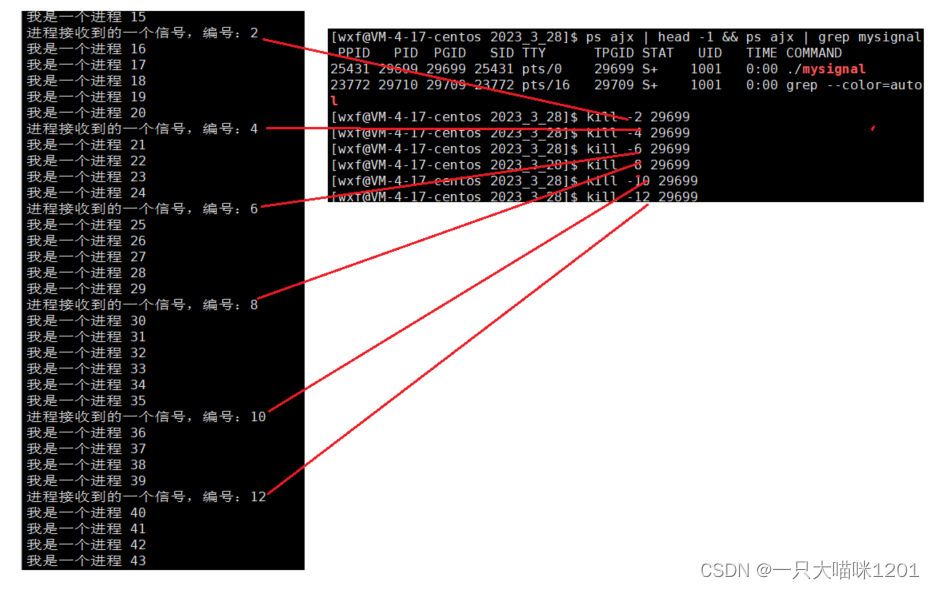
可以看到,给这个进程这么多信号,都没有结束,而且自定义处理方式也执行了,打印出了接收到的信号编号,但是进程还是在执行。
那这样是不是意味着这个进程无法结束了?不是的,操作系统就防着你呢,不会让这种恶意的东西存在的。
- 9号信号SIGKILL是不能够自定义处理方式的,所以该信号能够将这个进程结束掉。
kill -9 pid值//杀死指定进程
该指令可以结束任何进程,这就是操作系统留的后手。
🔔信号的产生
有了上面的预备知识以后,就可以正式来研究信号了。
🎵通过终端按键产生信号
也就是在键盘上按一些热键,来给进程发送相应的信号,ctrl+c在上面本喵就讲解过了,它产生的是2号信号SIGINT。
还有常用按键ctrl+\,它产生的是3号信号SIGQUIT。
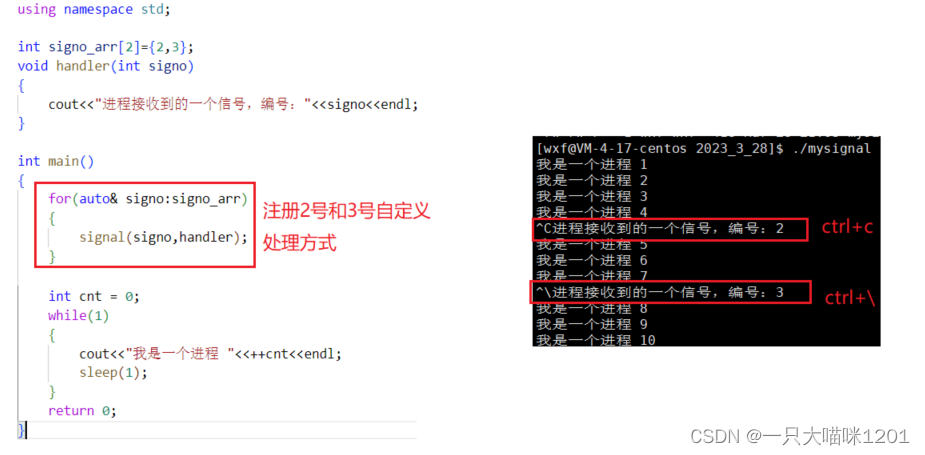
可以看到通过键盘产生了2号和3号信号。
🎵调用系统调用向进程发信号
系统调用kill():
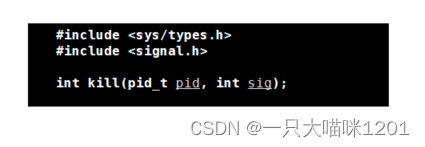
- pid_t pid:要给发信号的pid
- int sig:要发送的信号编号
- 返回值:发送成功返回0,失败返回-1
该系统调用是一个进程给另一个进程发送指定信号,可以向任意进程发送任意信号。
信号接收端:

这是一个一直在运行的程序,用来接收从其他进程发送过来的信号。
信号发送端:
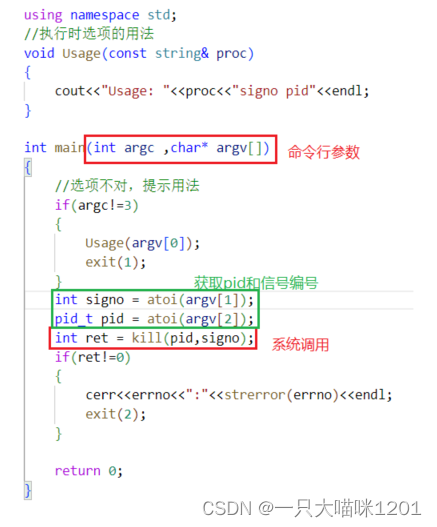
这是一个带有命令行参数的程序,输入的选项中的pid值和信号编号,在程序中在调用kill系统调用向指定pid的进程发送指定信号。
效果:
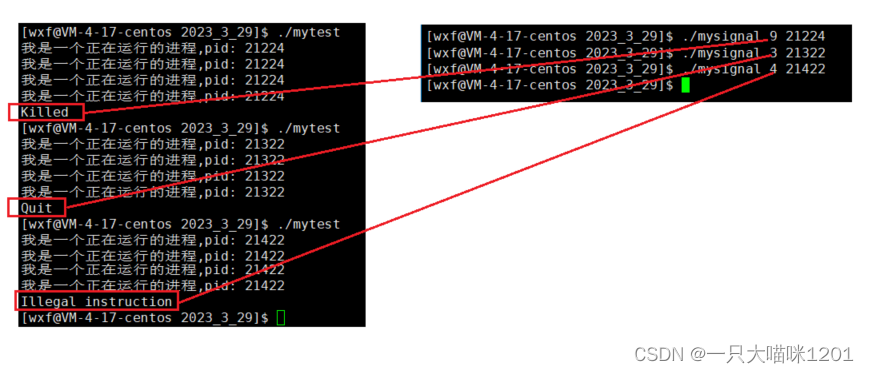
左边在执行mysginal的时候,输入对应的信号编号和pid,右边正在运行的进程就会接收到指定的信号而停止运行。
系统调用raise():
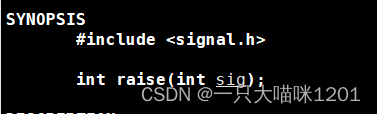
- int sig:要发送的信号
- 返回值:发送成功返回0,失败返回-1
该系统调用是由进程自己调用,也就是进程自己可以给自己发送任意信号。

通过命令行参数指定信号,在程序执行5秒钟后给自己发送该信号。
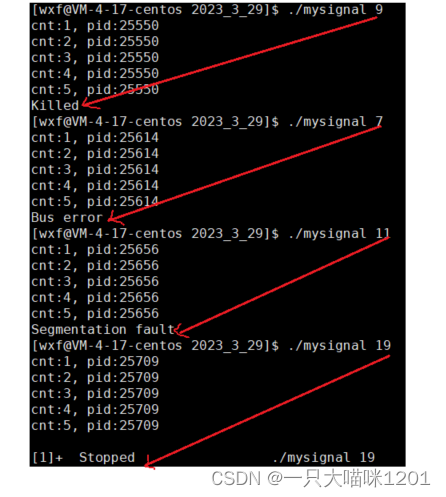
无论命令行输入哪个信号的编号,在5秒钟后,该进程都会给自己发送输入的信号,让进程结束。
系统调用abort():
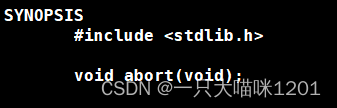
- 没有参数,没有返回值
该系统调用只能给自己发送指定的信号,该信号是SIGABRT,信号编号是6。

5秒钟后给自己发送SIGABRT信号。
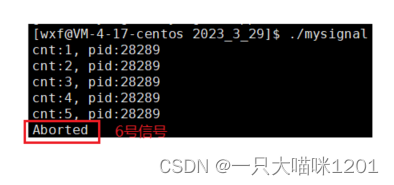
在运行5秒钟后,该进程接收到了6号信号SIGABRT。
虽然有3个系统调用来产生信号,但是归根到底都是在使用kill系统调用。
- kill()可以给任意进程发送任意信号。
- raise()可以给自己发送任意信号。
//raise本质
kill(getpid(),signo);
- abort()可以给自己发送SIGABRT信号。
//abort本质
kill(getpid(),SIGABRT);
🎵硬件异常产生信号
除0操作导致的硬件异常:
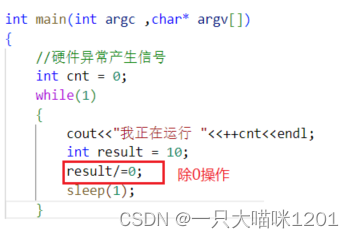
在这段代码中,有除0操作,我们知道,除0得到的是无穷大的数,所以在编程的时候是不允许出现的。
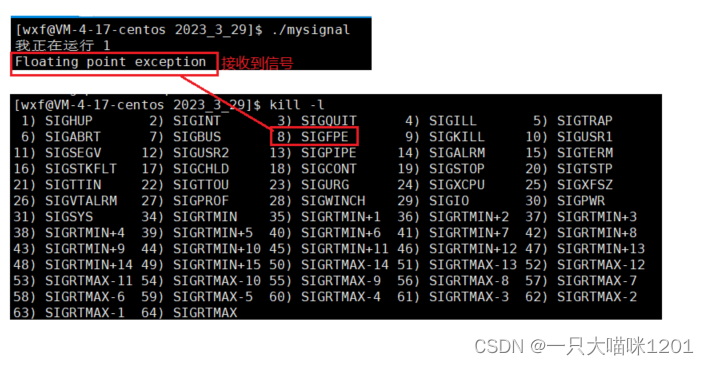
- 在运行的时候,直接出错,没有再执行下去,是因为接收到了信号。
- 接收到的信号是SIGFPE信号,编号为8号。
这其实就是一种硬件异常产生的信号。
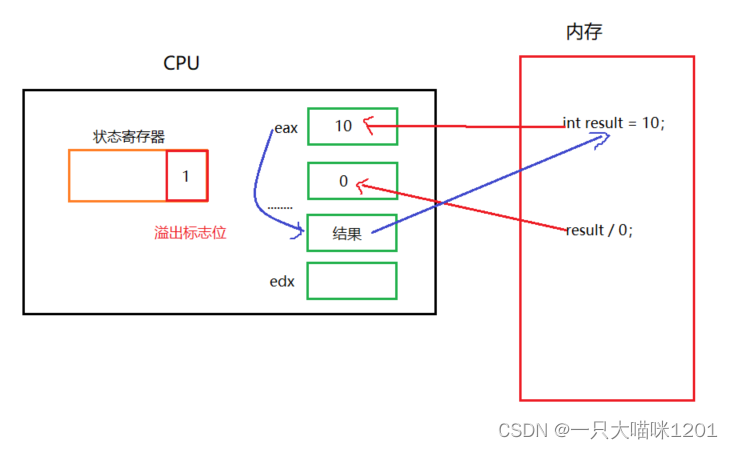
- CPU中有很多的寄存器,例如eax,ebx,eip等等。
CPU会从内存中将代码中的变量拿到寄存器中进行运算,如果有必要,还会将运算的结果放回到内存中。
- 还有一个状态寄存器,如果CPU在运算的时候发现了除0操作,就会将状态寄存器的溢出标志位置一。
此时就意味着硬件产生了异常。而操作系统是一个进行软硬件资源管理的软件,CPU的中状态寄存器的溢出标志位置一后,操作系统可以第一时间拿到。
- 除0导致硬件异常以后,操作系统会给对应的进程发送SIGFPE信号。
当进程接收到SIGFPE信号以后,默认的处理方式就是结束进程。
现在我们对这个SIGFPE信号注册一个自定义处理方式:

只打印接收到的信号编号,进程不退出。
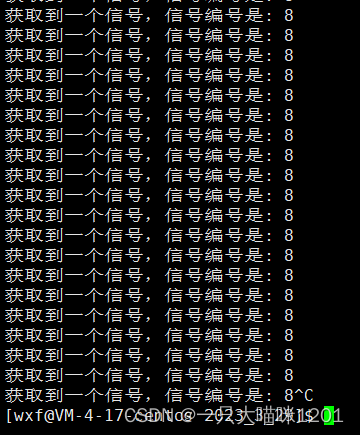
在进程运行起来后,怎么就开始鞭尸了呢?也就是这个信号被操作系统不停的发送给这个进程。
- 进程收到信号后进程不退出,随着CPU时间片的轮转就会再次被调到。
- CPU中只有一份寄存器,但是寄存器中的内容属于当前进程的上下文。
- 当进程被切换的时候,就有无数次的状态寄存器被保存和恢复的过程。
- 而除0操作导致的溢出标志位置一的数据还会被恢复到CPU中。
- 所以每一次恢复的时候,操作系统就会识别到,并且给对应进程发送SIGFPE信号。
所以就会导致上面不停调用自定义处理函数,不停打印接收到的信号编号。
解引用空指针导致的硬件异常:
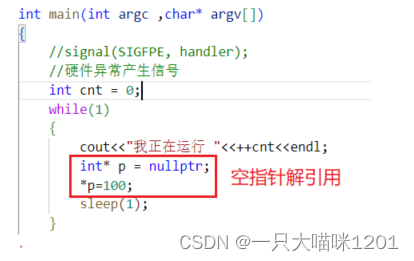
上面代码中存在对空指针的解引用操作,空指针的本质是(void*)0,而0地址处是不允许我们用户进行访问的,这部分属于内核空间。
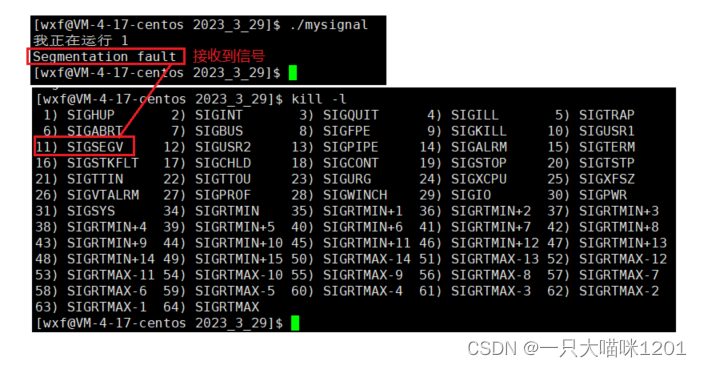
- 运行的时候直接出错,没有再运行下去,也是因为接收到了信号。
- 接收到的信号是SIGSEGV,编号是11。
这同样是一种硬件异常产生的信号。
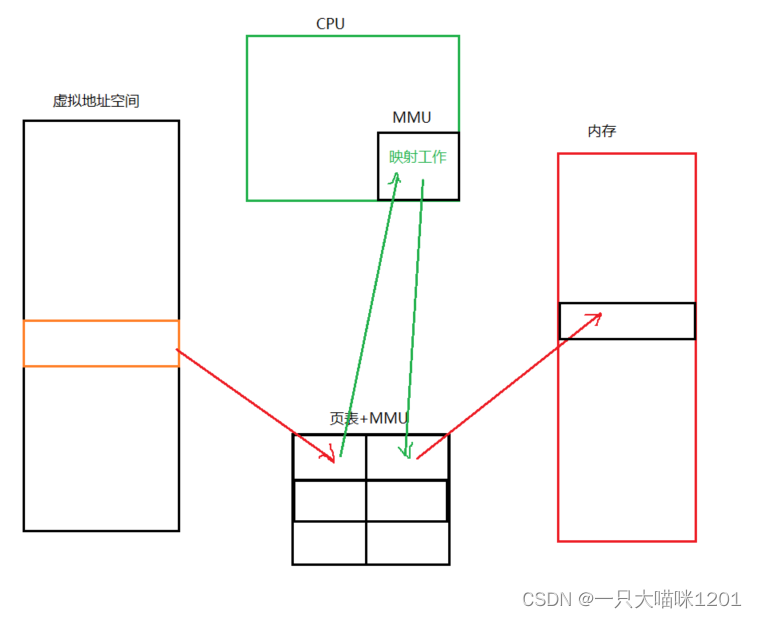
- 我们之前一直谈论的页表时间上是页表+MMU,而MMU是在CPU中的,未来简便,我们就只说页表。
- 进程地址空间和物理内存之间的映射关系实际上是有MMU去完成映射的。
- 当对空指针解引用的时候,MMU会拒绝这种操作,从而产生异常标志。
- 操作系统拿到MMU产生的异常以后就会给对应的进程发送SIGSEGV信号。
当进程接收到编号为11的SIGSEGV信号以后,默认的处理动作就是结束进程。
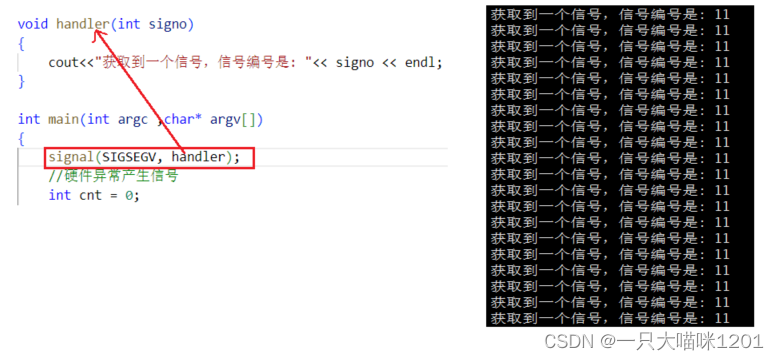
将这个信号注册自定义处理方式,同样打印接收到的信号编号,但是不结束进程,可以看到,和除0操作一样,也是在鞭尸,不停的打印。
- 硬件异常所产生的信号,如果不结束这个进程,我们是没有能力去处理这个进程的。
- 随着时间片的轮转,这个导致硬件异常的进程还会不停的调到,所以操作系统会不停的向进程发送信号。
- 硬件异常产生的信号并不会显示发送,而是由操作系统自动发送的。
🎵由软件条件产生信号
读端关闭触发的信号:
比如在学习匿名管道的时候,当读端关闭的时候,写端所在进程就会收到编号为13的SIGPIPE信号结束进程。
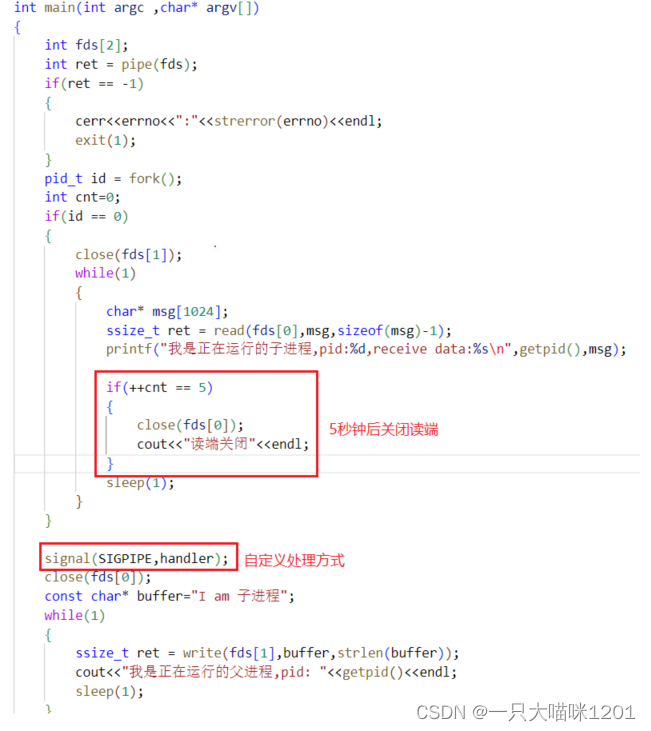
读端5秒钟之后关闭,写端进程注册自定义处理方式,打印写端接收到的信号编号,但是不结束进程。
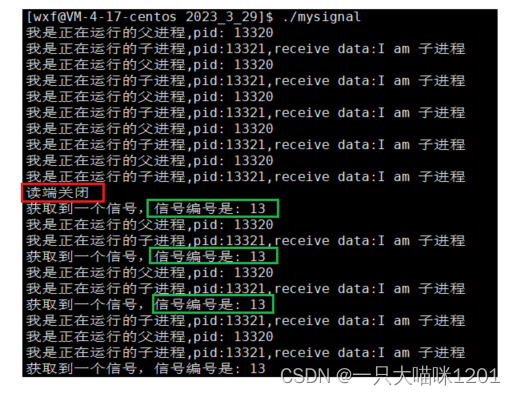
在读端关闭以后,写端的自定义处理方式中就接收到了系统发给的SIGPIPE信号,编号为13。
- 读端是否关闭是软件中的条件。
- 当条件达成以后,产生信号。
闹钟触发的信号:
闹钟就是系统中的定时器,使用的时候同样需要通过系统调用实现:

- 参数:要定的时长。
- 返回值:距离定的时间还差多少。

定时1秒钟,在循环中进行疯狂加1,设置自定义处理方式,打印定时到后收到的信号编号,并且统计这一秒中内进行了多少次加1操作。
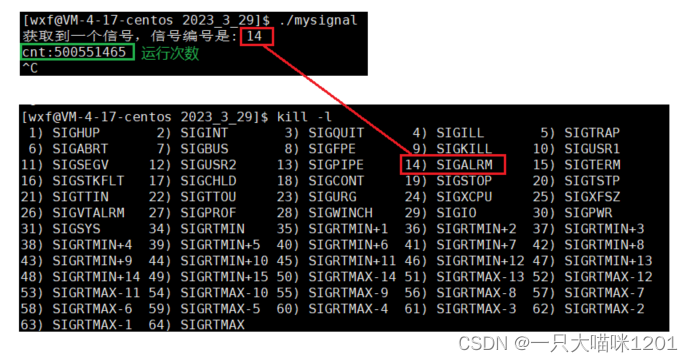
当定时1秒钟时间到了以后,自定义处理方式中打印出接收到的信号编号是14号的SIGALRM信号,并且统计出了1秒钟进行加1操作的次数。
- 自定义处理方式中没有退出进程,所以在执行完处理方式以后,进程继续运行。
- 也就是继续进行加1操作,但是不会再收到信号了,因为定时到的条件只达成一次,所以信号也只产生一次。
如果想每隔一秒条件达成一次,产生一次SIGALRM信号,可以在这样处理:
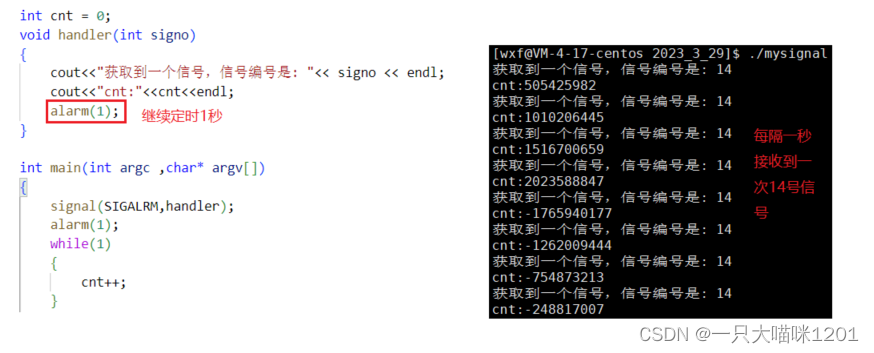
- 在自定义处理方式中定时1s。
- 当1秒定时条件达成以后,产生信号,执行处理方法后会开始新一轮的定时。
- 软件中某个条件达成以后,操作系统就会产生相应的信号,比如上面的SIGPIPE信号和SIGALRM信号。
闹钟的管理:
操作系统中会有很多个进程,我们可以创建一个闹钟,那么其他进程也可以创建闹钟,这样就会存在很多个闹钟,那么这些闹钟是怎么管理的呢?先描述再组织。
首先需要创建一个闹钟的结构体,伪代码:
struct alarm
{
unit64_t when;//定时时长
int type;//闹钟类型,一次性还是周期性
task_struct* p;//所属进程的地址
struct_alarm* next;//下一个闹钟的地址
//其他属性
}
大概就是这样的一个结构体来描述闹钟,必须由的肯定是定时时长,所属进程。
接下来就是组织了,用某一种数据结构来管理这些闹钟对象,为了方便管理,可以选择优先级队列prority_queuq来管理。
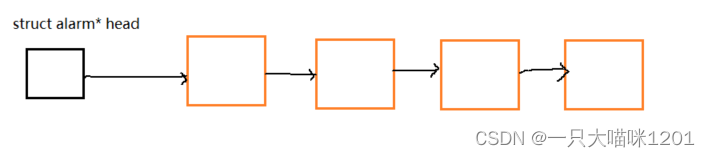
- 将定时时间最小的闹钟放在前面,时间长的放在后面。
- 操作系统每次只需要检测队首的定时时间是否达到就可以。
- 达到了就向对应进程发送SIGALRM信号,并且从队列中取出,以待再次检测。
操作系统会周期性的检测链表中的这些闹钟,伪代码:
curr_timestamp > alarm.when;//超时了
//OS发送SIGALRM信号到alarm.p;
具体的实现细节有兴趣的小伙伴可以看看源码是怎么管理的,这里本喵只是介绍一种思想。
🔔核心转储
是否有一个疑问,31个信号的默认处理方式都是结束进程,并且还可以自定义处理方式,那么为什么要这么多信号呢?一个信号不就行了吗?
- 重要的不是产生信号的结果,而是产生信号的原因。
- 所有出现异常的进程,必然是收到了某一个信号。
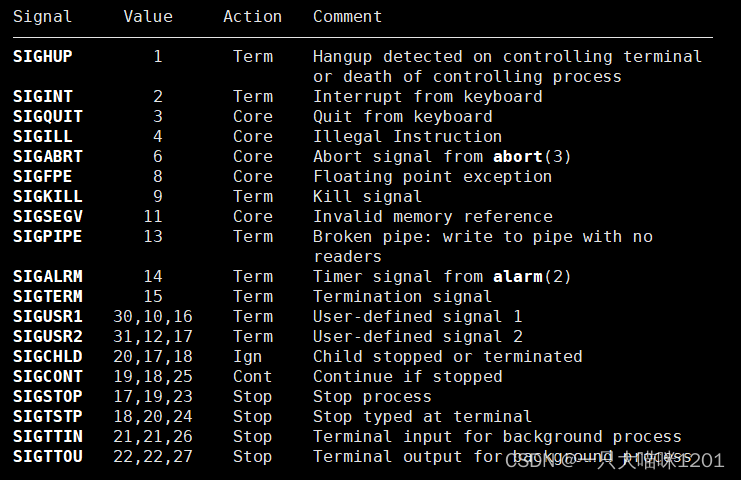
在man的7号手册中介绍了信号的名称,对应的编号,默认处理方式,以及产生该信号的原因。
- 我们可以根据这个表找到不同信号产生所对应的不同原因。
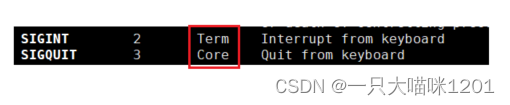
以信号2和3为例,他两的默认处理方式一个是Term,一个是Core。
- Term和Core的结果都是结束进程。
那么这两个方式的区别在哪里呢?
- Term方式仅仅是结束进程,结束了以后就什么都不干了。
- 但是Core不仅结束进程,而且还会保存一些信息。
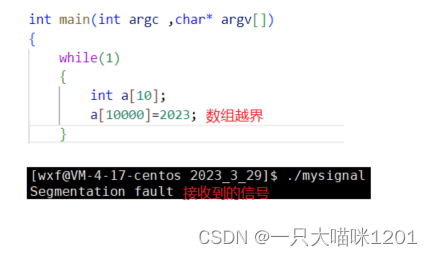
在数据越界非常严重的时候,该进程会接收到SIGSEGV信号,来结束进程。
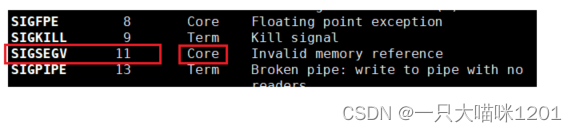
- 11号信号的默认处理方式是Core。
在云服务器上,默认情况下是看不到Core退出的现象的,这是因为云服务器关闭了core file选项:
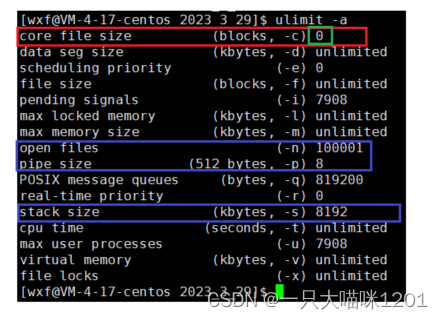
- core file size(红色框)的大小是0,意味着这个选项是关闭的。
- 从这里还可以看到别的关于这个云服务器的信息,比如能够打开的最多文件个数,管道个数,以及栈的大小等等信息。
为了能够看到Core方式的明显现象,我们需要将core file选项打开:
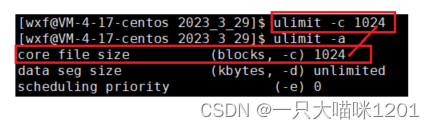
此时该选项就打开了,表示的意思就是核心转储文件的大小是1024个数据块。
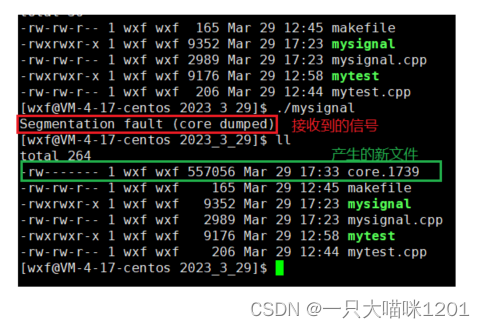
- 再运行数据越界的程序时,同样会收到SIGSEGV信号停止。
- 但是在当前目录下会多出一个文件,如上图中的绿色框。
- core.1739:被叫做核心转储文件,其中后缀1739是接收到该信号进程的pid值。
对于一个奔溃的程序,我们最关心的是它为什么崩溃,在哪里崩溃?
- 当进程出现异常的时候,将进程在对应的时刻,在内存中的有效数据转储到磁盘中-------核心转储。
- 核心转储的文件我们可以拿着它进行调试,快速定位到出现异常而崩溃的位置。
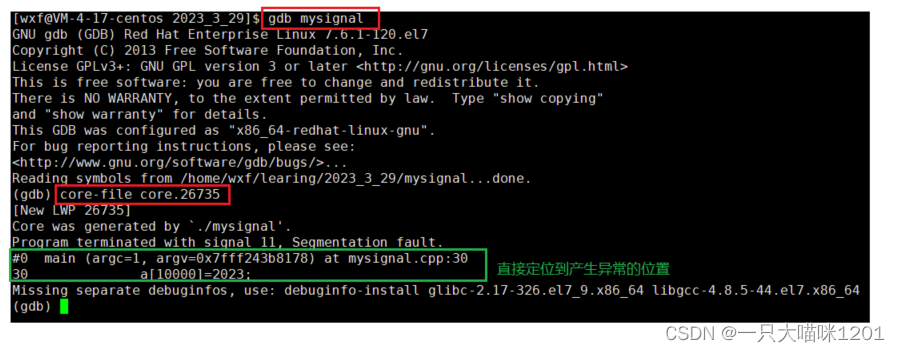
- 使用gdb调试我们的可执行程序。
- 调试开始后,输入core-file core.pid值,表明调试核心转储文件。
- 此时gdb就会直接定位到产生异常的位置。
这就是核心转储的重要意义,它相比Term方式,能够让我们快速定位出现异常的位置。
篇幅有限,下篇文章再接着介绍。






![[API]string常量池string常用方法StringBuilder类(一)](https://img-blog.csdnimg.cn/5c0ed022bd2f46958f266ff07387fd6e.png)