文章目录
- 01:ODS层构建:代码结构及修改
- 02:ODS层构建:连接代码及测试
- 03:ODS层构建:建库代码及测试
- 04:ODS层构建:建表代码及测试
01:ODS层构建:代码结构及修改
-
目标:了解整个自动化代码的项目结构及实现配置修改
-
路径
- step1:工程代码结构
- step2:代码模块功能
- step3:代码配置修改
-
实施
-
工程代码结构

-
-
代码模块功能
-
auto_create_hive_table:用于实现ODS层与DWD层的建库建表的代码cn.itcast
-
-
datatohive- CHiveTableFromOracleTable.py:用于创建Hive数据库、以及获取Oracle表的信息创建Hive表等
- CreateMetaCommon.py:定义了建表时固定的一些字符串数据,数据库名称、分层名称、文件类型属性等
- CreateHiveTablePartition.py:用于手动申明ODS层表的分区元数据
- LoadData2DWD.py:用于实现将ODS层的数据insert到DWD层表中
-fileformat
- AvroTableProperties.py:Avro文件格式对象,用于封装Avro建表时的字符串
- OrcTableProperties.py:Orc文件格式对象,用于封装Orc建表时的字符串
- OrcSnappyTableProperties.py:Orc文件格式加Snappy压缩的对象
- TableProperties.py:用于获取表的属性的类
- CHiveTableFromOracleTable.py:用于创建Hive数据库、以及获取Oracle表的信息创建Hive表等
-
entity- TableMeta.py:Oracle表的信息对象:用于将表的名称、列的信息、表的注释进行封装
-
ColumnMeta.py:Oracle列的信息对象:用于将列的名称、类型、注释进行封装
-
utils- OracleHiveUtil.py:用于获取Oracle连接、Hive连接-
FileUtil.py:用于读写文件,获取所有Oracle表的名称
- TableNameUtil.py:用于将全量表和增量表的名称放入不同的列表中
-
-
ConfigLoader.py:用于加载配置文件,获取配置文件信息
-
OracleMetaUtil.py:用于获取Oracle中表的信息:表名、字段名、类型、注释等
-
EntranceApp.py:程序运行入口,核心调度运行的程序
# todo:1-获取Oracle、Hive连接,获取所有表名 # todo:2-创建ODS层数据库 # todo:3-创建ODS层数据表 # todo:4-手动申明ODS层分区数据 # todo:5-创建DWD层数据库以及数据表 # todo:6-加载ODS层数据到DWD层
-
todo:7-关闭连接,释放资源
-
resource-
config.txt:Oracle、Hive、SparkSQL的地址、端口、用户名、密码配置文件
-
config- common.py:用于获取日志的类
-
settings.py:用于配置日志记录方式的类
-
-
log-
itcast.log:日志文件
-
dw:用于存储每一层构建的核心配置文件等- 重点关注:dw.ods.meta_data.tablenames.txt:存储了整个ODS层的表的名称
-
-
代码配置修改
- 修改1:auto_create_hive_table.cn.itcast.EntranceApp.py
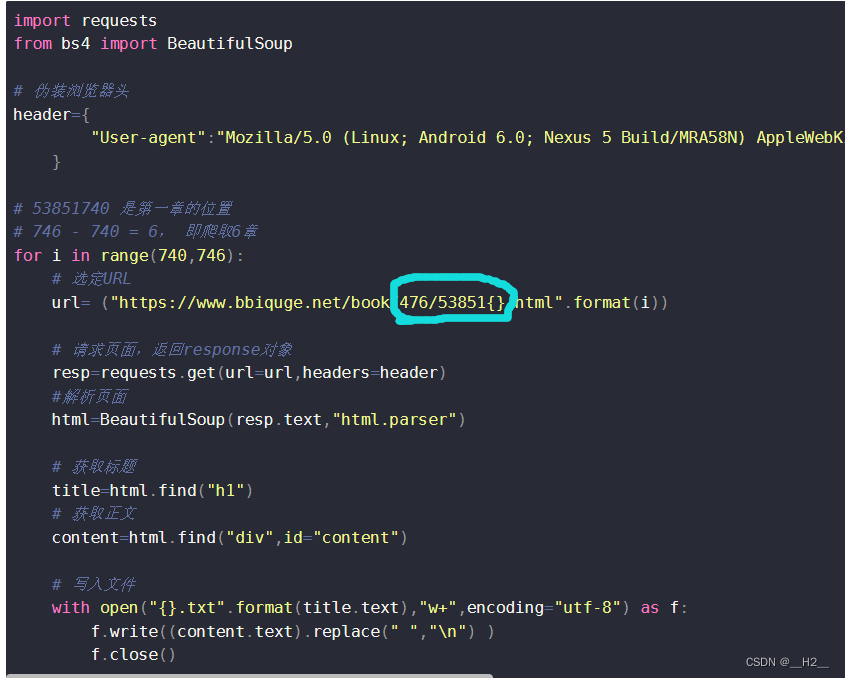
# 51行:修改为你实际的项目路径对应的表名文件 tableList = FileUtil.readFileContent("D:\\PythonProject\\OneMake_Spark\\dw\\ods\\meta_data\\tablenames.txt")- 修改2:auto_create_hive_table.cn.itcast.utils.ConfigLoader
# 10行:修改为实际的连接属性配置文件的地址 config.read('D:\\PythonProject\\OneMake_Spark\\auto_create_hive_table\\resources\\config.txt') -
小结
- 了解整个自动化代码的项目结构及实现配置修改
02:ODS层构建:连接代码及测试
-
目标:阅读连接代码及实现连接代码测试
-
路径
- step1:连接代码讲解
- step2:连接代码测试
-
实施
-
为什么要获取连接?
- Python连接Oracle:获取表的元数据
- 表的信息:TableMeta
- 表名
- 表的注释
- list:[列的信息]
- 列的信息:ColumnMeta
- 列名
- 列的注释
- 列的类型
- 类型长度
- 类型精度
-
Python连接HiveServer或者Spark的ThriftServer:提交SQL语句
-
连接代码讲解
-
step1:怎么获取连接?
-
Oracle:安装Python操作Oracle库包:cx_Oracle
cx_Oracle.connect(ORACLE_USER, ORACLE_PASSWORD, dsn) -
Hive/SparkSQL:安装Python操作Hive库包:PyHive
``` hive.Connection(host=SPARK_HIVE_HOST, port=SPARK_HIVE_PORT, username=SPARK_HIVE_UNAME, auth='CUSTOM', password=SPARK_HIVE_PASSWORD) ```-
step2:连接时需要哪些参数?
- Oracle:主机名、端口、用户名、密码、SID
- Hive:主机名、端口、用户名、密码
-
step3:如果有100个代码都需要构建Hive连接,怎么解决呢?
- 将所有连接参数写入一个配置文件:resource/config.txt
- 通过配置文件的工具类获取配置:ConfigLoader
-
step4:在ODS层建101张表,表名怎么动态获取呢?
- 读取表名文件:将每张表的名称都存储在一个列表中
-
step5:ODS层的表分为全量表与增量表,怎么区分呢?
- 通过对@符号的分割,将全量表和增量表的表名存储在不同的列表中
-
-
-
-
连接代码测试
-
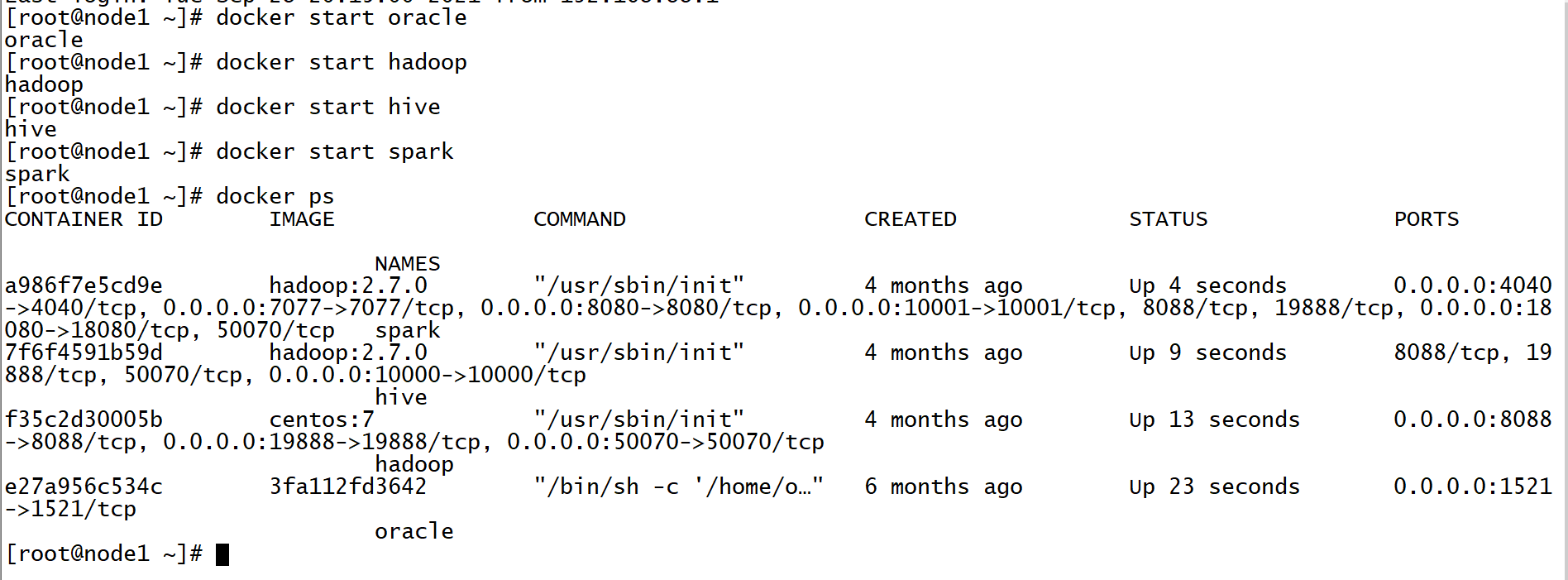
启动虚拟运行环境
-
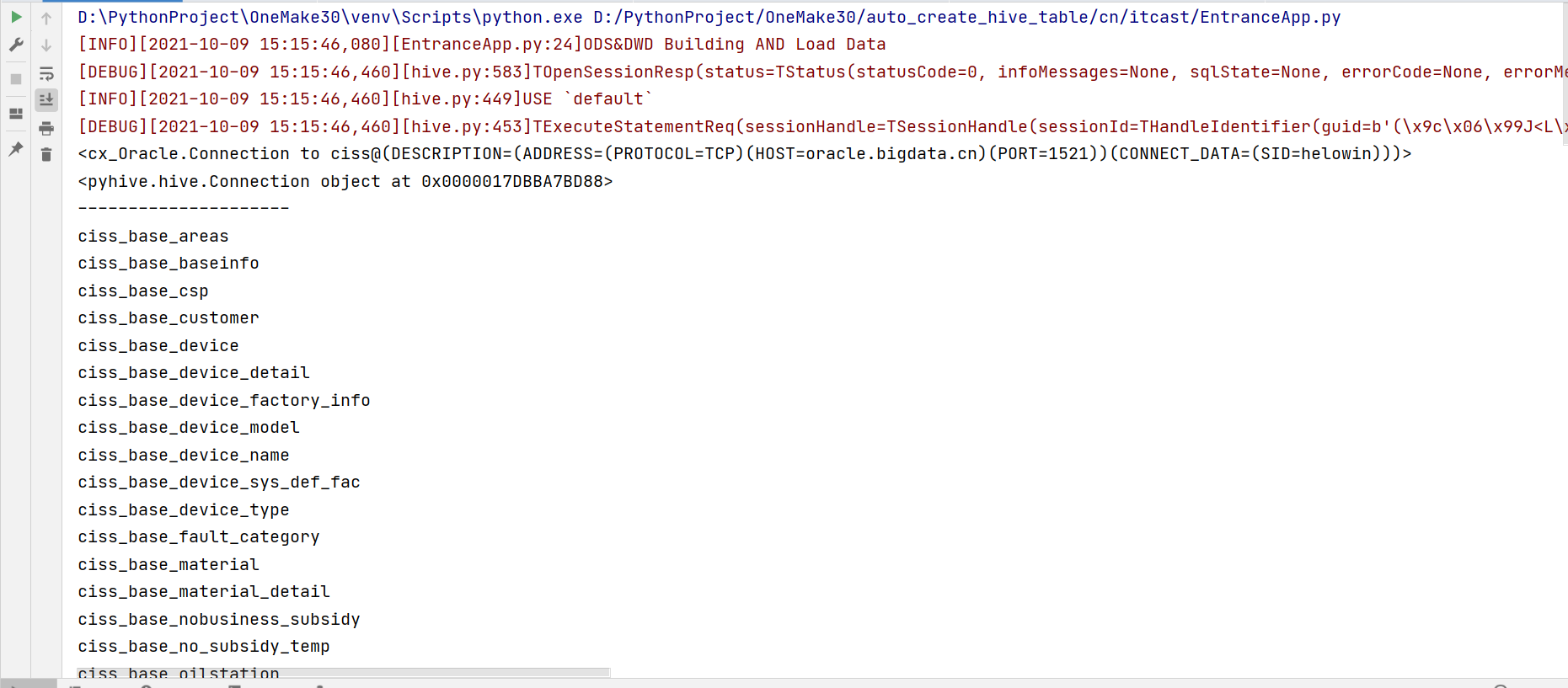
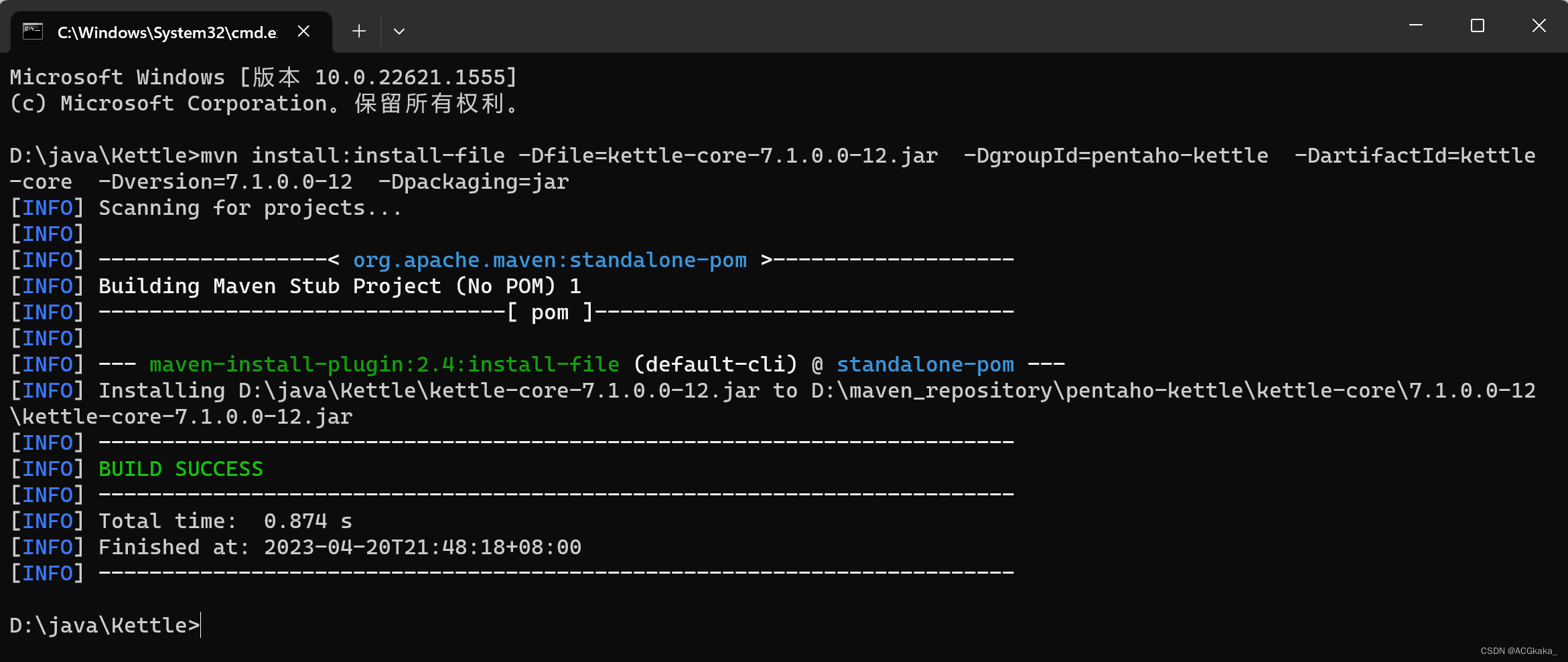
运行测试代码
- 注释掉第2 ~ 第6阶段的内容
- 取消测试代码的注释
- 执行代码观察结果
-
-
-
小结
- 阅读连接代码及实现连接代码测试
03:ODS层构建:建库代码及测试
-
目标:阅读ODS建库代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
-
step1:ODS层的数据库名称叫什么?
one_make_ods -
step2:如何使用PyHive创建数据库?
- 第一步:先获取连接
- 第二步:拼接SQL语句,从连接对象中获取一个游标
- 第三步:使用游标执行SQL语句
- 第四步:释放资源
-
-
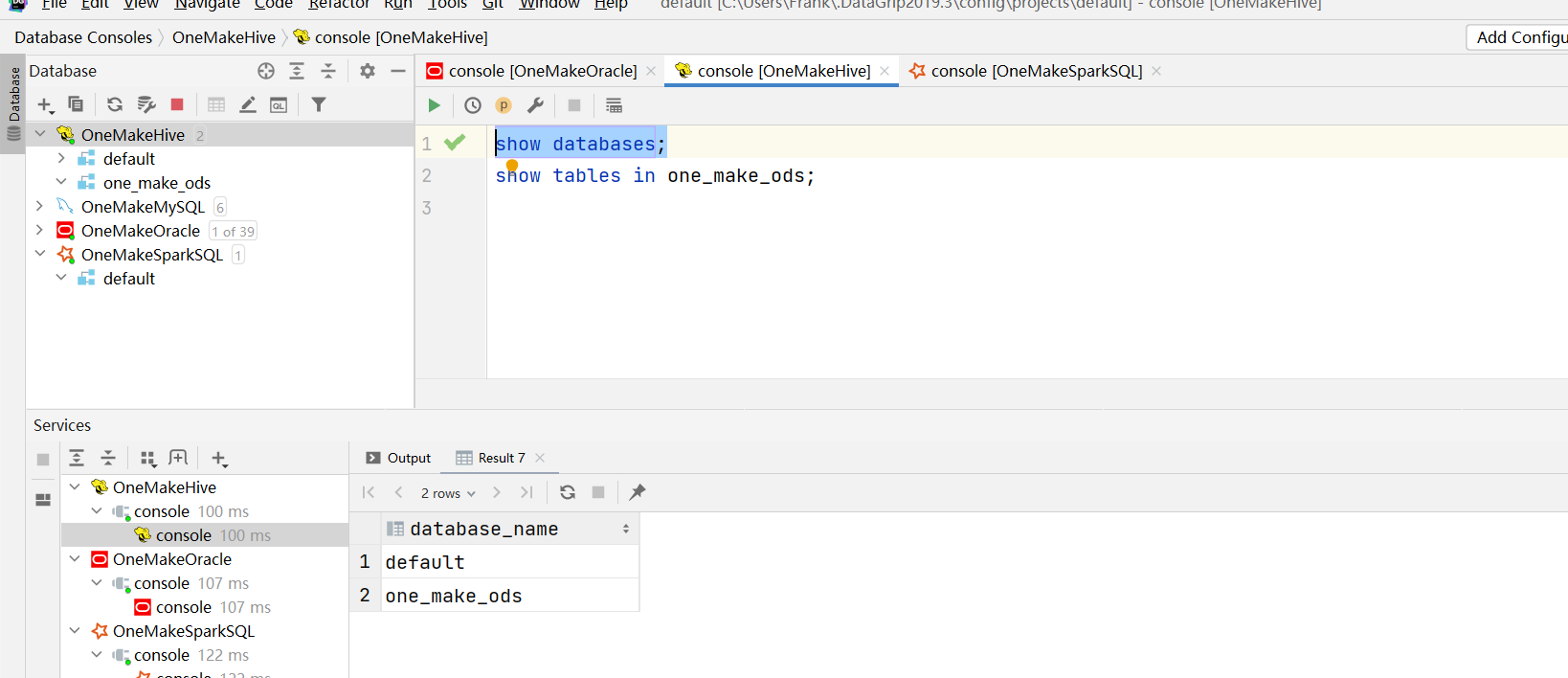
代码测试
- 注释掉第3 ~ 第6阶段的内容
- 运行代码,查看结果
-
-
小结
- 阅读ODS建库代码及实现测试
04:ODS层构建:建表代码及测试
-
目标:阅读ODS建表代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
-
step1:表名怎么获取?
tableNameList【full_list,incr_list】 full_list:全量表名的列表 incr_list:增量表名的列表 -
step2:建表的语句是什么,哪些是动态变化的?
create external table 数据库名称.表名 comment '表的注释' partitioned by ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '这张表在HDFS上的路径' TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')-
表名
-
表的注释
-
表的HDFS地址
-
Schema文件的HDFS地址
-
-
step3:怎么获取表的注释?
-
从Oracle中获取:从系统表中获取某张表的信息和列的信息
select columnName, dataType, dataScale, dataPercision, columnComment, tableComment from ( select column_name columnName, data_type dataType, DATA_SCALE dataScale, DATA_PRECISION dataPercision, TABLE_NAME from all_tab_cols where 'CISS_CSP_WORKORDER' = table_name) t1 left join ( select comments tableComment,TABLE_NAME from all_tab_comments WHERE 'CISS_CSP_WORKORDER' = TABLE_NAME) t2 on t1.TABLE_NAME = t2.TABLE_NAME left join ( select comments columnComment, COLUMN_NAME from all_col_comments WHERE TABLE_NAME='CISS_CSP_WORKORDER') t3 on t1.columnName = t3.COLUMN_NAME;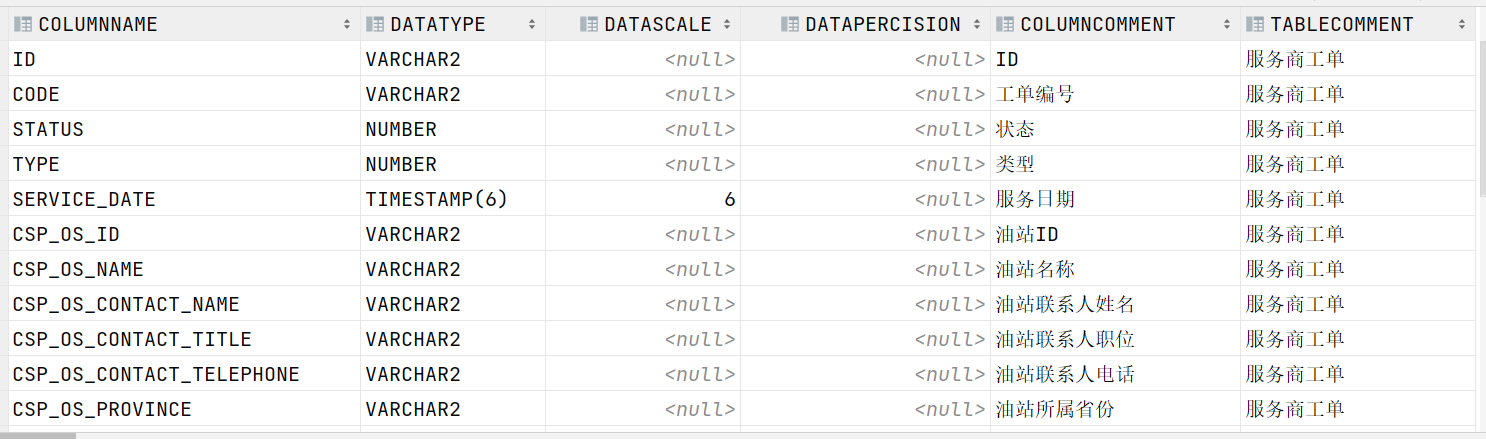
-
-
step4:全量表与增量表有什么区别?
- 区别1:表名不一样
- full_table_list
- incr_table_list
- 区别2:路径不一样
/data /dw /ods /one_make /full /Oracle库名.表名/data /dw /ods /one_make /incr /Oracle库名.表名
- 区别1:表名不一样
-
step5:如何实现自动化建表?
- 自动化创建全量表
- 获取全量表名
- 调用建表方法:数据库名称、表名、全量标记
- 通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
- 拼接建表语句
- 执行SQL语句
- 自动化创建增量表
- 获取增量表名
- 调用建表方法:数据库名称、表名、增量标记
- 通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
- 拼接建表语句
- 执行SQL语句
- 自动化创建全量表
-
-
代码测试
- 注释掉第4~ 第6阶段的内容
- 运行代码,查看结果
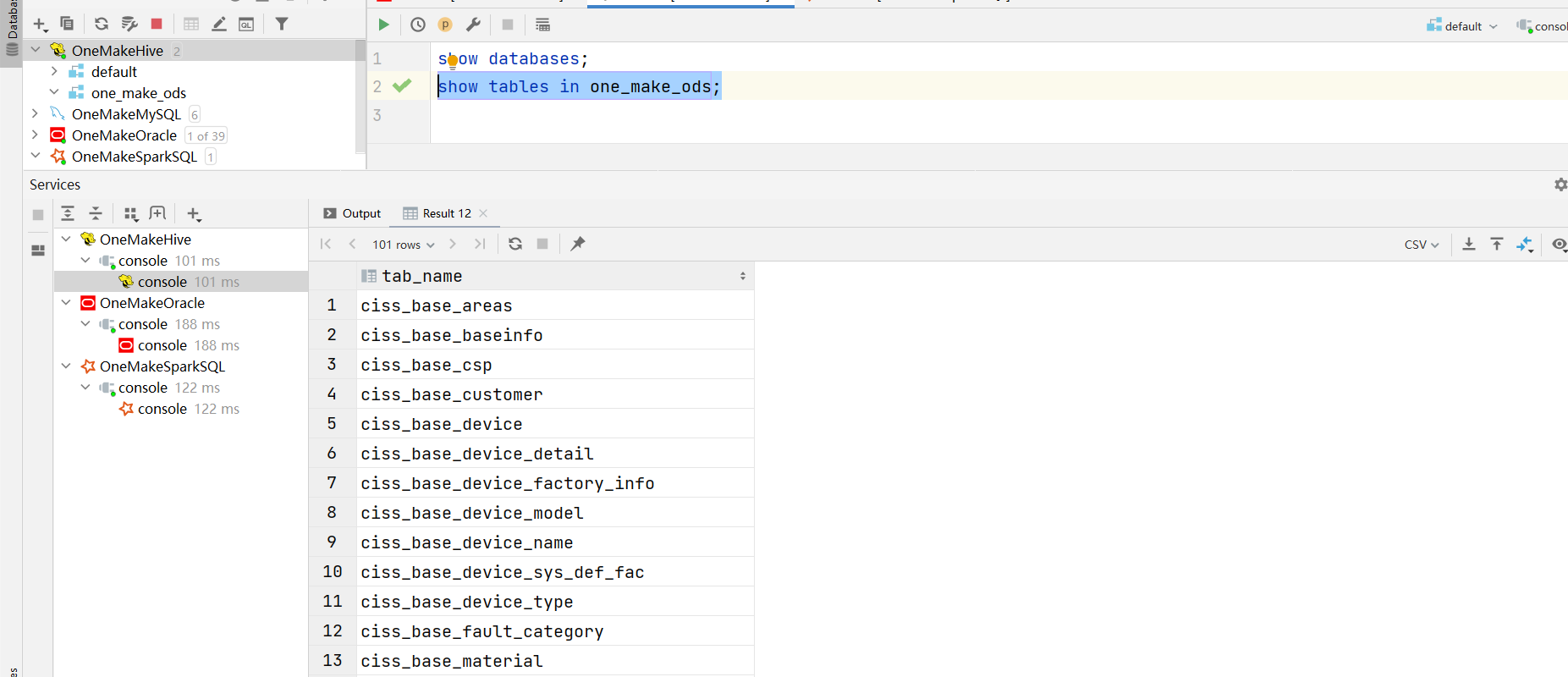
-
-
小结
- 阅读ODS建表代码及实现测试



![[API]string常量池string常用方法StringBuilder类(一)](https://img-blog.csdnimg.cn/5c0ed022bd2f46958f266ff07387fd6e.png)