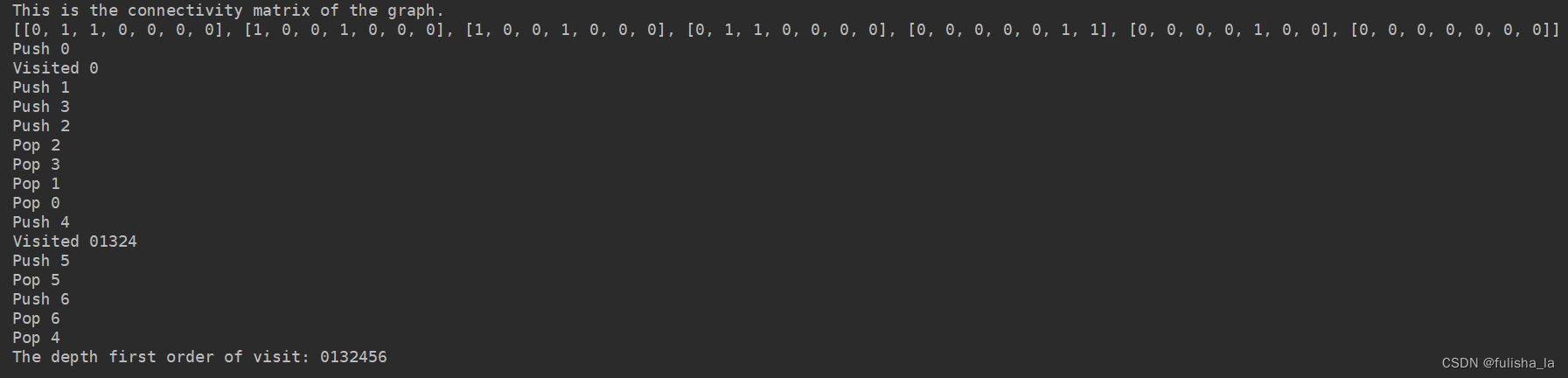
一、什么是web自动化测试?
Web自动化测试是指使用自动化工具模拟用户在Web浏览器中执行的操作,通过编写脚本来自动化执行测试用例,以验证Web应用程序的功能、性能和兼容性等方面的质量。其主要目的是降低测试成本和时间,并提高测试效率和准确性。
Web自动化测试通常包括以下步骤:
-
确定测试目标:明确需要测试的Web应用程序的功能、性能、兼容性等方面的需求。
-
选择自动化测试工具:从众多可用的自动化测试工具中选择适合自己的工具,如Selenium、Appium、TestComplete等。
-
编写测试脚本:根据测试目标编写测试脚本,实现自动登录、点击按钮、输入数据、验证结果等操作。
-
执行测试脚本:运行测试脚本并生成测试报告,检查测试结果是否符合预期结果。
-
分析测试结果:对测试结果进行分析,确定哪些问题需要修复,哪些测试需要迭代。
Web自动化测试相比手动测试,可以节省测试人员大量的时间和精力,提高测试覆盖率和质量。但同时也需要注意一些限制和注意事项,如测试环境的搭建、测试脚本的维护和更新、测试用例的设计和管理等方面。如果想领取笔记,面试题,简历模板等测试相关的资料可以加wx:mashang-nn(备注CSDN555)
在华为工作了10年的大佬出的Web自动化测试教程,华为现用技术教程!_哔哩哔哩_bilibili在华为工作了10年的大佬出的Web自动化测试教程,华为现用技术教程!共计16条视频,包括:1. 【web自动化】主流Web自动化测试技术对比、2. 【web自动化】Selenium自动化测试环境一键搭建、3. 【web自动化】Selenium八大定位策略详解等,UP主更多精彩视频,请关注UP账号。 https://www.bilibili.com/video/BV1sM4y1d7tq/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1sM4y1d7tq/?spm_id_from=333.337.search-card.all.click
二、web自动化测试流程实施过程:
Web自动化测试流程的实施过程一般包括以下步骤:
-
需求分析和测试计划制定:明确需要测试的Web应用程序的功能、性能、兼容性等方面的需求,并根据需求制定相应的测试计划。
-
环境搭建:搭建测试环境,包括安装浏览器驱动程序、自动化测试工具、测试框架以及所需的其他软件和硬件设备。
-
测试案例设计:根据测试计划,设计测试用例,编写测试脚本并进行测试数据准备。
-
测试执行:运行测试脚本,执行测试用例,并记录测试结果。
-
缺陷分析和报告:对测试结果进行分析和评估,对发现的问题进行缺陷报告,并与开发人员协商解决方案。
-
重新测试和确认:经过修复后的缺陷,进行重新测试和确认,验证问题是否已经得到解决。
-
性能测试和兼容性测试:针对Web应用程序的性能和兼容性进行测试。
-
测试总结和优化:根据测试结果进行总结和优化,不断改进测试流程和方法,提高测试效率和质量。
以上是Web自动化测试流程的基本实施过程,但具体实施步骤可能因应用程序的不同而有所区别。
三、Python+Selenium环境搭建
python+selenium自动化测试环境包括四个部分:python、selenium、chrome谷歌浏览器、chrome谷歌浏览器驱动。其中浏览器也可以是火狐,IE等。目前自动化的主流浏览器还是chrome谷歌浏览器
(1)python的安装
目前测试行业应用最广的编程语言当属Python为首。python现在主流是3.7的版本。安装很简单,在官网(官网地址:Welcome to Python.org)选择对应系统的版本直接下载,然后双击安装即可,安装路径可自定义,不是一定非要安装在C盘,但请尽可能避免中文路径。
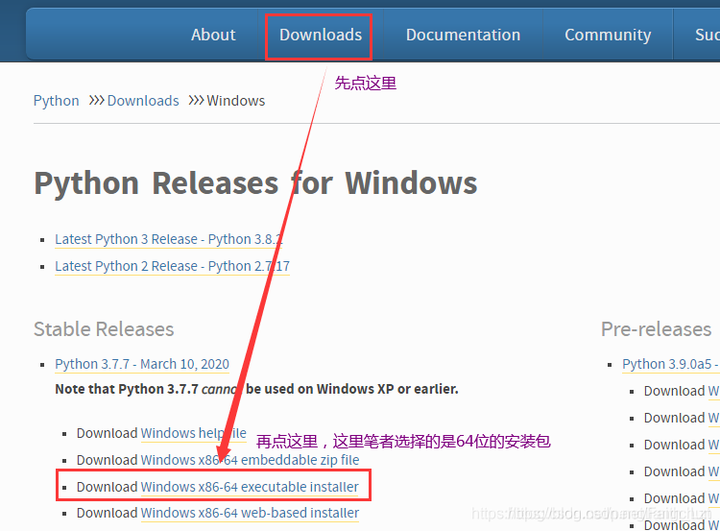
python安装包后,需要配置环境变量,其实在3.7的安装过程中,第一个界面有一个“add python to path”的选项可以勾选(大概是这个名字)。勾选之后会自动将python添加到系统环境变量Path中。当然你也可以选择手动添加,添加方法如下:
我的电脑右键选择属性–>高级系统设置–>环境变量–>环境变量–>系统变量:找到path变量并修改,在Path路径的最前面加入:C:\Python37;C:\Python37\Scripts; (如果你的python安装在其他路径请做相应的改动,笔者这里是默认路径)
特别要注意:很多新手会把Path中原来的内容删除掉,笔者提醒一下这个绝对不能这样做,慎重!慎重!慎重!
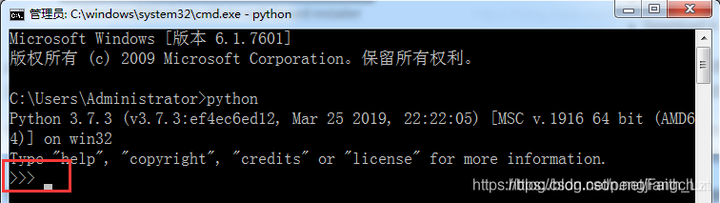
安装之后,运行CMD窗口,输入python指令,用于校验python是否安装成功。如下图表示成功!
另附上python开发工具PyCharm的官方下载地址:Download PyCharm: Python IDE for Professional Developers by JetBrains
(2)selenium的安装
selenium可以通过pip命令进行安装,安装方法如下:
打开cmd窗口
输入:pip install selenium
等待cmd窗口提示successful,则selenium安装成功,如中途中断了继续输入pip install selenium重新安装,不影响!
(3)chrome浏览器
目前网上谷歌浏览器下载的坑太多了,很多网站做得跟官网太像了。一不小心就会入坑,这里笔者提供Chrome官网的下载地址:
Chrome官网:Google Chrome 网络浏览器
下载完成后双击会自动安装。等待安装完成即可。
(4)安装chrome浏览器驱动
当Selenium提出了WebDriver的概念之后,它提供了利用浏览器原生的接口,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件)。
由于使用的是浏览器原生的接口,速度大大提高,而且调用的稳定性交给了浏览器厂商本身,显然是更加科学。然而带来的一些副作用就是,不同的浏览器厂商,对Web元素的操作和呈现多少会有一些差异,这就直接导致了Selenium WebDriver要分浏览器厂商不同,而提供不同的实现。例如Firefox就有专门的geckoDriver驱动,Chrome就有专门的Chrome驱动等。
这里特别要注意:
chrome浏览器驱动必须和安装的chrome浏览器版本对应。那么如何保证对应呢?
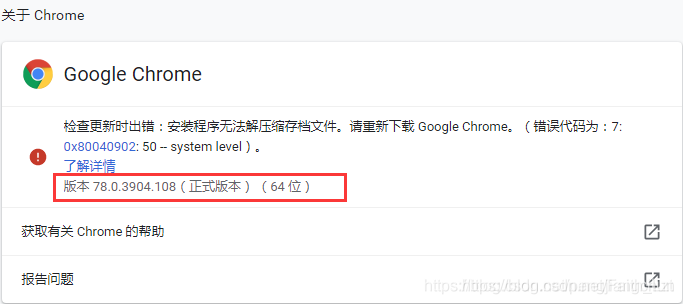
先检查chrome浏览器的版本:点击chrome浏览器右上角的三个点–>帮助–>关于Google Chrome,如下图所示:
2.chrome浏览器驱动下载地址:
Chromedriver驱动下载地址:CNPM Binaries Mirror
找到和上图chrome版本最接近的版本:上图为:78.0.3904.108,所以这里驱动选择:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
下载完成后:把chrome驱动包放入:C:\python37 目录下 (这个是必须的)
四、八大元素定位
Web自动化测试八大元素定位是指在Web页面中对需要进行操作的元素进行精确定位,以便实现自动化操作。这八大元素定位包括:
-
元素ID:每个HTML标签都可以设置id属性,使用该属性可方便地定位元素。
-
元素name:通过元素名称定位元素,一般用于表单元素。
-
元素class name:使用CSS样式类名称定位元素。
-
元素tag name:通过标签名称定位元素,适用于找到多个相同的元素。
-
链接文本:通过链接文本定位链接元素。
-
CSS选择器:通过CSS样式规则定位元素。
-
XPath:使用XPath语法定位元素。
-
DOM结构:使用元素的DOM层次结构定位元素。
以上八种方式可以组合使用,以获得更精确的元素定位。定位元素的准确性和稳定性对于Web自动化测试的成功非常重要,因此需要根据具体需求选择最佳定位方式。
五、项目实战
unittest管理测试用例的规则:
1.必须继承:unittest.TestCase
2.导包:import unittest
3.写一个以test_开头的测试用例。
为啥有没有main都没关系,都可以执行。原因是:unittest有两种运行方式,并且默认的还
是第一种运行方式: (巨坑)
1.命令行的运行方式(默认)
python -m unittest 模块名.py
python -m unittest 模块名.类名.方法名
2.main主函数运行方式(非默认)
main方式。
frameset(框架集,直接忽略)
frame(框架)/iframe(子框架)
导包的快捷键:Alt+Enter
定位一组元素:
windows自带的弹窗:
alert 只有一个确定按钮
confirm 有一个确定和一个取消按钮
prompt 除了确定和取消按钮外还有一个输入框。
都是:driver.switch_to.alert
六、设计模式
在Web自动化测试中,封装是一种非常重要的设计模式。通过封装,我们可以将操作页面元素的方法进行统一管理,减少代码冗余,提高可维护性和可读性。
具体来说,Web自动化测试中可以采用如下几种封装方式:
-
页面对象模型(Page Object Model):将每个页面封装成一个对象,对象中包含页面中所有需要操作的元素和操作方法。这种方式可以将测试脚本与页面的实现细节分离开来,提高了测试代码的可读性和可维护性。
-
模块化设计:将项目中的功能模块进行分解,每个模块都有独立的测试用例和测试脚本。这种方式可以减少代码耦合度、提高测试效率和可扩展性。
-
数据驱动设计:将测试数据和测试脚本进行分离,并将测试数据放在外部文件或数据库中。这种方式可以提高测试数据的复用性、减少测试脚本的冗余代码。
-
关键字驱动设计:将测试步骤封装成关键字,以关键字为单位编写测试脚本。这种方式可以提高测试脚本的可读性和可维护性。
以上几种封装方式都可以提高Web自动化测试的效率和可靠性,同时也可以减少测试代码的冗余和维护成本。具体采用哪种方式,需要根据项目需求、团队规模和技术水平来选择。
七、引入Pytest(解耦合)
默认的测试用例的运行规则:
1.测试模块必须以test_开头或者_test结尾。
2.测试类必须以Test
pip install pytest
pip install allure-pytest3.测试用例必须以test_开头
pytest的运行的方式有三种
1.命令行
2.main方法
3.通过pytest.ini文件来运行。
pip install pytest
pip install allure-pytest随意的切换。unitest/pytest都必须要灵活的掌握
pip install pytest
pip install allure-pytest并且灵活的应用。
八、pytest结合allure-pytest插件生成漂亮的测试报告
pytest是一个非常流行的Python测试框架,可以方便地编写和运行各种类型的自动化测试。而allure-pytest插件则是为pytest提供测试报告生成功能的插件,可以生成漂亮、可视化的测试报告,帮助我们更好地了解测试结果。
下面是使用pytest和allure-pytest插件生成测试报告的步骤:
1、安装pytest和allure-pytest插件
pip install pytest
pip install allure-pytest2、编写测试用例 编写pytest测试用例文件,并使用pytest标准的断言函数进行断言。
3、运行测试 在终端中进入测试脚本所在目录,执行以下命令:
pytest --alluredir ./result
这个命令会在当前目录下创建一个名为result的文件夹,并把测试结果保存到该文件夹中。
4、生成测试报告 在终端中输入以下命令:
allure generate ./result -o ./report --clean这个命令会根据result文件夹中的测试结果生成一个名为report的文件夹,其中包含了测试报告的所有文件。
5、查看测试报告 在浏览器中打开report文件夹中的index.html文件,即可查看生成的测试报告。
通过以上步骤,我们就可以使用pytest和allure-pytest插件生成漂亮的测试报告了。同时,allure-pytest还提供了丰富的功能,如历史结果展示、图表分析等,可以帮助我们更好地了解自动化测试执行情况。
九、实现企业级的能够落地实施的web自动化框架以及实现报告的定制
报告的定制:logo的定制,模块的定制,用例的定制,严重程度,错误截图,用例描述, 参数化。日志监控。
编程语言:python,java
设计模块:PO,关键字驱动
用例管理:精通unitetst,pytest
数据驱动:ddt,pytest.mark。parametrize
二次封装:excel,yaml,ini,数据库封装
日志监控:logging
异常处理:try/except
jenkins:持续集成和无人值守
分布式运行:Grid
前端:html和js
十、Pytest的数据驱动@pytest.mark.parametrize()+Excel实现数据 驱动
方法详情:
@pytest.mark.parametrize(args_name,args_value)
args_name:参数名
args_value:参数值(list列表,tuple元祖,字典列表,字典元祖)
举例:
@pytest.mark.parametrize("caseinto",["百里","依然","星瑶"])
def test_01(self,caseinto):
print(caseinto)举例:
@pytest.mark.parametrize("name,age",[["百里","12"],["依然","14"]])
def test_01(self,name,age):
print(name,age)