1 hive的优缺点
优点
- SQL
- 减少MR的开发难度
- 使用于实时性不高的数据分析场合
- 优势处理大数据
- 自定义函数
缺点
-
Hql表达能力优先:迭代式算法?
-
处理延迟效率较低,小数据的时候,不如传统数据库
2 对hive的了解
优点+本质:基于hadoop将HQL转换成MR的工具
3. hive架构
- 用户接口
- 元数据:表,数据库,字段,表类型,表目录
- hadoop:hdfs和driver
- 驱动器:解析器、编译器、优化器、执行器
4. 外部表和内部表区别(高频)
- 外部表被external修饰
- 存储管理:外部表hdfs,内部表hive
- 存储位置:外部表存储可以自己定义,并且可以和其他外部表共享数据
- 创建表:内部表会将数据移动到所指定的路径,外部表仅仅记录了数据所在路径
- 删除表:外部表删除元数据,存储数据不会被删除,内部表都会一起删掉,外部表安全
- 修改表:外部表对分区和表结构进行修改,需要修复MSCK REPAIR TABLE table_name;外部表会直接更改元数据

5. hive建表语句
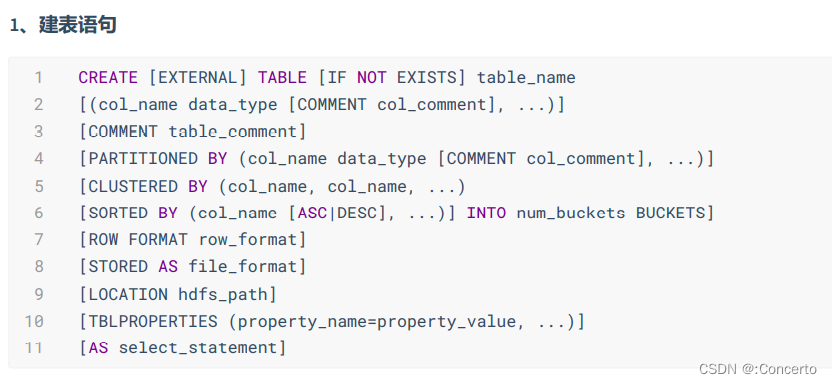
- create
- external
- comment
- partition by分区
- clustered by分桶表
- row format delimited
- fields terminated by
- lines terminated by如果没指定会使用SerDe(序列化和反序列化)
- 分隔符如果特殊可以用multidelimitserde
- stored as
- location
6. hive数据倾斜/优化[待完善]
-
含义:key值的数据过多导致的某几个reduce的节点 运行比较慢
-
关键词:join、空值、group by维度过小,count distinct特殊值较多
-
聚合倾斜group by解决
- 参数调节set hive.map.aggr=true代表开启map端预聚合
- set hive.groupby.skewindata=true;均衡数据倾斜的配置项
- 具体:两个MR的job,第一个MR的map的输出结果会随机给到reducer,随机表示可以一定程度达到负载均衡的目的。第二个MR会再去根据预处理结果把相同的key值放到同一个reduce中
-
join倾斜解决
- join的时候选择join key分布最均衡的表作为驱动表
- 大小表join让小的表加载到内存中在map段进行join,避免reducer处理,提高效率
- 大表和大表join:null值不参与运算或者给key值中null值后面加上随机值,不会影响结果
- 多表join:在原理中也有,可以使用同一列为join条件仅仅会 生成一个MRjob
-
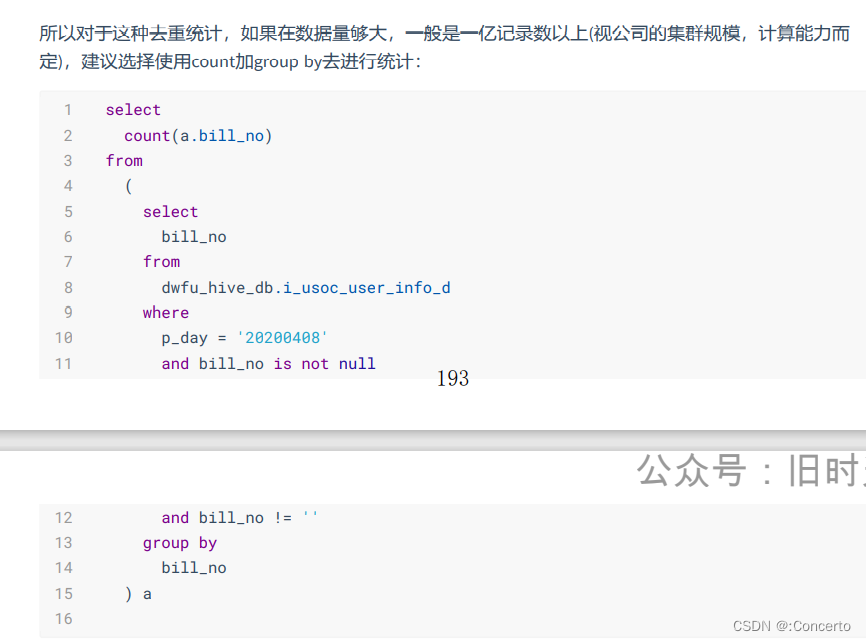
count distinct优化
- 使用使用count…group by代替count(distinct)。如:即group by在子查询中,再count字段
-
map阶段优化:可以通过调整map和reduce的个数来进行优化,分别是map.tasks和reducer.tasks,
-
map的个数取决于input的文件数和大小,文件无论大小都会当成一个map任务执行,因此可以在map执行前合并小文件,根据实际环境减少map个数。辩证分析也不是全部是减少,如果一个文件127M但是字段很少,数据很多,需要增大map的个数了
-
因为有多少reduce就会有多少输出的文件,如果作为下一个的输入文件,也会产生产生小文件,一般调整有几个考虑,根据map的输出估算reduce的个数和实际环境
-
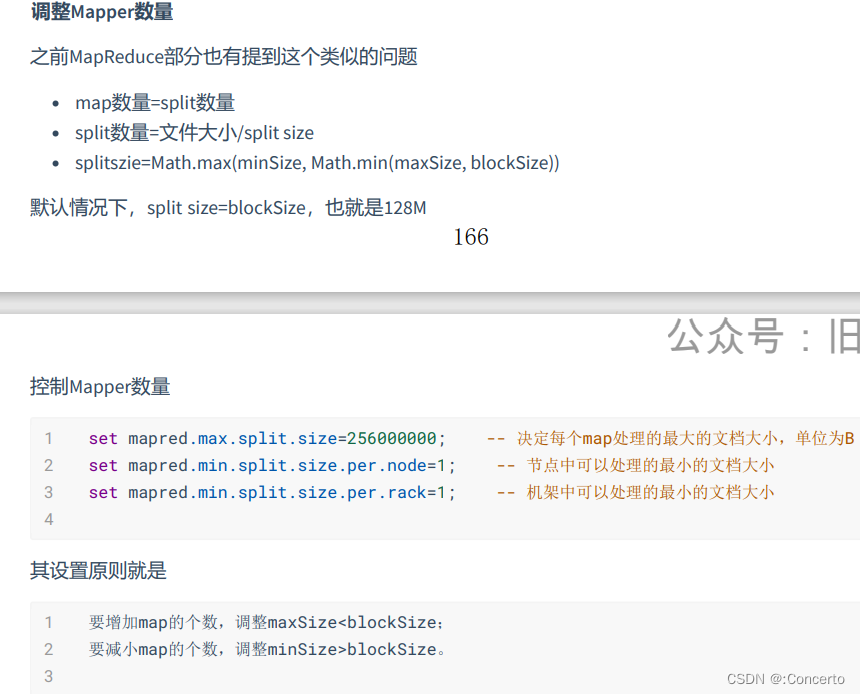
map数量的参数
-
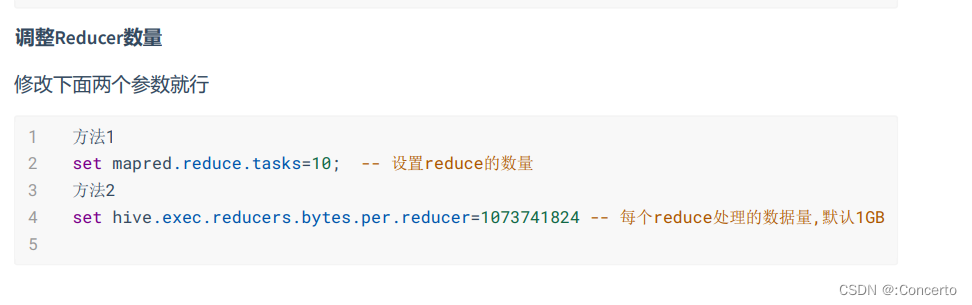
reducer数量的参数
-
-
hive输出小文件参数调整

-
行列/分区过滤
- select的时候只拿所需的列
- 只读所需要的分区,有两个参数,都是默认true
- 谓词下推,将where写在子查询中,有参数可以调整,尽量将过滤条件提前执行,使得最后参与join的表的数据量更小
- 少用join,可以转换成case
-
sort by代替order by
- sort by是保证多个reduce进行排序,并且保证每个reduce有序,可以再加distribute by排序,不加就随机分配
-
插入数据的时候少用动态分区,可以采用distributed by rand(),可以使得后续处理reduce的数据大致相同

- 压缩优化:
- 设置中间结果压缩,减少数据倾斜以及减少io流和网络传输
- 使用sequencefile作为表存储,可以减少小文件,二进制kv存储,可以合并。或者是常用testfile以及parquent
- jvm重用:调节参数增加一个JVM可以执行多个MR job
- 压箱方法:把倾斜值值拿出来后打上随机值后处理在union回去
7. hive自定义函数
- 继承UDF类,或者UDAF和UDTF
- 写代码后打包成jar包并注册该jar文件
- 为这个类起别名create temporary function as ‘xx’
- 使用select进行使用
8. hive中有哪些UDF
- UDF:一进一出,upper
- UDAF:聚合函数,多进一出,sum/min
- UDTF:表函数,一进多出,explore,split
9. cluster by,sort by,distributor by,order by区别
- order by:全局排序,在只有一个reduder的时候使用,数据量大需要时间多
- sort by:非全局排序,在数据进入reduce前排序,只能保证每个reduce输出有序
- distributor by:分区排序,按照分区字段进行排序
- cluster by:distribute by Word sort by Word ASC只能升序
10. 分区和分桶的区别
- 定义上:
- 分区相当于在hdfs的子目录中包含了分区对应的名字,子分区就是子目录
- 分桶在分区表上是根据hash算法进行组织,每个桶有数据,但是数量不一定一致
- 关系:cluster by:distribute by Word sort by Word ASC只能升序,分区容易数据倾斜,分桶比较平均
- 关系:外部表和内部表,分区表都是对HDFS上的目录,桶表对应是目录中的文件
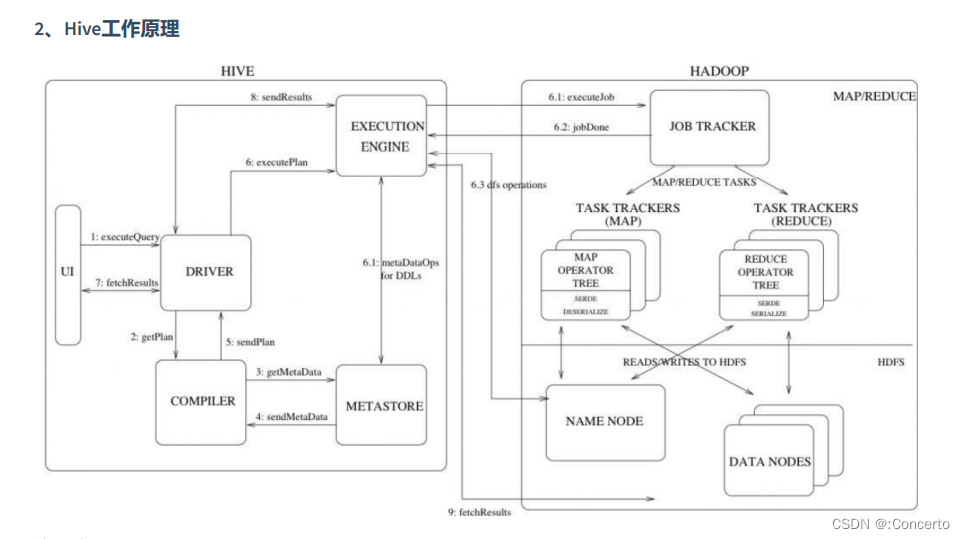
11. hive的查询执行流程
-
用户提交任务给到driver
-
编译器获取任务后去metastore获取hive的元数据,编译过程:
- hivesql转换为抽象语法树
- 遍历抽象语法树,抽象出查询的基本单元queryblock
- 遍历查询块,翻译为执行操作树operatortree
-
优化器:
-
逻辑优化器进行操作数变换,合并不需要的reducesinkoperator,减少shuffle
-
遍历operatortree翻译成MR生成最终执行计划
-
-
最终将计划给回到driver后转交ExcutorEngine去执行,获取元数据,然后交给hadoop那边的jobtracker执行,会直接读取hdfs上的文件进行操作
12. hive创建表流程
- 获取到hive语句的信息,包括表,字段,分区等,先写到元数据中,主要是通过sequence_table中构建对象的ID,然后同步到系统表?
- 执行顺序

13. hivesql的实现原理
-
join
-
基本原理
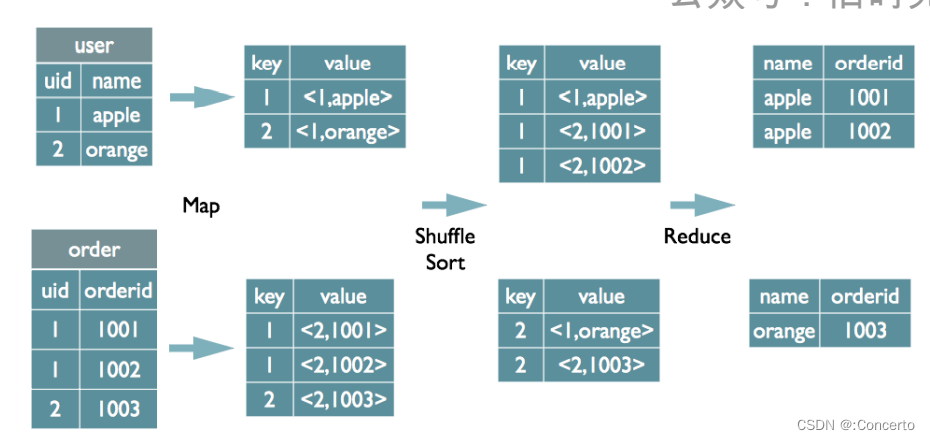
-
多表join:如果多表使用同一列进行关联将会被翻译成一个reduce,否则将会被翻译成多个reduce任务,原因是因为多表基于不同的列做join,无法在一轮MR任务中将数据shuffle到reducer中,多表的时候会将中间表缓存在reducer的内存中,然后后面的表会流式的进入进行接下来的任务
-
join的分类:分为map join和common join,如果参数设置的是hive.auto.convert.join = true,那么小表和大表join就会转化成mapjoin,reducer不做join处理。common join就是一般认为的common join了
-
-
group by
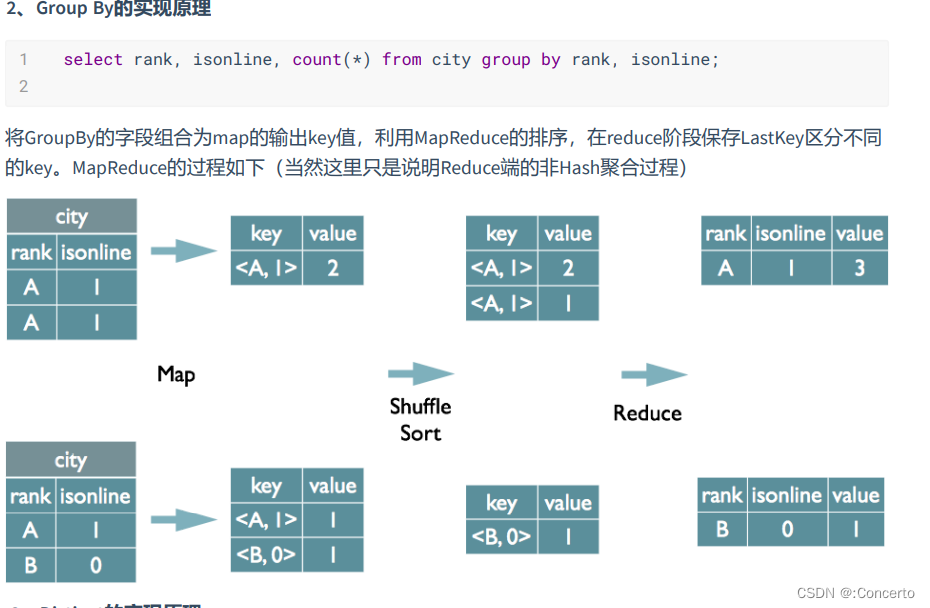
- distinct

- distinct+count

14. hive的计算引擎?
- MR引擎
- Tez
- 特点是将原有的map和reduce简化为一个概念:vertex,计算节点被拆分成vertex input,vertex output,sorting,merging,这些元素可以任意组装形成一个大的DAG作业,由map和reduce变成map-reduce-reduce,似流水线,减少了调度
- yarn依然作为资源调度和管理,但是不是提交到resourcemanager而是AMPoolServer,存放着已经预先启动的Applicationmaster
- tez针对mapreduce的序列化和反序列化是可以在内存中处理的
- spark:通过支持DAG作业的计算引擎
15. hive的存储引擎
-
testfile:按行存储,不支持块压缩,磁盘开销大,加载速度最高
-
rcfile:
- 按行存储,每块按照列压缩,结合了行存储和列存储的特点,
-
ORCFile:
- 是refile的升级版,加了索引
-
parquet:列式存储,压缩比ORC低一些,查询效率较低,
-
sequencefile:hadoop api中的二进制文件,以kv形式序列化到文件中
-
压缩比:orc>parquet>testfile 查询速度:三者差不多
16. hive的count的用法
- count(*):所有行进行统计,包括null
- count(1):所有行进行统计,包括null
- count(字段):不包含null
17 hive存储数据的方式/保存元数据的方式
- hive的元数据存储
- 内嵌模式:保存本地的derby数据库
- 本地模式:保存本地mysql中
- 远程模式:需要单独起元数据
- hive的表数据存储
- 存在hdfs中,这些数据的元数据存在namenode中
18 hiveserver2是什么
- 是一个服务器端口,远程客户端可以执行对hive的增删改查
- 基于thrift RPC,支持多客户端并发和身份验证
19 hive表字段换类型如何修改?
- 使用alter table change column针对没有数据的时候
- 有数据使用
- 先将要该字段结构的表名修改成一个临时表:alter table 表1 rename to 表2
- 创建和表1 一模一样的表3
- 将表2的结果插入到新表
20 案例:连续活跃登陆的用户指至少连续2天都活跃登录的用户
Hive-SQL查询连续活跃登录用户 - 渐逝的星光 - 博客园 (cnblogs.com)
21案例: hive怎么实现行转列或者列转行
22 hive的常用函数
(130条消息) Hive函数大全_斑马!的博客-CSDN博客_hive函数


![[数据结构 - C语言] 顺序表](https://img-blog.csdnimg.cn/img_convert/f766197ad4bb9bbd8492a153dbd020b4.png)
![逆向-还原代码之(*point)[4]和char *point[4] (Interl 32)](https://img-blog.csdnimg.cn/1cf95bbf676e4a998c6e3da488a72f17.png)