缓存穿透
用户查询的数据在缓存和数据库中都不存在
这样的请求每次都会打到数据库上
解决方案:
1.缓存空字符串(额外的内存消耗,可能造成短期的不一致)
2.布隆过滤(内存占用少,没有多余key,实现复杂,存在误判可能)
对于数据库中没有的数据,向缓存中缓存空值,别再访问数据库了,减少压力
缓存一致性问题
更新数据库的时候,先更新数据库,再删除缓存
实现强一致性,需要使用分布式锁控制,修改数据和向缓存存数据使用同一个分布式锁
实现最终一致性,缓存数据要加过期时间
对于实时性要求强的,要实现数据强一致性要尽量避免使用缓存
缓存雪崩
同一时间大量的key失效或者redis宕机
解决方案:
1.过期时间可以设置随机数,如30+(0~5)分钟随机,不要同时过期
2.使用redis集群提高可用性
3.给缓存业务添加降级限流策略
4.给业务添加多级缓存
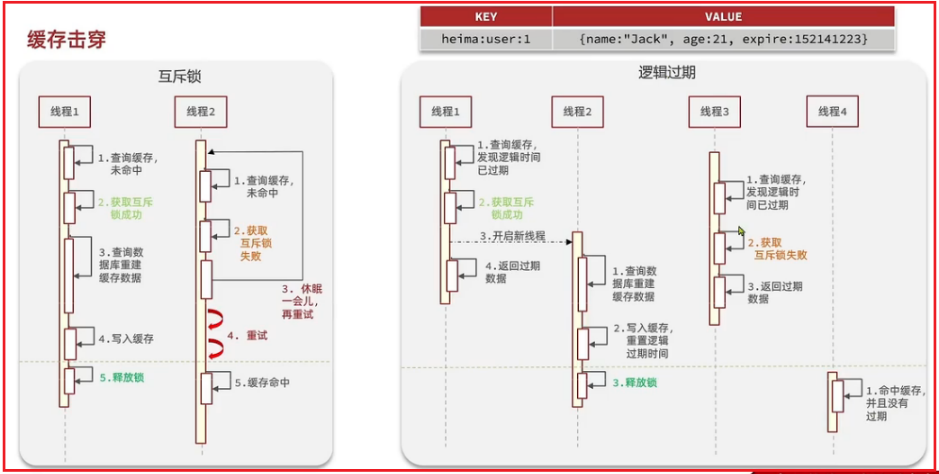
缓存击穿
热点key问题
某些Key属于极端热点数据,且并发量很大的情况下,如果这个key过期,可能会在瞬间出现大量的并发请求直接打到了数据库
常见解决方案
互斥锁:
线程在重建缓存数据时,进行加锁,其他线程等待重试,直到释放锁之后,其他线程就可以缓存命中了
保证一致性,实现简单
其他线程需要等待,可能有死锁风险
逻辑过期:
对数据加一个过期时间字段,但并不实际设置过期时间,始终在redis当中。
校验发现逻辑时间过期时,获得互斥锁,开新线程去重建缓存数据,本线程返回那个过期的数据
对于其他线程,发现缓存中数据逻辑时间过期时,尝试获取互斥锁失败,就直接返回过期数据。
线程无需等待,不保证一致性
全局ID生成器
# 全局唯一ID生成策略
UUID
Redis自增
snowflake
数据库自增
在分布式系统下用来生成全局唯一ID的工具
(唯一性,高可用,高性能,递增性,安全性)
Long型,8个字节

超卖问题
多个线程在操作共享的变量\资源
解决方案:加锁
悲观锁:认为线程安全问题一定会发生,在操作数据之前先获取锁,确保线程串行执行(Synchronized,Lock)
乐观锁:认为线程安全问题不一定会发生,因此不加锁,只在更新数据时去判断有没有其他线程对数据做了修改
常见方案:
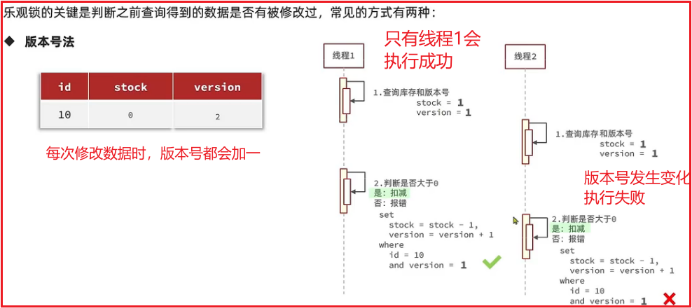
1.版本号法
给数据加上一个版本字段
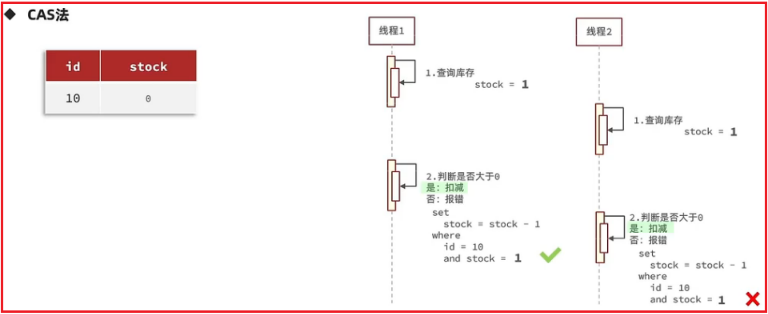
2.CAS法
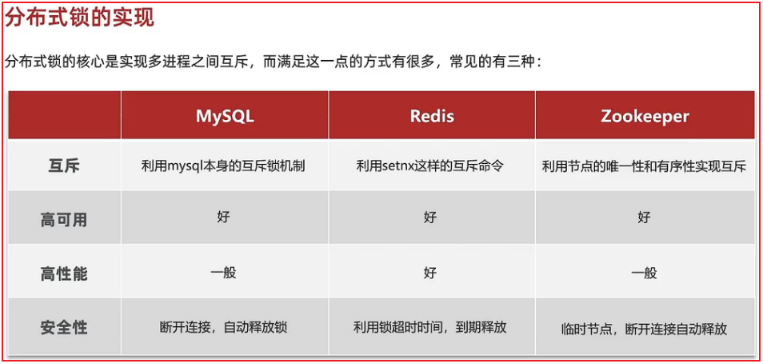
分布式锁
单机情况下由于有锁,所以安全
但是集群模式下,synchronized并不能保证集群并发安全性
需要多进程可见互斥的分布式锁

# lua脚本
eval "lua_script" NumberOfKeys key argv
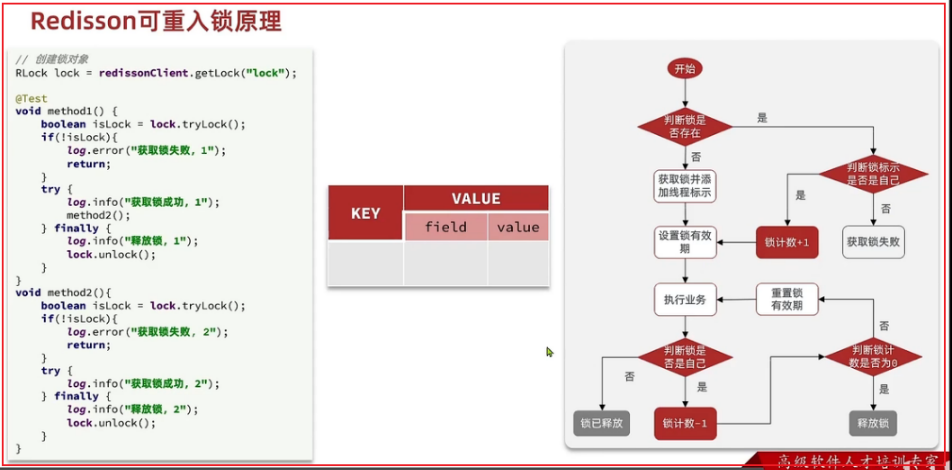
redisson可重入锁原理
"lockName":{
"threadId": "重入次数"
}
# 利用hash结构记录线程对应的重入次数
获取锁时锁已存在:
看线程标识是否是自己,是自己,锁计数value+1(并且重置有效期),不是自己获取锁失败
获取锁时锁不存在:
获取锁,并添加线程标识,锁计数为1,设置有效期
释放锁时:
线程标识是自己:锁计数减一,且重置有效期(减完如果为0,则释放锁)
线程标识不是自己:说明已经超时释放
-- 获取锁
local key = KEYS[1]; --锁的名字
local threadId = ARGV[1]; --线程标识(fieldName),对应的value是重入次数
local releaseTime = ARGV[2]; -- 过期时间(自动释放)
-- 锁不存在
if(redis.call('exists',key) == 0) then
redis.call('hset',key,threadId,'1'); -- 将field(threadId)对应的value置为1
redis.call('expire',key,releaseTime);
return 1;
end;
-- 锁已存在(且线程标识是自己)
if(redis.call('hexists',key,threadId) == 1) then
redis.call('hincrby',key,threadId,'1'); -- 重入次数+1
redis.call('expire',key,releaseTime);
return 1;
end;
return 0; -- 说明锁已存在但线程标识不是自己,获取锁失败
-- 释放锁
local key = KEYS[1]; -- 锁名
local threadId = ARGV[1]; --线程标识(fieldName),对应的value是重入次数
local releaseTime = ARGV[2]; -- 过期时间(自动释放)
-- 线程标识不是自己(不用管)
if(redis.call('HEXISTS',key,threadId) == 0) then
return nil;
end;
-- 是自己,重入次数-1
local count = redis.call('HINCRBY',key,threadId,-1);
if(count > 0) then
redis.call('EXPIRE',key,releaseTime);
return nil;
else
redis.call('DEL',key); -- 重入次数为0,则释放锁(删除)
return nil;
end;
可重试原理:
第一次获取锁失败以后,等待释放锁的消息(redis中pubsub机制),释放锁的时候会发送这样的消息
得到消息后,重新获取锁,再次失败会继续等待消息
会有等待时间,超过时间不会再重试
超时续约问题:
默认的锁释放时间是30s
获取锁成功以后,会开启一个延时定时任务,每隔一段时间,不断的刷新有效期,直到手动释放锁
释放锁的时候:会取消掉定时任务
解决主从一致性问题(使用multilock,只要有一个主节点没挂,就是安全的)


Redis消息队列
redis消息队列和阻塞队列区别
1.消息队列是在JVM内存以外的独立服务,不受JVM内存限制
2.消息队列里的消息会做持久化,不管服务宕机还是重启,数据不会丢失
3.消息投递给消费者以后,要求消费者做消息的确认,没有确认,消息就会在队列中依然存在,确保消息至少被消费一次


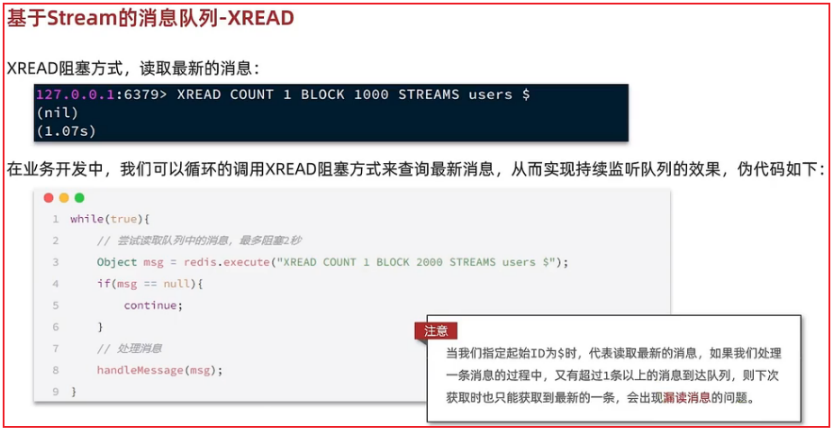
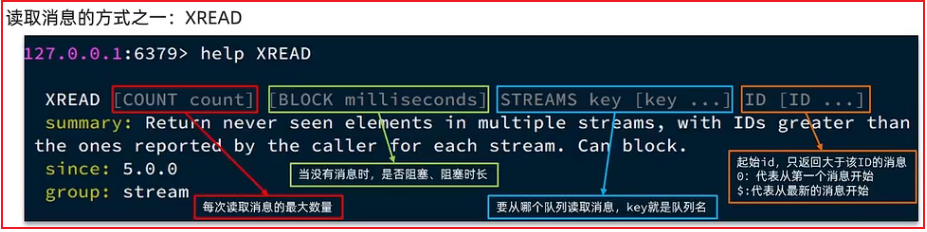
# 发送消息
XADD 队列名 *(表示消息id自动生成) field value [field value ...]
# 创建名为users的队列,发送一条消息{name:jack,age:21},消息id自动生成
XADD users * name jack age 21
# 消费消息(消息可以被重复消费,并不会删除)
# 阻塞读取一条消息, 阻塞时长1秒, 从users队列中读取消息, $表示读取最新的消息
XREAD COUNT 1 BLOCK 1000 STREAMS users $
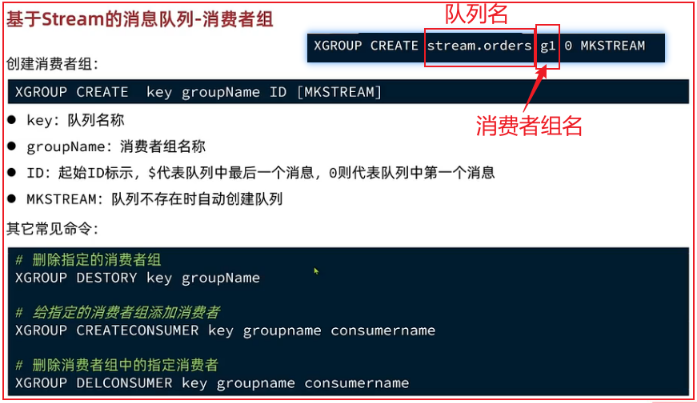
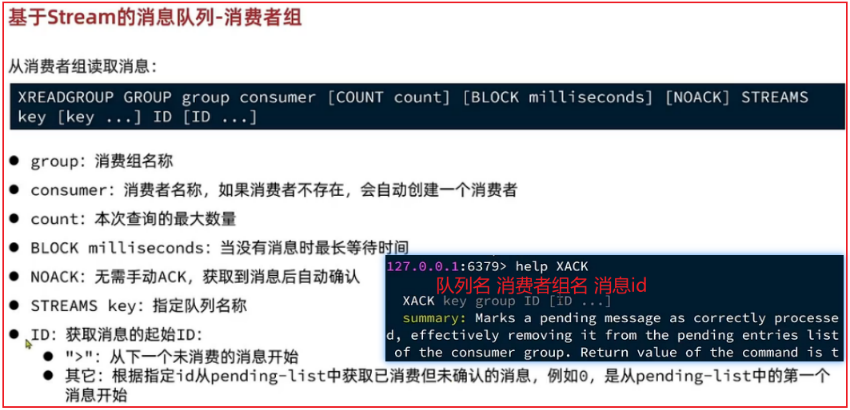
消费者组:将多个消费者划分到一个组当中,监听同一队列
有以下特点:
1.队列中的消息会分流给组内不同的消费者, 同一个消费者组内的消费者是竞争关系, 不会重复消费
2.消费者组会维护一个标识,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标识后读取消息
3.消费者获取消息后,消息处于pending状态,并存入pending-list,处理完成以后需要使用XACK来确认消息,标记已处理,才会从pending-list移除
推送Feed流
发布文章时,推送给所有的粉丝

附近的人

使用GEO数据结构(基于SortedSet)
# 添加一个地理信息
# GEOADD key longitude latitude member [longitude latitude member ...]
# Add one or more geospatial items in the geospatial index represented using a sorted set
# key是g1,成员是(bjn,bjz,bjx)
GEOADD g1 116.378248 39.865275 bjn 116.42803 39.903738 bjz 116.322287 39.893729 bjx
# bjn和bjx的距离(单位米)
GEODIST g1 bjn bjx
GEODIST g1 bjn bjx km # 单位(km)
# 返回成员bjn的地理坐标
GEOPOS g1 bjn
# 将指定成员的地理坐标转为hash字符串并返回
GEOHASH g1 bjn
# 北京天安门附近10km内的地理坐标信息(升序列出)
GEOSEARCH g1 FROMLONLAT 116.397904 39.909005 BYRADIUS 10 km WITHDIST
用户签到


# 用一个二进制串表示本月中的签到情况,每一位表示其中的某一天
setbit bm1 5 1 # 第6天签到(1表示签到,默认是0)
getbit bm1 2 # 查看第3天是否签到
bitcount bm1 # 值为1的位数
bitfield bm1 get u3 0 # 从索引0位开始,查3位,返回值是十进制,u表示无符号
UV统计
UV:Unique Visitor,独立访客量,一天内同一用户多次访问只记录一次
PV:Page View,页面访问量\点击量,每次访问页面,都会记录
# 大用户量的时候,做UV统计要判断是否已统计过,需要存数据,是一个巨大的数据量



![很合适新手入门使用的Python游戏开发包pygame实例教程-02[如何控制飞行]](https://img-blog.csdnimg.cn/3d72ed578a9a4e4096526f5f9b5acb58.gif#pic_center)