【数据结构】数据结构小试牛刀之单链表
- 一、目标
- 二、实现
- 1、初始化工作
- 2、单链表的尾插
- 2.1、图解原理
- 2.2、代码实现
- 解答一个疑问
- 3、单链表的尾删
- 3.1、图解原理
- 3.2、代码实现
- 4、打印单链表
- 5、单链表的头插
- 5.1、图解原理
- 5.2、代码实现
- 6、单链表的头删
- 6.1、图解原理
- 6.2、代码实现
- 7、单链表的查找
- 7.1、原理解析
- 7.2、代码实现
- 8、单链表的随机插入
- 8.1、图解原理
- 8.2、代码实现
- 9、单链表的随机删除
- 9.1、图解原理
- 9.2、代码实现
- 10、销毁单链表
- 10.1、图解原理
- 10.2、代码实现
不讲虚的啦,直接肝!
一、目标
单链表所要实现的功能罗列如下:
// 创建一个新节点,并初始化数据域,返回节点指针
Node* create_newNode(data_type x);
// 单链表的尾插
void single_list_push_back(Node** pphead, data_type x);
// 单链表的尾删
void single_list_pop_back(Node** pphead);
// 单链表的打印
void print_single_list(Node* phead);
// 单链表的头插
void single_list_push_front(Node** pphead, data_type x);
// 单链表的头删
void single_list_pop_front(Node** pphead);
// 单链表的查找,根据数据域的值返回节点指针
Node* find_Node(Node* phead, data_type x);
// 单链表的随机插入,在某个节点的后面插入新节点
void single_list_insert(Node** pphead, Node* target, data_type x);
// 单链表的随机删除,根据节点指针删除某个节点
void single_list_remove(Node** pphead, Node* target);
// 销毁单链表,销毁单链表的所有节点
void destory_single_list(Node** pphead);
二、实现
1、初始化工作
初始化工作我们先初始化一个节点类型,类型中包括了数据域和指针域,数据与中保存着该节点要保存的数据,指针域则保存着链表下一个节点的地址:
typedef int data_type;
typedef struct single_list_node {
data_type data; // 数据域,保存数据
struct single_list_node* next; // 指针域,指向下一个节点
} Node;
然后我们在创建一个函数,用于创建一个新的节点,因为后面我们在创建插入节点的函数的时候,每次都要在堆中开辟出一个新的节点,所以把创建新节点的功能单独写成一个函数能有效地较少代码的冗余:
// 创建一个新节点,并初始化数据域,返回节点指针
Node* create_newNode(data_type x) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (NULL == newNode) {
perror("create_newNode fail");
exit(-1);
}
newNode->data = x;
return newNode;
}
做好这些工作之后我们就可以来创建链表了,我这里是用的是不带头结点的方式来创建链表,我们是通过一个定义一个Node *phead的头指针来指向链表的第一个节点,从而找到链表,并对链表进行各种操作的,所以所以我们只需要在main函数中定义一个头指针即可:
int main() {
Node* head = NULL;
// 插入数据
return 0;
}
而之后我们创建的新节点都是在堆上创建的,我们只需要让phead保存堆中第一个节点的地址即可,用一个形象一点的图来解释就如下图:
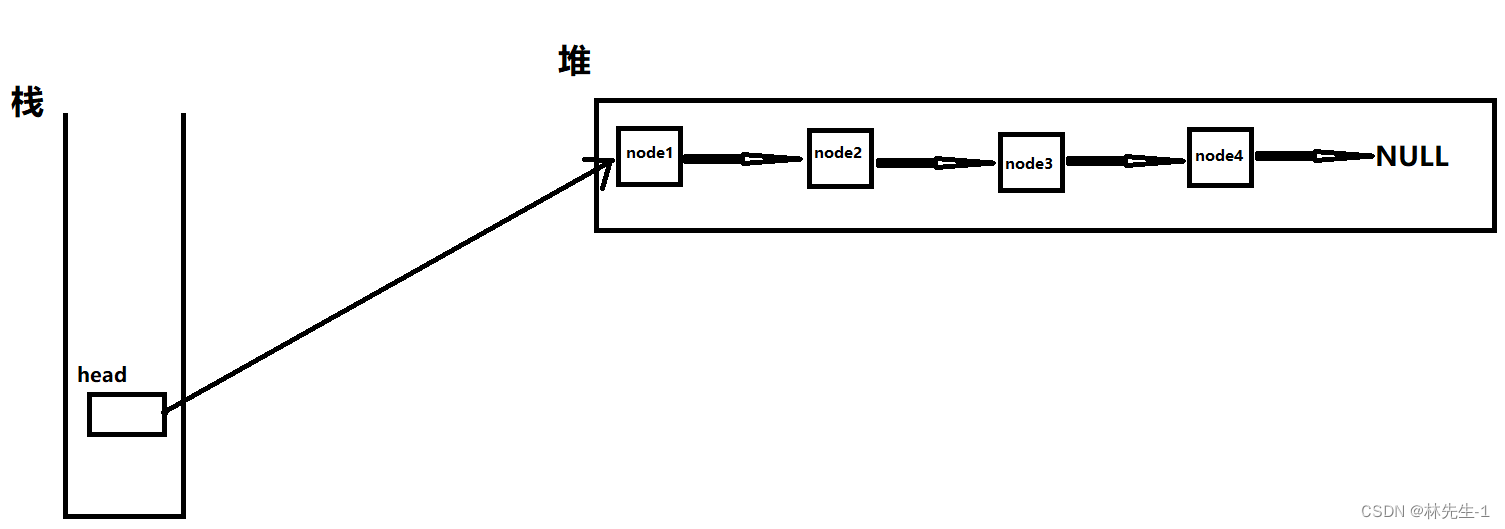
大家先记住这个图,这对后面分析一些问题会有帮助。
2、单链表的尾插
做好初始化工作之后,我们就可以创建链表了,这里首先要实现的就是单链表的尾插,即在单链表的尾部插入节点。
2.1、图解原理
讨论问题我们都倾向于先讨论一般情况,后讨论一般情况,所以我们先来讨论一般情况,就是单链表中已经有多个节点,那我们就要设法先找到链表的最后一个节点:

但该怎么找到最后一个节点呢?
其实很简单,我们只需要在定义一个Node *tail的指针,初始时让它跟head一样指向链表的第一个节点:

然后我们一直令tail = tail->next,当tailnext == NULL的时候就说明tail已指向链表的最后一个节点:

然后假设我们已经创建了一个新节点newNode,那我们就只需要将tial->next = newNode,然后令newNode ->next = NULL,我们就完成了新节点的插入:

而对于特殊情况,这个操作就只有一种特殊情况,就是链表为空时:
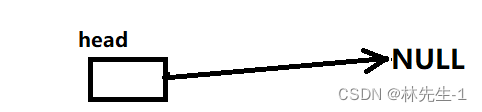
而这种情况也不难解决,我们只需要对head的指向做更改即可,即令head指向newNode:
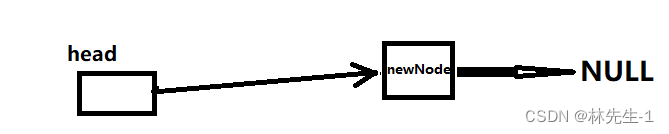
2.2、代码实现
有了思路,代码也就跳出来了
void single_list_push_back(Node** pphead, data_type x) {
Node* newNode = create_newNode(x);
if (NULL == *pphead) { // ;链表为空时
*pphead = newNode;
newNode->next = NULL;
}
else {
Node* tail = *pphead;
while (tail->next != NULL) {
tail = tail->next;
}
tail->next = newNode;
newNode->next = NULL;
}
}
而对于这里为什么要传递二级指针,这其实就是C语言指针相关的基础语法问题,我只简单说只有传递二级指针才能对外部的head进行更改。而如果这都看不明白的话,那你就真的应该反思一下自己的C语言语法是否学的扎实了。
解答一个疑问
虽然说对于head的修改要用二级指针属于语法层面的问题,但我见过还有些朋友会有这样的疑问,就是说为什么到后面尾插的时候对于tail的next和newNode的next的修改就不需要用到二级指针了?
我感觉之所以会出现这样的问题其实是由于对指针的访问原理还不太深刻导致的。
指针的访问原理其就是通过一个指针变量来保存地址,访问时候先从指针变量中取出其中保存的地址,有了地址就能访问到对应的空间,就拿一个最简单的打印数组的例子来举例吧:
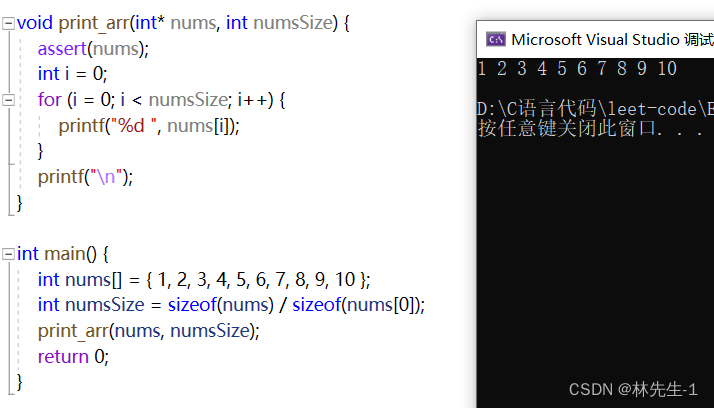
我们知道print_arr里nums其实就是一个保存了数组起始地址的指针变量,但我们也知道数组是连续存储的,所以我们只要有数组的起始地址,就可以不断的往后递增4个字节地址来访问到后面的元素:

而我们使用的head其实也跟上图的nums`起到的作用是相同的,也是只起到了一个保存地址的作用,有了地址就可以访问对应的节点空间,然后在通过节点空间中的next中保存的地址就可以在访问到下一个节点空间:

所以我们只需要拿到第一个节点的地址就可以拿到后面所有节点的地址,有了地址就可以访问但对应的节点的空间,对这些空间的修改就是对这些节点的修改,所以在后面尾插的时候就不需要用到二级指针了。
3、单链表的尾删
尾删即删除链表的最后一个节点
3.1、图解原理
这个操作的一般情况我们还是得找到链表的最后一个节点:

但想要完成尾删的操作却并不能直接找到最后一个节点,因为再删除最后一个节点后,我们必须将倒数第二个节点的next置为NULL。而单链表有一个缺陷就是只能单向遍历,也就是说当tail指向最后一个节点后,我们将找不到tail的前一个节点,这样就不能将倒数第二个节点的next置为空了。
所以我们我们只能找到倒数第二个节点,通过倒数第二个节点来删除最后一个节点:

具体做法就是先用free函数释放掉tail->next,再令tail->next为NULL。
而特殊情况有两种,就是链表为空和链表中只有一个节点:
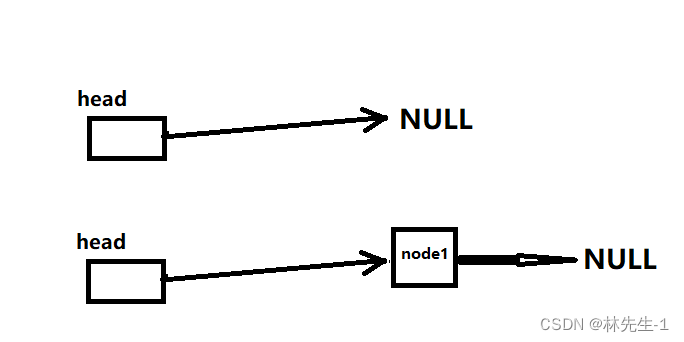
链表为空就很简单,直接不允许删除,直接返回即可。而链表中只有一个节点我们只需要先将第一个节点即head->next释放掉在令head->next=NULL即可。
3.2、代码实现
有了思路,写起代码来也就应该水到渠成了:
void single_list_pop_back(Node** pphead) {
if (NULL == *pphead) {
printf("链表为空,不可删除……\n");
return;
}
if (NULL == (*pphead)->next) { // 链表中只有一个节点时
free(*pphead);
*pphead = NULL;
}
else { // 链表中节点大于一个时
Node* tail = *pphead;
while (tail->next->next != NULL) {
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
4、打印单链表
我们可以写一个打印函数来试验一下我们上面所写的函数是否有问题。
其实打印就等于是遍历,我们同样只需要使用一个Node *cur指针来辅助遍历链表,当cur不为空时,打印出节点中的信息即可:
void print_single_list(Node* phead) {
if (NULL == phead) {
printf("链表为空,没有信息可打印……\n");
return;
}
Node* temp = phead;
while (temp->next != NULL) {
printf("[%d]——>", temp->data);
temp = temp->next;
}
printf("[%d]——>NULL\n", temp->data);
}
这样我们就可以来测试我们上面所写的两个函数了:
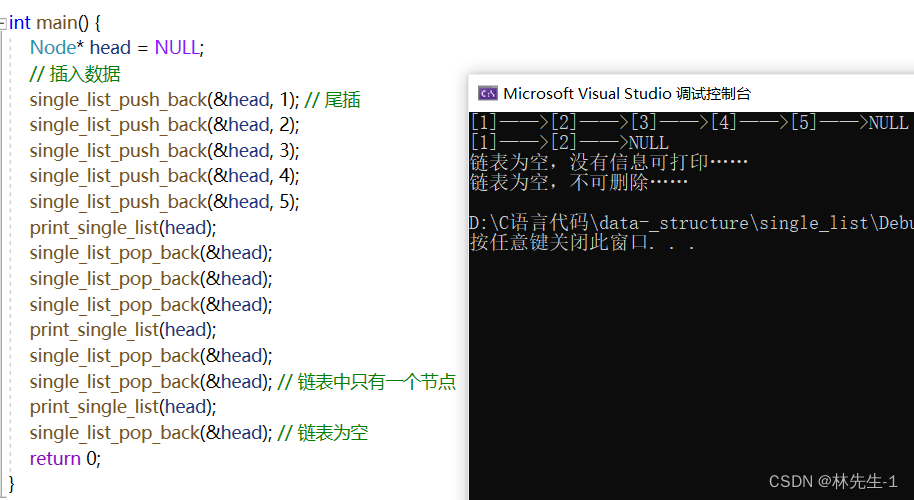
从上面的测试结果中可以分析出,我们写的代码是没有什么问题的。
5、单链表的头插
有了尾插我们再写一个头插,头插即在链表的头部插入一个节点
5.1、图解原理
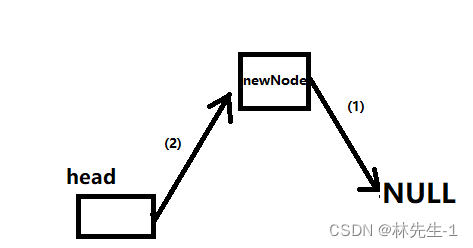
因为头插每次都是在头部插入节点,所以我们也不必遍历链表了,我们直接对head进行更改即可,我们只需要先令newNode->next=head->next,然后再令head->next=newNode:

需要注意的是,因为是单链表所以(1)和(2)的顺序不能颠倒,一旦颠倒了,就找不到节点了。
而这里是否需要特殊处理链表为空的情况呢?
其实不用的,因为如果链表为空的话,执行完(1)后newNode的next为NULL,然后head的next=newNode正好也能完成任务:
5.2、代码实现
有了以上思路,那我们写起代码来也就水到渠成了:
void single_list_push_front(Node** pphead, data_type x) {
Node* newNode = create_newNode(x);
newNode->next = *pphead;
*pphead = newNode;
}
6、单链表的头删
有了头插,我们再来写一个头删
6.1、图解原理
头删其实也是比较轻松地,我们只需要对head做更改并释放掉第一个节点即可,但因为第一个节点在释放掉后就找不到后一个节点了,所以我们每次需要先用一个Node *newhead的指针保存第二个节点后,再释放第一个节点,然后再让head指向newhead:
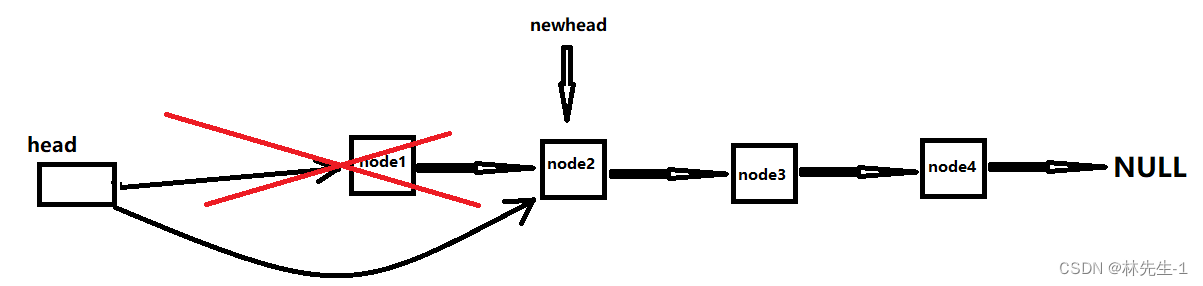
而当链表中只有一个节点时我们也不用改变操作。
6.2、代码实现
void single_list_pop_front(Node** pphead) {
if (NULL == *pphead) {
printf("单链表为空,不可删除……\n");
return;
}
Node* newhead = (*pphead)->next;
free(*pphead);
*pphead = newhead;
7、单链表的查找
根据数据域的值来查找节点,设要寻找的目标值为target,返回数据域的值为target的节点的地址,如果找不到就返回NULL。
7.1、原理解析
因为是单链表,所以我们只能从前往后依次遍历,我们使用一个cur指针来遍历数组,当cur->data == target时,就返回
7.2、代码实现
Node* find_Node(Node* phead, data_type target) {
if (NULL == phead) {
printf("单链表为空,没有任何信息……\n");
return NULL;
}
Node* cur = phead;
while (phead->next != NULL) {
if (cur->data == target) {
return cur;
}
cur = cur->next;
}
return NULL;
}
8、单链表的随机插入
单链表的随机插入,在某个节点的后面插入新节点
8.1、图解原理
其实我们上面所写的查找函数就是为这里的实现而服务的,使用这个函数,我们就得先用上面的查找函数查找到目标节点target的地址,才能在这个目标节点的后面插入新节点。
当我们找到目标节点后,操作就很简单了,只需要先让newNode的next指向target的next,然后再让target的next指向newNode:
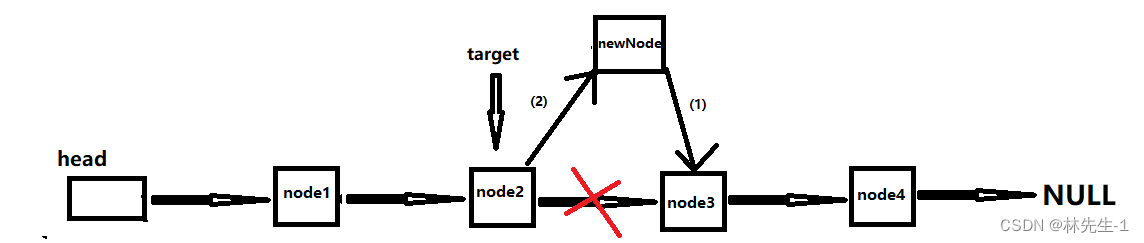
同样,因为是单链表,所以操作(1)一定要在操作(2)前面执行。
当然啦,我这样设计的函数一定是要在链表中能找到target节点的前提下才能完成的,所以对于一些特殊情况的处理,比如目标节点不存在,其实在上面的查找函数中就已经处理了。
而还有一个特殊情况可能就只剩链表中只有一个节点了,但这个情况其实跟尾插的处理方式是一样的,我们同样是不需要特殊来处理这个情况的。
而对于链表为空,我们只需要执行头插的逻辑即可。
8.2、代码实现
void single_list_insert(Node ** pphead, Node* target, data_type x) {
if (NULL == *pphead) { // 链表为空,统一执行头插
single_list_push_front(pphead, x);
return;
}
if (*pphead != NULL && NULL == target) { // 链表不为空,但目标节点不存在
printf("目标节点不存在!\n");
return;
}
Node* newNode = create_newNode(x);
newNode ->next = target->next;
target->next = newNode;
}
9、单链表的随机删除
删除链表中的某个节点
9.1、图解原理
因为实单链表,所以我们要删除某个节点就必须找到这个节点的前一个节点,这样我们才能保证在删除节点后,还能把链表给链接上:
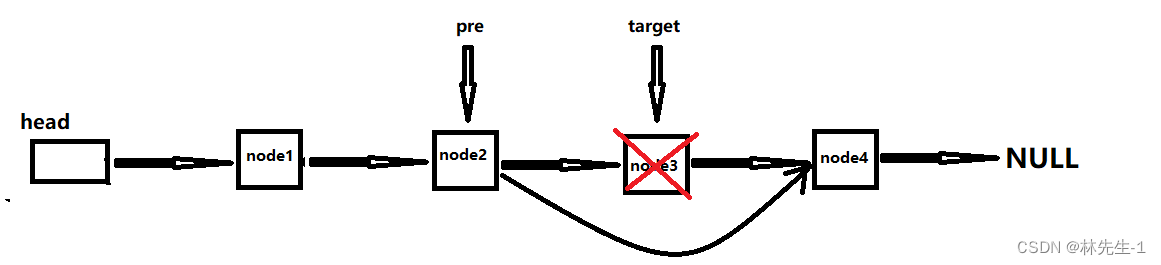
如上如,一般情况下,当我们找到target的前一个节点pre之后,需要想让pre的next指向target的next,然后再将target给释放掉。
但是含有些特殊情况,第一个就是当链表中只有一个节点时,这时target是没有前驱的:
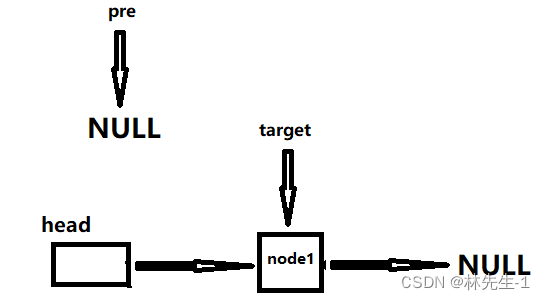
这个情况其实也很好解决,直接释放掉target然后将head的next置为NULL就行了。
还有一个情况就是当target的next为NULL时候,也就是当target为最后一个节点时:

这时候我们直接释放掉target然后将pre的next置为NULL即可。
9.2、代码实现
void single_list_remove(Node** pphead, Node* target) {
if (NULL == *pphead) {
printf("链表为空,不可删除……\n");
return;
}
if (*pphead != NULL && NULL == target) {
printf("待删除节点不存在!\n");
return;
}
if (NULL == (*pphead)->next) {
free(*pphead);
*pphead = NULL;
}
else {
Node* pre = *pphead;
while (pre->next != target) {
pre = pre->next;
}
if (NULL == target->next) {
free(target);
pre->next = NULL;
}
else {
pre->next = target->next;
free(target);
}
}
}
10、销毁单链表
我们链表的节点都是在堆上动态申请而来的,所以当我们不用的时候,就需要将这些节点全都回收,所以我们需要一个函数来帮我们销毁单链表中所有的节点
10.1、图解原理
有人可能会投机的想,那我用之前写好的删除函数来将链表中的节点一个个的删除掉直到头节点为不就行了吗?
这当然也是一个很好的实现方法,但我今天不想用这种方法,我们单独写一个新的函数。
因为是单链表,所以当我们释放掉一个节点后就找不到它的后一个节点了,所以我们应该在删除某个节点之前就保存它的下一个节点。
所以我们就可以这样设计让一个指针cur来遍历整个链表,用一个指针pre保存cur的前一个节点,然后我们每次都释放pre即可,直到后面cur的next为空时我们才释放掉cur:
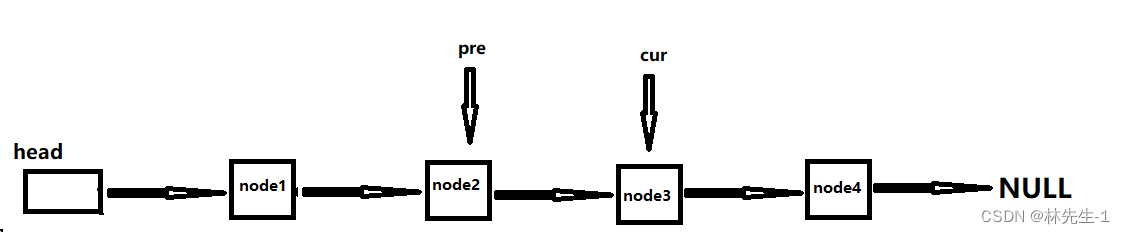
最后再将head置为NULL。
10.2、代码实现
void destory_single_list(Node** pphead) {
if (NULL == *pphead) {
return;
}
Node* cur = *pphead;
Node* pre = NULL; // 保存cur的前一个节点
while (cur->next != NULL) {
pre = cur;
cur = cur->next; // 一定要先后移再释放
free(pre);
}
free(cur);
*pphead = NULL;
}