之前使用querydatabasetable处理器来获取mysql中的数据,我们只能写死一个sql的查询语句,但是
实际引用环境中,我们的一张mysql的表,可能有上千万的数据,那么,不可能,我们把sql查询语句写死,这样一次性如果获取所有数据,那么压力太大了,我们怎么弄呢?找了很久没有找到相关教程,自己做了测试,整理出来了.
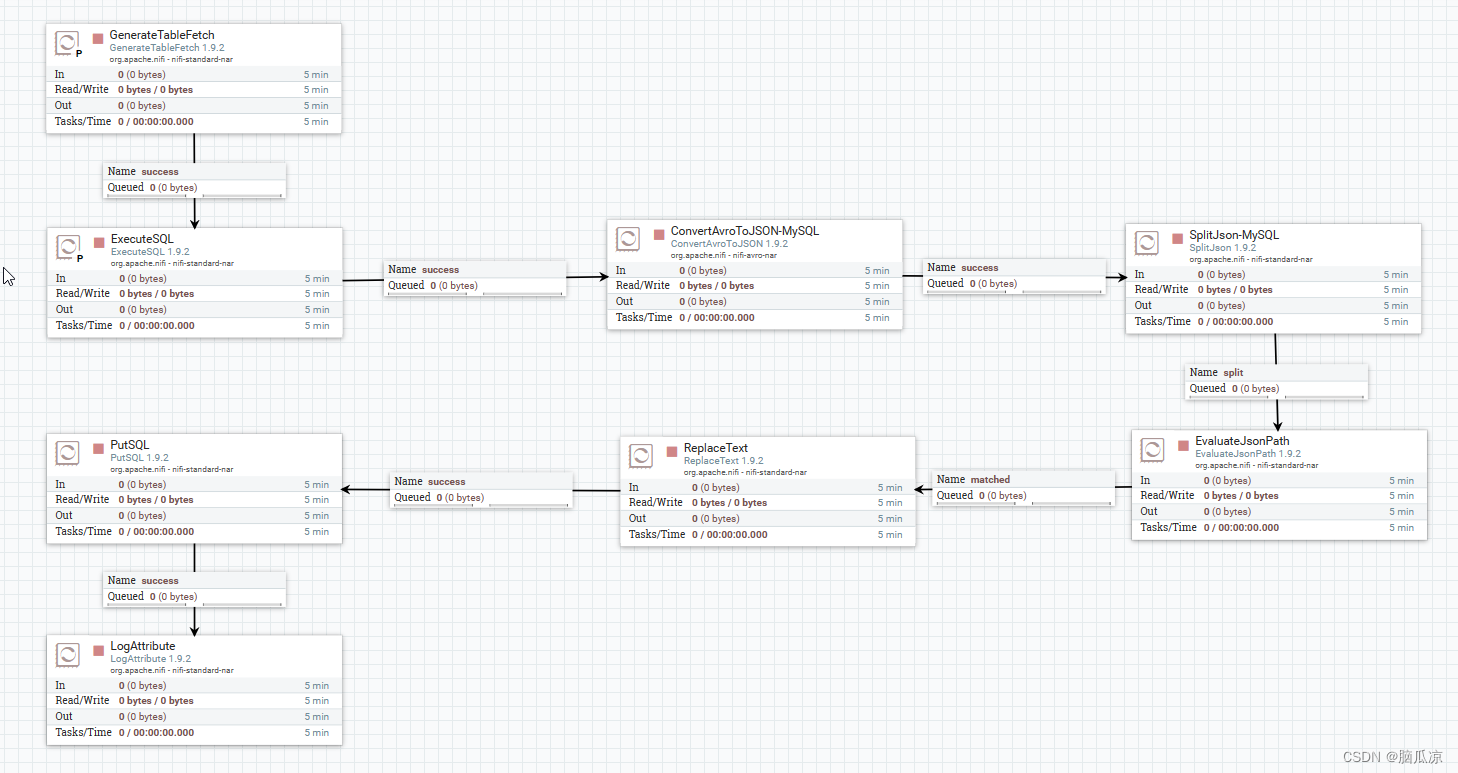
先来看一下整体的一个处理器的流程,可以看到,我们新添加了,两个处理器generateTableFetch处理器,和ExecuteSql处理器,然后把
querydatabasetable处理器删除掉了,对,因为querydatabasetable,不支持分页,所以我们删除掉了,除了替换掉了,这两个处理器,其他的
处理器都是原来的,没有变
好,首先我们拖拽一个GenerateTableFetch处理器,然后我们
然后我们看一下 这个处理器的配置
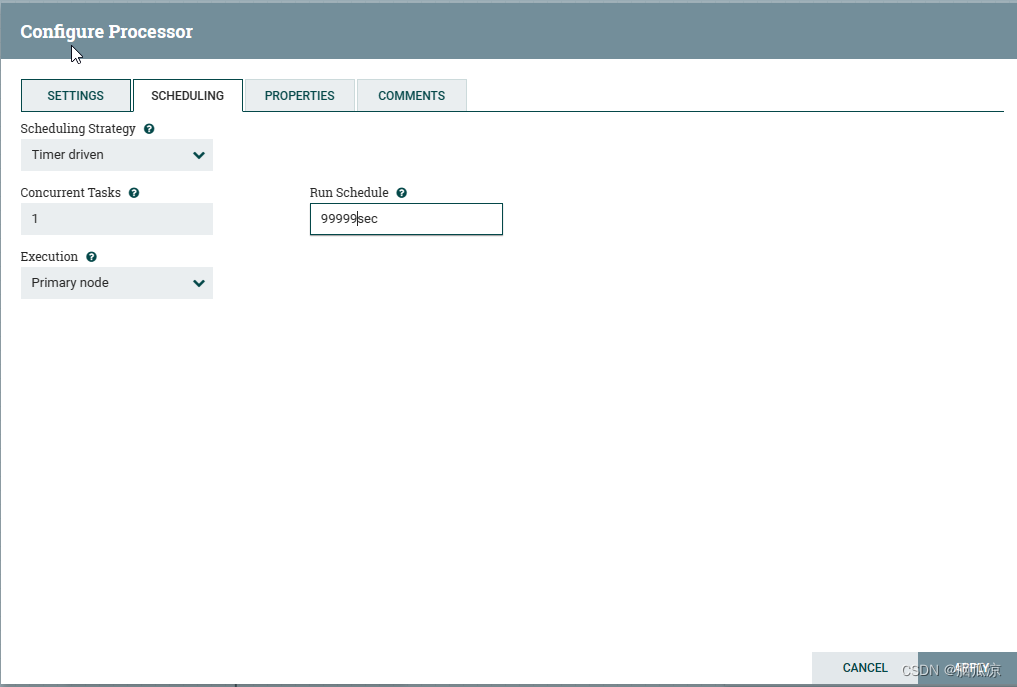
这里首先看这个schedule属性页,这里设置run schedule这里是9999sec,就是时间要长一些,也就是,让他帮我们执行一次
分页的,sql操作以后就完了,不继续执行了,要不然,他就会不停的产生sql.
比如过我我们数据库中有3条数据.我们设置让他一次获取一条数据,他就会生成下面的3条sql
SELECT i